1. 컴퓨터구조
단순히 코드를 작성하고 실행할 수 있다고 해서 좋은 프로그래머라고는 할 수 없다. 진정한 실력있는 개발자가 되기 위해서는 컴퓨터의 구조를 아는것이 기본이라고 생각한다. 그렇기에 컴퓨터 구조를 안다면 얻을 수 있는 이점에 대해서 공부해보았다.
1-1. 컴퓨터 구조를 알아야 하는이유
문제 해결
학창 시절이나 인터넷으로 프로그래밍 강의를 들으면서 코드를 그대로 쳤는데도 제대로 실행되지않거나, 내가 작성한 코드가 다른 사람의 코드에서는 실행되지 않는 문제가 발생 할 때가 있다. 이러한 문제가 발생했을 때 '어떻게 해야하지?'라고 생각하는 경우는 컴퓨터는 코드만 작성하면 결과물을 내놓는 '미지의 대상'이라고 생각하기 때문이다.
컴퓨터 구조에 대해 공부하고 이해한다면 문제 상황을 빠르게 인식하고 분석하여 문제해결의 실마리를 찾을 수 있을것이다. 이러한 사고가 가능하다면 컴퓨터는 '미지의 대상'이 아닌 '분석의 대상'이 될 것이다.
성능, 용량, 비용
내가 웹사이트를 개발한다고 가정했을때, 내가 개발한 웹사이트를 이용자들에게 선보이려면 서버컴퓨터가 필요할 것이다. 서버 컴퓨터는 일반 컴퓨터와 달리 CPU, 메모리 등 한정된 자원에서의 최적을 선택을 할 수있어야한다. 또한 하드웨어적으로 뿐만아닌 소프트웨어적으로도 최선의 효율을 내기 위해서는 내 스스로가 컴퓨터 구조에 대해서 이해하고 있어야 최적의 컴퓨터 환경을 구축하고 그에 맞는 성능도 개발 할 수 있을것이다. 결국, 컴퓨터 구조를 이해한다면 입력과 출력에만 집중을 하는 개발을 넘어 성능, 용량, 비용까지 고려하는 개발자가 될 수 있는것이다.
확인 문제
- 컴퓨터 구조를 알아야하는 이유로 적절하지 않은 것은?
① 문제 해결을 위한 다양한 실마리를 찾을 수 있습니다.
② 프로그램을 빠르게 구현 할 수 있습니다.
③ 개발한 프로그램의 성능과 용량을 고려할 수 있습니다.
④ 개발한 프로그램의 비용을 고려할 수 있습니다.
답 2. 컴퓨터 구조를 알면 문제 해결에 대한 능력을 키울 수 있으며, 성능,용량, 비용을 고려하며 최적의 결과를 낼 수 있는 개발자가 될 수있다. 프로그램을 빠르게 구현하는 것은 프로그래밍적 능력이지. 다른 보기에 비해 컴퓨터구조를 알아야하는 이유로는 적절치 않다.
- 다음 설명의 빈칸에 들어갈 알맞은 내용을 보기에서 골라 써보세요
보기 : 미지의 대상, 분석의 대상
컴퓨터 구조를 이해하면 우리는 컴퓨터를 빈칸 1에서 빈칸 2으로 인식하게 됩니다.
답 빈칸 1 : 미지의 대상 , 빈칸 2: 분석의 대상
1-2. 컴퓨터 구조의 큰그림
컴퓨터 구조 지식에서 알아야 할 대표적인 두가지 지식이 있다. '컴퓨터가 이해하는 정보'와 '컴퓨터의 네 가지 핵심 부품'이다.
컴퓨터가 이해하는 정보
컴퓨터는 0과 1로 표현된 정보만을 이해한다. 그리고 이렇게 0과 1로 표현되는 정보에는 크게 두가지가 있는데 '명령어'와 '데이터'이다.
- 데이터(data) : 컴퓨터가 이해하는 숫자, 문자, 이미지, 동영상과 같은 정적인 정보
- 명령어(instruction) : 데이터를 움직이고 컴퓨터를 작동시키는 정보
컴퓨터의 4가지 핵심 부품
컴퓨터의 핵심 부품으론 '중앙처리장치(CPU, Central Processing Unit)', '주기억장치(Main Memory, 혹은 메모리)', '보조기억장치(secondary storage)', '입출력장치(input/ouput, I/O)'입니다.
주기억 장치에는 크게 RAM(Random Access Memory), ROM(Read Only Memory) 두가지가 있지만, 현재 공부하고 있는 교재에서는 주기억장치는 RAM이라 생각해도 무방
메모리
현재 실행되는 프로그램의 명령어와 데이터를 저장하고 있는 부품. 즉, 프로그램이 실행되려면 반드시 메모리에 저장되어있어야 한다.
실행되는 프로그램은 프로세스(Process)라고 한다. 추후 다룰 예정
프로그램이 빠르게 실행되기 위해서는 메모리의 데이터와 명령어가 정돈되어 있어햐한다. 메모리에 저장된 값에 빠르고 효율적으로 접근하기 위해 '주소'라는 개념이 사용된다.
CPU
cpu는 컴퓨터의 두뇌이다. 메모리에 저장된 명령어를 읽어들여 해석하고 실행한다. cpu의 내부 구성요소 중 중요한 세가지는 다음과 같다.
- ALU(Arithmetic Logic Unit) : 쉽게 말해 계산기, 계산만을 위해 존재하는 푸품. 컴퓨터 내부의 수행되는 계산의 대부분을 담당
- 레지스터(register) : CPU 내부의 임시 저장 장치. 프로그램을 실행하는데 필요한 값들을 임시로 저장한다. CPU내부의 여러개의 레지스터가 존재하고 각기 다른 이름과 역할을 가진다.
- 제어장치(CU; Control Unit) : 제어신호라는 전기 신호를 내보내고 명령어를 해석하는 장치.
- 메모리에 저장된 값을 읽고 싶을 땐 메모리읽기라는 제어신호를 보낸다.
- 메모리에 어떤 값을 저장하고 싶을 땐 메모리쓰기라는 제어신호를 보낸다.
보조기억장치
메모리는 실행되는 프로그램의 명령어와 데이터를 저장하지만, 두 가지 치명적인 약점이있다. 첫번째는 가격이 비싸 저장 용량이작고, 두번째는 전원이 꺼지면 저장된 내용을 잃는다는 것이다.
이에 메모리보다 크기가 크고 전원이 꺼져도 저장된 내용을 잃지 않는 메모리를 보조할 저장 장치를 보조기억장치라고 한다.
ex) USB, HDD, CD-ROM 등...
입출력장치
마이크, 스피커, 마우스, 처럼 컴퓨터 외부에 연결되서 컴퓨터 내부와 정보를 교환하는 장치
보조기억장치는 관점에 따라 입출력장치의 일종으로 볼 수 있다. 실제로 보조기억장치와 입출력장치를 주변장치라 통하기도 한다. 다만 보조기억장치는 일반적인 입출력장치에 비해 메모리를 보조하는 특별한 기능을 수행하는 입출력장치이다.
메인보드와 시스템 버스
지금까지 설명한 컴퓨터의 핵심부품들은 메인보드라는 판에 연결된다. 마더보드(mother board)라고도 부른다.
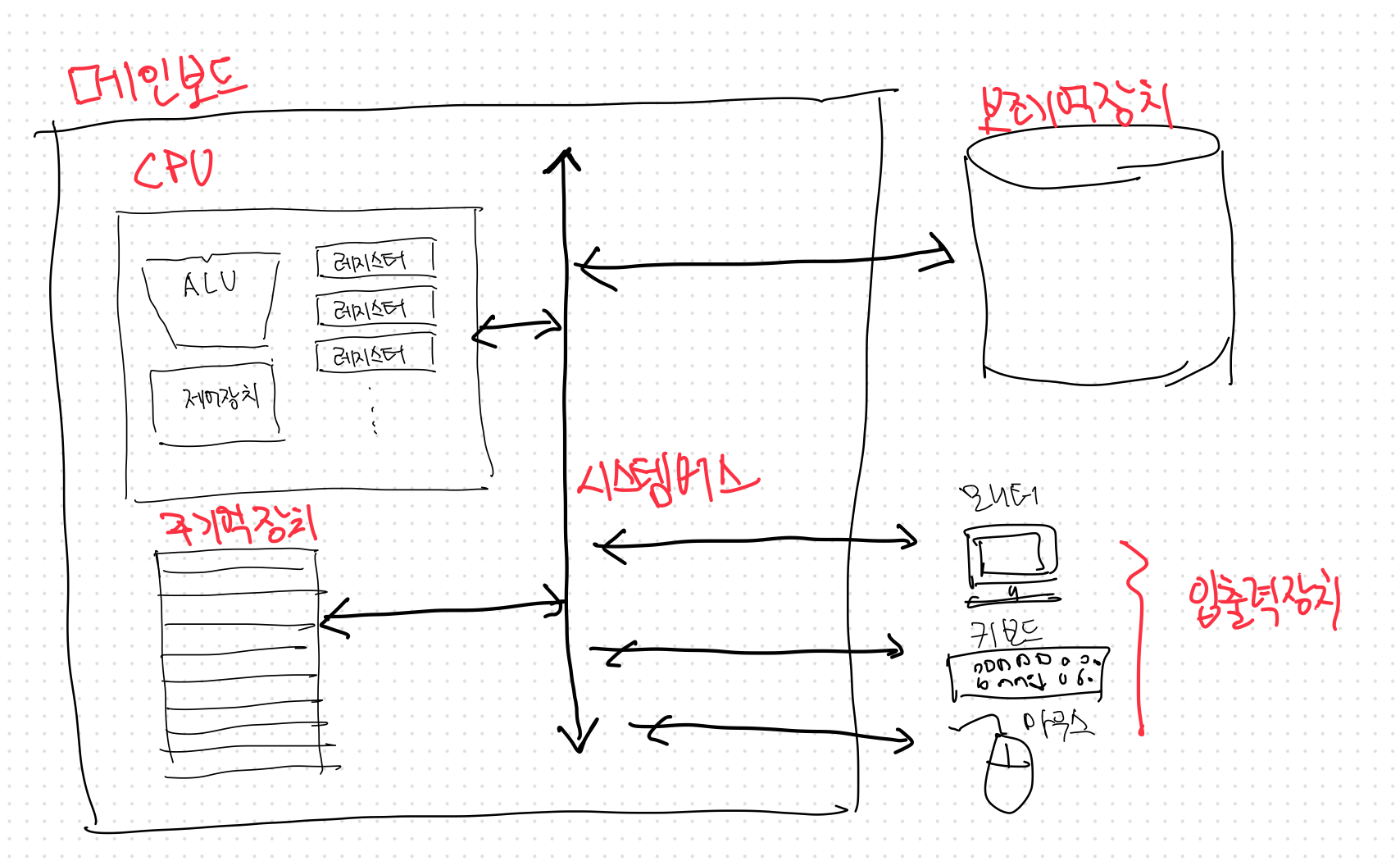
메인보드에 연결된 부품들은 내부의 버스(bus)라는 통로를 통해 정보를 주고 받는다.
여러 버스 가운데 가장 중요한 버스는 시스템버스이다.
시스템 버스는 주소를 주고받는 주소버스, 명령어와 데이터를 주고 받는 데이터버스, 제어신호를 주고받는 통로인 제어버스 세가지로 이루어져있다.
확인문제
- 다음 설명의 빈칸에 들어갈 알맞은 내용을 보기에서 골라 써보세요.
보기 : 명령어 , 데이터, CPU, 메모리, 보조기억장치
컴퓨터가 이해하는 정보에는빈칸 1와빈칸 2가 있습니다.
답 : 빈칸 1 - 명령어, 빈칸 2 - 데이터
-
컴퓨터의 네 가지 핵심 부품 중 명령어를 해석하고 실행하는 장치를 고르시오
① 보조기억장치
② 입출력장치
③ CPU
④ 주기억장치답 : 3.CPU
-
다음 설명의 빈칸에 들어갈 알맞은 내용을 써보세요.
프로그램이 실행되려면 반드시빈 칸에 저장되어 있어야 합니다.답 : 주기억장치
-
컴퓨터의 부품과 역할을 올바르게 짝지으세요.
가. 보조기억장치 ㄱ. 실행되는 프로그램 저장
나. 메모리 ㄴ. 보관할 프로그램저장답 : 가-ㄴ , 나-ㄱ
-
시스템 버스와 관련하여 옳지 않은 내용을 고르세요
① 시스템 버스는 컴퓨터의 핵심 부품을 분리시키는 버스입니다.
② 시스템 버스는 주소버스, 데이터 버스, 제어 버스로 구성되어 있습니다.
③ 메인보드 내부에는 시스템 버스를 비롯한 다양한 버스가 있습니다.
④ CPU가 메모리에 값을 저장할 때 주소버스, 데이터 버스, 제어버스를 모두 사용할 수 있습니다.답 : 1. 시스템 버스는 핵심 부품들을 연결한 메인보드에서 정보를 주고 받는 통로이다.
2. 데이터
컴퓨터는 0과 1로 모든 정보를 표현하고, 0과 1로 표현된 정보만을 이해할 수있다.
컴퓨터가 표현하는 정보단위를 학습하고, 0과 1만으로 숫자를 표현하는 방법을 배워본다.
2-1. 0과 1로 숫자를 표현하는 방법
정보단위
컴퓨터는 0또는 1밖에 이해하지 못한다. 0과 1을 나타내는 가장 작은 단위를 비트(bit)라고 한다.
- 바이트(byte) : 여덟 개의 비트를 묶은 단위로 비트보다 한 단계 큰 단위. 1바이트는 8비트 이므로 2^8(256)개의 정보를 표현할 수 있다.
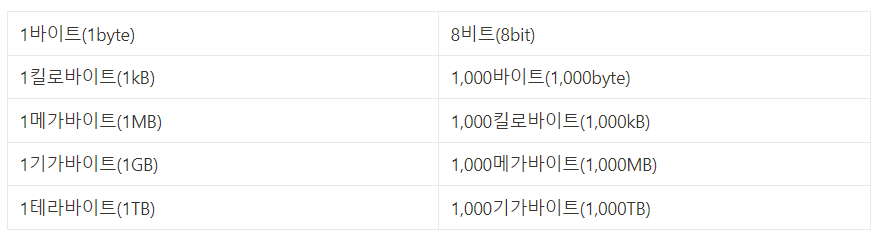
1kB를 1,024byte같이 표현하는 잘못된 관습이다 . 이전 단위를 1,024개 묶어 표현한 단위는 KiB,MiB,GiB,TiB이다.
중요한 정보 단위중 워드라는 단위도 있다. 워드란 CPU가 한번에 처리할 수 있는 데이터의 크기를 의미한다. CPU마다 다르지만 현대 컴퓨터의 워드 크기는 대부분 32비트 또는 64비트이다.
이진법
수학에서 0과 1만으로 모든 숫자를 표현하는 방법을 이진법(binary)이라고 한다. 우리는 일상적으로 십진법(decimal)을 사용한다.
이진수를 표기할 때는 1000(2)혹은 앞에 0b를 붙여서 0b1000처럼 표기한다.
이진수의 음수표현
이진수의 음수표현 2의 보수를 구해서 이 값을 음수로 간주한다. 사전적의미로는 '어떤 수를 그보다 큰 2^n에서 뺀 값'을 의미하지만 이진수를 0과1을 뒤집어서 1을 더하면 그 수가 2의 보수이다.
하지만 이진수만 보고 음수, 양수를 판별하기는 쉽지않다. 이를 위해 컴퓨터 내부에서는 플래그를 사용하여 구분한다.
십육진법
이진법은 0과 1만으로 모든수를 표현하다보니 숫자의 길이가 너무 길어진다는 단점이 있었고, 이를 보완하기 위해 십육진법도 자주 사용하게 되었다. 십육진법은 수가 15를 넘어가는 시점에 자리 올림을 하는 숫자표현방식이다.
확인 문제
-
2000MB는 몇 GB인가요?
답 : 1000MB는 1GB이므로, 2GB
-
다음 중 옳지 않은 것을 골라보세요.
① 1000GB는 1TB와 같습니다.
② 1000kB는 1MB와 같습니다.
③ 1000MB는 1GB와 같습니다.
④ 1024bit는 1byte와 같습니다.답 : 1byte는 8bit이다.
-
1101(2)의 음수를 2의 보수 표현법으로 구해보세요.
답 : 1101을 뒤집으면 0010, 1을 더하면 0011
-
DA(16)을 이진수로 표현하면?
답 : D는 13이므로 1101 , A는 10이므로 1010 즉 11011010
-
이진수와 더불어 십육진수가 많이 사용되는 대표적인 이유는 무엇인가요?
① 이진수와 십육진수 간의 변환이 쉽기 때문입니다.
② 십육진수에 비해 이진수로 표현되는 글자 수가 일반적으로 적기 때문입니다.
③ 십육진수가 십진수보다 일상적으로 더 많이 사용되기 때문입니다.
④ 컴퓨터는 이진수를 이해하지 못하기 때문입니다.답: 1. 십육진수의 각 자릿수들을 하나씩 이진수로 변환하면 간단하다. 나머지 보기들은 틀린 사례이다.
2-2. 0과 1로 문자를 표현하는 방법
컴퓨터는 0과 1로밖에 이해하지 못하지만 사용자들이 입력하는 문자를 어떻게 이해 할 수 있는지 학습한다.
문자집합과 인코딩
컴퓨터가 인식하고 표현할 수 있는 문자의 모음을 문자집합(Character Set)이라고 한다. 컴퓨터는 문자 집합에 속해있는 문자를 이해할 수 있고, 반대로는 이해하지 못한다.
문자 집합에 속해 있다고 해서 컴퓨터가 그대로 이해할 수 있는 건 아니다. 문자를 0과 1로 변환해야 컴퓨터가 이해할 수 있다. 이 변환 과정을 문자 인코딩(Character encoding)이라 한다.
인코딩의 반대 과정, 즉 0과 1을 이루어진 문자를 사람이 이해할 수 있는 문자로 변환 과정을 문자 디코딩(character decoding)이라고 한다.
아스키 코드
아스키, ASCII는 초창기 문자 집합 중 하나로, 7비트로 표현되는데 7비트로 표현할 수 있는 정보의 가짓수는 2^7개로 총 128개의 문자를 표현 할 수 있다.
실제로는 8비트를 사용하지만 1비트는 패리티 비트라고 불리는 오류 검출을 위해 사용되는 비트로, 실질적으로는 7비트만 사용된다.
EUC-KR
아스키 코드로는 영어권 외의 나라들의 언어를 표현하는데에 한계가 있으므로 고유한 문자 집합과 인코딩 방식이 필요하다고 생각했고. 이런 이유로 발샐한 한글 인코딩 방식이다.
한글의 인코딩 방식으론 초성,중성,종성의 집합으로 이루어진 완성형인코딩 방식과 초성, 중성, 종성에 해당하는 코드를 합하여 하나의 글자 코드를 만드는 조합형 인코딩방식이 있다.
EUC-KR은 대표적인 완성형 인코딩 방식이다. 즉 한글 단어에 2바이트 크기의 코드를 부여한다.
하지만 EUC-KR방식으론 2,350개 정도의 한글 단어를 표현 할 수 있으므로 한계가 있었고, 이를 조금이나마 해결하기 위한 것이 마이크로소프트의 CP949이다.
유니코드와 UTF-8
EUC-KR같이 각 나라별로 인코딩 방식을 만든다면 각 나라의 방식을 알아야하는 번거로움이 있었고, 모든 언어를 아우르는 문자 집합과 통일된 표준 인코딩 방식이 등장했고, 이는 유니코드문자 집합니다.
현대 문자를 표현할 때 가장 많이 사용되는 표준 문자 집합이며, 문자 인코딩 세계에서 매우 중요한 역할을 맡고 있다.
유니코드는 글자에 부여된 값 자체를 인코딩된 값으로 삼지 않고, 이 값을 다양한 방법으로 인코딩 한다. 방법에는 크게 UTF-8, UTF-16, UTF-32등이 있다.
확인 문제
- 68쪽의 아스키 코드를 참고하여 아래의 아스키 코드를 디코딩한 내용을 써 보세요.
104 111 110 103 111 110 103 -> ????답 : hongong
-
다음 중 EUC-KR 인코딩에 대한 설명 중 옳지 않은 것을 고르세요.
① 한국어를 표현할 수 있는 인코딩 방식입니다.
② 조합형 인코딩 방식 입니다.
③ 하나의 완성된 한글 글자에 코드를 부여합니다.
④ 모든 한글을 표현할 수 없습니다.답 : 2. 완성형 인코딩 방식
-
유니코드 문자 집합에서 '안'에 부여된 값은 C548(16), '녕'에 부여된 값은 B155(16)입니다. '안녕'을 UTF-8로 인코딩한 값을 구해보세요.
답 : C548의 이진수는 1100 0101 0100 1000, B155는 1011 0001 0101 0101, 이므로 UTF-8로 인코딩 한 값은 11101100 10010101 10001000, 11101011 10000101 10010101
3. 명령어
컴퓨터는 명령어를 처리하는 기계이다. 명령어는 컴퓨터를 실직적으로 작동시키는 매우 중요한 정보이다. 프로그래밍 언어로 작성된 소스코드는 컴퓨터 내부에서 명령어로 변환되어 실행된다. 어떻게 프로그래밍 언어가 명령어가 되는지 학습한다.
3-1. 소스 코드와 명령어
고급언어와 저급언어
프로그래밍언어는 컴퓨터가 이해하는 언어가 아닌 사람이 이해하고 작성하기 쉽게 만들어진 언어이다. 이렇게 '사람을 위한 언어'를 고급언어라고 한다.
반대로 컴퓨터가 직접 이해하고 실행할 수 있는 언어를 저급언어라고 합니다. 저급언어는 명령어로 이루어져 있다.
저급언어에는 두가지 조율가 있고, 그 두가지는 기계어와 어셈블리어이다.
기계어는 0과 1의 명령어 비트로 이루어진 언어이다. 기계어는 오로지 컴퓨터만을 위해 만들어진 언어이므로 사람이 이해하기 어렵다. 그래서 등장한 저급 언어가 어셈블리어이다. 어셈블리어는 기계어를 읽기 편한 형태로 변환한 것이다.
컴파일 언어와 인터프리터 언어
그렇다면 고급언어에서 저급언어로 어떻게 변환되는 것일까? 여기에는 크게 두가지, 컴파일방식과 인터프리터방식이 있습니다. 컴파일 방식으로 작동하는 언어를 컴파일 언어, 인터프리터 방식으로 작동하는 언어를 인터프리터 언어라고 한다.
컴파일 언어
컴파일 언어는 컴파일러에 의해 소스 코드 전체가 저급언어로 변환되어 실행되는 고급 언어이다. 컴파일 언어로 작성된 코드를 저급언어로 변환되는 과정을 컴파일이라고 한다. 그리고 컴파일을 수행해주는 도구를 컴파일러라고 한다.
컴파일러가 저급언어로 변환하던중 소스 코드내에서 오류를 하나라도 발견한다면 컴파일러는 컴파일에 실패하게 된다.
컴파일이 성공적으로 수행되어 저급언어로 변환된 코드를 목적코드, Object code라고 한다.
인터프리터 언어
인터프리터 언어는 인터프리터에 의해 한줄씩 실행되는 고급 언어입니다. 대표적으로는 Python이 있다.
인터프리터 언어는 소스코드를 한줄씩, 한줄씩 차례로 실행합니다. 그리고 한줄씩 저급언어로 변환해주는 도구를 인터프리터라고 한다. 코드 전체를 저급언어로 변환하는 시간을 기다릴 필요가 없고, N번째 줄에 오류가 있더라도 N-1번째 줄까지는 올바르게 수행된다.
일반적으로 인터프리터언어는 컴파일 언어보다 느리다.
목적파일 vs 실행파일
목적코드로 이루어진 파일을 목적파일이라고 부른다. 마찬가지로 실행코드로 이루어진 파일을 실행 파일이라고 부른다. .exe확장자를 가진 파일이 대표적이다.
목적코드가 실행일이 되기 위해서는 링킹이라는 작업을 거쳐야 한다.
확인문제
-
다음 중 고급 언어가 아닌 것을 모두 고르세요.
① 컴파일 언어
② 인터프리터 언어
③ 기계어
④ 어셈블리어답 : 3,4 - 두 개는 모두 저급 언어이다.
-
다음 중 옳지 않은 것을 고르세요.
① 컴파일 언어는 한 줄이라도 소스 코드상에 오류가 있다면 실행될 수 없습니다.
② 일반적으로 컴파일 언어보다 인터프리터 언어가 더 빠릅니다.
③ 인터프린터는 인터프리터 언어로 작성된 소스 코드를 한 줄씩 저급언어로 변환하여 실행합니다.
④ 컴파일러는 컴파일 언어로 작성된 소스 코드 전체를 목적코드로 변환합니다.답 : 2. 인터프리터 언어는 한줄씩 저급언어로 변환하여 실행하므로, 전체소스코드를 저급언어로 변환하여 실행하는 컴파일언어보다 일반적으로는 느리다.
3-2. 명령어의 구조
기계어나 어셈블리어를 이루는 각각의 명령어를 자세히 들여다보고 학습한다.
연산 코드와 오퍼랜드
아래 그림의 색 배경 필드는 명령의 '작동', 달리 말해 '연산'을 담고 있고 흰색 배경 필드는 '연산에 사용할 데이터'또는 '연산에 사용할 데이터가 저장된 위치'를 담고 있다.
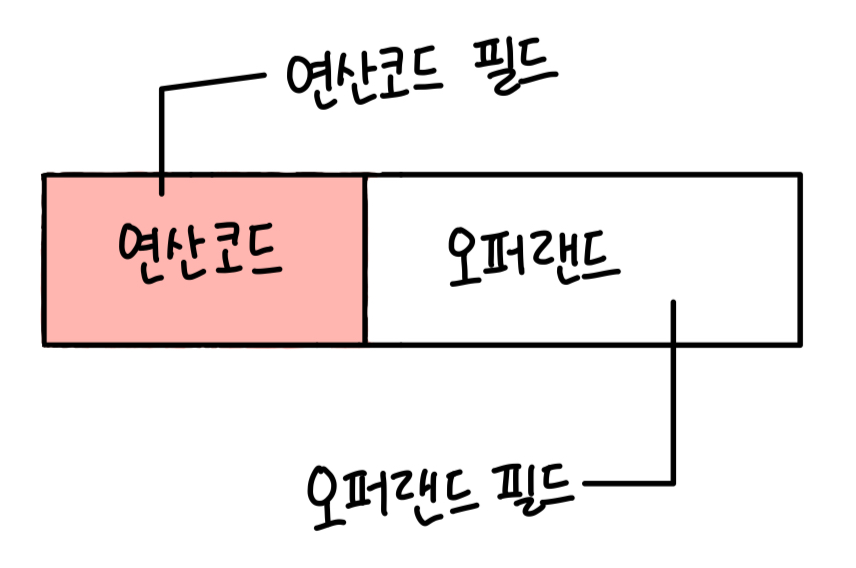
명령어는 연산코드와 오퍼랜드로 구성되어 있다. '명령어가 수행할 연산'을 연산코드라하고, '연산에 사용할 데이터' 또는 '연산에 사용할 데이터가 저장된 위치'를 오퍼랜드라고 한다.
연산코드는 연산자, 오퍼랜드는 피연산자라고도 부른다.
오퍼랜드
오퍼랜드 필드에는 데이터 또는 메모리나 레지스터 주소가 올 수 있다. 보통 데이터를 직접 명시하기 보다는 데이터가 저장된 위치, 즉 메모리 주소나 레지스터리 이름이 담긴다. 그래서 주소필드라고 부르기도 한다.
오퍼랜드가 하나도 없는 명령어를 0-주소 명령어, 하나라면 1-주소 명령어, 두개인 명령어를 2-주소 명령어, 세 개인 명령어를 3-주소 명령어라고 한다.
연산 코드
연산 코드의 종류는 매우 많지만, 가장 기본적인 연산 코드 유형은 네가지로 나눌 수있다.
- 데이터 전송
- 산술/논리연산
- 제어흐름 변경
- 입출력제어
주소지정방식
오퍼랜드 필드를 주소 필드라고 부르기도 한다. 라고 앞에서 학습했다.
굳이 데이터를 담지 않고 주소를 담는 이유가 뭘까? 이는 명령어 길이 때문이다. 하나의 명령어가 n비트로 구성되어 있고, 그중 연산 코드 필드가 m비트라고 가정 해보면, 1-주소 명령어라 할지라도 n-m 비트가 되고, 주소가 많을 수록 오퍼랜드 필드의 크기는 작아지기 때문이다.
이 때 연사코드에 사용할 데이터가 저장된 위치, 즉 연산의 대상이 되는 데이터가 저장된 위치를 유효주소라고 한다. 이렇듯 오퍼랜드 필드에 데이터가 저장된 위치를 명시할 때 연산에 사용할 데이터 위치를 찾는 방법을 주소 지정 방식이라고 한다.
주조 지정 방식은 유효 주소를 찾는 방법이다.
즉시 주소 지정 방식
연산에 사용할 데이터를 오퍼랜드 필드에 직접 명시하는 방식. 이런 방식은 표혈 할 수있는 데이터의 크기가 작아지는 단점이 있지만, 연산에 사용할 데이터를 메모리나 레지스터로부터 찾는 과정이 없기 때문에, 다른 지정방식 들보다 빠르다.
직접 주소 지정 방식
오퍼랜드 필드에 유효 주소를 직접적으로 명시하는 방식. 표현 할 수 있는 오퍼랜드 필드의 길이가 연산 코드의 길이 만큼 짧아져 표현 할 수 있는 유효 주소에 제한이 생길 수 있다.
간접 주소 지정방식
유효 주소의 주소를 오퍼랜드 필드에 명시한다. 직접 주소 지정방식보다 표현할 수 있는 유효 주소의 범위가 더 넓어졌지만, 두 번의 메모리 접근이 필요하기 때문에 앞선 방식보다는 일반적으로 느리다.
레지스터 주소 지정방식
직접 주소 지정 방식과 비슷하게 연산에 사용할 데이터를 저장한 레지스터를 오퍼랜드 필드에 직접 명시하는 방법.
일반적으로 CPU 외부의 메모리에 접근하는 것보다 CPU내부의 레지스터에 접근하는 것이 더 빠르지만 표현할 수 있는 레지스터 크기에 제한이 생길 수 있다.
레지스터 간접 주소 지정 방식
연산에 사용할 데이터를 메모리에 저장하고, 유효주소를 저장한 레지스털르 오퍼랜드 필드에 명시하는 방법. 간접 주소 지정방식과 비슷하지만 메모리에 접근하는 횟수가 한번으로 줄어듦으로 간접 주소 지정방식보다 빠르다.
주소지정방식 정리
연산에 사용할 데이터를 찾는 방법을 주소지정방식이라고 한다. 연산에 사용할 데이터가 저장된 주소를 유효 주소라고 한다.
- 즉시 주소 지정방식 : 연산에 사용할 데이터
- 직접 주소 지정방식 : 유효주소(메모리 주소)
- 간접 주소 지정방식 : 유효주소의 주소
- 레지스터 주소 지정방식 : 유효주소(레지스터 주소)
- 레지스터 간접 주소 지정방식 : 유효 주소를 저장한 레지스터
확인 문제
-
명령어에 대한 설명 중 옳지 않은 것을 고르세요.
① 명령어는 연산 코드와 오퍼랜드로 구성된다.
② 연산 코드 필드에는 메모리 주소만 담을 수 있다.
③ 오퍼랜드 필드는 여러 개 있을 수 있습니다.
④ 명령어에 연산에 사용할 데이터를 직접 명시할 경우 표현할 수 있는 데이터의 크기는 연산 코드의 크기만큼 작아집니다.답 : 2 - 오퍼랜드 필드에 메모리주소와 데이터를 담을 수 있다.
-
아래 그림 속 CPU에는 R1, R2라는 레지스터가 있고, 메모리 5번지에 100, 6번지에 200, 7번지에 300이 저장되어 있습니다. 아래 명령어를 레지스터 간접 주소 지정방식으로 수행한다면 결과는 어떻게 나올까?
메모리 빈칸 1번지 속 빈칸 2이란느 값을 CPU로 가지고 온다.
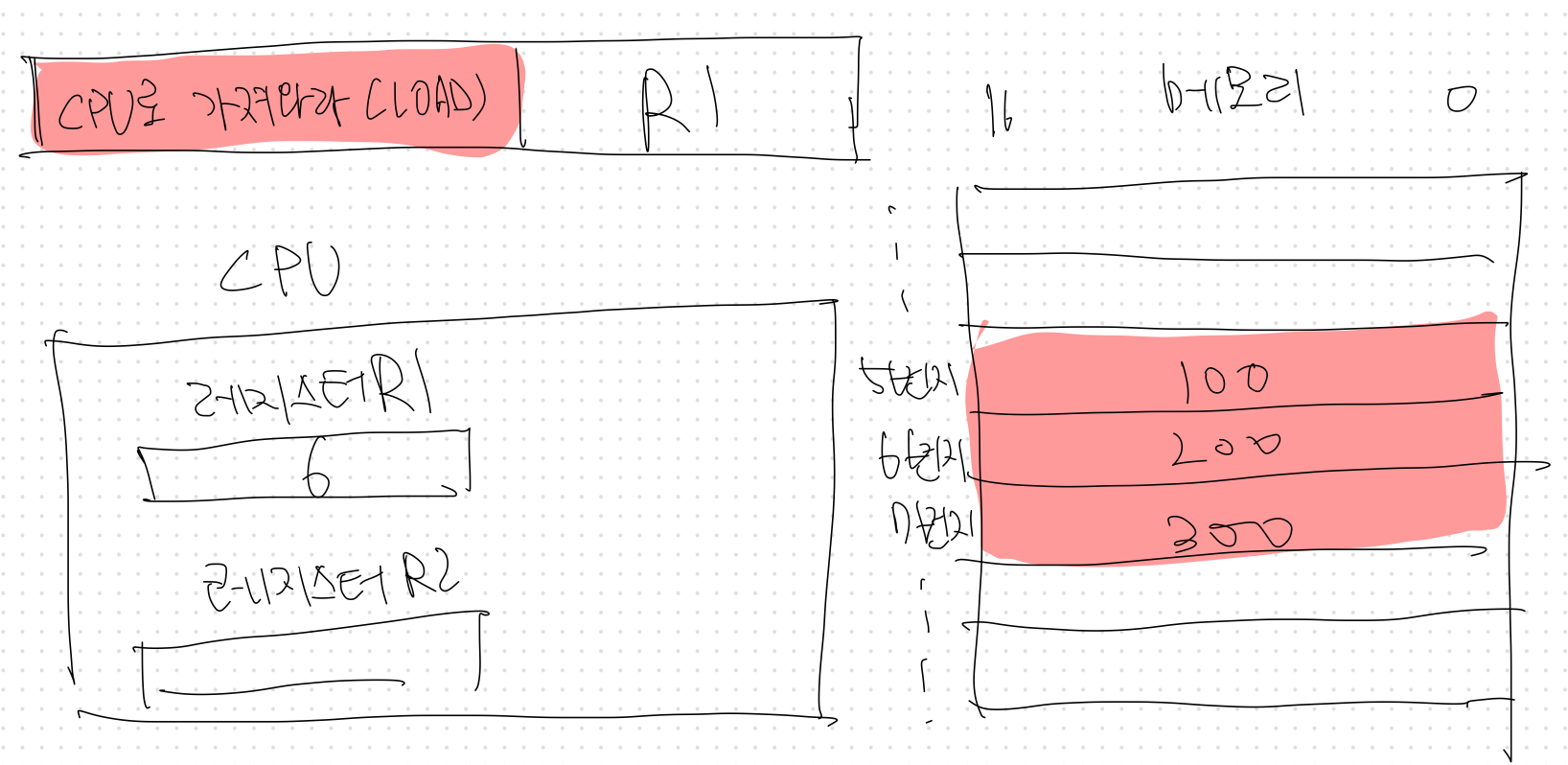
답 : 빈칸 1 - 6, 빈칸 2 - 200, 레지스터 간접 주소 지정 방식
추가 숙제
스택, 큐
https://velog.io/@betaa06/Apple.py-%EC%8A%A4%ED%83%9D-%ED%81%90
