
CS공부 13일차. 오늘은 OS에 대해 정리해보았습니다.
Process
-
프로세스 vs 스레드 : 프로세스는 OS로부터 자원을 할당받은 작업의 단위이고 스레드는 프로세스 내부에서 프로세스의 자원을 다른 프로세스들과 공유하는 CPU 실행 단위입니다. 스레드는 프로세스 안에 여러개 존재할 수도 있고 하나 존재할 수도 있습니다. 여러개 존재할 경우 stack, register set, PC만 독립적으로 가지고 code와 data 영역, OS 자원은 공유합니다.
-
멀티 스레드 vs 멀티 프로세스 : 멀티 프로세스는 다른 프로세스가 종료되어도 영향을 받지 않지만 멀티스레드보다 공간을 많이 차지하는 단점이 있습니다.
-
스택을 스레드마다 독립적으로 할당하는 이유 : 스택에는 함수에 필요한 파라미터, 함수 내 변수 등이 저장되어서 스택을 독립적으로 할당받는 것은 독립적인 함수 실행이 가능하다는 것을 의미하기 때문에
-
PC 레지스터를 스레드마다 독립적으로 할당하는 이유 : context를 독립적으로 기록해야 해서
-
멀티 프로세스 대신 멀티 스레드를 사용하는 이유 : 공간과 자원을 절약하기 위해서
-
Context Switching : 문맥 교환이라는 뜻으로 진행되고 있는 프로세스나 스레드가 system call이나 interuppt로 중단되어 다른 프로세스가 실행되어야 할때, PCB에 프로세스의 context를 저장하고 다음 프로세스를 불러오는 과정
-
인터럽트 : 인터럽트가 발생하면 PC와 register를 PCB에 저장하고 Interrupt 처리 루틴에 CPU 제어를 넘깁니다. 인터럽트는 하드웨어 인터럽트와 소프트웨어 인터럽트가 있는데 소프트웨어 인터럽트에는 System call과 예외처리 등이 있습니다.
-
시스템 콜 : 사용자 프로그램이 OS에서 제공하는 기능을 사용하기 위해 커널함수를 호출하는 인터페이스입니다.
-
fork(), exec(), exit(), wait() : fork는 자식 생성, exex은 덮어쓰기, exit는 종료, wait는 대기
-
Process Synchronization : 멀티프로세스들의 공유되는 정보가 일치하도록 하는 것
-
IPC : Interprocess Communication의 약자로 커널을 통해 메시지를 전달하는 방법과 shared memory를 통해 주소 공간을 공유하는 방법이 있습니다.
-
child process와 zombi process : 자식은 부모의 PCB와 data, heap, stack등을 복사하고 fork()함수로 생성됩니다. 좀비 프로세스는 프로세스는 종료되었는데 메모리상에 정보가 남아있는 상태입니다.
-
프로세스 스케줄러 : 단기 스케쥴러, 중기 스케쥴러, 장기 스케쥴러로 나뉘는데 장기는 시작 프로세스중 어떤 것을 ready queue에 보낼지 결정하고 중기 스케쥴러는 여유공간을 마련하기 위해 프로세스를 통째로 메모리에서 디스크로 쫓아내며(swapping) 단기 스케쥴러는 어떤 프로세스를 다음에 running할지 결정합니다.
Dead Lock
-
정의 : 프로세스들이 서로가 가지고 있는 공유 자원을 차지하지 못해 종료되지 못하는 상황
-
조건
- No Premmption : 자신이 자원을 내놓기 전까지는 빼앗기지 않습니다.
- Hold and Wait : 자원을 가질때까지 자신이 가진 자원을 내놓지 않습니다.
- Circular Wait : 서로 가지고 있는 자원이 순환구조를 이룹니다.
- Mutal Exclusion : 한 자원은 하나의 프로세스만 사용할 수 있습니다.
-
해결법 : 선점 방식을 택하거나, 하나의 자원을 여러 프로세스가 공유하게 하는 방식이 있는데 자원 낭비가 심합니다. 또한 미리 deadlock이 일어날지 파악해서 방지하는 방법이 있는데 은행원 알고리즘을 사용하기도 합니다. 은행원 알고리즘은 프로세스들의 max 자원과 현재 자원을 빼서 need 자원을 구하고 현재 가용 자원을 구해서 가용자원보다 need가 크면 빌려주지 않습니다. 자원을 가져간 프로세스들은 모두 유한 시간 내에 반납하여야 합니다.
-
Race Condition과 해결방법
- kernal mode에서 Interrupt가 발생할 때 → kernal mode에서는 Interrupt 무시
- System call에 의해 kernal에서 실행중인 프로세스에 context switching이 일어날 때 → kernal에서 실행중인 프로세스는 CPU를 뺏기지 않음
- 프로세스들이 공유 자원에 접근할 때 → 커널 내의 공유 데이터에 lock 걸기
-
Critical Section : 각 프로세스에서 공유 자원에 접근하는 부분
-
Mutex vs Semaphore : Semaphore는 공유 자원에 접근하는 연산과 반환하는 연산으로 나누어져 있어서 멀티 프로세스 환경에서의 공유 자원을 관리합니다. Mutex는 0과 1값만 가지는 Semaphore로서 상호 배제를 원칙으로 합니다.
-
Monitor : 자원 획득과 해제를 처리해주며 자바에서 synchronized를 붙여 자주 사용됩니다. 이미 사용되고 있으면 wait()함수로 기다려집니다.
-
전통적인 동기화 문제 : Dining Philosopher, Readers and Writer, Bounded-Buffer
-
Dining Philosopher
- 설명 : 철학자들이 식사를 하는데 젓가락이 두개 필요합니다. 젓가락은 각각 한개씩 양 옆에 있고 철학자들은 원탁에 둘러앉아있습니다. 철학자들은 생각을 하다가 젓가락을 집어서 젓가락을 두개 집으면 밥을 먹습니다.
- Dead Lock 성립 조건 : 상호배제, hold and wait, no preemption, circular wait
- 해결책 : 철학자들이 순서대로 밥을 먹거나 왼쪽 젓가락과 오른쪽 젓가락을 집을 수 있을때만 집기 등등
CPU Schedueling
-
FCFS : 들어온 순서대로 실행하는 방식입니다. convoy effect라고 하는 긴 프로세스가 처음에 들어와 비효율적이 되는 문제가 발생할 수 있습니다.
-
SJF : 짧은 것 먼저 수행하는 방식입니다. 비선점형으로 긴 프로세스는 영원히 CPU를 할당받지 못하는 starvation 문제가 발생할 수 있습니다.
-
SRTF : SJF의 선점형 방식입니다. 마찬가지로 starvation 문제가 발생할 수 있으며 오래 할당받지 못한 프로세스에 나이를 매겨 우선권을 주는 aging 기법으로 해결할 수 있습니다.
-
RR : Round Robin 방식으로 돌아가면서 최대 q의 시간만큼 점유하도록 하는 방식입니다. 대부분의 OS에서 채택하고 있으며 q가 너무 길면 FCFS와 비슷해지고 q가 너무 짧으면 context switching이 자주 일어나는 단점이 있습니다.
-
Priority Scheduling : 우선도에 따라 할당하는 방식입니다. 마찬가지로 starvation이 발생할 수 있습니다.
-
Multilevel Queue : 여러 queue에서 각각의 CPU schedueling을 사용하는 방식입니다.
-
Multilevel Feedback Queue : 각 queue에서 일정 시간이 지나면 다음 queue로 넘어가는 방식입니다.
-
성능 척도 : CPU Utilization, throughput, turnaround time, waiting time, response time
Memory
-
메모리 영역
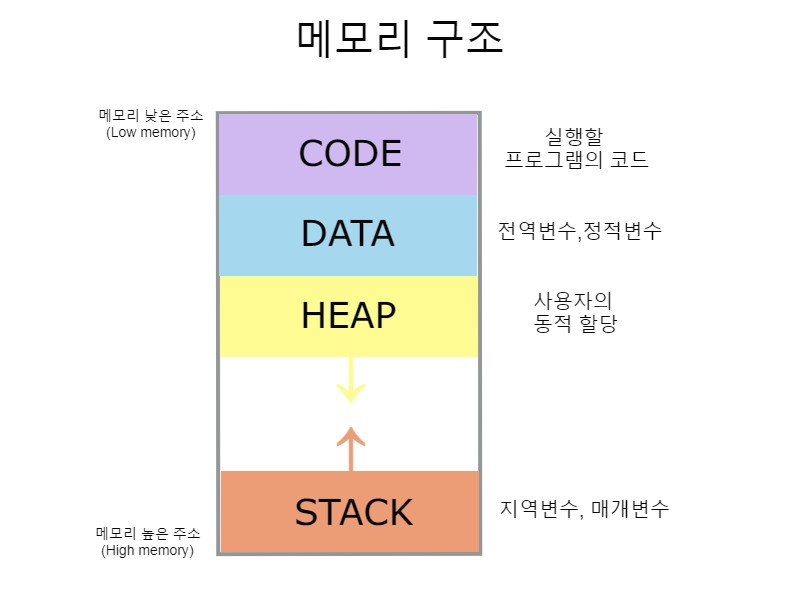
-
Java에서 Heap 영역은 GC가 알아서 메모리를 해제해줌
-
메모리 구조의 순서(CPU에서 가까운 순) : 레지스터, 캐시, 주기억장치, 보조기억장치
-
Cache Memory : Register와 주기억장치 사이에 속도를 맞추고 CPU를 할당받을 프로세스들을 미리 올려두는 역할을 합니다. 적중률을 높이기 위해 Caching Locality를 활용하여 시간 지역성과 공간 지역성을 참고해 가져옵니다.
-
Call Stack : 함수를 실행할 때 그에 관한 정보를 함수마다 stack에 쌓는 자료구조입니다.
-
Heap vs Stack : Heap보다 Stack이 상대적으로 접근이 빠르고 메모리가 단편화되지 않는 장점이 있습니다. 다만 Stack은 변수의 크기를 조정할 수 없고 스택 크기가 제한되는 단점이 있습니다.
-
DMA : Direct Memory Access로 I/O장치가 CPU의 중개 없이 메모리에 직접 접근하도록 돕는 것입니다.
Page
-
Virtual Memory : 프로그램에 실제 물리적인 주소 공간이 아닌 가상의 논리적인 주소 공간을 할당하여 Address Binding을 하는 것입니다.
-
External Fragmentation : 고정 분할이나 가변 분할 방식에서 분할의 크기가 프로그램 크기보다 작아서 할당받지 않아 빈 공간
-
Internal Fragmentation : 고정 분할에서 프로그램이 분할에 들어갔을 때 남는 공간
-
First Fit, Best Fit, Worst Fit : 가변 분할 방식에서 어느 Hole에 프로세스를 할당할지 정하는 방법 중 3가지 입니다. First Fit은 발견되는 처음 Hole에 넣는 방식이고 Best Fit은 모든 Hole을 탐색하여 가장 크기가 비슷한 Hole에 넣는 방식이고 Worst Fit은 가장 큰 Hole에 넣는 방식입니다.
-
Paging vs Segmentation : Paging은 물리적 메모리와 VM을 동일한 Page 단위로 잘라서 넣는 방식입니다. Segmentation은 같은 크기로 자르지 않고 Code Segment, Data Segment와 같이 의미있는 크기로 자르는 방식입니다.
-
Demand Paging : 실제로 필요할 때 page를 메모리에 올리는 것입니다. I/O 양과 메모리 사용량이 줄어들어 더 효율적이 되는 장점이 있습니다.
