제목: Feature selection for text classification: A review (2018)
링크: https://link.springer.com/article/10.1007/s11042-018-6083-5
0. Abstract
- Text classification에서의 Feature Selection에 대한 리뷰 논문
- Representation 방법, Classifier 종류, 그리고 네 가지 Feature Selection 모델 소개
1. Introduction
- 기술의 발전으로 많은 양의 텍스트 정보가 돌아다니고 있다. (CNN 뉴스, 트위터 트윗, 아마존 고객 리뷰 등등)
- 수많은 양의 텍스트 중에서 내가 관심 있는 주제로만 읽고 싶어하고 싶을 땐 text categorization으로 분류하기
- 하지만 다양한 단어들이 등장하는 데이터에서 모든 단어들로 텍스트 분류를 하겠다고 하면, 당연히 성능이 낮죠
- 그래서 이번 리뷰 페이퍼에서는 최고의 성능을 위한 여러 가지 방법과 기본 지식을 소개하겠다~
2. Text Classification
- 정의: 문서에 사전 정의된 레이블/카테고리를 부여해주는 것
- 미리 모은 문서 {D}를 이용해 분류기 {T}를 만든다
2.1 Document Representation
- 가장 유명한 document representation은 bag-of-words model (문서 d에 단어 s가 빈도 f번 나왔는지 표현)
- bag-of-words에서 단어에 좀 더 weight를 부여하고 싶으면 TF-IDF weighting scheme을 넣을 수 있음
- 문서의 단어/feature 리스트를 설정하는데 두 가지 방법: universal dictionary method, local dictionary method
Universal method: 모든 문서에 사용할 feature를 생성
Local method: 문서 label 클래스에 특정한 dictionary를 지정
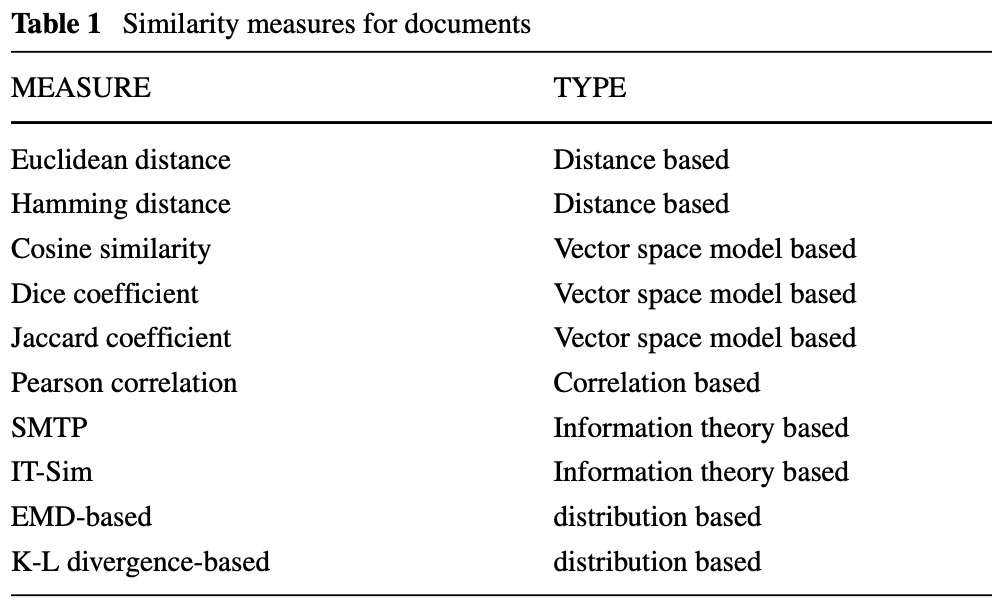
2.2. Similarity between documents
-
유사도 계산은 document clustering, classification, data mining, information retrieval에 매우 중요
-
대표적인 유사도 계산 방법은 다음의 예시가 있다:
a) Euclidean distance: L2 metric으로 좌표간 거리 계산. 하지만 고차원 영역에서는 Euclidean distance가 다 비슷비슷해져서 굉장히 성능이 낮음
b) Cosine similarity: Text categorization에서 자주 사용. 주로 문서 벡터를 미리 normalize하고 사용
c) Jaccard coefficient: 시작은 두 ecological species 간의 유사도를 구하기 위해서 사용 되었으나, 이제는 두 집합이 얼마나 비슷한지 계산을 위해 많이 쓰이는 중
d) Dice coefficient: Jaccard coefficient와 비슷한 측정 방법 -
어떤 연구자들은 Information theory 의 시선에서 유사도를 측정해야 한다고 주장. 그래서 다음과 같은 기법:
e) IT-Sim: i.e. Information-theoretic measure. 메인 아이디어는, 두 물체 간의 유사도는 = 그 물체가 소유하고 있는 공통적인 정보 + 다른 정보의 관한 주제. 성능은 매우 좋으나, computational cost가 크다
f) SMTP: 같은 information-theory 기반 측정법. 다음의 세가지 정보를 사용: 두 문서에 등장하는 feature, 하나의 문서에만 등장하는 feature, 그리고 두 문서에서도 등장하지 않는 feature. SMTP이 IT-Sim보다 성능이 좋다 -
문서 구조에 대한 정보 (즉, 문서 상에서의 단어의 분포도와 같은 정보)는 사용하지 않았는데, 그 정보도 고려해야하지 않나. 문서마다 단어에 대한 분포도는 다른데, 그 정보도 고려해야 한다:
g) EMD-based: 우선 문서를 subtopic으로 분해한 후에, subtopic에 따라서 Earth Mover’s Distance로 유사도를 계산
h) K-L divergence-based: 두 단어의 분포도에 대한 발산을 바탕으로 유사도 계산
2.3 Classifiers for text classification
- 문서 분류기
- kNN (k-Nearest Neighbor) classification
정의한 거리/유사도 측정의 기준으로 가까운 문서들을 묶어서 분류하는 방법.
사용하기 간단하고 실용성이 좋다, 하지만 computational cost가 높다
- kNN (k-Nearest Neighbor) classification
- Naive Bayes (NB)
특정 feature의 값은 다른 feature와 independent하다는 가정에 사용
두 가지 NB 분류기가 있는데, 하나는 multivariate Bernoulli NB = binary vector로 문서를 표현하고 feature가 있다/없다로만 단순히 표기. 다른 하나는 multinomial NB = term frequency로 문서 표현
- Naive Bayes (NB)
- Linear Least Squares Fit (LLSF)
Multivariate regression model. Training 문서와 그 category 간의 correlation을 스스로 학습하는 모델
결과는 word-category regression coefficient의 행렬로 반환
- Linear Least Squares Fit (LLSF)
- Decision Tree
Decision Tree를 만들어 문서가 어떻게 분류가 되어야 하는지 tree대로 따라감
Accuracy에 한정해서 NB보다 성능이 잘 나오는 편
- Decision Tree
- Support Vector Machines (SVMs)
Structural risk minimization principle to construct an optimal hyperplane with the widest possible margin to separate a set of data points that consist of positive and negative data samples. (즉, +/-한 데이터 포인트들을 가장 잘 분리할 수 있는 hyperplane을 정의하는 모델)
텍스트 데이터는 주로 굉장히 고차원 벡터인데 SVM은 그 고차원 특성과 independent해서 잘 쓰임. 또한 굉장히 sparse한 문서 벡터에도 사용이 잘되고, 모든 feature들을 잘 사용할 수 있어서 애용되는 기법
- Support Vector Machines (SVMs)
- Neural Network
CNN으로 text classification해보니깐 잘 되더라~
- Neural Network
3. Feature selection for text classification
- 다양한 분류기 (classifier)가 있음에도 불구하고, 텍스트 분류는 매우 고차원 벡터인 특성상 어려움을 겪는다.
- 또한 feature인 단어들이 noisy, less informative, redundant한 정보일 수도 있으므로 더 어려워진다.
- Feature selection은 결국 이런 불필요한, 부정확한 정보들을 추릴 수 있어야 한다
- 주로 4가지로 분류가 된다: filter model, wrapper model, embedded model, hybrid model
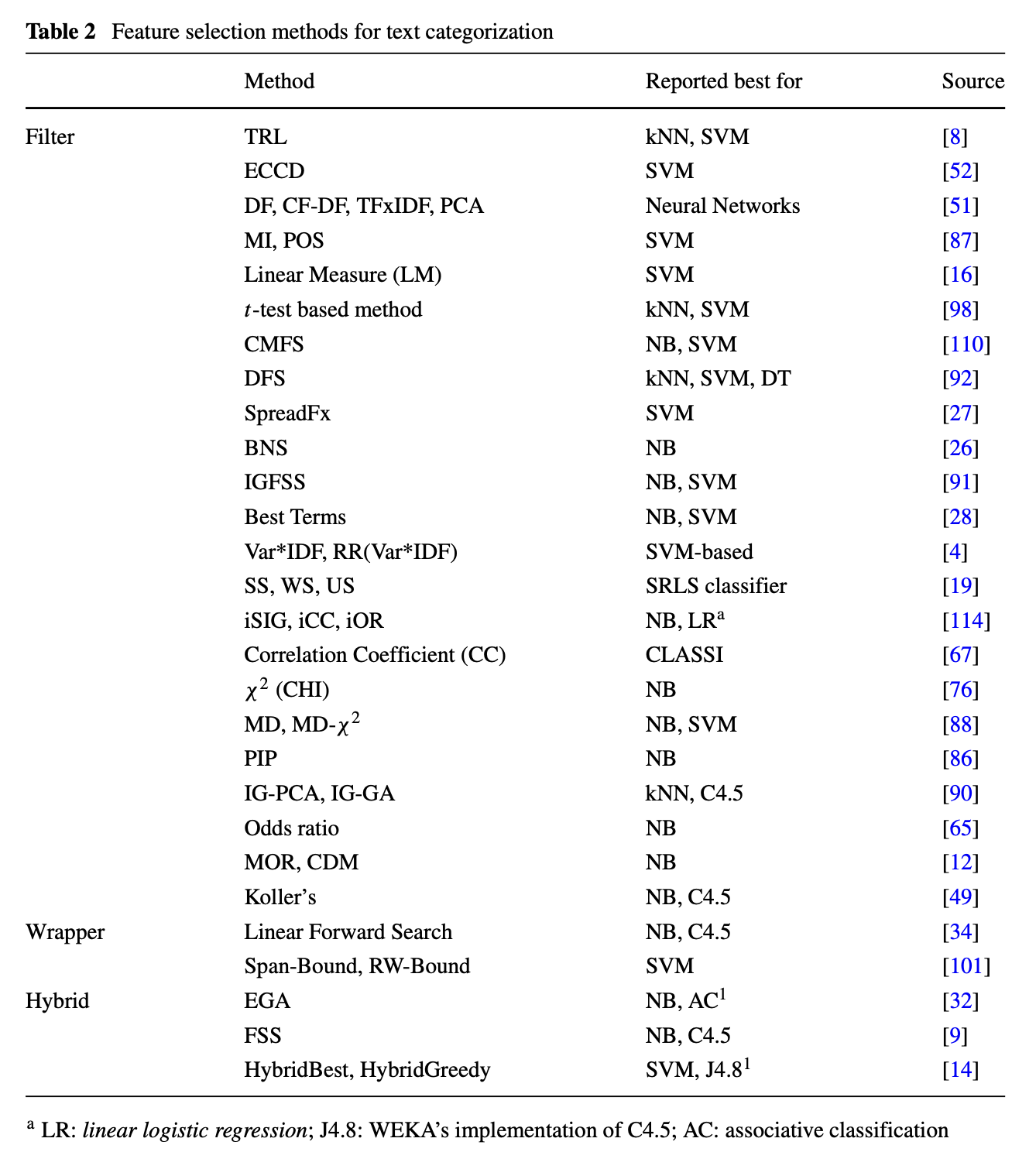
3.1 Filter Model
- Frequency로 필터 가능: Document Frequency (DF), TF-IDF
- Information theory로도 필터 가능: Mutual Information (MI), Information Gain (IG), Chi-squared (CHI), ECCD, PCA, correlation coefficient (CC), t-test. etc
- 아래의 테이블에 예시가 굉장히 많은데, 굉장히 단순하면서도 써볼만한 filter 방법들이 많으니, 해결하고자하는 문제에 잘 맞는 방법을 사용하는 것을 추천한다
3.2 Wrapper Model
- 분류기의 최고의 성능을 내는 Feature subset S’ 를 선별하고 고르는 작업
- 하지만 S에서 최고의 S’를 구하는데 정말 많은 자원 필요…
3.3 Embedded Model
- 우리가 아는 그 임베딩 모델
3.4 Hybrid Model
- Embedding 모델과 다르게, filter + wrapper 조합으로 feature selection하는 방법
- Filter model과 wrapper model을 같이 사용하면, 필요 없는 feature를 앞단에서 좀 제거를 하여 wrapper model의 cost가 줄을 수 있는 방식으로 진행
4. Discussion and Conclusion
- 보여준 예시 말고도 정말 다양한 기법들이 등장을 했으니, 잘 살펴보며 사용을 해보자
