python으로 구현하는 CNI Plugin - pynet
1. 프로젝트 동기: CNI란 무엇인가
Kubernetes를 사용하면서 CNI라는 말을 자주 접해왔지만 저에게 CNI란 단순히 "쿠버네티스에서 Pod 간 통신을 위해 필요한 것" 정도로 추상적인 개념이었습니다. 또한 업무를 하면서 CNI가 문제가 된 적이 많지 않았고, 컨테이너 네트워크를 직접 설정해본 경험도 없었습니다. 그러다 보니 아래와 같은 단순한 질문도 생소하게 느껴졌습니다.
- 컨테이너 네트워크 설정이 무엇이고, 구체적으로 뭘하는건지?
- Pod의 네트워크 구성이 무엇이고, 어떻게 하는건지?
- Pod IP를 할당하는 것은 왜하는거고, 구체적으로 어떻게하는건지?
위 설정들은 제 쿠버네티스의 CNI plugin이 알아서 해주는 기능이기 때문에, 역설적으로 저에게는 생소한 내용이었습니다.
쿠버네티스 패턴 스터디를 하면서, 당연하게 생각했던 쿠버네티스의 동작들이 사실은 정교한 설계와 철학을 기반으로 하고 있었다는 것을 많이 느꼈습니다. 그래서 CNI가 무엇이고, CNI plugin은 무슨 일을, 어떻게, 왜 하는지 알고 싶었습니다.
Kubernetes에서 최소한의 Pod 네트워킹을 동작시키는 CNI plugin을 만들어보면, 그 과정에서 자연스럽게 이해할 수 있을 것이라고 판단했습니다.
2. 프로젝트 요약: pynet
무슨 프로젝트인가
pynet은 kindnet의 핵심 기능을 Python으로 재구현한 프로젝트입니다.
kindnet은 kind(로컬 Kubernetes 클러스터 설치 도구)에서 기본으로 쓰이는 CNI 플러그인으로, 코드가 비교적 작고 구조가 깔끔합니다. Go로 작성되어 있지만 그 덕분에 Python으로 거의 1:1 대응해서 옮길 수 있었습니다.
pynet에서는 웹 대시보드를 추가해, CNI가 컨테이너 네트워크를 어떻게 구성하는지 브라우저에서 직접 볼 수 있게 했습니다. veth pair, routing table, IP 할당 현황, nftables 규칙까지 노드별로 실시간으로 확인할 수 있습니다.
진행 순서
- CNI 관련 개념 이해 — CNI 명세, 네트워크 네임스페이스, veth, nftables 등
- kindnet 이해 — Go 코드를 읽으며 전체 흐름 파악
- pynet 구현 — cni-pynet(CNI 플러그인) + pynetd(데몬) 구현
- pynet-web 구현 — 웹 대시보드 추가
3. 관련 CS 개념
CNI가 왜 필요한가? - 컨테이너 네트워크 설정의 표준화
CNI (Container Runtime Interface)는 말 그대로, 컨테이너 네트워크에 대한 표준 인터페이스입니다. 이런 표준이 왜 만들어졌는지는 공식 문서에 잘 나와 있습니다.
"networking is not well addressed as it is highly environment-specific ... it is prudent to define a common interface between the network plugins and container execution"
Problem
컨테이너 네트워크 구현 방식은 운영 환경에 따라 매우 다양합니다.
- 온프레미스 환경: 물리 네트워크와 직접 라우팅하는 BGP 기반 네트워크 (Calico)
- 클라우드 환경: VPC와 같은 클라우드 네트워크와 연동 필요 (AWS VPC CNI)
- 멀티 노드 환경: VXLAN 기반 overlay 네트워크 사용 필요 (Flannel)
운영 환경마다 네트워크 구현이 다르면, 컨테이너 런타임(또는 orchestrator)에서 반복적인 수정이 필요해지고 비슷한 구현을 계속 반복하게 됩니다.
Solution
- 역할 분리: 컨테이너 네트워크 구성은 네트워크 플러그인이 담당합니다. 컨테이너 런타임은 컨테이너 실행에만 집중하고 네트워크 플러그인을 실행.
- (+) 네트워크 구현은 플러그인 형태로 쉽게 교체 가능합니다.
- 표준화: 컨테이너 런타임과 네트워크 플러그인 사이의 공통 인터페이스를 정의합니다.
- ex) 플러그인은 바이너리 형태이며 컨테이너 런타임이 직접 실행
- ex) 컨테이너 런타임은 네트워크 설정에 관한 환경변수와 JSON config를 플러그인에 전달
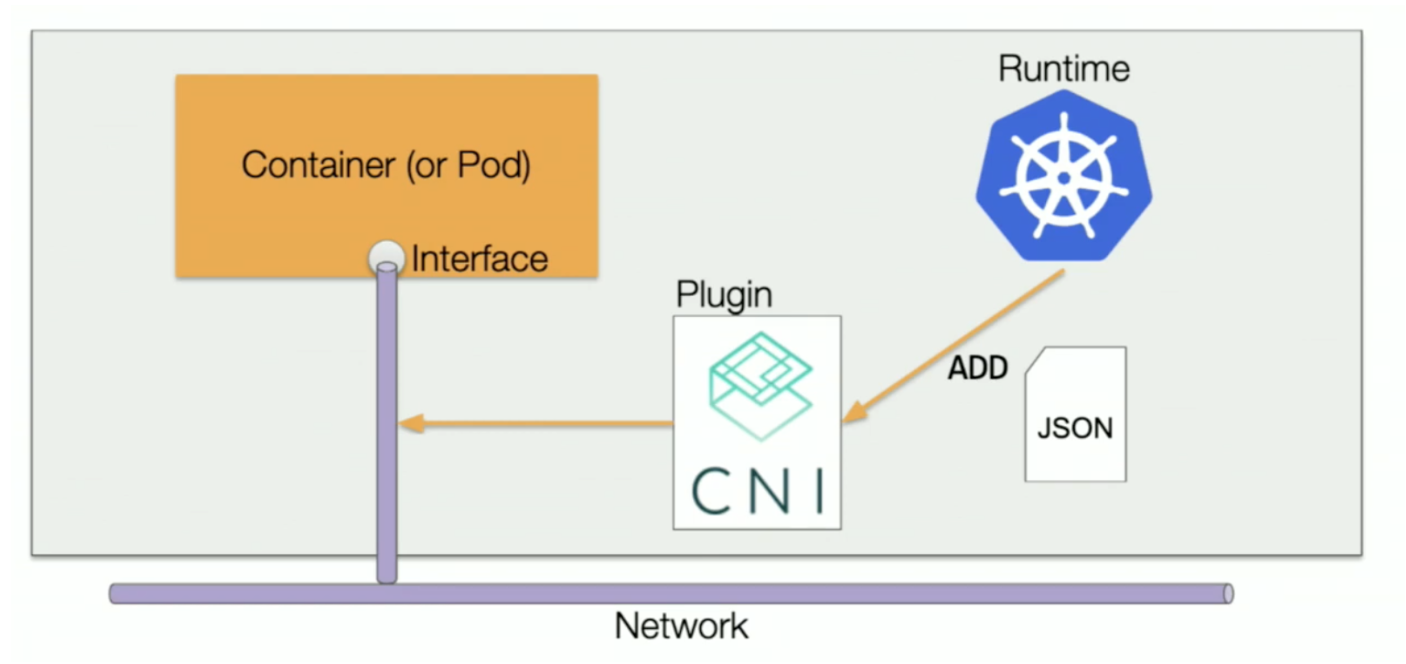
CNI와 CNI 플러그인
CNI(Container Network Interface)는 컨테이너 런타임과 네트워크 플러그인 사이의 표준 인터페이스입니다. 사양 자체는 단순합니다.
CNI 플러그인은 CNI의 구현체로, 실제 컨테이너 네트워크를 구성하는 프로그램. 컨테이너 런타임이 Pod를 생성하거나/삭제할 때 해당 바이너리를 직접 실행합니다. 통신 방식은 다음과 같습니다.
kubelet/containerd
├── 환경변수 설정 (CNI_COMMAND=ADD, CNI_CONTAINERID=..., CNI_NETNS=...)
├── stdin에 JSON 설정 전달
└── 바이너리 실행
├── stdout: 결과 JSON (ADD 성공 시, IP/인터페이스 정보)
├── stderr: 에러 JSON (실패 시)
└── exit: 0(성공) / 1(실패)CNI_COMMAND는 네 가지입니다.
| 명령 | 동작 |
|---|---|
ADD | 컨테이너에 네트워크 연결 — IP 할당, veth 생성, 라우팅 설정 |
DEL | 컨테이너 네트워크 해제 — veth 삭제, IP 반환 |
CHECK | 현재 네트워크 상태가 기대대로인지 확인 |
VERSION | 플러그인이 지원하는 CNI 버전 목록 반환 |
네트워크 네임스페이스
Linux의 네임스페이스 기능 중 하나입니다. 각 컨테이너는 독립적인 네트워크 네임스페이스를 가지고, 그 안에서는 자신만의 네트워크 인터페이스, 라우팅 테이블, iptables 규칙이 존재합니다.
CNI ADD가 하는 일의 핵심은 두 개의 네트워크 네임스페이스(host, container)를 veth pair로 연결하는 것입니다. veth는 두 끝이 항상 쌍으로 붙어있는 가상 이더넷 케이블입니다. 한쪽으로 들어온 패킷은 반드시 반대쪽으로 나옵니다.
[ Host Network Namespace ] [ Container Network Namespace ]
vnetXXXXXX ←──── veth pair ────→ eth0
addr: gw/32 addr: ip/324. pynet 소개
구성 요소
pynet/
├── cni-pynet/ # CNI 플러그인 바이너리 (kubelet이 매 Pod ADD/DEL마다 호출)
│ └── src/
│ ├── main.py # ADD/DEL/CHECK/VERSION 핸들러
│ ├── ipam.py # IP 주소 관리 (SQLite)
│ ├── netdev.py # veth pair 생성/삭제 (pyroute2)
│ ├── portmap.py # 포트 매핑 (nftables DNAT)
│ └── db.py # SQLite 상태 저장소
│
└── pynetd/ # DaemonSet 데몬 (장기 실행)
└── src/
├── main.py # 노드 watch 루프 + masquerade 에이전트
├── cni.py # CNI config 파일 작성
├── routes.py # 노드 간 pod CIDR 라우트 관리 (pyroute2)
├── masq.py # IP masquerade 규칙 관리 (nftables)
└── web.py # 웹 대시보드 (Flask)cni-pynet은 일회성 바이너리입니다. kubelet이 Pod를 만들 때마다 실행되고 종료됩니다. PyInstaller로 단일 실행파일로 컴파일해 /opt/cni/bin/에 배포합니다.
pynetd는 각 노드에서 DaemonSet으로 항상 실행 중인 데몬입니다. Kubernetes API를 watch하면서 두 가지 역할을 합니다.
- 노드 컨트롤러: 노드 추가/삭제/변경을 감지해 CNI config 파일 갱신, 다른 노드로 가는 라우트 동기화
- masquerade 에이전트: nftables에 IP masquerade 규칙 동기화 (pod → 외부 트래픽 SNAT)
kind에 적용시, 아래와 같이 cni-pynet 바이너리와 pynet daemonset을 확인할 수 있습니다.
> docker exec kind-control-plane ls /opt/cni/bin
cni-pynet
host-local
loopback
portmap
ptp
> k get daemonset -n kube-system
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
kube-proxy 2 2 2 2 2 kubernetes.io/os=linux 49m
pynet 2 2 2 2 2 <none> 48m네트워크 구성 방식
pynet은 kindnet의 네트워크 구성 방식을 그대로 따릅니다.
같은 노드의 pod 간 통신
pynet은 브리지를 만들지 않습니다. pod가 추가될 때마다 커널 라우팅 테이블에 /32 host route 하나를 추가합니다. "이 pod IP는 이 veth로 직접 보내라"는 L3 규칙입니다.
[ pynet 방식 (bridgeless L3) ]
Host Network Namespace
┌─────────────────────────────────────────────────────────┐
│ │
│ Routing Table │
│ ┌──────────────────────────────────────────────────┐ │
│ │ 10.244.0.5/32 dev vnetAAA scope host │ │
│ │ 10.244.0.7/32 dev vnetBBB scope host │ │
│ └──────────────────────────────────────────────────┘ │
│ │ │ │
│ vnetAAA vnetBBB │
└──────────────┼───────────────────────┼─────────────────┘
│ │
┌──────┴──────┐ ┌──────┴──────┐
│ pod-a NS │ │ pod-b NS │
│ eth0 │ │ eth0 │
│ 10.244.0.5 │ │ 10.244.0.7 │
└─────────────┘ └─────────────┘pod-a → pod-b로 패킷을 보내면, 커널은 라우팅 테이블에서 10.244.0.7/32 → vnetBBB를 찾아 직접 전달합니다. 브리지를 거치지 않습니다.
다른 노드의 pod 간 통신
같은 노드 안에서는 /32 host route로 해결되지만, 다른 노드의 pod로 가는 트래픽은 물리 네트워크를 건너야 합니다. pynetd가 이를 담당합니다.
[ Node 1 (172.18.0.2) ] [ Node 2 (172.18.0.3) ]
Routing Table Routing Table
┌────────────────────────────┐ ┌────────────────────────────┐
│ 10.244.0.5/32 dev vnetAAA │ │ 10.244.1.3/32 dev vnetCCC │
│ 10.244.1.0/24 via 172.18.0.3 ─────────▶ (eth0 수신 후 라우팅) │
└────────────────────────────┘ └────────────────────────────┘pynetd는 K8s API로 다른 노드의 pod CIDR(10.244.1.0/24)을 감지하면, 그 노드의 IP(172.18.0.3)를 게이트웨이로 하는 라우트를 추가합니다. Node 1에서 10.244.1.x로 가는 패킷은 Node 2의 eth0으로 전달되고, Node 2의 /32 라우트가 최종 pod까지 연결합니다.
핵심 코드
cmd_add(): Pod 네트워크 설정의 진입점
CNI_COMMAND=ADD가 들어오면 cmd_add()가 호출됩니다. 이 함수 하나가 Pod 네트워크 설정의 전체 흐름을 담당합니다.
def cmd_add(args, conf):
# 1. IP 범위 등록 (CNI config의 ranges → DB)
create_ip_ranges(conf["ranges"])
# 2. Pod 레코드 먼저 생성 (IP 없이)
write_pod_without_ip(container_id, pod_name, pod_ns, netns, host_iface, mtu)
# 3. IPAM: IP 할당
ip, gateway = get_ip_config(container_id)
# 4. veth pair 생성 + IP 주소 + 라우팅
create_pod_interface(netns, host_iface, ifname, ip, gateway, mtu, ...)
# 5. CNI 결과 출력 (stdout → containerd가 수신)
print(json.dumps({
"cniVersion": "0.4.0",
"interfaces": [{"name": host_iface}, {"name": ifname, "sandbox": netns}],
"ips": [{"version": "4", "address": f"{ip}/32", "gateway": gateway}],
}))순서가 중요합니다. IP를 먼저 할당하고 veth를 만드는 게 아니라, Pod 레코드를 먼저 DB에 기록한 뒤 IP를 할당합니다. 할당 실패 시 롤백할 레코드가 있어야 하기 때문입니다.
create_pod_interface(): 실제 네트워크 연결
CNI ADD에서 가장 핵심적인 함수입니다. host namespace와 container namespace 양쪽에 인터페이스를 설정하고 커널 라우팅 테이블을 구성합니다.
[Host Namespace]
1. veth pair 생성 (vnetXXX ↔ eth0)
2. eth0 쪽을 container namespace로 이동
3. vnetXXX: UP, MTU, ifalias 설정
4. vnetXXX에 gateway IP 부여 (/32)
5. "pod_ip/32 → vnetXXX scope host" 라우트 추가
[Container Namespace] ← setns syscall로 진입
6. lo 인터페이스 UP
7. eth0: UP, MTU 설정
8. eth0에 pod IP 부여 (/32)
9. "gateway/32 scope link" 라우트 추가 ← gateway 직접 도달 가능
10. "0.0.0.0/0 via gateway" 기본 라우트 추가5번의 /32 scope host 라우트가 pynet의 핵심입니다. 커널에 "이 pod IP는 이 veth로 직접 보내라"고 알려주는 역할로, 브리지 없이 pod 간 통신이 가능한 이유입니다.
_in_netns(): 네트워크 네임스페이스 전환
container namespace 안에서 작업하려면 프로세스의 network namespace를 일시적으로 바꿔야 합니다. setns syscall을 직접 호출하는 컨텍스트 매니저로 구현했습니다.
@contextlib.contextmanager
def _in_netns(netns_path: str):
host_fd = os.open("/proc/self/ns/net", os.O_RDONLY) # 현재 NS 저장
ns_fd = os.open(netns_path, os.O_RDONLY)
_libc.setns(ns_fd, CLONE_NEWNET) # container NS로 진입
try:
yield
finally:
_libc.setns(host_fd, CLONE_NEWNET) # 반드시 host NS 복원try/finally로 복원을 보장하는 것이 중요합니다. NS 복원에 실패하면 이후 모든 네트워크 작업이 잘못된 namespace에서 실행됩니다.
IPAM: SQLite로 IP 주소 관리
IP 주소 관리(IPAM)는 SQLite DB로 구현했습니다. CIDR 범위를 ipam_ranges 테이블에 등록하고, pod가 추가될 때마다 pods 테이블에서 미사용 IP를 선택해 할당합니다.
def get_ip_config(container_id: str) -> tuple[str, str]:
# pods 테이블의 레코드를 기반으로 이미 할당된 IP 집합 파악
# ipam_ranges에서 CIDR을 읽어 미사용 IP 선택
# pods 테이블 UPDATE (ip_address_v4, ip_gateway_v4)
return ip, gatewaygateway는 host-side veth에 부여하는 IP입니다. container에서 보면 자신의 기본 라우트(0.0.0.0/0 via gateway)의 대상이고, host에서 보면 pod IP로 가는 /32 라우트의 출발지입니다.
웹 대시보드 (web.py)
Flask로 각 노드에 :9090 HTTP 서버를 올립니다. /api/all은 K8s API로 전체 노드 IP를 조회한 뒤 각 노드의 /api/data를 병렬로 fetch해 집계합니다.
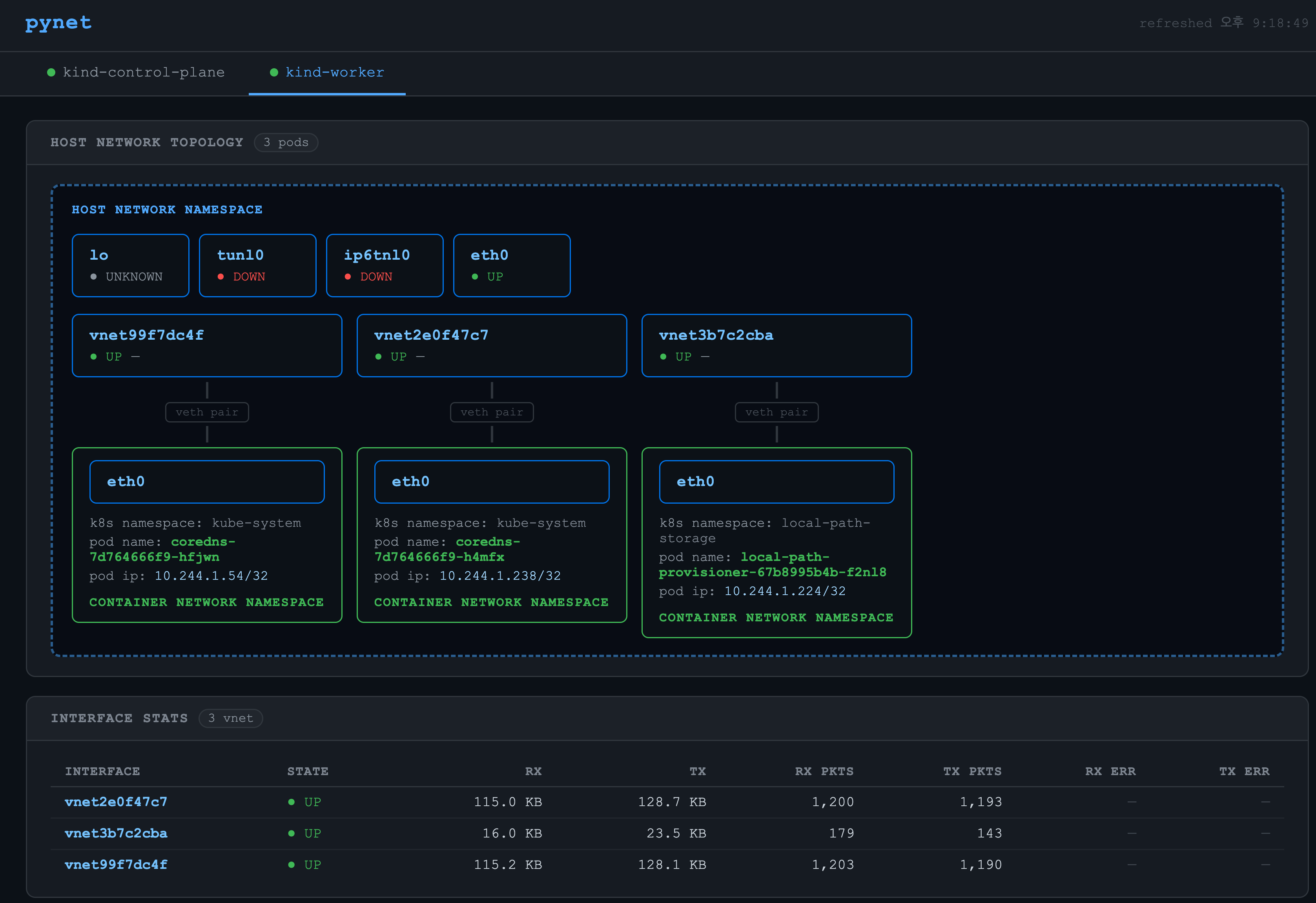
대시보드에서 보여주는 카드들:
- Host Network Topology: veth ↔ pod 연결 관계를 시각화합니다. 라우팅 테이블(
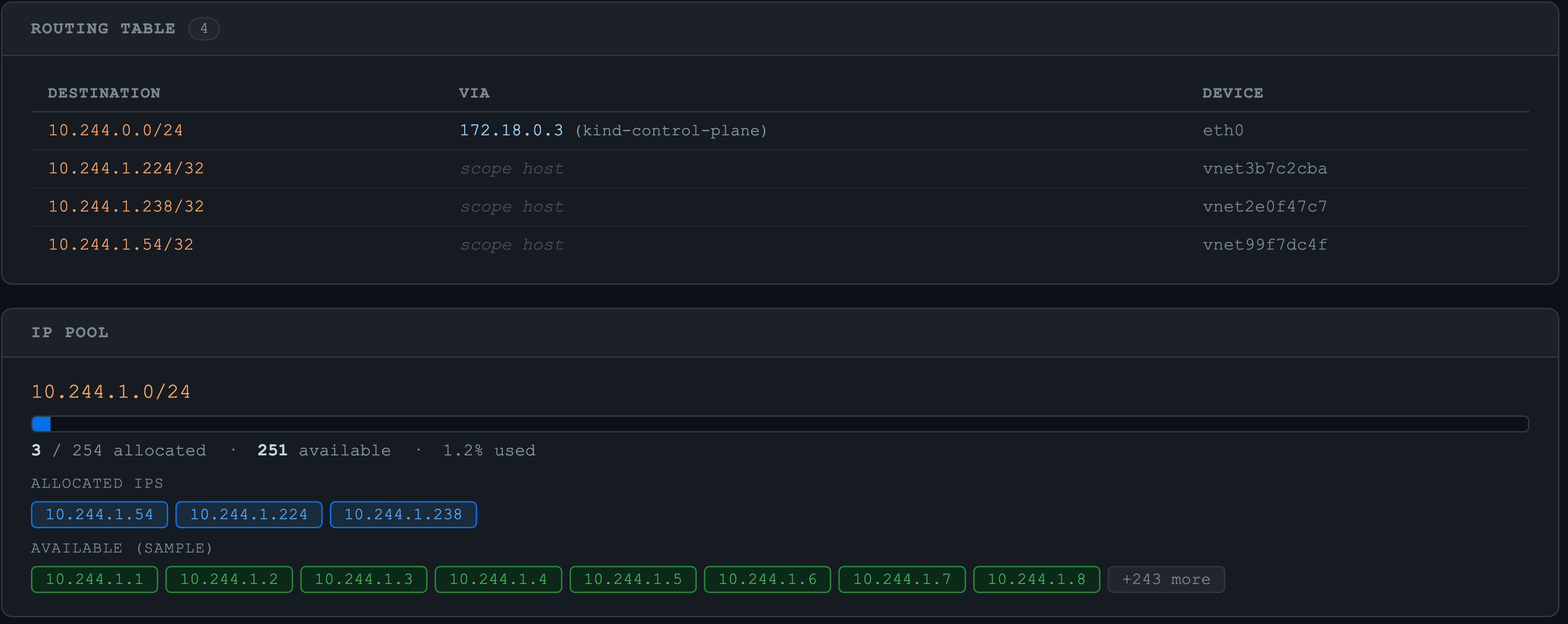
ip route show)을 source of truth로 사용해 stale 레코드를 피합니다. - Routing Table:
/32 scope host(same-node pod)와/24 via nodeIP(cross-node) 라우트를 구분해 표시합니다. - Interface Stats: vnet* 인터페이스별 RX/TX bytes/packets/errors
- IP Pool: CIDR 기준 IP 할당 현황
- CNI Config:
/etc/cni/net.d/10-pynet.conflistJSON - nftables Ruleset:
nft list ruleset출력
5. 삽질
6. 후기
실습
1. CNI Plugin 없이 kind cluster 배포
- 노드 2개, CNI X
# kind-config.yaml
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
networking:
# 기본 pynet(Go) 비활성화 → pynetd DaemonSet으로 대체
disableDefaultCNI: true
nodes:
- role: control-plane
extraPortMappings:
- containerPort: 30080 # pynet-web NodePort → web.py 9090
hostPort: 30080
protocol: TCP
- role: worker> kind create cluster --config kind-config.yaml
Creating cluster "kind" ...
✓ Ensuring node image (kindest/node:v1.35.0) 🖼
✓ Preparing nodes 📦 📦
✓ Writing configuration 📜
✓ Starting control-plane 🕹️
✓ Installing StorageClass 💾
✓ Joining worker nodes 🚜
Set kubectl context to "kind-kind"
You can now use your cluster with:
kubectl cluster-info --context kind-kind
Have a nice day! 👋결과
- CNI plugin 설치X -> coredns pod를 스케쥴링 할 수 없음
> k get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-7d764666f9-h4mfx 0/1 Pending 0 29s
coredns-7d764666f9-hfjwn 0/1 Pending 0 29s
etcd-kind-control-plane 1/1 Running 0 37s
kube-apiserver-kind-control-plane 1/1 Running 0 36s
kube-controller-manager-kind-control-plane 1/1 Running 0 36s
kube-proxy-hvsdp 1/1 Running 0 29s
kube-proxy-prg4w 1/1 Running 0 29s
kube-scheduler-kind-control-plane 1/1 Running 0 36s
> k describe pod coredns-7d764666f9-h4mfx -n kube-system
...
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 81s default-scheduler 0/1 nodes are available: 1 node(s) had untolerated taint(s). no new claims to deallocate, preemption: 0/1 nodes are available: 1 Preemption is not helpful for scheduling.2. pynet 빌드 + 배포
> make kind-all
docker build \
--build-context cni-pynet=./cni-pynet \
-t pynetd:latest \
-f pynetd/Dockerfile \
pynetd/
[+] Building 2.2s (23/23) FINISHED
...
clusterrole.rbac.authorization.k8s.io/pynet created
clusterrolebinding.rbac.authorization.k8s.io/pynet created
serviceaccount/pynet created
daemonset.apps/pynet created
service/pynet-web created
...결과
- pynet daemon 생성 성공
- coredns pod도 스케쥴링 성공
- web dashboard 접근 가능
> k get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-7d764666f9-5phwm 1/1 Running 0 54m
coredns-7d764666f9-zr92q 1/1 Running 0 54m
etcd-kind-control-plane 1/1 Running 0 54m
kube-apiserver-kind-control-plane 1/1 Running 0 54m
kube-controller-manager-kind-control-plane 1/1 Running 0 54m
kube-proxy-dd9rk 1/1 Running 0 54m
kube-proxy-nkbvm 1/1 Running 0 54m
kube-scheduler-kind-control-plane 1/1 Running 0 54m
pynet-gb8s4 2/2 Running 0 54m
pynet-zbxmb 2/2 Running 0 54m
> k describe pod coredns-7d764666f9-hfjwn -n kube-system
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 4m28s default-scheduler 0/1 nodes are available: 1 node(s) had untolerated taint(s). no new claims to deallocate, preemption: 0/1 nodes are available: 1 Preemption is not helpful for scheduling.
Normal Scheduled 105s default-scheduler Successfully assigned kube-system/coredns-7d764666f9-hfjwn to kind-worker
Normal Pulled 104s kubelet Container image "registry.k8s.io/coredns/coredns:v1.13.1" already present on machine and can be accessed by the pod
Normal Created 104s kubelet Container created
Normal Started 104s kubelet Container started
3. pod 추가
- test pod 배포
> kubectl run test-pod-0 \
--image=busybox:1.36 \
--restart=Never \
--command -- sleep 3600
pod/test-pod-0 created
> kubectl run test-pod-1 \
--image=busybox:1.36 \
--restart=Never \
--command -- sleep 3600
pod/test-pod-1 created
> kubectl run test-pod-2 \
--image=busybox:1.36 \
--restart=Never \
--command -- sleep 3600
pod/test-pod-2 created
> kubectl run test-pod-3 \
--image=busybox:1.36 \
--restart=Never \
--command -- sleep 3600
pod/test-pod-3 created-
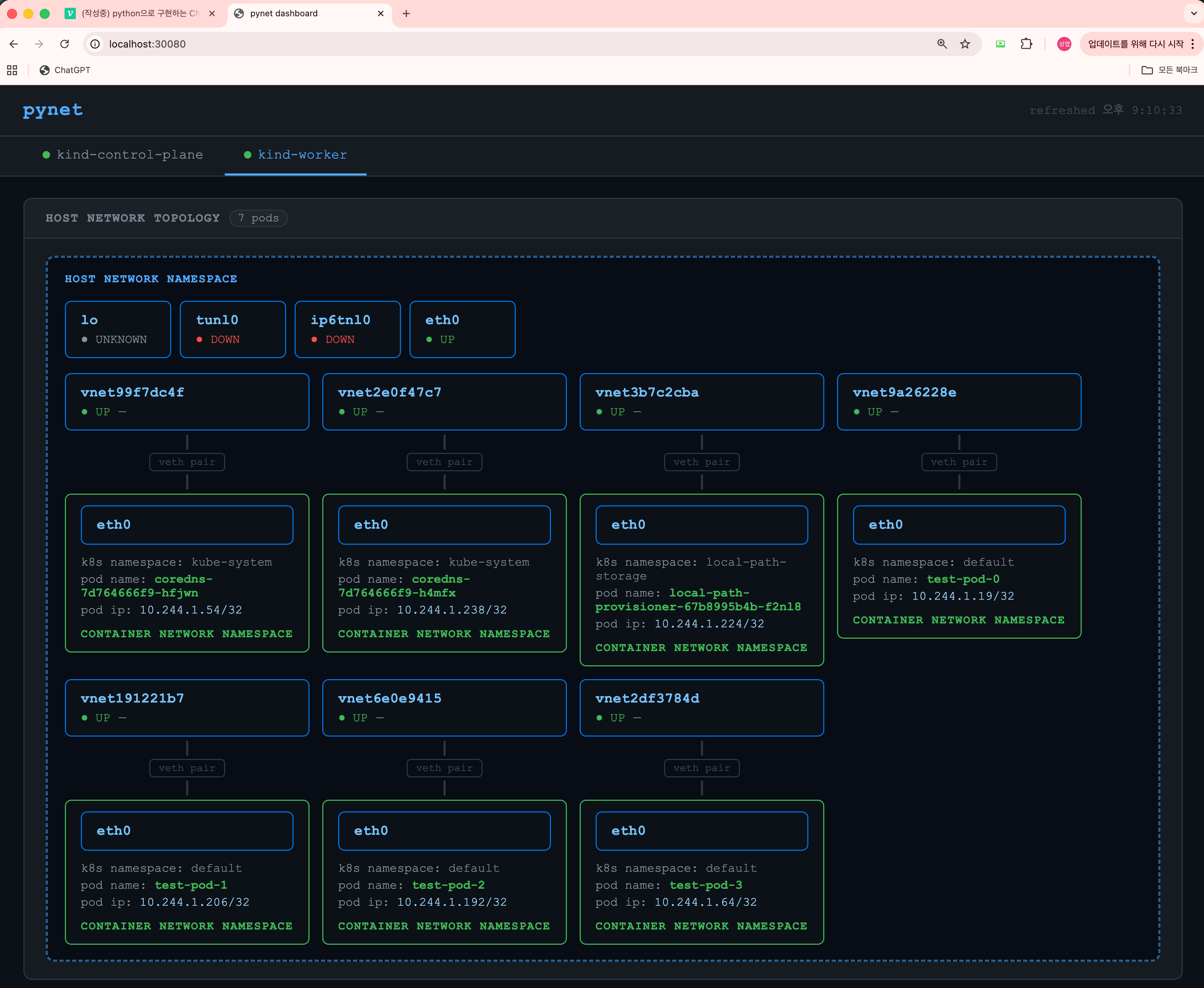
네트워크 토폴리지: veth pair 생성 (host network namespace의 네트워크 인터페이스 <-> container network namespace의 네트워크 인터페이스), pod IP 할당 확인,
-
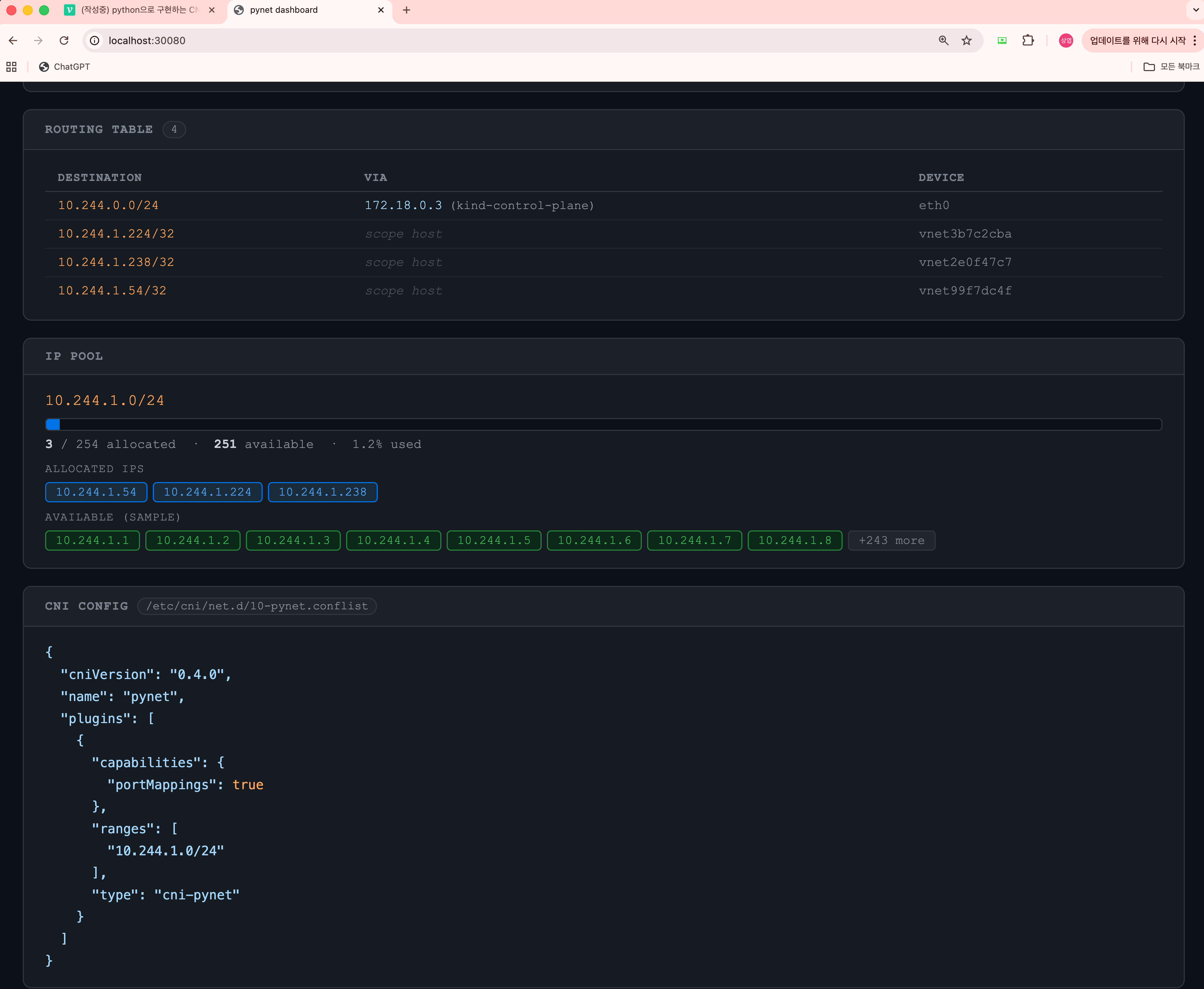
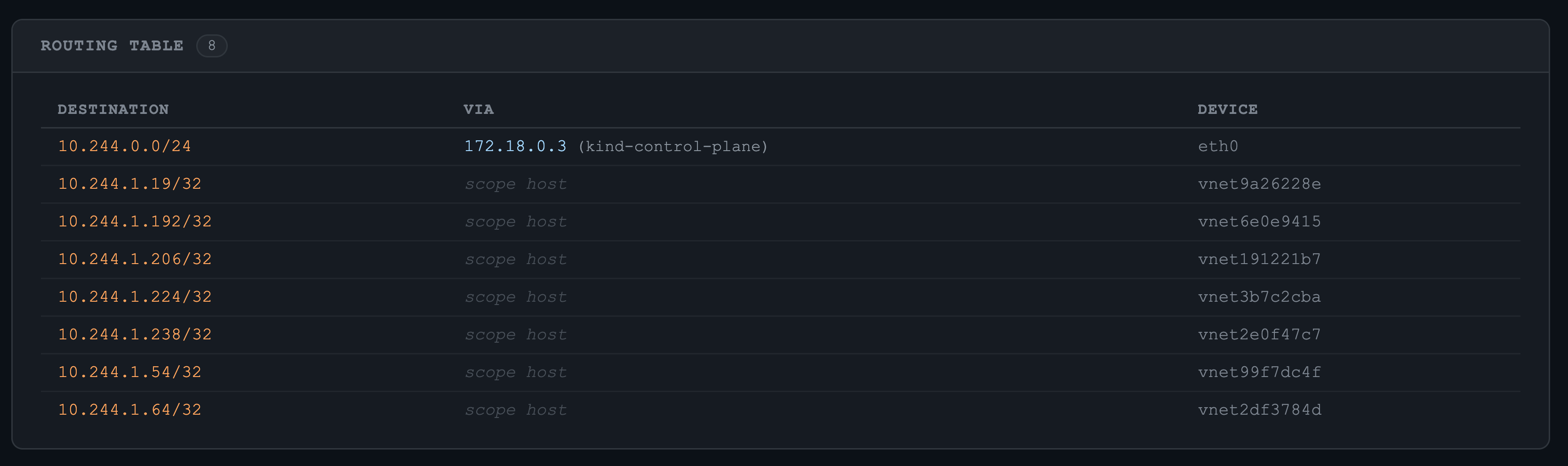
routing table (pod ip에 대한 entry 추가 확인)
-
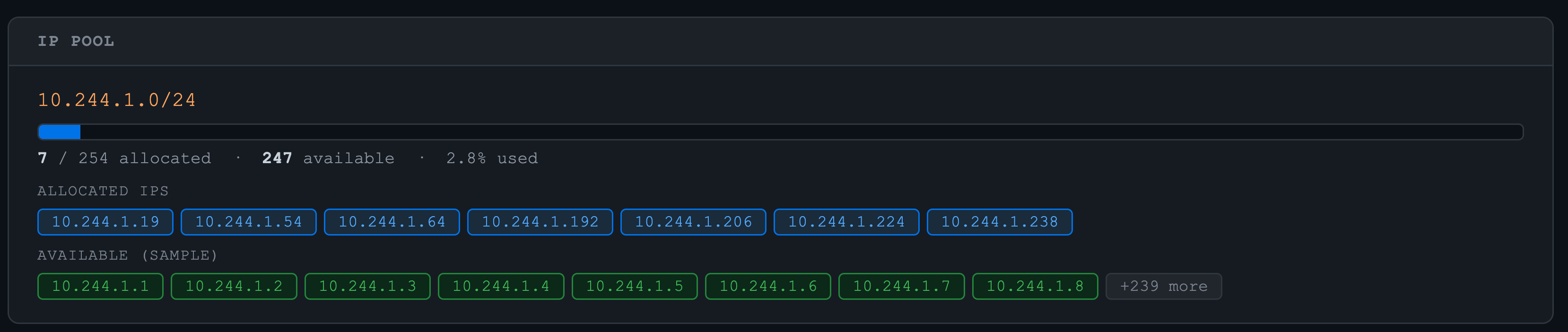
IP Pool (random 기반의 IPAM에 따라 pod IP 할당 확인)
4. Pod 삭제
- test pod 삭제
> kubectl delete pod test-pod-0
pod "test-pod-2" deleted
> kubectl delete pod test-pod-1
pod "test-pod-2" deleted
> kubectl delete pod test-pod-2
pod "test-pod-2" deleted
> kubectl delete pod test-pod-3
pod "test-pod-2" deleted네트워크 인터페이스, ip pool 및 routing table 삭제 확인