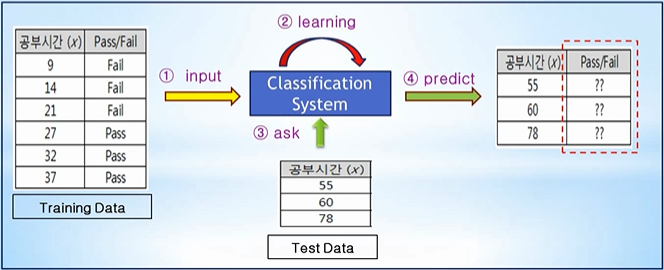
분류 (Classification)
Training Data 특성과 관계 등을 파악한 후에,
미지의 입력 데이터에 대해서 결과가 어떤 종류의 값으로 분류될 수 있는지를 예측
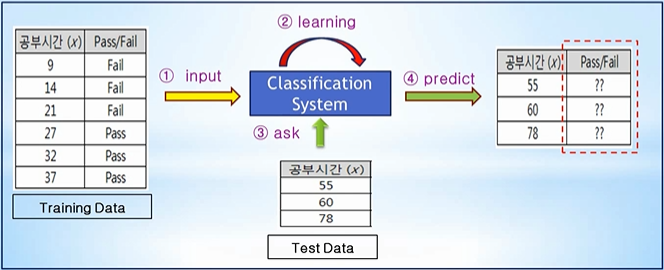
앞선 Regression은 결과(t) 값 또한 연속적인 값으로 입력 받았으나 Classification은 입력 값은 연속적인 데이터지만 출력 값은 0과 1의 값을 예측해주는 시스템입니다.

즉, Logistic Regression 알고리즘은,
- Training Data 특성과 분포를 나타내는 최적의 직선을 찾고 (Linear Regression)
- 그 직선을 기준으로 데이터를 분류(Classification)해주는 알고리즘입니다.
- sigmoid function

분류(Classification) 시스템에서 출력 값 y를 1 또는 0 만을 가지므로, 함수 값으로 0~1 사이 값을 갖는 sigmoid 함수를 사용할 수 있습니다.
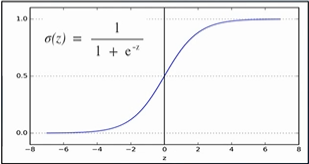
=> sigmoid 계산 값이 0.5보다 크면 결과로 1이 나올 확률이 높음
=> sigmoid 계산 값이 0.5보다 작으면 결과로 0이 나올 확률이 높음
- 손실함수(loss funtion), W, b
Linear Regression (y)과 sigmoid (1 or 0)에 의한 최종 출력 값이 다르기 때문에 다른 손실함수가 필요합니다.
- cross-entropy 유도
- 입력 x에 대해 출력이 1일 확률을 y로 정의합니다.
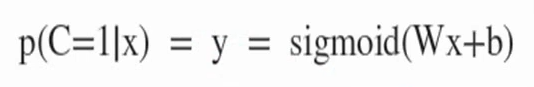
- 입력 x에 대한 출력이 0일 확률은 1 - y입니다.
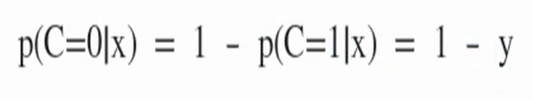
3. 출력(확률변수 C)이 1 혹은 0 이기 때문에 다음처럼 정의 가능합니다.

- 각 입력 데이터의 발생 확률을 모두 곱하여 우도 함수를 정의합니다.

- 함수의 최대값을 알기위해서 편미분 하는 과정을 간략화하기 위해 log를 취하며, 파라미터 최적화를 위해 최소값을 구하는게 일반적이므로 부호를 바꾼 형태로 손실함수를 정의합니다.

- Classification에서 [W, b] 계산 과정
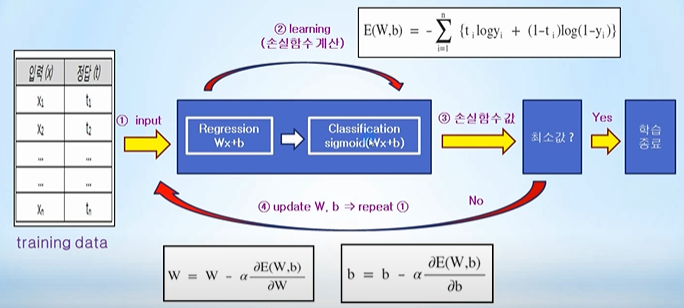
Classification 프로세스를 리뷰해보자면 임의의 직선 Wx +b를 가정한 후에, Training Data를 이용하여 Linear Regression을 수행하고 그 결과값을 sigmoid 함수에 입력하여 0과 1사이의 값 y를 출력합니다.
출력된 y를 이용하여 손실함수(cross-entropy) 값을 계산하고 최소값인지 확인합니다.
최소값이 아니라면 수치 미분을 이용하여 W와 b를 업데이트하는 과정을 반복하여 다시 손실함수 값이 최소값을 찾는 과정이 반복됩니다.
출처 : 유튜브 NeoWizard 채널 머신러닝/딥러닝 강의
