프로젝트를 진행하다보면 많은 데이터가 필요할 때가 있습니다
실무에서는 데이터가 많이 쌓여 있을 테니 더미 데이터가 필요 없겠지만...
저 같은 취준생은 데이터를 만들어서 넣어야 하죠(ㅠㅠ)
현재 저는 넘블에서 진행 중인 Redis와 Kafka, Spring을 활용한 강아지 인기투표 아키텍쳐 만들기 를 진행하고 있습니다. 아직 Redis 랑 Kafka는 건들이지 도 못했...
이 프로젝트를 진행하면서 저는 좋아요 수를 집계하는 방식을 스케쥴링을 돌리면서 좋아요 수를 갱신하는 방법을 사용하고 있습니다!!

간단하게 테이블은 2개만 사용하고 있습니다!!!
좋아요 집계 방법
저는 예전에는 좋아요를 누르면 해당 게시물에 좋아요 += 1 하면 되다고 생각을 했습니다
하지만 그렇게 동시성 문제가 생길 수 있고, 좋아요를 제거 할 때, 처리가 복잡해지기 때문에 해당 방법이 최선이 아니라고 생각하고, 다른 방법으로 집계를 시도했습니다.
바로 좋아요 리스트에서 개수를 세는 것이죠!!
사용자가 좋아요를 누르면 게시문 엔티티의 좋아요 칼럼의 수를 증가시키는 것이 아니라 별도의 좋아요 테이블을 만든 다음, 거기서 몇 개의 좋아요가 눌렸는지 세는 방법입니다!!!
아직 카프카가 뭔지, 어떻게 사용하면 좋을지, 투표 등에 자주 사용된다는 데 왜 그런지 잘 몰라서 백엔드를 위와 같이 구성했습니다!!! 추후에 카프카를 활용하면 집계방식은 변경될 가능성이 있습니다!!
그런데 여기서 문제가 생깁니다...
그것은... 좋아요 테이블에 데이터가 아주 많이 필요하다는 사실입니다....!!!
일일히 하나하나 데이터를 넣기에는 너무 귀찮고..
bulk insert를 해야할 것 같은데...
그렇기에는 데이터를 만들어야 하는데...
어떻게 하면 좋을까요??
Object Mother
An object mother is a kind of class used in testing to help create example objects that you use for testing.
Martin Fowler
Object Mother 란 테스트에 도움을 주기 위해 예제 객체를 생성하는 클래스입니다.
우리가 개발을 할 때 모든 객체를 직접 일일히 만들어서 넣기에는 힘이 부치니... 외부 API의 도움을 받는 것이라고 할 수 있죠!!
그러면 어떤 것을 사용하면 좋을까요??
EasyRandom
저는 패스트캠퍼스의 대용량 데이터 강의를 듣다가 EasyRandom 이라는 클래스의 존재를 알게 되었습니다.
그래서 저는 해당 클래스를 사용해서 데이터를 아주 많이 만들어 보도록 하겠습니다!!
들어갈 데이터 클래스는 아래와 같습니다!!
Likes class
@Getter
@Entity
@Table(name = "likes")
@NoArgsConstructor(access = PROTECTED)
public class Likes extends BaseTimeEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private Long puppyId;
private Boolean isDeleted;
@Builder
public Likes(Long id, Long puppyId) {
this.id = id;
this.puppyId = puppyId;
this.isDeleted = false;
}
public Likes(Long id, Long puppyId, Boolean isDeleted, LocalDateTime createdAt, LocalDateTime updatedAt) {
this.id = id;
this.puppyId = puppyId;
this.isDeleted = isDeleted;
this.createdAt = createdAt;
this.updatedAt = updatedAt;
}
public void delete(){
this.isDeleted = true;
}
@Override
public String toString() {
return "ID : " + this.id + ", puppyId : " + puppyId + ", isDeleted : " + isDeleted;
}
}Gradle
testImplementation 'org.jeasy:easy-random-core:5.0.0'
테스트 환경에서 데이터를 삽입했기 때문에 testImplementation 으로 사용했습니다!!
이제 Likss 클래스의 인스턴스를 EasyRadom을 사용해서 생성해보겠습니다!
BulkTest.java
@Slf4j
@SpringBootTest
public class BulkTest {
@Test
void easyRandomTest(){
Likes likes = new EasyRandom().nextObject(Likes.class);
log.info(likes.toString());
}
}실행 결과

Likes 클래스의 인스턴스가 생성 되었습니다!!!...
흐음.. 근데 실제로 사용하에는 좀 무리가 있군요...
EasyRandom 공식 깃허브에서 는 위키를 제공하고 있습니다
해당 위키 페이지로 가보면...
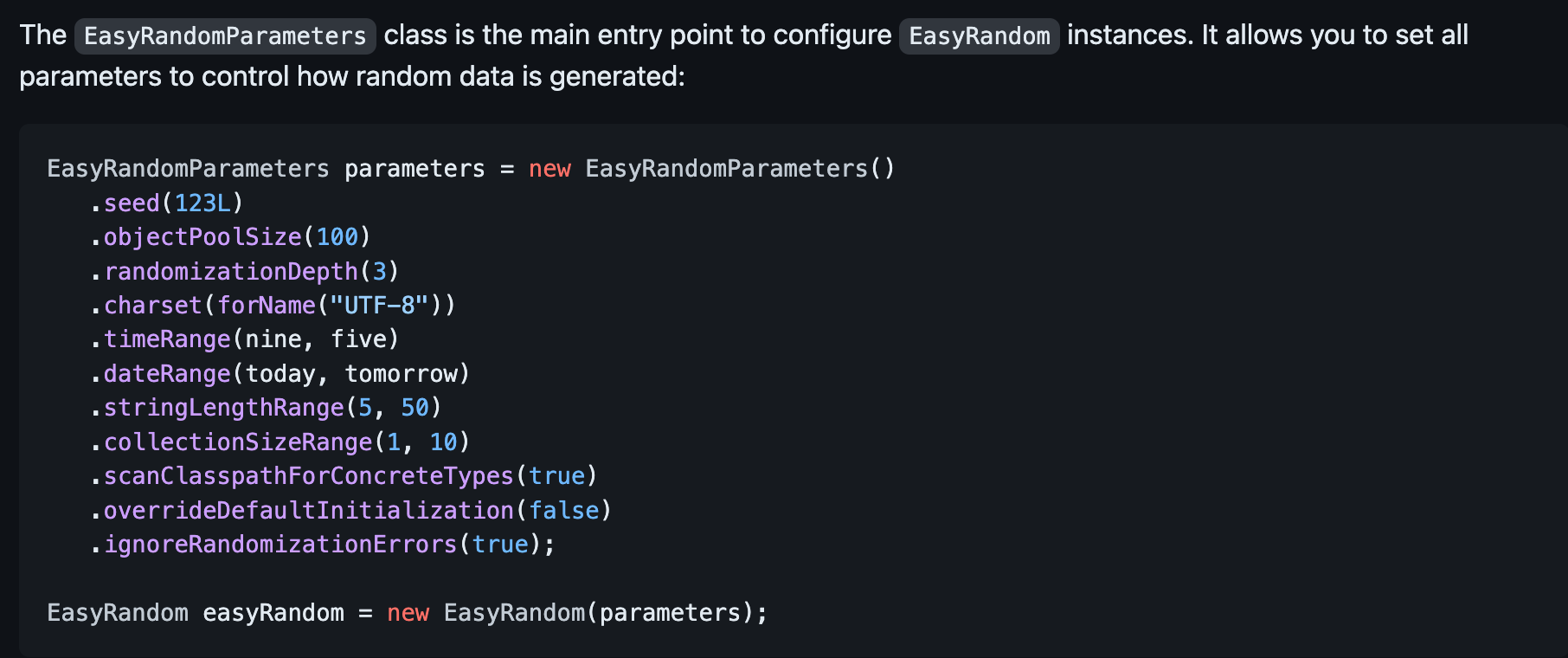
맨 처음에 보이는 코드입니다!!
메소드를 활용해서 원하는 형태의 값을 뽑아낼 수 있도록 지원해주고 있군요!!
그 밑에 예시를 한 번 살펴보면
EasyRandomParameters parameters = new EasyRandomParameters()
.randomize(String.class, () -> "foo")
.excludeField(named("age").and(ofType(Integer.class)).and(inClass(Person.class)))
// set other parameters
.build();
EasyRandom easyRandom = new EasyRandom(parameters);
Person person = easyRandom.nextObject(Person.class);randomize 메소드를 사용해서 값을 고정시키고 있다...!!
excludeField 를 사용해서 특정 필드도 랜덤 생성을 안할 수 있다!!
등의 행위를 할 수 있습니다
그렇다면 Long 형의 값을 1로 고정시켜 보겠습니다!
@Slf4j
@SpringBootTest
public class BulkTest {
Likes createLikes() {
EasyRandomParameters parameters = new EasyRandomParameters()
.randomize(Long.class, () -> 1L);
return new EasyRandom(parameters).nextObject(Likes.class);
}
@Test
void easyRandomTest(){
Likes likes = createLikes();
log.info(likes.toString());
}
}
잘 되는 군요!
하지만 우리는 ID 값은 필요가 없습니다! DB의 생성 전략에 따라 DB가 알아서 생성해 줄 것이기 때문이죠
그러면 ID 칼럼은 무시하고 puppy_id만 값을 고정시켜서 생성해 볼까요??
Likes createLikes() {
EasyRandomParameters parameters = new EasyRandomParameters()
.excludeField(
named("id")
.and(ofType(Long.class))
.and(inClass(Likes.class))
)
.randomize(Long.class, () -> 1L);
return new EasyRandom(parameters).nextObject(Likes.class);
}
잘 되는 것을 볼 수 있습니다!!!
exclude 해주면 null이 들어가는군요
그런데 저 named 이런 것들은 저는 변수로 빼고 싶군요...
depth가 깊어지면 개인적으로 보기 힘들더라구요
그래서 한번 named의 리턴형을 보러 가 보져
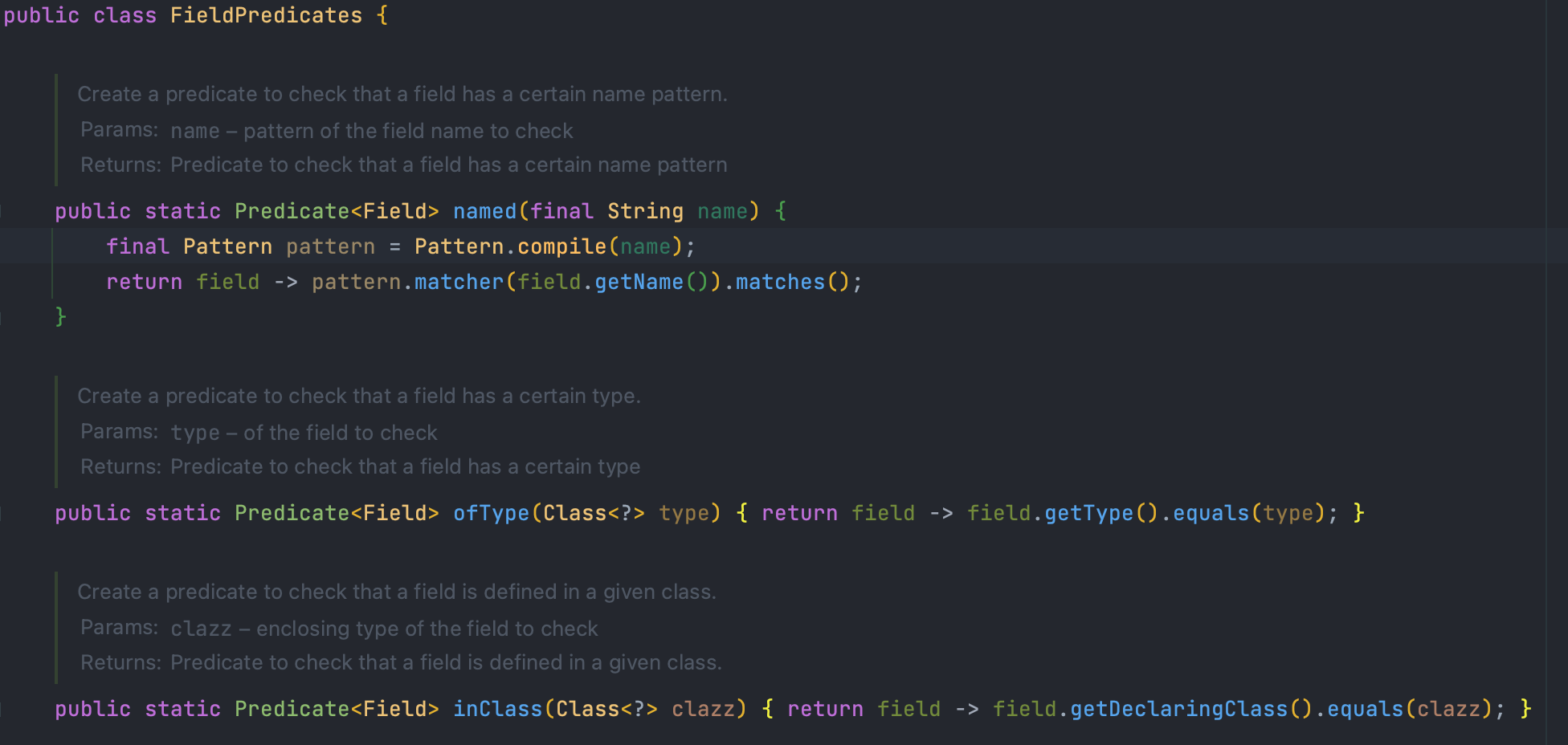
오!!! naemd 뿐 아니라 ofType, inClass의 리턴형이 모두 Predicate<Field>군요!!
변수화 해서 보기 좋게 뺄 수 있겠어요!!
Likes createLikes() {
Predicate<Field> idPredicate = named("id")
.and(ofType(Long.class))
.and(inClass(Likes.class));
Predicate<Field> isDeletedPredicate = named("isDeleted")
.and(ofType(Boolean.class))
.and(inClass(Likes.class));
EasyRandomParameters parameters = new EasyRandomParameters()
.excludeField(idPredicate)
.randomize(isDeletedPredicate, () -> false);
return new EasyRandom(parameters).nextObject(Likes.class);
}그럼 이제 제가 하고 싶은 일은 하나입니다.
바로 puppy_id의 범위 지정이죠
id와 달리 직접 랜덤값을 넣어 줘야 하죠
그럼 일단 가장 먼저 Radom을 쓰고 싶군요!!
Random r = new Random();
r.nextLong(1, 강아지_마릿수);위의 코드를 어디에 삽입 하면 될 것 같은데 말이죠...
randomize() 메소드에 적절히 삽입하면 될 것같습니다!!
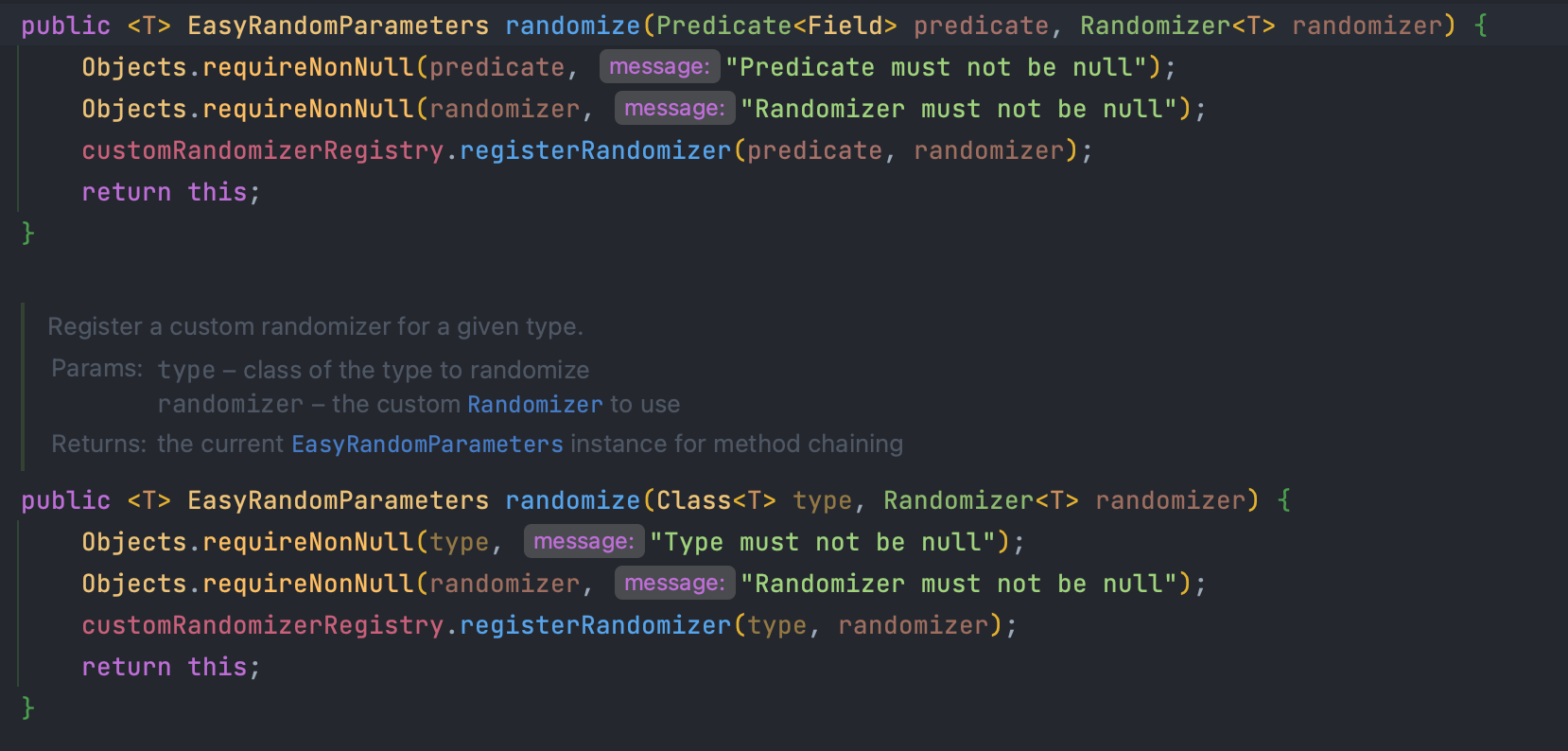
위와 같이 randomzie 메소드는 첫 번째 인자로는 Predicate 또는 Class 를 받고 두 번째 인자로는 randomizer를 받는군요...
첫 번째 인자로는 Predicate를 만들어서 넣어주면 될 것 같습니다.
지금까지 위에서 했던 일을 되돌아 보면 무슨 필드에 적용하는지 넣어줘야 할 것 같군요.
Predicate<Field> puppyIdPredicate = named("puppyId")
.and(ofType(Long.class))
.and(inClass(Likes.class));이 녀석을 넣어주면 될 것 같습니다!!
그럼 이제 Randomizer....
저건 뭘까요??
다행히도 답은 가까이 있었습니다!!
코드를 타고 올라가다 보면...
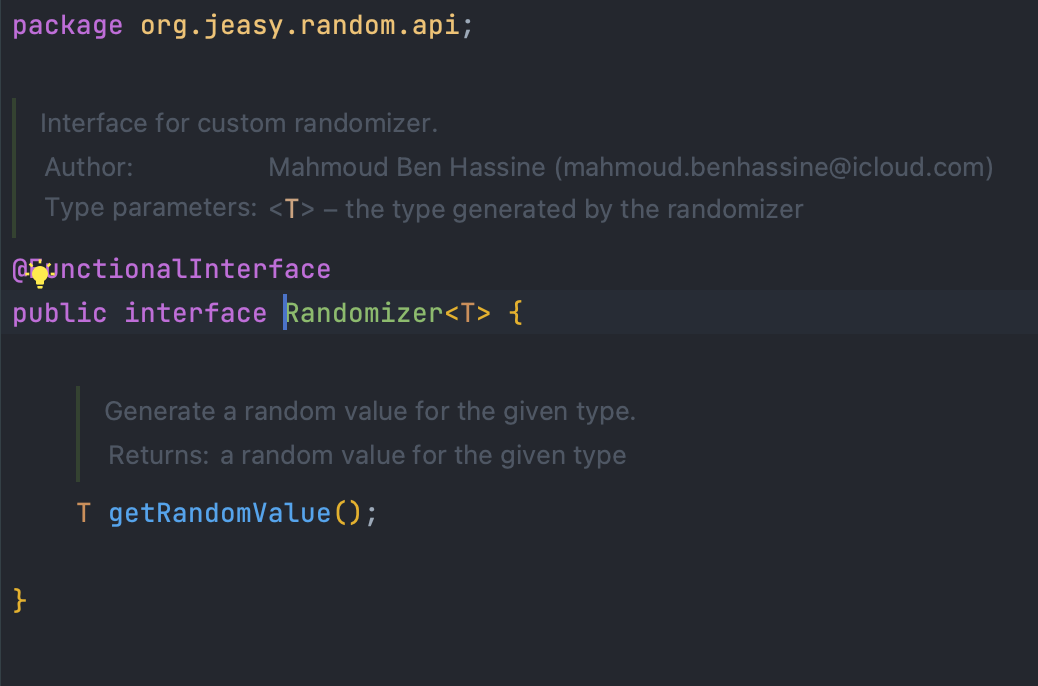
EasyRadom에서 제공하는 api군요!!
그럼 다시 깃허브로 가봅시다!!

찾았다 요놈!
타고 타고 들어가다 보면...
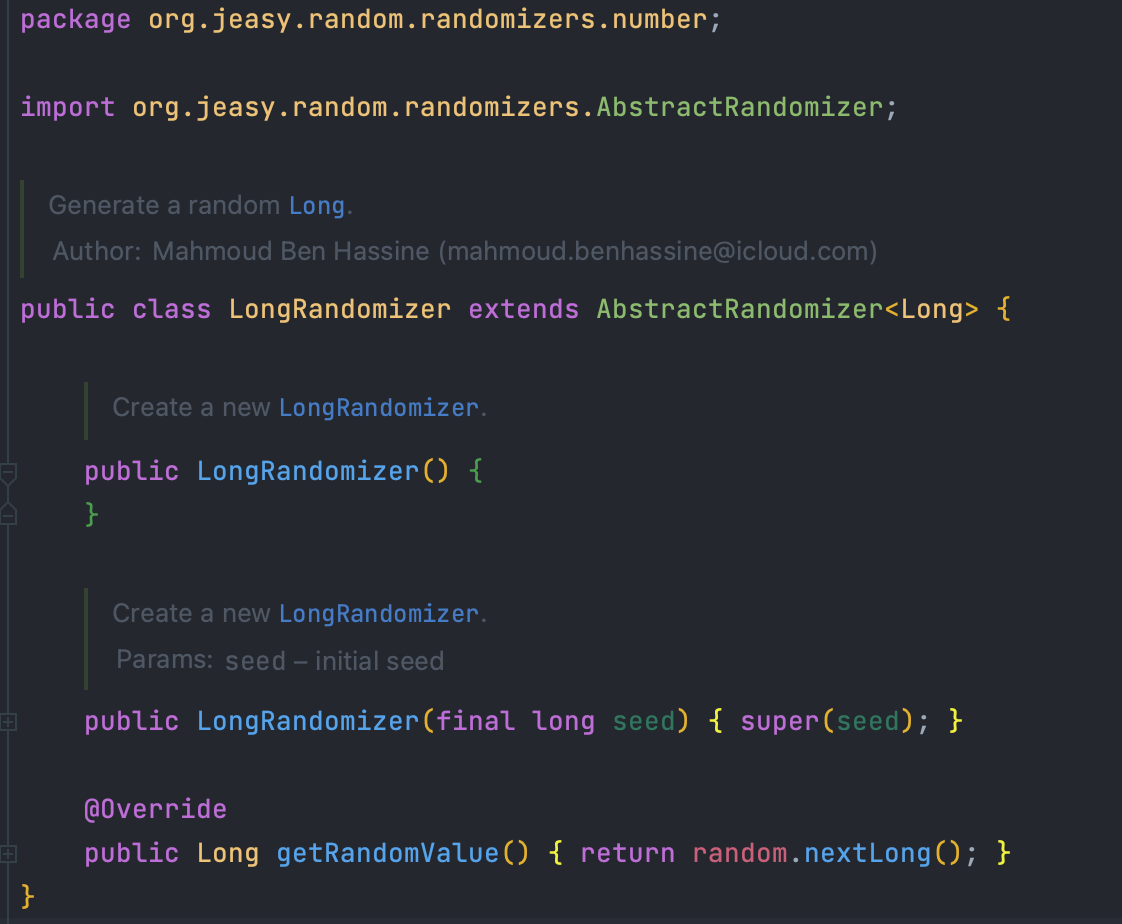
찾았습니다!!
여기서는 getRandomValue를 오버라이딩 하고 있는데...
익숙한 nextLong()가 보이는군요?
그런데 raddom 이놈이 우리가 아는 그 랜덤이 아닌 것 같군요...
그럼 다시 한 번 타고 들어가면...
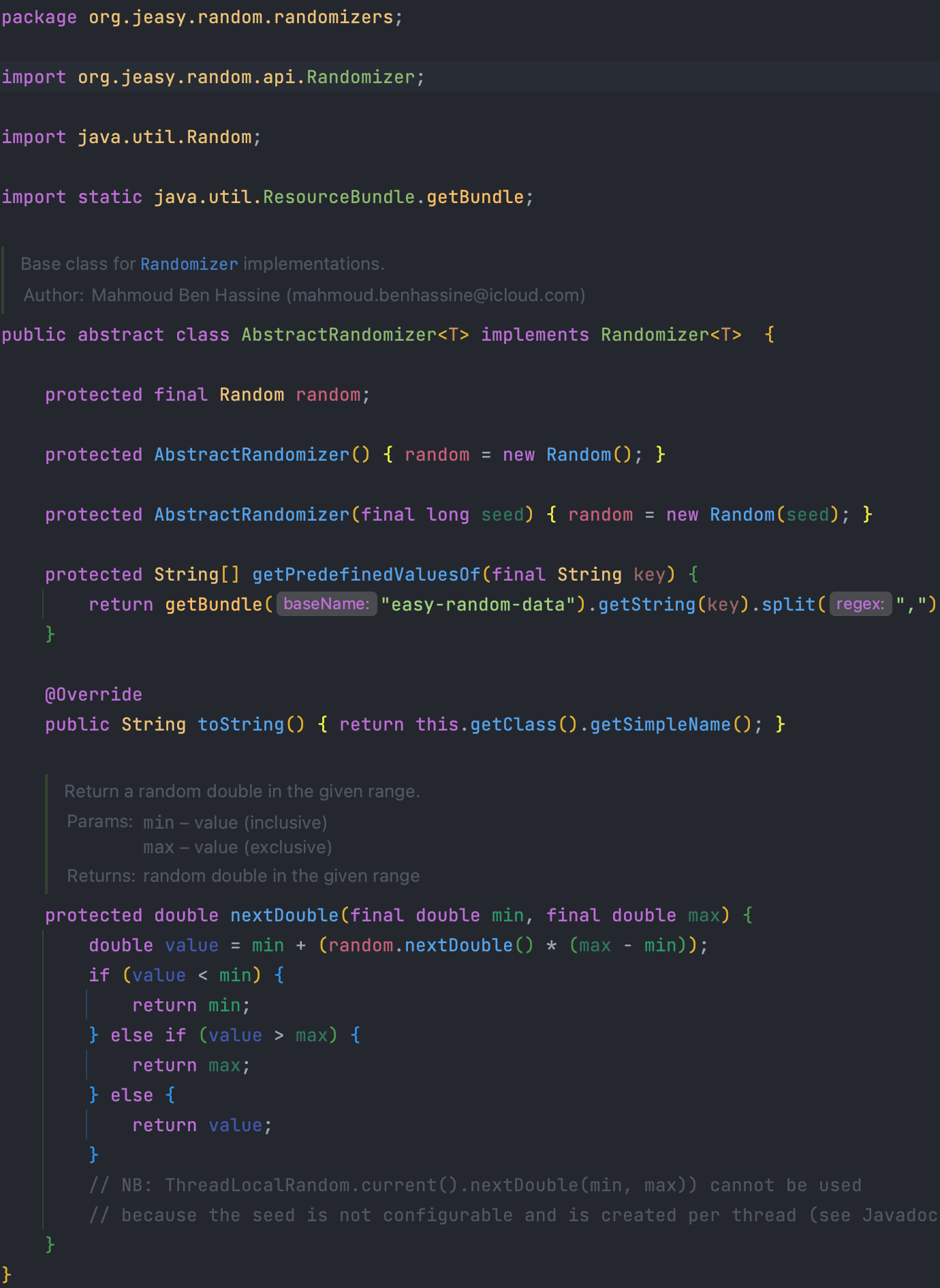
우리가 아는 그 Random 이었군요!!!
그럼 아주 편하게 평소에 Random 클래스를 이용할 때 처럼 이용하면 될 것 같습니다!!
그리고 Randomizer는 Predicate 이므로 람다식으로 전달해주면 아주 편하게 사용하 수 있을 것 같습니다!!
Likes createLikes(int puppySize) {
Predicate<Field> idPredicate = named("id")
.and(ofType(Long.class))
.and(inClass(Likes.class));
Predicate<Field> isDeletedPredicate = named("isDeleted")
.and(ofType(Boolean.class))
.and(inClass(Likes.class));
Predicate<Field> puppyIdPredicate = named("puppyId")
.and(ofType(Boolean.class))
.and(inClass(Likes.class));
EasyRandomParameters parameters = new EasyRandomParameters()
.excludeField(idPredicate)
.randomize(isDeletedPredicate, () -> false)
.randomize(puppyIdPredicate, () -> new Random().nextLong(1, puppySize + 1));
return new EasyRandom(parameters).nextObject(Likes.class);이제 외부에서 강아지가 몇 마리 있는지 주입받으면, 그 사이의 숫자를 리턴하도록 해서 원하는 랜덤 객체를 생성할 수 있게 됐습니다!!
EasyRandom 으로 원하는 객체 만들기 최종!
그러면 위에서 알아본 내용을 가지고 Likes의 객체들을 대량으로 만들어 보겠습니다!!
조건은 다음과 같습니다!!
- ID는 DB(MySQL)의 생성 전략 (strategy = IDENTITY, auto increment)를 따르기로 했으므로 무작위 생성을 하지 말아야 한다 - exclude
- isDeleted 는 false 값을 가진다 - randomzie
- createdAt과 updatedAt 또한 굳이 생성할 필요가 없으므로 생성하지 않는다 - exclude
- puppyId는 (1 ~ 총 강아지 마릿수) 만큼의 범위에서 랜덤한 값을 가진다 - randomize
public static Likes create(int seed, Long puppySize) {
Predicate<Field> idPredicate = named("id")
.and(ofType(Long.class))
.and(inClass(Likes.class));
Predicate<Field> isDeletedPredicate = named("isDeleted")
.and(ofType(Boolean.class))
.and(inClass(Likes.class));
Predicate<Field> createdAtPredicate = named("createdAt")
.and(ofType(LocalDateTime.class))
.and(inClass(Likes.class));
Predicate<Field> updatedAtPredicate = named("updatedAt")
.and(ofType(LocalDateTime.class))
.and(inClass(Likes.class));
EasyRandomParameters params = new EasyRandomParameters()
.seed(seed)
.excludeField(createdAtPredicate)
.excludeField(updatedAtPredicate)
.excludeField(idPredicate)
.randomize(isDeletedPredicate, () -> false)
.randomize(Long.class, () -> new Random().nextLong(1, puppySize + 1));
;
return new EasyRandom(params).nextObject(Likes.class);
}이제 데이터를 많이 많이 만들어서 넣어 봅시다!!!
저는 총 백만 개를 넣어볼 건데요
근데 한 번에 백만개를 넣으면.... 무슨 일이 생길지 조금은 불안해서 총 10만개 씩 10번에 걸쳐너 나눠 넣어 볼겁니다!!
그리고 IntStream을 사용해서 parallel() 병렬처리를 해서 최대한 빠르게 처리해도록 하겠습니다.
그리고 @Sl4fj의 로그를 활용해서
1. EasyRandom으로 데이터를 10만개 생성하는 데 걸리는 시간
2. 10만개의 데이터를 삽입하는데 걸리는 시간
을 각각 측정해보도록 하겠습니다!!
@Test
void insertLikesBulk() {
int dateSize = 10 * 10000;
long puppySize = 30L;
StopWatch generatingData, bulkInsert;
for (int i = 0; i < 10; i++) {
generatingData = new StopWatch();
bulkInsert = new StopWatch();
generatingData.start(); // 데이터 생성 시작
var likes = IntStream.range(0, dateSize)
.parallel()
.mapToObj(o -> LikesFixtureFactory.create(o, puppySize))
.toList();
generatingData.stop(); // 데이터 생성 끝
bulkInsert.start(); // 데이터 삽입 시작
likesJdbcRepository.bulkInsert(likes);
bulkInsert.stop(); // 데이터 삽입 끝
String logString = "#" + (i + 1) + "\t데이터 크기 : " + dateSize + " | 데이터 생성에 걸린 시간 : " + Math.round(generatingData.getTotalTimeSeconds() * 1000) / 1000.0
+ "s\t | 데이터 삽입에 걸린 시간 : " + Math.round(bulkInsert.getTotalTimeSeconds() * 1000) / 1000.0 + "s";
log.info(logString);
}
}그럼 이제 돌려 보면...!

전 진짜 노트북 터지는 줄 알았습니다...
맥 사고 나서 팬 처음 돌아갔어요!!
보시다시피 총 13분 정도에 걸쳐서 10 * 10만 = 100만 개의 데이터를 넣었습니다!!
로그를 찍어 보니 생각보다 데이터를 넣는데는 시간이 얼마 안걸리는데, 생성하는데 시간이 엄청 크군요..!!
추후에 JPA BulkInsert를 최적화 하는 방법도 공부해서 최적화를 시켜봐야겠습니다
그럼 넣어진 데이터를 한 번 확인해볼까요??
SELECT *
FROM likes;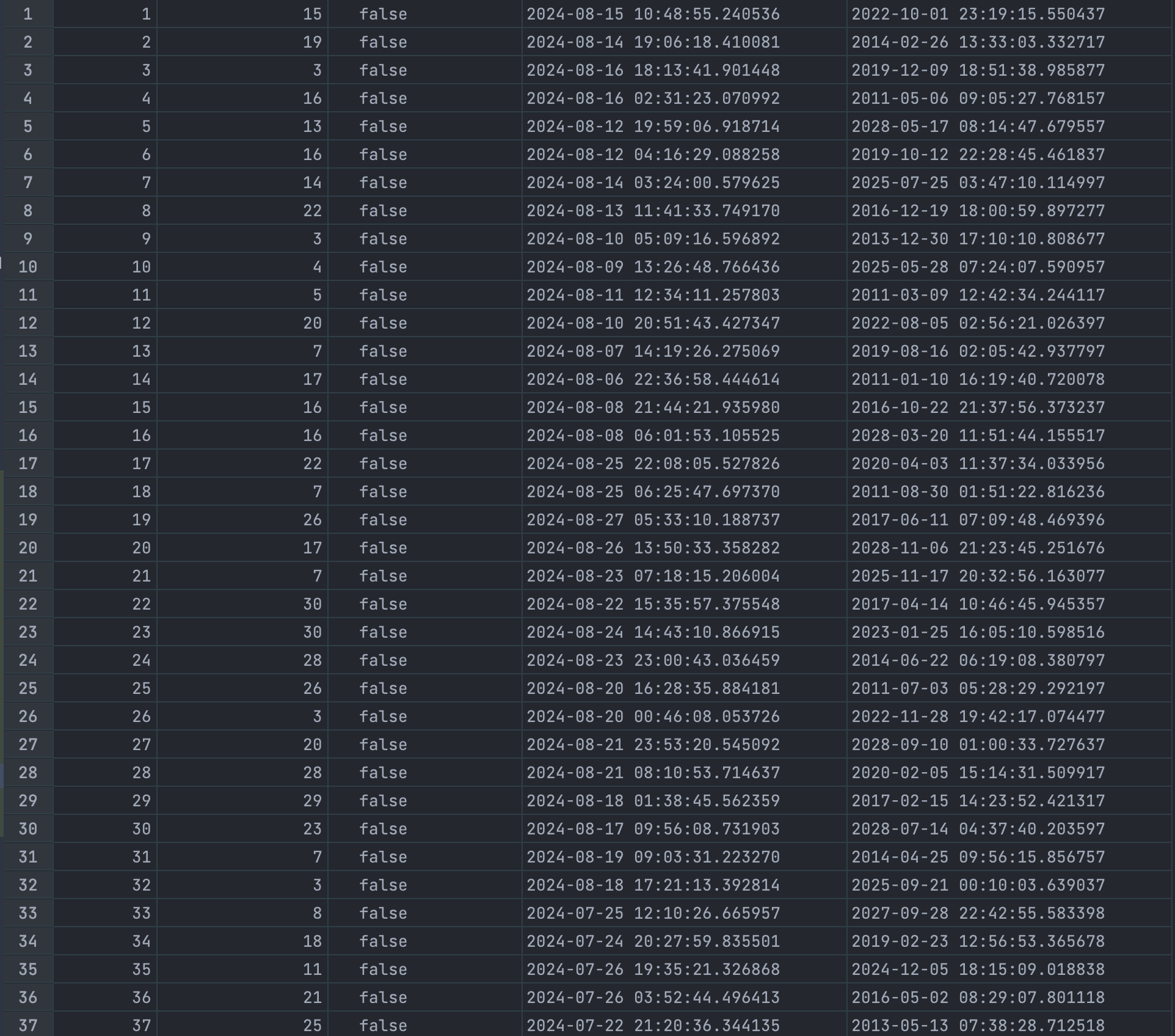
오호....뭔가 많이 들어가있군요!!
그럼 한 번 puppy_id 별로 몇 개씩 들어갔는지 확인해볼까요??
SELECT puppy_id, COUNT(*)
FROM likes
GROUP BY puppy_id;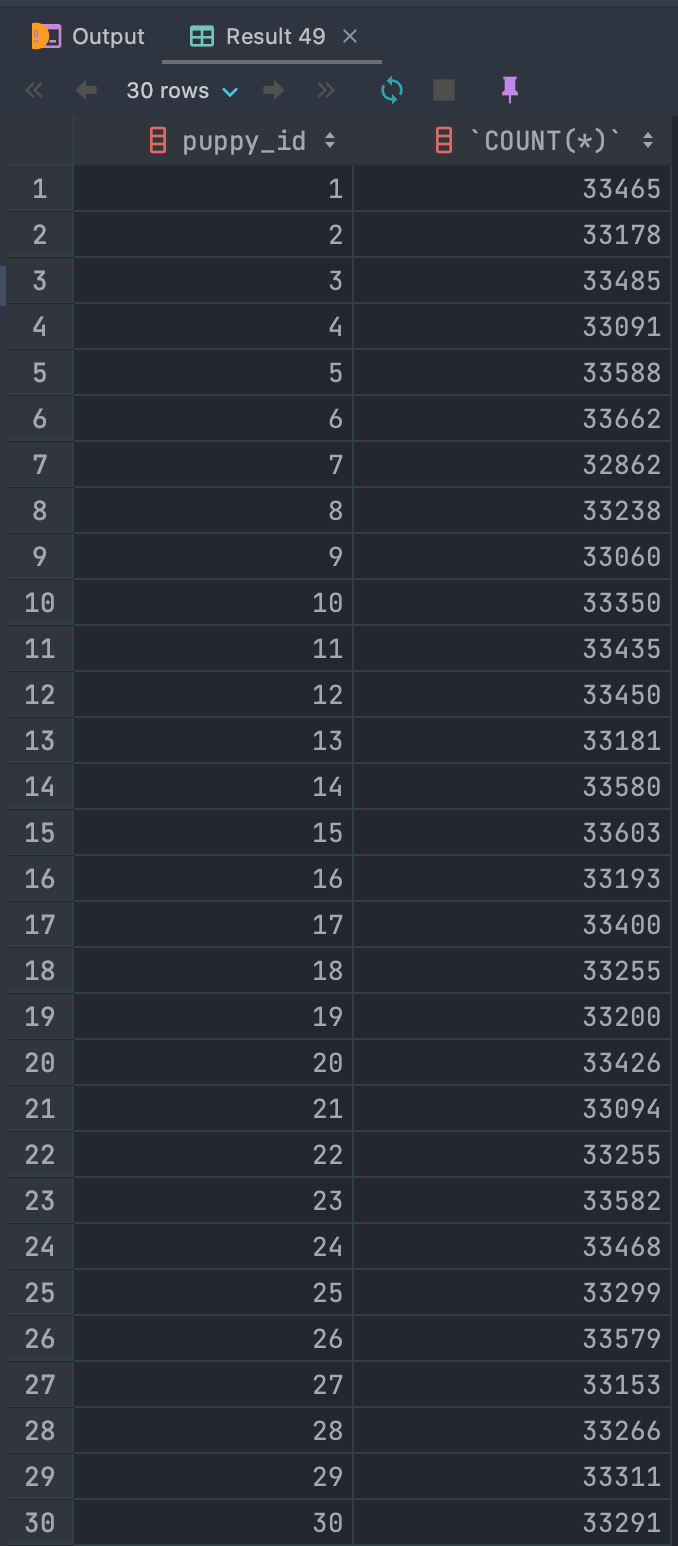
랜덤이라 그런지 꽤 균일하게 잘 들어간 모습입니다!!!
뿌듯하군요ㅎㅎ
누가 우승할지 한 치 앞을 볼 수 없을 정도로 치열하게 30마리의 강아지가 우승을 향해 달려가고 있습니다!!
그럼 이제 강아지 테이블에 데이터를 삽입해 볼까요??
SELECT *
FROM puppy;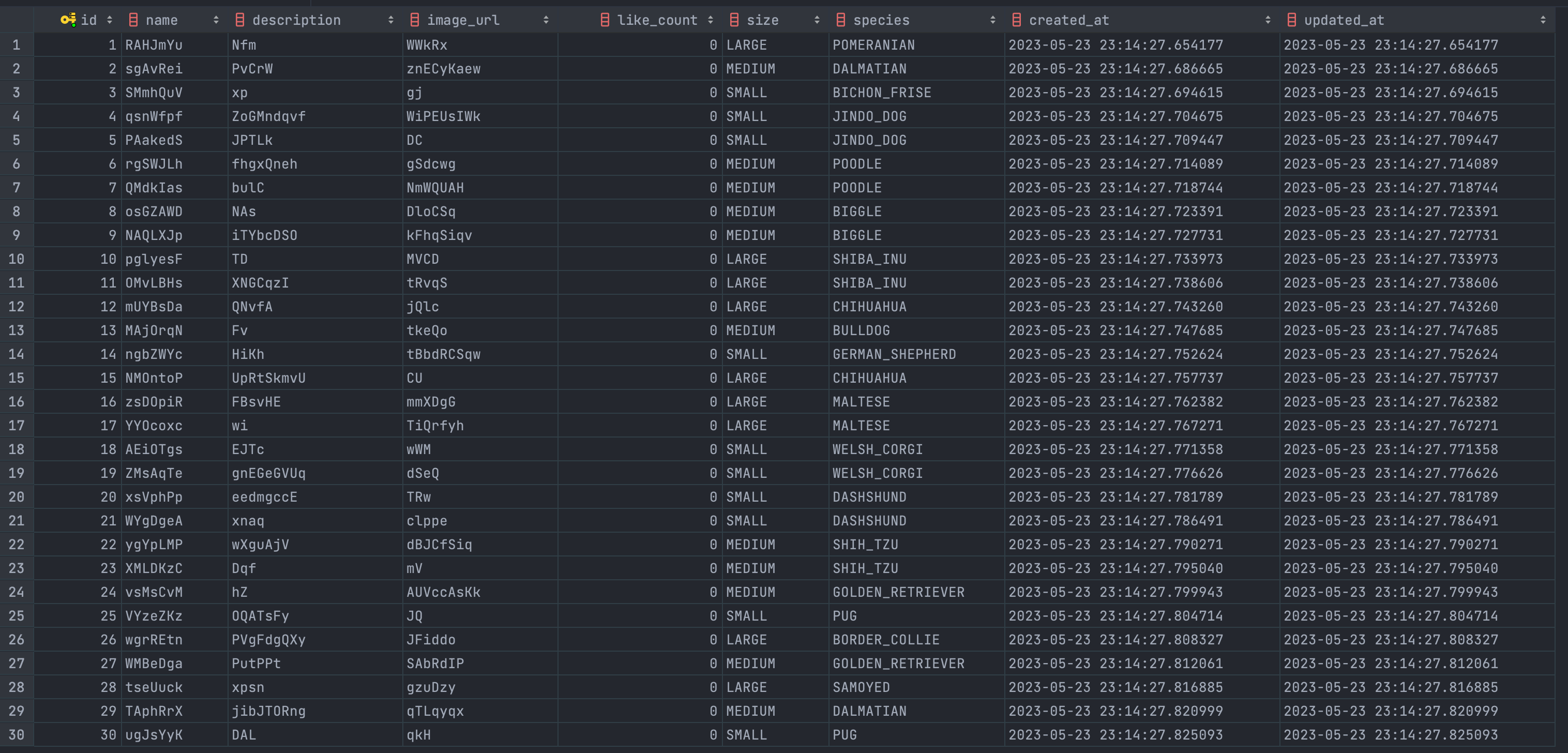
EasyRandom 을 통해서 Puppy 클래스도 30개의 객체를 만들어서 넣어 놨습니다!!
이름, 상세설명, 사진 주소, 사이즈, 종 모두 랜덤으로 넣었고, 좋아요 수만 0으로 exclude 해서 생성했습니다!
그럼 여기서...

집계 로직을 한 번 돌려 주면....
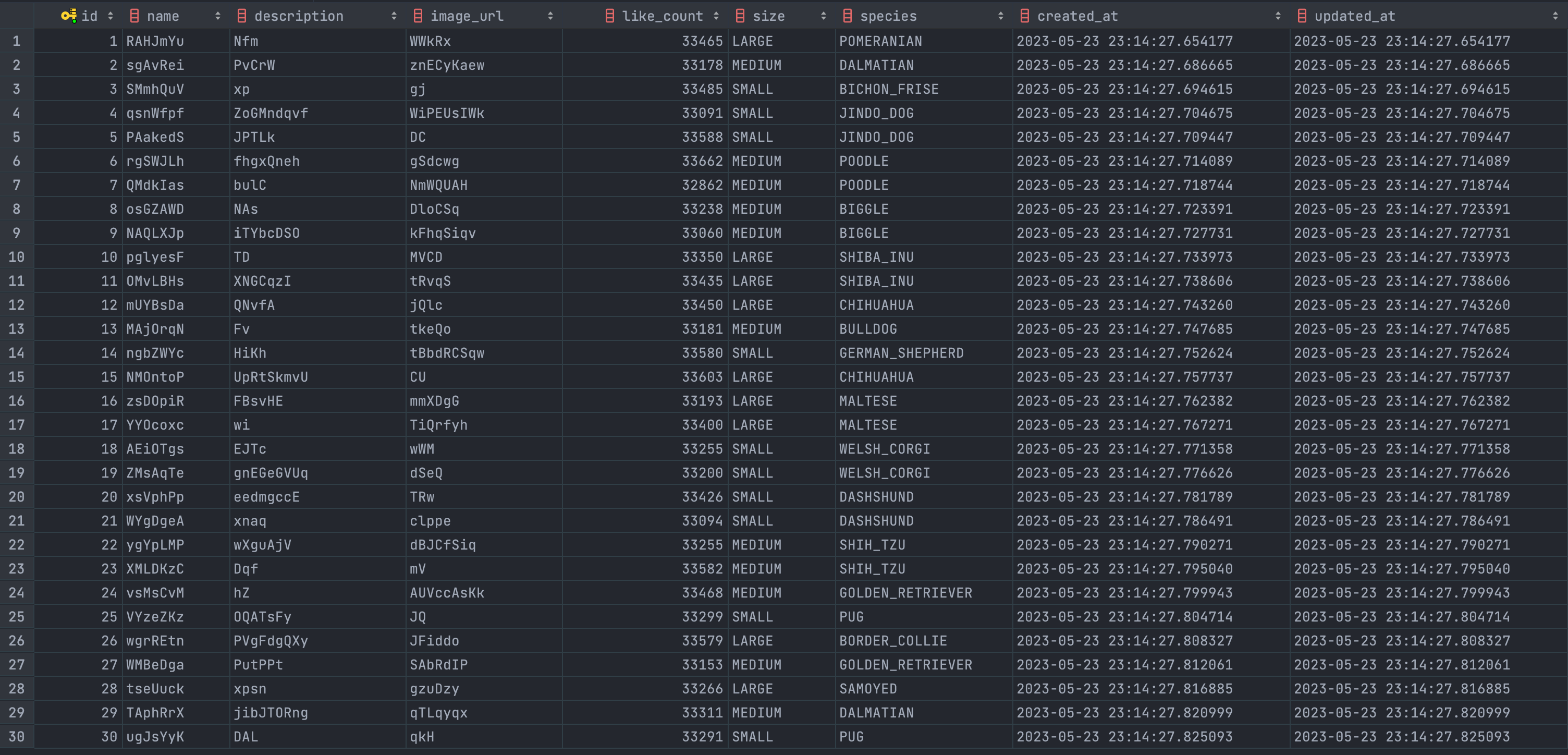
쨘!!!
모든 강아지들에게 좋아요 수가 제대로 갱신 됐습니다!!
집계 로직과 JPA BulkInsert에 대해서는 추후에 올려보도록 하겠습니다!!
전체 코드는 제 깃허브에서 확인하실수 있습니다!
감사합니다!!

매번 for문과 UUID로 더미 데이터 만드느라 힘들었는데 이런 방법이 있군요!! 잘 읽고 갑니다!