Vacuum 이란?
- PostgreSQL의 쓰레기 데이터 청소
- 디스크 조각 모음과 유사
역할
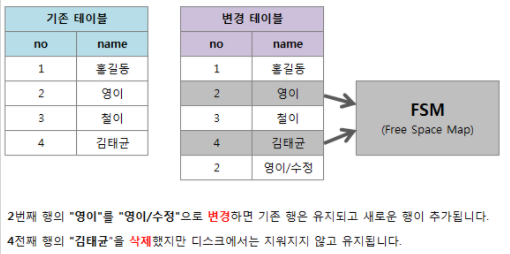
1. 변경 또는 삭제된 자료들이 차지하고 있는 디스크 공간을 다시 사용하기 위한 디스크 공간 확보
- PostgreSQL은 데이터 갱신(Update), 삭제(Delete)시 디스크에 있던 기존 정보를 갱신하거나 삭제하지 않음
-> 기존 정보 변경되었다는 표시를 남기고 새롭게 디스크에 갱신(Update)된 정보를 기록, 삭제(Delete) 했어도 디스크 용량은 줄어들지 않으며 갱신(Update)시에는 새로운 행이 추가되므로 디스크 용량 증가
-> Update, Delete, Transaction 이벤트가 많아질 수록 데드 튜플(Dead Tuple) 발생에 따른 디스크 I/O 증가가 성능 저하 결과를 가져옴
2. PostgreSQL 통계 정보 갱신
- PostgreSQL 쿼리 실행 계획기는 쿼리의 좋은 실행 계획을 짜기 위해서 각 테이블에 저장된 자료를 바탕으로 수집된 통계 정보를 이용한다.
- 통계 정보 갱신 작업이 제대로 되지 않으면 의도 되지 않은 쿼리 실행 계획이 짜여짐
- 전체적인 데이터베이스 성능을 떨어뜨림
3. 인덱스 전용 검색 성능 향상하는데 이용하는 실자료 지도(visibility map, vm) 정보를 갱신
- 지도 정보는 인덱스 전용 쿼리들에 대해서 빠른 응답을 제공하는데 사용된다.
-> 인덱스 전용 검색인 경우는 테이블 페이지를 검색하지 않고, 먼저 이 실자료 지도를 검색해서 이곳에 해당 자료가 있다면 그것을 사용한다.
-> 테이블 페이지 읽기 작업을 줄일 수 있다. - Vaccum 작업은 이미 지도 정리 작업이 끝난 것에 대해서는 더 이상 그 작업을 하지 않는다.
4. 트랜잭션 ID 겹침이나, 다중 트랜잭션 ID 겹침 상황으로 오래된 자료가 손실 될 가능성을 방지
- PostgreSQL 트랜잭션 자료에 대한 MVCC 기법은 트랜잭션 ID(XID)를 숫자로 처리하고 그것을 비교하는 방식
-> 한 로우의 자료 입력 XID 값이 현재 트랜잭션 XID 보다 더 크다면 "앞으로 생길" 자료이며 현재 트랜잭션에서는 보이지 말아야할 자료임을 뜻한다.
-> 트랜잭션 ID(XID)는 하나의 클러스터 기준으로 관리되며 서버가 오랫동안 운영 되었다면 (40억 트랜잭션을 넘게 사용했다면) 트랜잭션 ID 겹침 오류 발생 - 트랜잭션 ID(XID)가 40억을 넘어 다시 0부터 시작하려고 하면 보관 되어 있는 모든 자료의 XID 값이 0보다 크기 때문에 모든 자료는 보이지 말아야 할 자료로 처리 됨
-> 일반 XID 비교 방법은 2의 32승 나머지 연산을 이용
-> 20억개의 옛XID와 20억개의 새 XID로 나누고 이 XID 값은 계속 순환하며 사용한다는 뜻
-> 모든 데이터베이스의 모든 테이블에 대해서 20억 트랜잭션을 사용하기 전에 vacuum 작업이 필요
-> vacuum 작업은 PostgreSQL에 FrozenXID 라는 특별 XID를 미리 예약 해둔다. (일반적인 XID 비교 대상에서 항상 제외되어 항상 보여지는 XID)
Vacuum이 청소하는 기준
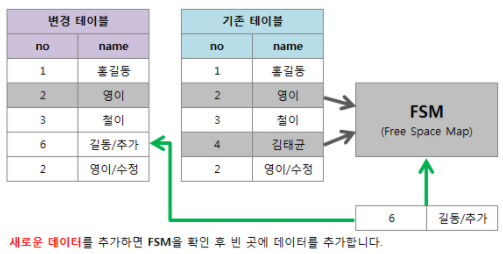
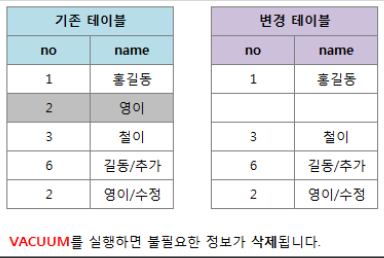
- FSM(Free Space Map) 기준으로 청소함.
- FSM가 더 이상 필요하지 않는 행의 정보를 보유
-> 사용되지 않지만 용량 차지, 새로운 행이 삽입 될 때 DBMS는 FSM의 여유공간을 확인하여 해당 행을 사용
-> 필요하지 않는 행의 정보를 청소
튜플(Tuple) 정보 확인 쿼리(Live Tuple, Dead Tuple 확인가능)
SELECT
n.nspname AS schema_name,
c.relname AS table_name,
pg_stat_get_live_tuples(c.oid) + pg_stat_get_dead_tuples(c.oid) as total_tuple,
pg_stat_get_live_tuples(c.oid) AS live_tuple,
pg_stat_get_dead_tuples(c.oid) AS dead_tupple,
round(100*pg_stat_get_live_tuples(c.oid) / (pg_stat_get_live_tuples(c.oid) + pg_stat_get_dead_tuples(c.oid)),2) as live_tuple_rate,
round(100*pg_stat_get_dead_tuples(c.oid) / (pg_stat_get_live_tuples(c.oid) + pg_stat_get_dead_tuples(c.oid)),2) as dead_tuple_rate,
pg_size_pretty(pg_total_relation_size(c.oid)) as total_relation_size,
pg_size_pretty(pg_relation_size(c.oid)) as relation_size
FROM pg_class AS c
JOIN pg_catalog.pg_namespace AS n
ON n.oid = c.relnamespace
WHERE
pg_stat_get_live_tuples(c.oid) > 0
AND c.relname NOT LIKE 'pg_%'
ORDER BY dead_tupple DESC;- schema_name: 스키마 명을 나타냄
- table_name: 테이블 명을 나타냄
- total_tuple: 전체 튜플의 개수를 나타냄
- live_tuple: 사용되는 튜플의 개수를 나타냄
- dead_tuple: UPDATE, DFGELETE 등에 의해 사용되지 않는 튜플의 개수를 나타냄
- live_tuple_rate: 사용되는 튜플의 비율을 나타냄
- dead_tuple_rate: 사용되지 않는 튜플의 비율을 나타냄
- total_relation_size: 릴레이션의 전체 크기를 나타냄. 인덱스와 TOAST 데이터를 포함
- relation_size: 릴레이션의 크기를 나타냄
조건
- pg_stat_get_live_tuples(c.oid) > 0 : 비율을 표시하기 위해 0보다 큰 값만 조회
- c.relname NOT LIKE 'pg%': 사용자가 생성한 테이블만 조회하기 위해 'pg' 문자열을 포함하지 않는 테이블 명만 조회
Vacuum 통계 정보 확인 쿼리
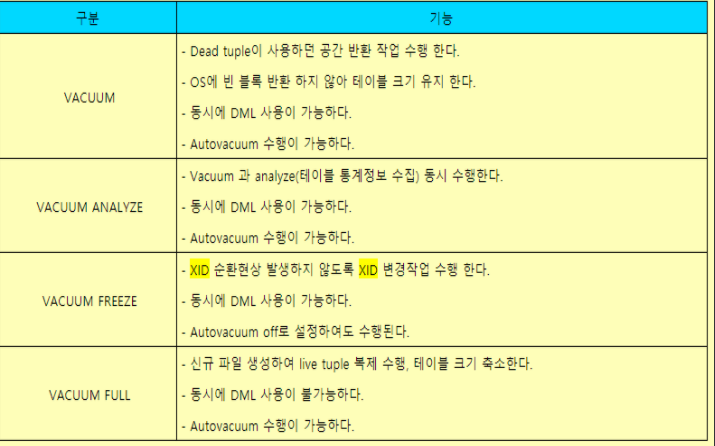
SELECT * FROM pg_stat_all_tables ORDER BY schemaname, relname;Vacuum 명령어
-
DB 전체 풀 실행
vacuum full analyze; -
DB 전체 간단하게 실행
vacuum verbose analyze; -
해당 테이블만 간단하게 실행
vacuum analyse [테이블명] -
특정 테이블만 풀 실행
vacuum full [테이블명]
- full 옵션으로 실행 시 데이터베이스가 잠김(Lock)처리 되므로 운영중인 데이터베이스에서는 지양
Autovacuum
- vacuum, freeze, analyze 명령을 자동으로 수행해 준다.
- postgresql.conf 설정 파일을 이용하여 수행
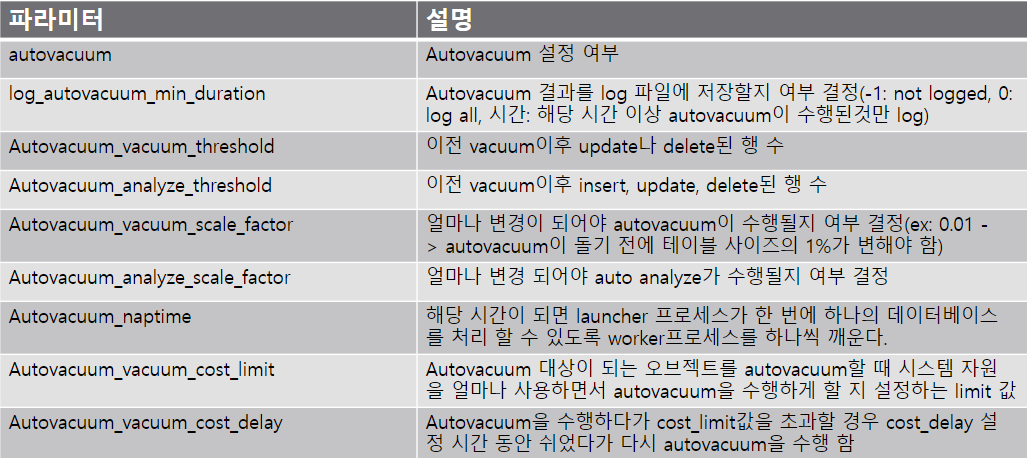
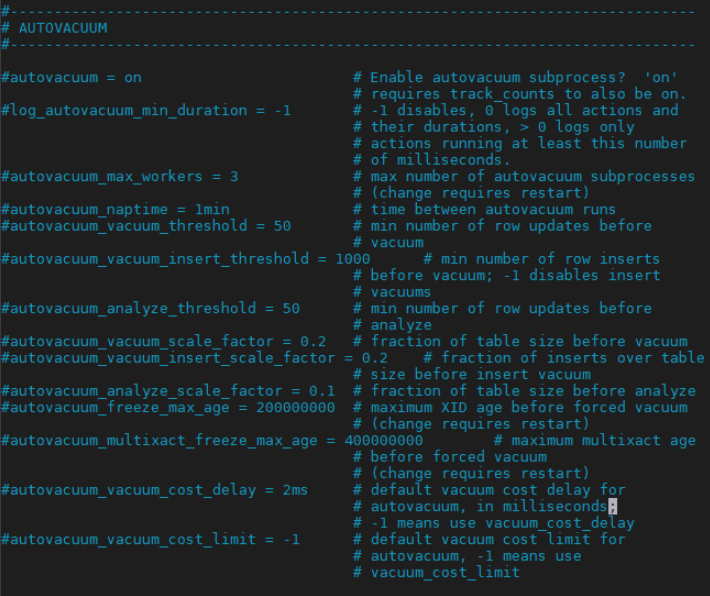
Autovacuum 설정 값 예시

성장형 인간