
4학년이 되어서야 백엔드 개발자로 직무를 결정할 수 있었고, 헐레벌떡 졸업 프로젝트에 첫 백엔드 프로젝트를 참여할 수 있었다. 학교에서 강제로라도 이렇게 프로젝트를 진행하지 않았으면 제법 큰일났을지도 모르지만 … ! 그래도 이렇게 다행히 프로젝트를 강제로라도 참여할 수 있었고 무사히 완료할 수 있었다는 것에 다행이다. 이번 프로젝트를 진행하면서의 과정과 마무리까지 기록을 해보려 한다.
🍷 What is “WineOclocK” ?
프로젝트 소개
내 작은 아이디어에서 시작되었다. 예전부터 와인을 좋아하지만 와인입문자로서 와인은 너무나 어렵다. 와인을 좋아해도 가서 먹는 건 언제나 ‘추천’ 와인이나 ‘저렴한’ 와인일뿐 … 그래서 예전부터 와인 추천 웹 서비스에 대한 아이디어를 기존에 갖고 있었으나 구현까지는 생각해보지 못했는데 이번 프로젝트에 내 아이디어를 가져와 도전해볼 수 있게 되었다.
‘와인어클락’ 이란 와인을 먹기 좋은 시간이란 뜻으로, 와인 입문자들을 위한 와인 추천 웹 기반 서비스이다. 클라이언트는 와인 추천을 받을 수 있으며 심리테스트와 같은 테스트를 통해서도 상황 및 기분 별 와인 추천을 받을 수 있고 와인을 저장하고 평가할 수 있다. 그리고 와인을 키워드 혹은 필터링을 통해 검색할 수 있는 기능도 존재한다.
깃허브
📖 How to “WineOclock” ?
백엔드가 처음인데 나 혼자?

이전 인문대에서 공대로 코로나 시기에 전과를 한 탓에 같은 같은 전공의 동기랑 친해질 수 있는 기회가 없었고 그래서 프로젝트 시작 전 팀원을 구하는 것부터 애를 먹었다. 그래도 다행히 다른 개발동아리에서 친해진 친구가 자신의 친구를 소개시켜줘서 프론트2명의 친구들과 함께 총 3명이 프로젝트를 진행하게 되었다. 사실 백엔드 역할로서 java/spring 프레임워크 사용은 처음이라 프로젝트 시작 전에 많이 두렵긴했다. 처음인만큼 부딪히고 부딪히고 또 부딪히자 라는 마음가짐으로 시작했고, 부딪히니까 어떻게든 되더라 라는게 이번 프로젝트를 하면서 느꼈다.
프로젝트에서 담당한 기능
앞서 이야기한대로, 백엔드를 맡아 진행했고 java/spring 프레임워크를 사용하여 구현했다.
- 추천 알고리즘 구현 - Python
- Flask Python Web Server - Spring java Web server 통신
- 프로젝트 기능 모든 API 개발
- jwt 를 통한 인증/인가 로그인
- JPA를 이용한 키워드 및 필터링 검색 기능
- 와인 테이스팅 노트 기본적인 CRUD 및 와인 저장 기능
리팩토링 할 부분들
- API 템플릿 추가
- 예외처리
- API 응답속도 확인 및 개선
- 함수 추상화 및 분리
- 폴더 구조 개선
✍️ Look back “WineOclock” !
회고록을 크게 아래 세가지 영역으로 나눠서 작성해려 한다. (GDSC 회고록 작성한 템플릿이 좋아보여 낼름 가져왔다)
- Keep :프로젝트에서 만족했고, 앞으로의 업무에서 지속하고 싶은 부분
- Problem : 프로젝트에서 부정적인 요소로 작용했거나 아쉬웠던 부분
- Try : Problem에 대한 해결 방식으로 다음 프로젝트에서 시도해볼 부분
Keep
[ 에러를 기록하는 습관 ]

모든 에러를 다 적었다고 자부할 순 없지만, 그래도 최대한 에러를 모두 기록하려고 노력했다. 이전 회사에서 인턴 생활을 했을 때 실수 노트를 적었던게 생각이 나서 에러 노트를 적어서 기록했다. 에러 진행여부 (해결 미완, 해결 완), 에러 난이도(별 1개, 3개, 5개), 해당 에러가 발생한 프레임워크를 표시하여 나중에 다시 봤을 때 바로 찾을 수 있게 정리했다.
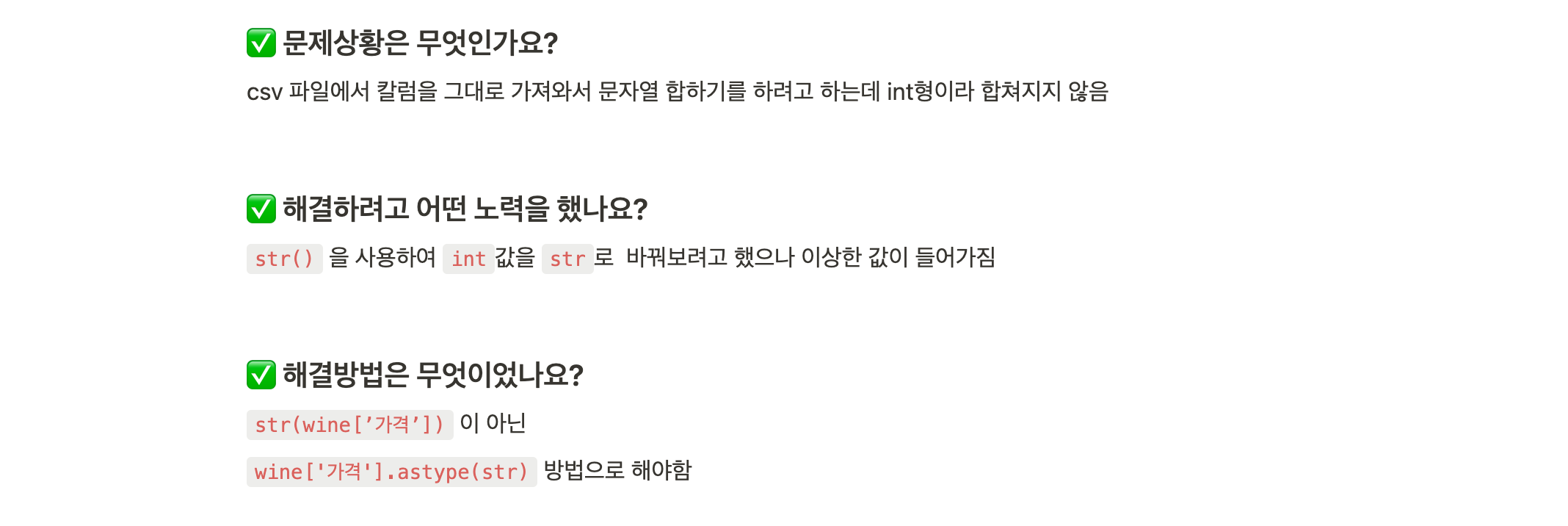
틀이랄건 따로 없고, 내가 적으면서 어떤 것을 적어두면 좋을지 생각해서 3가지 질문을 스스로 던지는 템플릿을 만들어 이용했다. 문제상황은 무엇이었는지, 해결하려고 어떤 노력을 했는지, 마지막으로 해결방법은 무엇이었는지 적었다. 적으면서도 템플릿의 완벽성 여부는 좀 떨어지지만, 프로젝트를 빠르게 진행하면서 금방금방 적긴 편했다. (나중에 뒤로 갈수록 링크만 띡 던지고 가기도 했지만 … )
이 과정을 진행하면서 느꼈던 것은 같은 실수를 생각보다 많이 반복한다 라는 점이다. 분명 이전에 봤던 에러 메세지인 것 같은데 말이지 … 싶어 에러 노트에 가면 어김없이 있다. 같은 실수를 반복하는 바보같은 나이지만 그래도 한 번 에러노트를 적어봐서 그런가 같은 실수를 반복하면 그래도 아니 이 녀석 익숙한 에러인걸 ?! 는 금방 느꼈다. 만약 에러 노트가 없었으면 같은 실수를 반복하고 있음에도 불구하고 또 낯선 에러마냥 어 .. 안녕? 하고 있지 않았을까 싶다.
[ 주석을 통한 설명 ]

기존 지식이 아예 없는 상황에서 코드를 짜다보니까 아무래도 구글링을 통해 이미 짜져있는 코드를 가져와 많이 사용했다. 그래도 다른 코드를 가져와 사용할 때, 단순히 그냥 가져다 쓰는게 아니고 이해하면서 사용하려고 했다. 내가 이해하지 못한 코드는 결국 또 나중에 문제를 일으키고 이해를 못하고 넘어갔기 때문에 결국 또 시간이 소요되는 것을 느꼈다. 처음부터 이해를 하고 코드를 짜는 것이 오히려 시간과 에너지를 아끼는 것이라는 것을 깨달은 것 !
처음에는 노션에다가 해당 개념을 정리하는 방식으로 진행했는데, 배보다 배꼽이 더 커지는 경우가 발생. 한 개념의 이해를 하다가 뒤의 기능 구현들이 밀리기 시작한 것이었다. 아 이렇게 하다간 프로젝트가 천년만년 걸리겠다 싶어 바로바로 주석으로 한줄 코드 정리하는 방법으로 바꿨다. 주석 : 코드 설명, 코드 : 주석 예시 이렇게 되니 바로바로 이해도가 높고, 한 줄로 정리하려고 하니 필요한 핵심 개념만 주석으로 남길 수 있게 되었다.
Problem
[ AWS 배포 실패 ]
이번에 자바/스프링과 파이썬/플라스크 웹 서버 2개를 올렸어야했다. 기존에는 서버 1개 가지고만 프로젝트를 해봤어서 2개를 올려야한다는 생각을 못했다. 그래서 프로젝트 서버인 자바/스프링은 AWS를 통해 배포를 완료했지만 추천 알고리즘을 위한 파이썬/플라스크 웹 서버는 배포하지 못했다. 배포를 하지 못한 것에 대해는 두 가지 이유가 있다.
첫번째는 시간 문제이다. 자바/스프링만 올릴 생각만 한 상태로 배포 기한을 타이트하게 잡았기 때문이다. 하지만 배포 경험이 많지 않아 하나를 올리는데도 꽤나 애먹고 시간이 오래걸려서 타이트한 기한 내에 서버를 두 개 올려서 도메인에 걸어 제대로 된 웹 사이트를 하나 만드는 것을 미리 포기했던 것 같다. 이번 프로젝트의 유일한 아쉬움이 가장 많이 남는 부분이다.
두번째는 비용문제이다. 이미 AWS 서버를 하나 올릴려고 에러를 잡고 노력하는데 비용을 (학생 기준) 꽤나 내고 있어서 하나를 더 서버를 올렸을 때에 값을 감당하기 어려울 것 같았다. (백엔드가 나 혼자라 서버 비용 부담을 나 혼자 내고 있었다…) 백엔드가 한명만 더 있었어도 따로 서로 서버를 올리고 주고받고 했을텐데 변명일 수도 있겟지만 나 혼자로서는 무리라는 판단을 했다.
[ API 설계 ]
백엔드 역할 자체가 처음이라, API 도 처음 만들어봤다. 일단 만드는데 급급해 프론트에게 필요한 데이터들이 무엇인지 물어보고 일단 뚝딱뚝딱 그 데이터들을 만들었는데, 아뿔싸! 데이터 타입은 무엇으로 할지, 데이터 이름은 무엇으로 할지를 전혀 전하지 않고 각자의 역할에 맞춰 구현을 하다보니 결국 기능 구현을 하고도 추가 회의가 필요했다. 다 만들고 나서야 데이터를 정의하니 수정해야할 곳들이 곳곳에 많았고 중간중간 바뀐 네이밍을 바꾸지 못해 발생한 오류를 잡는게 또 시간을 잡아먹었다.
예를 들어, 와인 가격을 처리할 때 1만원대 2만원대 3만원대를 int 형으로 1 2 3으로 처리할지 아니면 String으로 그대로 할지 정하지 못해 이부분에 대한 수정도 많이 필요했으며 와인 아로마를 정의할때 wineAroma1, wineAroma2, wineAroma3 으로 했다가 또 중간에 aroma1, aroma2, aroma3 으로 정의가 되어서 변수명 변경에 대한 혼란도 존재했다. 벡엔드인 내가 방향을 제대로 못 잡으니 다른 프론트 팀원도 같이 흔들렸다. 이때 API를 미리 설계해서 프론트와의 혼란을 줄이는 것이 중요하구나 라고 처음 생각이 들었다.

이미 어느 정도 와인 서비스에 대한 API가 진행되고 있었으나 이후 더 큰 혼란을 방지하기 위해서, 아예 처음부터 다시 API를 설계 방향을 잡았다. 1)데이터 타입과 이름을 정의했고 2)Http Method 정의 3)request 예시 4)response 예시 네가지를 정의했다. 다행히 틀을 잡고 나니 불필요한 추가적인 회의가 필요 없어졌고 각자 맡은 부분에서 개발을 진행하여 마지막에 제대로 데이터를 주고 받는지 확인하는 단계만 확인하면 되었다.
이후 틀을 잡은 것도 부족하기 그지없지만 처음부터 API를 잡았으면 좀 더 빠르게 개발을 진행할 수 있었을텐데 그러지 못해 아쉬웠고, 후에 다 개발을 하고 나니 다시 공통응답 API 및 에러처리 API 를 알게되어서 이 부분을 시도해보지 못해 아쉬웠다. 그래도 현재 리팩토링을 통해서 공통 응답 API와 에러 처리 API를 구현하고 있다. 아직까지 부족한 부분들이 많지만 이렇게 하나씩 채워나가는게 아닐까 생각한다.
[ 집 나간 테스트 코드, 예외처리는 저멀리 ]

우리가 서비스를 구동하면, 사실 원하는 방향대로 흘러가지 않는 경우가 허다하다. 하지만 이번 프로젝트는 ‘사용자가 우리가 예상한대로 행동할 것이다’ 라는 것을 전제로 프로젝트를 완성을 했다. 아니 이런 경우는 완성을 했다고 할 수 있는 것일까? 그렇다보니 테스트 디렉터리 같은 경우는 빈 디렉터리만이 나를 반겨주고 있다.
데이터베이스에 존재하지 않는 데이터를 조회하려고 할 때, 추천 알고리즘에서 존재하지 않는 와인 정보가 들어왔을때 등의 수많은 예외를 처리해주지 않았고, 최소한의 예외를 무마하기 위해서 프론트 단에서 형식에 맞지 않은 입력을 넣었을 때에 모달창이 떠서 입력되지 않는 입력예외만 두었다.
즉, 500에러 예외처리를 해놓지 않고 400에러만 장독대에 난 구멍을 두꺼비로 막아둔 정도랄까 … 예외처리를 따로 두지 않으니 API 설계를 했던 것도 결국 데이터 타입만 필요하고, 응답코드나 메세지 등은 필요가 없었다.
실제로 졸업 전시회를 할 때, 이 예외처리에 대한 중요성을 알게 되었다. 실제 사용자들에게 이용할 수 있도록 했을 때 추천 알고리즘이 제대로 적용되지 않거나 결과가 제대로 나오지 않는 상황들이 발생한 것. 근데 사용자가 보이는 서비스 화면에서는 아무 문제가 없었고, 서버로 들어가 로그를 보면 에러가 발생해있었다. 해당 에러를 잡으려고 해도 명확히 어느 부분에서 에러를 발생하는지 보지 않고 대강 수습하기 바빴던 것 같다. 테스트 코드로 테스트를 하면서 진행했으면 좀 더 명확하게 어느 부분이, 어떠한 에러로 났는지 확인이 가능하고 그것에 따라 예외처리를 했을지도 모르겠다.
Try
[ 리팩토링을 염두하되, 하지 않으면 좋을 수 있게 ! ]

코드를 짜면서 ‘클린코드는 나중에 리팩토링으로, 테스트 코드는 나중에 리팩토링으로, 이 기능은 나중에 리팩토링으로 …’ 실제로 프로젝트하면서 내가 스스로 생각한 부분들이다. 지금 생각해보면 스스로 회피하기 위한 변명에 지나치지 않는다. “기한 내 프로젝트를 ‘최소한’ 을 완성하기 위해서 ‘최대한’을 포기하는 것이다” 라고 생각했지만 여기저기 기능적인 부분에서 구멍도 많이 뚫렸다.
하드코딩하는 부분들도 많고, 객체지향원칙을 어기는 것인 것을 알면서도 구현했던 부분들이 명백히 존재한다. 또한 재사용할 여지가 있는 코드들임에도 불구하고 분리하지 않고 중복해서 그대로 사용했다. 특히 최소한을 구현하기 위해 예외처리는 위에 말했던 것처럼 저멀리 날아가버렸다.
너무 리팩토링에 의존적으로 프로젝트를 진행했던 것 같은데, 의존적으로 리팩토링에 코드를 맡기는 것이 아닌 이왕 기능을 구현할 때 리팩토링을 하지 않아도 되는 코드를 만들려고 노력해야할 것 같다. 테스트 코드를 통해서 문제가 발생하는 부분을 명확히 하여 예외처리 기능도 바로 처리하고, 중복되는 부분들이 발생하면 함수로 따로 분리하여 재사용성을 높여 나중에 리팩토링은 ‘수정’이 아닌 ‘확장’의 개념으로 다가갈 수 있도록 할 것이다.
[ 협업 툴도 중요하다 ]
제대로 백엔드와 프론트를 나눠 프로젝트를 진행한 것이 처음이라 협업 툴에 대한 중요성은 많이 못 느꼈었다. 하지만 이번 프로젝트를 진행하면서 협업 툴로 노션과 슬랙을 사용했는데, 생각보다 소통에 유용하게 사용하지 못해 아쉬움이 남는다.
그나마 백엔드가 나 혼자라서 내가 발생시킨 에러는 나 혼자 해결하면 되긴 했었는데, 이게 만약 백엔드를 2명이상 맡아 진행하게 된다면 에러나 에러 해결방법, 진행 상황에 대한 더욱 구체적인 협업 툴이 필요하다고 생각이 들었다. 특히 이번에 프론트와 소통하면서 카톡, 슬랙으로만 대강 어디까지 진행했는지 서로 물어보고 대답하는 식으로 진행했는데, 묻지 않아도 툴에서 바로바로 서로 진행되고 있는 부분, 막힌 부분을 확인하여 파트 간 소통을 원활하게 하면 좋을 것 같다.
JIRA 협업 툴에 대한 이야기를 종종 들었어서 다음 프로젝트 때는 해당 툴을 이용해서 버그 및 이슈 추적, 프로젝트 형상 관리를 하며 파트 간 원활하게 소통을 해보려고 한다.
[ 개발에 필요한 기본적 이론 공부를 채우자 ]
스프링 프레임워크를 처음 프로젝트에 적용하기 전에 기본적인 스프링 공부 (갓영한 선생님의 스프링 루트)를 끝냈지만, 여전히 너무나도 많이 부족한 부분들이 많았다. 부딪히면서 많이 배우고, 이론공부 100간 하는 것보다 실습으로 10시간 투자하는게 더 금방 배울 수 있는 것도 맞지만, 이론이 적당히 채워져야 그것도 의미있다는 것을 깨달았다.
한 기능을 구현하기 위해 하나의 길을 오래 가는 것은 상관없는데, 자꾸 5가지의 길을 가고 나서야 정답을 향한 길을 찾은 것은 조금 너무 불필요한 행위들인 것 같다. 적어도 2가지의 길로 좁힐 수 있는 것이 이론 공부인 것 같다. 막힌 길로 가는 것만큼 멍청한게 없을 것이다. 이론 공부를 하면 아 저기로 가면 끝엔 막히겠네 혹은 중간에 함정이 있겠다는 예상할 수 있을 것이고 프로젝트를 하면서 불필요한 코드 구현을 방지할 수 있을 것이다.
해당 프로젝트 로그인 구현에서 기본적인 이론이 없는 상태로 spring security 와 jwt를 통해 로그인을 시도했다가 된통 당한 경험이 있다. 우선 spring security에서 기본적으로 제공하는 인증방식이 존재하는지 몰라서 쓰고 싶지 않은데 자꾸 떠서 시간을 많이 잡아먹었다. 나중에서야 formLogin().disable() 코드를 추가하면 된다는 간단한 사실을 알게 되었다. 이것도 하나의 예시일뿐 … 로그인은 계속해서 위와 같은 헛발질의 연속이었다. 덕분에 이번 프로젝트하면서 로그인 구현에 가장 많은 시간을 쓰지 않았나 싶다… (가장 멘탈이 많이 나가던 시점이기도 하다)
적어도 내가 구현하려고 하는 것에 대한 기본적인 이론 지식은 갖고 있어야 1단계의 문제도 1단계로 해결할 수 있구나 라고 생각을 했다.
💡 What did you learn in Project?
기술 능력 향상
기술실력 향상은 기본적으로 깔고 가는 것 같다. 특히 이번에 백엔드를 혼자 맡으면서 모든 기술 기능 구현을 내가 맡아 진행해서 더욱 그런 것 같기도 하다. 이번에 프로젝트를 하면서, 스프링을 단순히 강의나 책을 통해서 배웠던 것과는 다른 새로운 부분들을 알게 되고 실제로 바로 적용해보면서 기술적인 실력이 많이 늘었다.
실제로 디렉토리를 어떻게 구성할지에 대한 고민을 통해 애플리케이션 별로 디렉토리도 나눠보고 Spring Batch 프로그램을 통해 애플리케이션이 실행될 때 자동으로 csv 파일이 데이터베이스에 들어가도록도 해봤다. 또한 JPA에서 단순히 findAll()이나 findById() 등이 아닌 키워드 검색에서 해당 키워드가 들어간 와인 데이터를 찾기 위해 like를 사용하는 구문인 findByWineNameContaining 도 새로 배워 적용해봤다.
하지만 확실히 이론적 공부를 바탕으로 적용한 것에 비해 구멍이 많아서, 배운 것을 구멍있는 상태로 두는 것이 아닌 메꾸기 위한 추가적인 작업이 필요할 것 같다.
이해를 통한 실수 방지
이론으로 공부했던 것들을 단순히 ‘암기’했다가 이번 프로젝트에서 실수하는 과정을 통해 단순히 암기가 아닌 이해가 되면서 더이상 실수를 하지 않게 되었다.
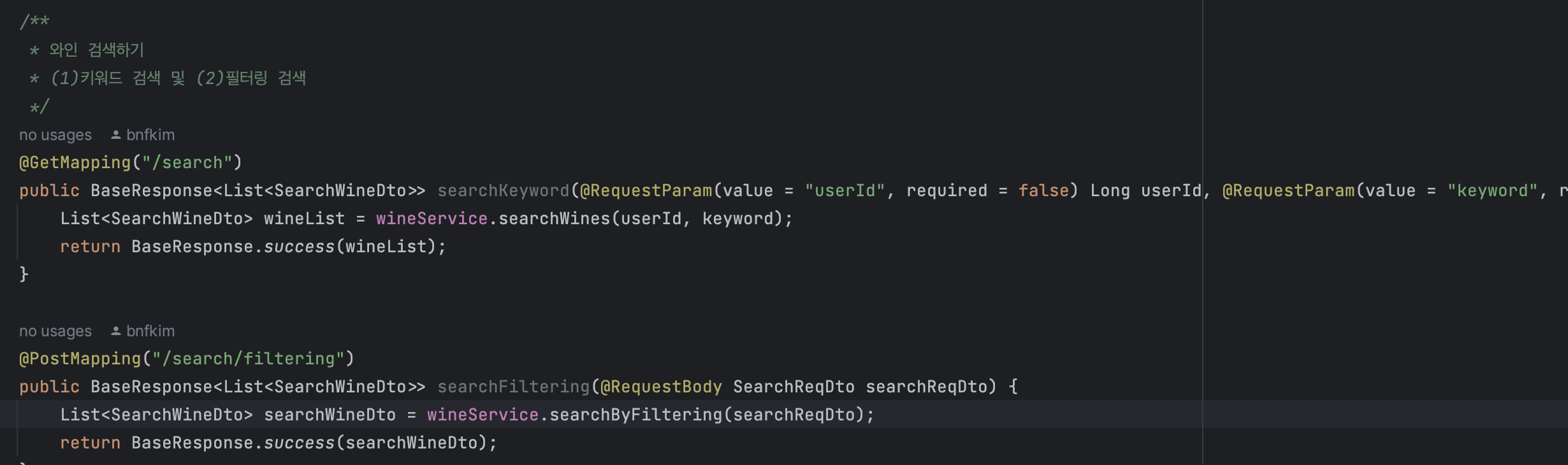
예를 들면, 단순히 Http method에 대한 내용을 이론적으로 공부했다가 실제로 적용하면서, @RequestBody 어노테이션으로 받기 위해서는 무조건 POST 형식을 사용해야한다는 것을 알게 되었다. 검색 기능해서 키워드 검색과 필터링 검색이 있는데 키워드 검색과 같은 경우, 키워드 1개만 받으면 되어서 @RequestParam 을 사용하고 필터링 검색은 여러 데이터를 받아야해서 @RequestBody를 사용했는데 둘 다 GET 형식으로 했더니 필터링 검색에서 문제가 발생했다. 단순히 공부했을 때는 그렇구나~ 하고 넘겨서 잊어버렸던 부분을 실제 코드에 적용해보면서 암기가 아닌 자연스럽게 이해할 수 있게되었다.

두 번째 예시는, @Autowired 를 이용한 필드 주입방식과 @RequiredArgsConstructor를 사용한 생성자 주입 두 가지를 배웠는데, @RequiredArgsConstructor를 사용하면서 final 접근자를 붙여주지 않아 null 에러를 마주한 경험이 있다. 단순히 생성자 주입 방식에 대해 암기했다가 제대로 이해하지 않아 생겼던 문제였다. 그 이후에는 @RequiredArgsConstructor를 사용한 경우엥는 칼같이 final을 붙여서 같은 실수를 반복하지 않았다.
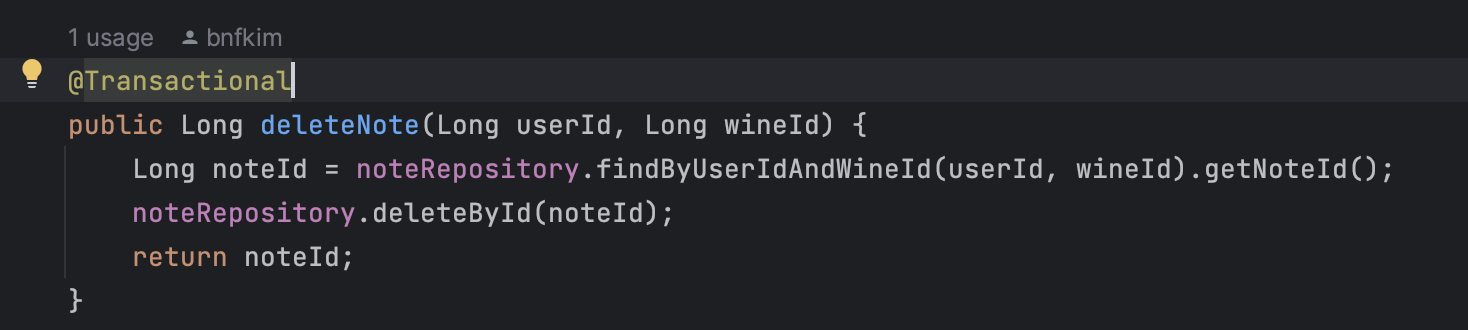
세 번째 예시는, 이전에는 왜 @Transactional 어노테이션을 사용하는지 몰랐는데 한 번 @Transactional 어노테이션이 없는 CRUD API를 만들었다가 서버와 데이터베이스 사이 데이터 불일치 문제를 실제로 보게되면서 @Transactional 어노테이션의 중요성에 대해서 알게 되었다.
모르는 것과 배우는 것을 두려워하지 않는 태도

프로젝트를 하면서 모르는 것 투성이었다. jwt를 이용해서 로그인 하는 방법도 모르겠고, 추천 알고리즘도 처음 사용해봤고, 추천 알고리즘을 위한 파이선 웹 서버로 플라스크도 처음 사용해보고, 결국 마지막에 사용하지 않았지만 인스타그램 크롤링을 위한 셀레니움도 처음 사용해봤다.
몰라서 하지 않았다고 하면 이렇게 다채로운 웹 서비스를 만들지 못했을 것이다. 기능을 기획하고 그 기획을 실제로 구현하기 위해서 검색하고 이해하고 공부하고 적용하고 수정하는 작업들을 걸쳐 결국은 해낼 수 있었다. 이러한 과정을 끊임없이 거치면서 내가 모르는 부분을 분명히 마주할 수 있었고, 부족한 부분을 채우기 위해 배우는 것을 두려워하지 않았다. 이전에는 좀 수동적인 공부를 했다면 이번 프로젝트를 통해서 능동적인 태도로 지식을 습득하는 법을 배우게 된 것 같다.
백엔드에 대한 확신
이전 웹 프로젝트를 했을 때는 프론트와 디자인(사실 프론트라고 하기엔 민망한게 html/css/js 만 사용했기때문)를 맡았는데 나쁘진 않지만 그냥 그랬다. 그러다 백엔드 공부를 하면서 재미를 느꼈고 이번 프로젝트를 통해서 확실하게 백엔드 직무로 결정을 할 수 있는 계기가 되었다.
전반벅인 아키텍처를 기획하고, API를 설계하여 만들고, 데이터베이스를 구성하여 데이터를 어떻게 저장하고 사용할 것인지 고민하고, 응답속도 개선에 대한 고민을 하는 시간들이 즐거웠다. 비단 백엔드가 이 역할만 하는 것은 아닐 것이고 실제 협업에 들어가면 더 엄청난 일들이 주어져 내가 맛보지 못한 일들을 하면서 힘들 수도 있지만 … 전반적인 구도를 이해하고 설계를 하고 로직을 짠다는 것을 너무나 멋있고 즐거운 일인 것 같다.

가볍게 회고록 써봐야 했던 것이 .. 어느새 만자가 넘어가 버렸다. 장장 3일에 걸쳐 회고록을 완성했다. 오히려 그만큼 이 프로젝트에 진심이었고, 많은 것을 도전하고 배워서 더 하고 싶은 말도 많았을 것이라 생각하기로 했다.
현재는 느리지만 조금씩 백엔드 프로젝트 리팩토링 과정에 있고 조금 더 클린코드를 만들어보고 다시 배포에 도전하여 실사용자를 모아보는 것까지 목표로 하고 있다. 이번 프로젝트가 힘들지만 재미있었어서 다른 프로젝트도 한번 도전해보고 싶다.
