본 글은 GPT와 함께 제 수정한 글입니다.
“토큰 한도 넘어서 못 읽겠다”… 그래서 문서를 쪼개 봤다 (그리고 성능이 확 달라졌다)
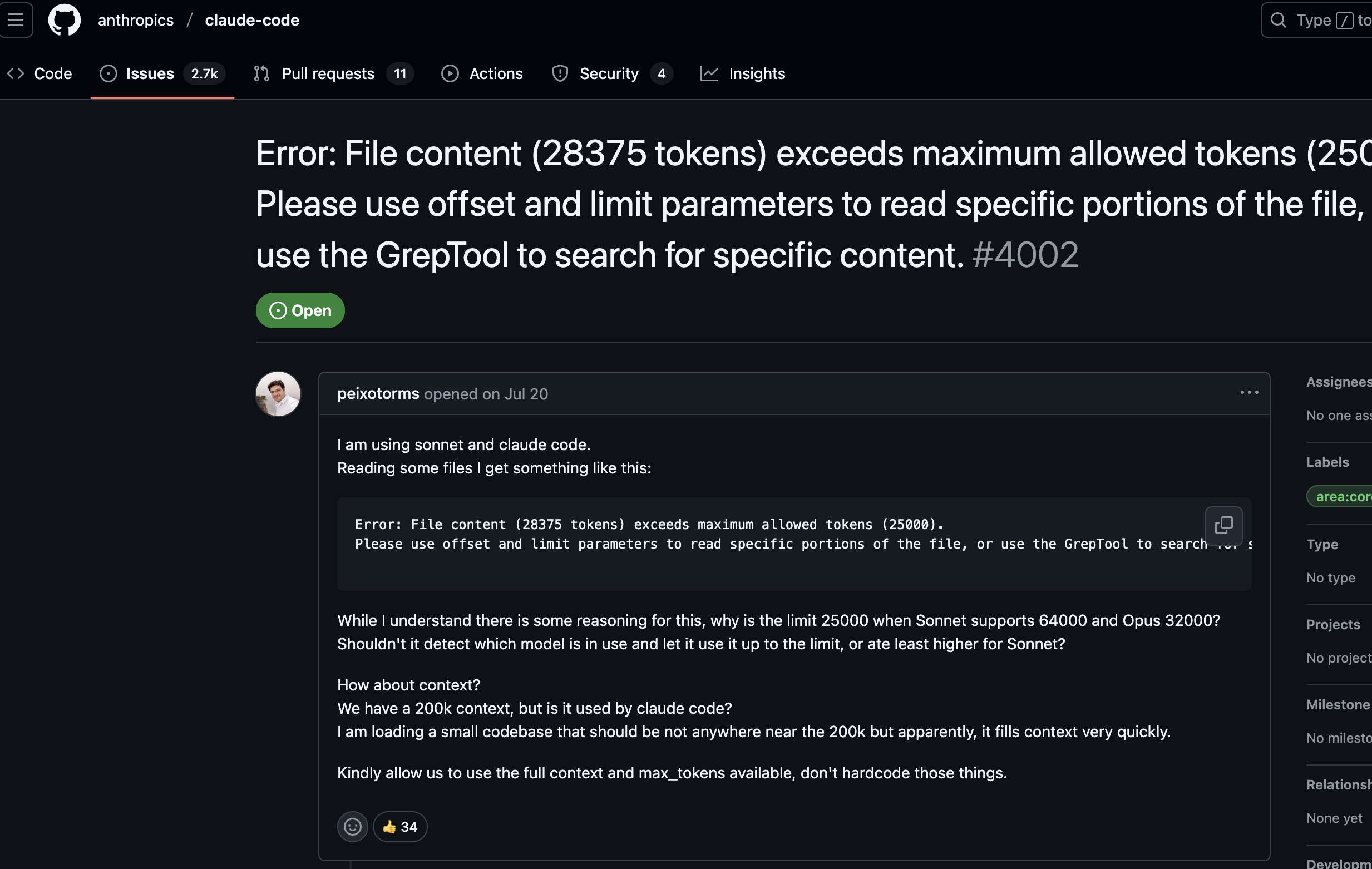
어느날 나를 찾아온(내 화면 캡쳐를 깜빡해서 동일한 에러 터진사람의 github issue)파일이 너무 길어서 토큰이 부족하다는 에러 https://github.com/anthropics/claude-code/issues/4002
확인해보니 내가 서비스를 만들면서 tasks.md로 일거리를 정리하고 있었는데 계속 추가되다 보니 2000라인에 가까운 경지를 보여주며 발생하였다.
“token limit exceed”
그러니까… 문서가 너무 길어서 모델이 아예 못 읽겠대요.
TASKS.md 파일(내가 일거리를 모아두는 파일)이 커지면서 단일 파일이 2,000+ 라인으로 불어났습니다.
결론부터 말하면, 문서를 구조화했더니 토큰 76% 절감, 탐색 70% 단축, 개발 효율 4배가 나왔습니다. “문서 구조가 곧 성능”이라는 걸 몸으로 배운 케이스였어요.
TL;DR
- 문제: 단일 파일이 커져서 token limit에 걸림 → AI 워크플로우 중단 + 사람도 찾기 지옥
- 해결: 180줄의 인덱싱 + 6개 전문 파일 + 완료 아카이브로 선택적 컨텍스트 로딩
- 성과: 토큰 42,000 → 10,100(-76.1%), 응답시간 ~75% 단축, 협업 효율 4x
- 교훈: “문서를 잘 쪼개는 일”은 단순 편집이 아니라 성능 최적화다.
왜 이런 일이 생겼을까? (Token limit가 ‘설계 요구’가 되는 순간)
- 한 파일이 커질수록 모델이 읽는 불필요한 문맥이 늘어난다.
- CLAUDE.md에 정의를 해둔 순간 각 세션에서는 이 파일을 무조건 읽고 시작한다.
- “완료한 과거 기록”과 “지금 필요한 실행 컨텍스트”가 섞이면 토큰 낭비가 커지고, 결국 한도를 넘어 읽지도 못합니다.
- 사람도 마찬가지예요. 필요한 순간에 필요한 조각만 보이게 하지 않으면, ‘찾는 시간’이 누적됩니다.
그래서 방향을 바꿨습니다. “문서를 줄이는 게 아니라, 컨텍스트를 설계한다.”
Before → After
Before
tasks.md2,000+ 라인- 완료/진행/계획/결제/보안/메타데이터 혼재
- 모델: token limit exceed, 입력 불가
- 사람: 분 단위 탐색 지연, 병렬 협업 어려움
After
tasks.md180 라인(마스터 허브)- 도메인별 6개 전문 파일
- 완료 23건은 아카이브로 분리
- 모델: 필요한 파일만 선택 로딩
- 사람: 초 단위 접근, 병렬 협업 OK
숫자로 본 성과 (정량) - 해당 세션에서 CLAUDE CODE에서 물어본 결과
- 토큰: 평균 42,000 → 10,100(-76.1%)
- 응답 시간: 단순 질의 15~25s → 3~5s, 복합 분석 35~50s → 8~12s (평균 ~75% 단축)
- 탐색 시간: 70% 단축(‘분’ → ‘초’)
- 개발 효율: 4배(도메인별 병렬 진행)
- 비용(예시 산정): 하루 50쿼리 기준 연 ~$8.7k API 비용 절감 + 시간 절감 ROI 연 ~$80k
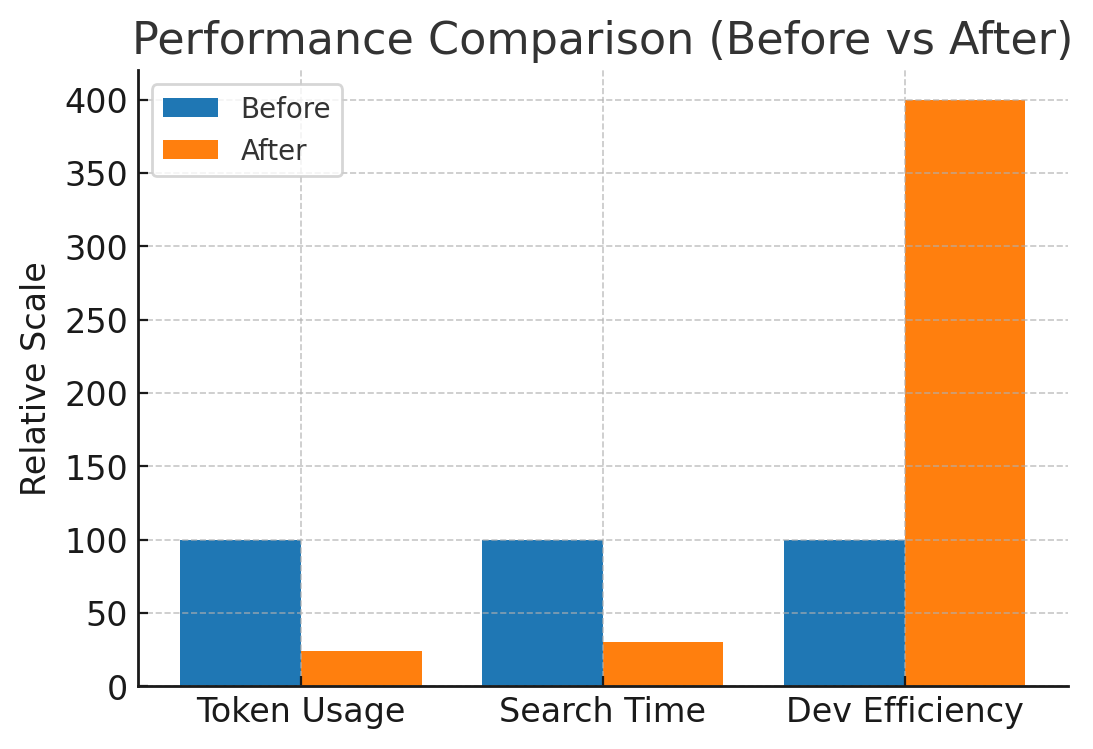
포인트: 전체를 한 번에 읽지 않는다. 필요한 순간에 최소 컨텍스트만 로드한다.
어떻게 바꿨나? (원칙 3가지)
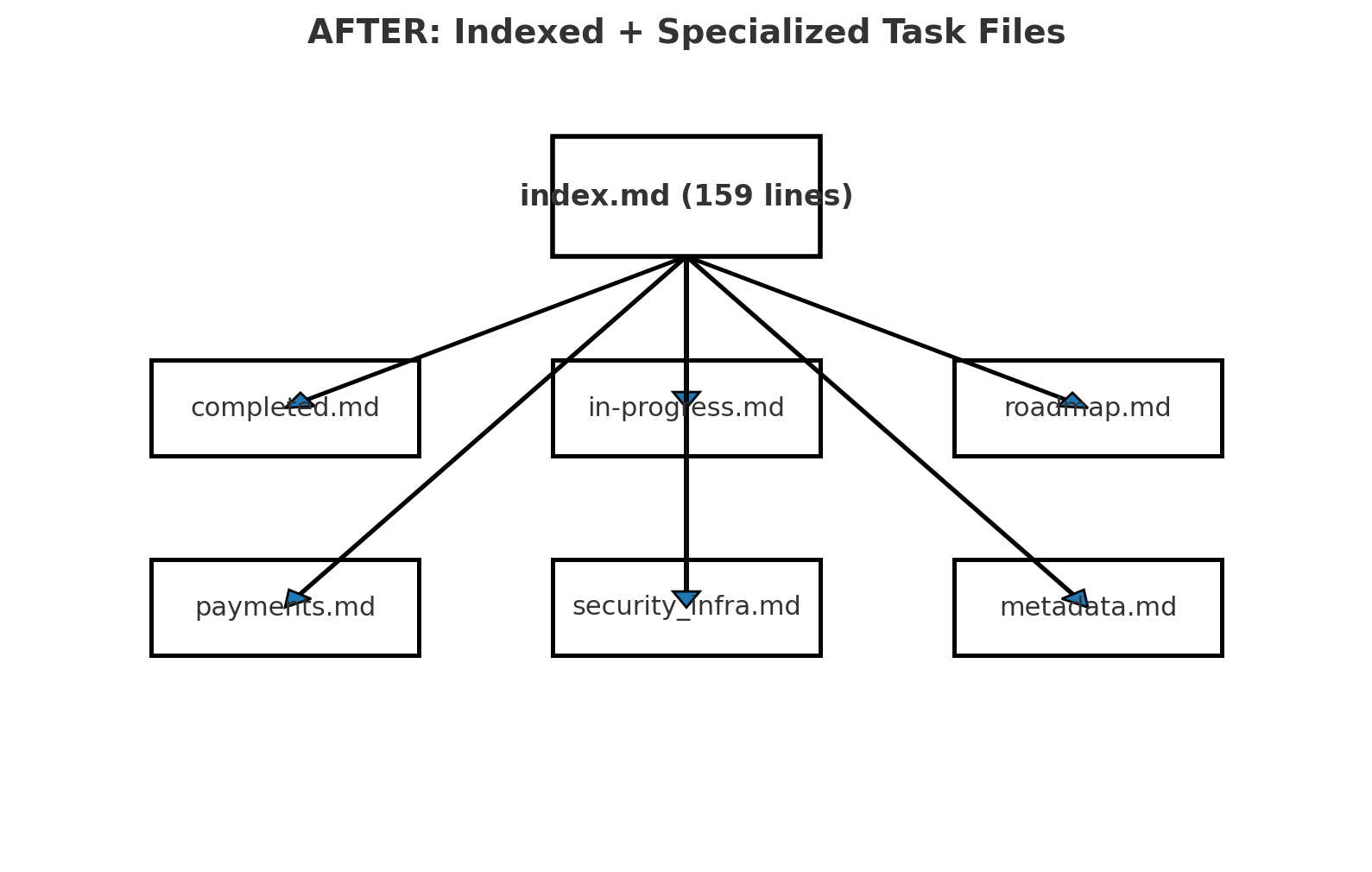
1) 허브를 만든다 (180줄 인덱스)
- 전체 그림, 빠른 시작, 핵심 링크만 남긴 “지도”
- 모델과 사람 모두 이 파일부터 본다
2) 도메인으로 쪼갠다 (6개 전문 파일)
- 예: 코어 개발 / 결제·구독 / 품질·테스트 / 인프라·보안 / PM / 미래확장
- 실제 TASK는 여기에 살고, 허브에서 링크로 진입
3) 완료는 과감히 아카이브
- 액티브 컨텍스트에서 과거 기록을 분리
- 필요하면 링크로 참조만 한다
구조 예시
/development
├─ index.md # Master Index (180 lines)
├─ completed-archive.md # 완료 아카이브 (23건)
└─ /current
├─ 01-core-dev.md
├─ 02-payments.md
├─ 03-quality-testing.md
├─ 04-infra-security.md
├─ 05-project-mgmt.md
└─ 06-future-expansion.md운영 규칙은 간단합니다.
- 일반 현황: 인덱스만
- 특정 업무: 인덱스 + 해당 1파일
- 우선순위: 인덱스의 우선순위 섹션만
- 완료 검토: 아카이브만

작은 디테일들이 성능을 만든다 (운영 팁)
- 파일명 접두어(01~, 02~)로 정렬 의미를 부여하면 탐색이 빨라진다..
- 교차 이슈(예: 보안×결제)는 Primary 도메인에 넣고, 다른 파일에서는 링크로만 참조.
- 인덱스 상단에 “무엇을 볼지 결정표”를 두면 신입/외부 협업자 온보딩이 쉬워진다.
- PR 리뷰 체크리스트에 “인덱스 링크 무결성”을 추가하면 구조가 오래 간다.
- 모델 프롬프트 룰에 “인덱스에서 앵커를 먼저 찾고, 필요한 파일만 열라”를 명시한다.
따라 하실 분들을 위한 10분 체크리스트
-
wc -l로 파일 길이부터 확인(2,000줄 넘으면 경고) - 완료·진행·계획·메타 섹션을 도메인 기준으로 다시 묶기
- 180줄 안쪽(개인 차 존재)으로 인덱스 제작(지도·우선순위·핵심링크)
- 완료 기록은 아카이브 분리, 본문엔 링크만
- 프롬프트/에이전트 룰에 선택적 로딩 명시
- 리뷰 체계에 링크 무결성 검사 추가
FAQ (짧게)
Q. 파일이 많아지면 더 헷갈리지 않나요?
A. 인덱스가 “어디로 갈지”를 결정해 준다. 허브 → 1파일로만 생각한다.
Q. 정보가 중복되는 건 어떻게 하죠?
A. Essential Duplication(필수 맥락만 최소 중복)만 허용하고, 나머지는 링크로 참조.
마무리: 문서는 UX고, 성능이 된다
처음엔 “읽기 좋게 정리하자”였는데, 끝나고 보니 토큰/시간/비용이 다 같이 좋아졌다.
AI를 붙여 일하는 시대에는, 문서 구조가 곧 모델 성능이고, 실행 속도입니다.
작게 쪼개고, 빠르게 도달하자. 그게 결국 ROI로 돌아온다.
tistory에 올라가는 글과는 아주 약간 차이가 있습니다.
https://developer-youn.tistory.com/196
