자바로 개발을 진행하다 보면 여러 난관에 부딪힐 때가 많습니다
특히 저는 SpringBoot를 배울때 항상 사람들이 "JPA를 조심해...!!" 라고 말하는 거를 옆에서 심심치 않게 듣고는 했습니다.
그리고 어느 정도 스프링부트에 대해서 알다 싶다가고, 사실 아직도 많이 헷갈리기도 하는게 JPA 이기도 합니다.
그래서 이번 JPA 시리즈를 통해서 저 스스로도 JPA에 대한 정보를 정리하는 시간을 가져 볼 까 합니다!!!
가장 먼저 오늘은 첫 번째 시간인 만큼 JPA에 대한 구체적인 설명 보다는 개념을 한 번 훑고 가는 시간을 가지고려고 합니다!
JPA
자바 퍼시스턴스(Java Persistence, 이전 이름: 자바 퍼시스턴스 API/Java Persistence API) 또는 자바 지속성 API(Java Persistence API, JPA)는 자바 플랫폼 SE와 자바 플랫폼 EE를 사용하는 응용프로그램에서 관계형 데이터베이스의 관리를 표현하는 자바 API이다.
흐으음... 위의 설명만 보고는 사실 무슨 소린지 잘 모르겠습니다.
그래서 다른 설명을 찾아봤습니다.
JPA는 자바 진영의 ORM 기술 표준이다. 자바 어플리케이션과 JDBC 사이에서 동작한다.
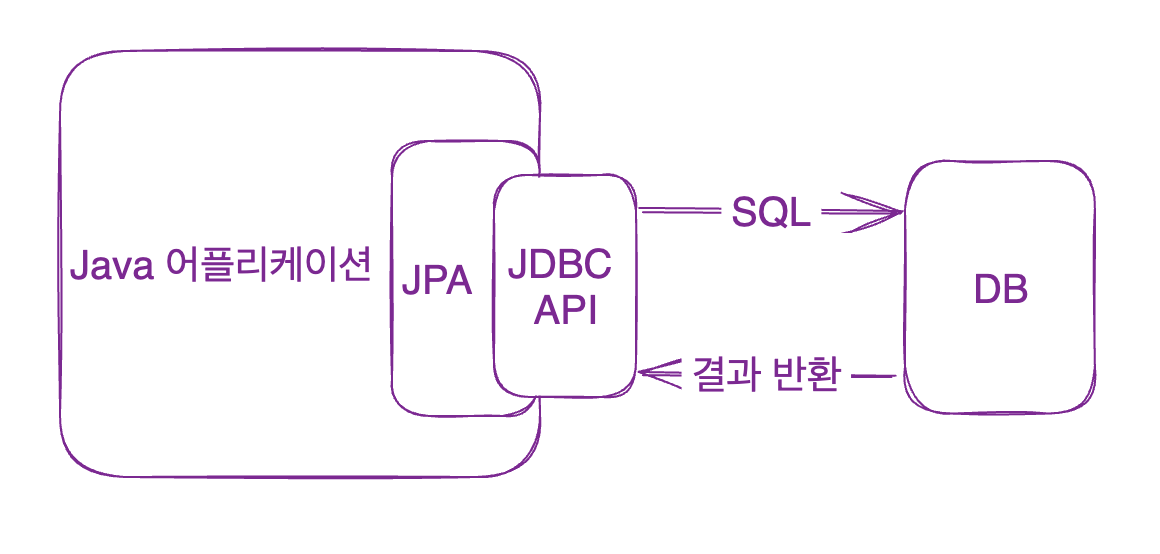
자바 ORM 표준 JPA 프로그래밍 -김영한 54p
오홍 그렇군요!
근데 그러면 JDBC는 뭐고 ORM은 또 뭘까요??
일단 영속성 부터 무슨 소린지 알아볼까요?
영속성
컴퓨터 공학에서 지속성(Persistence)은 프로세스가 생성했지만 별개로 유지되는 상태의 특징 중 한 가지이며, 별도의 기억 장치에 데이터를 보존하는 것을 목적으로 한다. 이 특징으로 인해 프로그래머는 저장 장치로부터 데이터를 전송하는 작업 및 자료 구조 등을 이용해 데이터를 보존하는 것이 가능하다.1
이 특징 없이는 상태는 오직 RAM에만 존재할 수 있고, 컴퓨터가 종료되어 RAM이 전력을 잃어버린다면 상태도 같이 사라져 버리게 된다.2
위키백과에서는 지속성이라고 번역을 했군요!
저는 편의상 Persistence를 영속성이라고 하겠습니다.
영속성을 프로그램이 종료 되어되, 컴퓨터가 꺼져도, 저장되는 속성입니다.
본래 RAM은 읽기/쓰기 속도가 매우 빠르지만, 전원이 공급되지 않으면 안에 저장되어있는 데이터가 모두 날아가는 휘발성을 가지고 있습니다.
그에 반해 디스크, SSD나 HDD 등의 기억장치들은 RAM과는 다르게 전원이 꺼져도 데이터가 손실되지 않습니다.
그러면 우리가 개발에서 보통 활용하는 부분은 어디일까요??
바로 메모리입니다. RAM에서 공간을 할당 받고, 사용하는 거지요
하지만 어떤 데이터들은 계속 저장될 필요가 있습니다. 회원 정보 같은 데이터들은 없어지면 곤란하겠죠
그렇기 때문에 우리는 데이터가 반영구적으로 존재하도록 작업을 해줄 필요가 있습니다.
이게 바로 영속성을 부여하는 이유입니다.
대표적으로 DB에 저장하는 방식이 존재합니다.
JDBC

JDBC(Java Database Connectivity)는 자바에서 데이터베이스에 접속할 수 있도록 하는 자바 API이다. JDBC는 데이터베이스에서 자료를 쿼리하거나 업데이트하는 방법을 제공한다.
자바에서 데이터를 영속화 시키는데 사용되는 API 입니다.
특히 데이터베이스에 직접 데이터를 저장하고, 수정하고, 조회해야하는 백엔드 단에서는 필수적인 API 라고 할 수 있죠.
여기서는 일단 이정도만 알고 넘어가겠습니다.
더 자세한 JDBC에 대한 설명은 나중에 추가로 업로드 하도록 하겠습니다.
ORM (Object Relational Mapping)
객체 관계 매핑(Object-relational mapping; ORM)은 데이터베이스와 객체 지향 프로그래밍 언어 간의 호환되지 않는 데이터를 변환하는 프로그래밍 기법이다. 객체 지향 언어에서 사용할 수 있는 "가상" 객체 데이터베이스를 구축하는 방법이다. 객체 관계 매핑을 가능하게 하는 상용 또는 무료 소프트웨어 패키지들이 있고, 경우에 따라서는 독자적으로 개발하기도 한다
ORM 이란 객체와 관계형 데이터 베이스를 매핑시켜준다는 뜻입니다.
자바는 객체지향 개발 언어입니다. 그렇기 때문에 자바의 모든 것을 객체화 시켜서 다루죠
그렇기 때문에 상속, 캡슐화, 다형성 등의 특성을 가지고 있고, 코드의 재사용성이 올라가는 등의 여러 가지 장점을 취할 수 있습니다.
하지만 DB에 저장할 때 만큼은 아니라고 할 수 있습니다. 특히 관계형 데이터 베이스에 저장하려면 머리가 아플 수 밖에 없죠
RDB에는 각 '객체'에 맞는 Data Type은 존재하지 않기 때문입니다.
그리고 이 문제를 해결하기 위해서 ORM 프레임워크를 사용하는 것입니다.
ORM 프레임워크는 객체와 테이블을 매핑시켜줌으로 패러다임의 불일치 문제를 개발자 대신 해결해줍니다.
이러한 ORM도 물론 주의하면서 사용해야 합니다.
통계 쿼리와 같이 복잡한 쿼리는 직접 Native Query를 날려주는게 더 좋습니다.
ORM 프레임워크를 사용하다 보면 하이버네이트라는 단어도 종종 등장을 하는데요.
하이버네이트는 다음과 같습니다.
하이버네이트
하이버네이트 ORM(Hibernate ORM)은 자바 언어를 위한 객체 관계 매핑 프레임워크이다. 객체 지향 도메인 모델을 관계형 데이터베이스로 매핑하기 위한 프레임워크를 제공한다.
하이버네이트는 GNU LGPL 2.1로 배포되는 자유 소프트웨어이다.
하이버네이트는 쉽게 말해 인터페이스인 JPA의 구현체입니다!
Spring Data JPA
Spring Data JPA, part of the larger Spring Data family, makes it easy to easily implement JPA based repositories.
스프링 데이터 JPA는 스프링에서 JPA를 더 사용하기 편하게 도와주는 모듈입니다!
위에서 나온 용어들의 관계를 정리하면 다음과 같습니다.
- JPA는 자바 ORM 기술에 대한 API 표준 명세이다. 즉 인터페이스들을 모아 둔 것이다.
- JPA를 사용하기 위해서는 JPA를 구현한 ORM 프레임워크를 선택해야 한다.
- 하이버네이트는 JPA를 구현한 ORM 프레임워크 중 하나이다.
그렇다면 JPA를 사용함으로 얻을 수 있는 장점은 무엇일까요??
장점
- SQL에 독립적인 코드를 작성할 수 있다.
- 개발자가 비즈니스 로직에 집중할 수 있다.
입니다!
물론 백엔드 개발자라면, 아니 모든 개발자라면 SQL은 다룰 수 있어야 한다고 생각합니다.
하지만 SQL을 작성하는게 시간을 많이 뺏긴다든지,
SQL을 DB에 날리기 위해 커넥션을 얻고, 해제하고, 각 객체를 하나 하나 해부해서 SQL을 날리기 위해 매핑을 해주는 등의 단순 반복 작업을 개발자가 코드 한줄 한 땀 한 땀 작성하는 것은 비효율적인 것 처럼 느껴집니다.
그리고 백엔드 개발자에게는 비즈니스 로직을 다루는 것이 가장 중요하다고 생각합니다.
그렇기 때문에 JPA와 같은 도구를 사용해서 어느 정도 편하게 작업하는게 좋다고 생각합니다.
물론 JPA가 만능은 아닙니다!!
단점
- 비효율적인 쿼리가 나갈 수 있다.
- 의도하지 않은 쿼리가 나갈 수 있다.
와 같은 등의 단점이 존재하죠
대표적으로 N + 1 문제가 있겠군요
위와 같은 문제는 대부분 개발자의 실수 및 JPA에 대한 이해 부족으로 인해 발생합니다
저도 JPA에 대해 완벽하게 알지 못하죠
사실 아는게 거의 없....ㅜㅜ
그렇기 때문에 이 시리즈를 통해 보다 깊게 JPA를 이해하고자 합니다!!
오늘은 이렇게 JPA 하면 떠오르는 용어들을 간단하게 훑어봤습니다.
다음에는 토이 프로젝트를 생성하고, 실행시키면서 JPA에 대해서 알아보도록 하겠습니다
감사합니다!

JPA에 장단점에 대해 설명하고 남기신 코멘트가 인상적이네요! 잘 읽고 갑니다~