문제 상황
크롤링 한 채널리스트의 중복 제거 속도를 개선하자.
현재 상황
모든 키워드를 검색 후 수집한 채널이름과 url을 pandas Dataframe을 통해 duplicate를 삭제한다.
하나의 키워드 당 약 2~300개의 채널을 수집하게 되는데 모든 키워드들을 모으고 나면 중복되는 채널이 많기 때문에 채널리스트를 줄이기 위해서 pandas를 이용하고 있었다.
하지만 이 방법의 문제점은 모든 키워드를 모아야 그제서야 중복을 제거할 수 있다는 것이었다. 따라서, 우리는 여기서 다른 방법을 논의하기 시작했고 나왔던 해결방법은 아래와 같았다.
1. RDB를 사용해서 INSERT INTO 시, 만약 이미 채널이 들어가있으면 IGNORE를 한다.
2. 채널리스트를 수집하는 여러개의 EC2 인스턴스가 끝나면
kinesis에서 람다가 데이터를 가져와 중복을 제거해서 영상 크롤링 EC2로 넘긴다.
3. 이미 key가 있으면 value가 업데이트 되는 Redis를 사용한다. 이 중에서, 1번은 채널리스트 하나의 테이블만을 위해 RDB를 구성할 필요가 없다고 생각되어져 기각되었으며, 2번은 크롤링이 끝난 데이터가 만약 100만 개 이상이 되었을 때 람다로 처리하면 과연 15분 안에 끝날까 하는 걱정이 되어 기각되었다.
결국, Redis를 이용해서 채널리스트의 크롤링이 끝나면 각각의 EC2에서 Redis로 보내고, 다중 클라이언트가 가능하기 때문에 여러대의 EC2에서 들어오는 데이터를 Redis 안의 데이터와 비교해서 없으면 넣고 있으면 업데이트 하는 방식을 시도해보기로 했다.
문제 해결
기존의 t4g.large 인스턴스의 이미지를 생성해 AMI로 복제하여 아래와 같이 2개의 인스턴스를 만들어주었다.

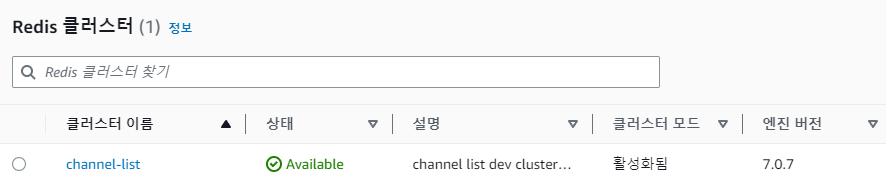
그 뒤, Elastic Cache에 가서 Redis 클러스터를 하나 만들어주었다. 테스트용이기 때문에 자세한 설정은 하지 않았다.
크롤링 결과



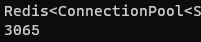
첫 번째 이미지는 원래 사용하던 t4g.large 인스턴스 한 개에서 10개의 키워드를 검색해서 얻은 중복제거 한 뒤의 채널 개수와 걸린 시간이다. 대략 6400개였던 채널리스트가 2700개로 줄었고, 790초 정도가 걸렸다.
그 아래의 이미지들은 새롭게 t4g.medium 인스턴스 2개로 10개의 키워드를 검색해서 얻은 채널 개수와 각각 걸린 시간이다. 대략 3000개로 채널리스트가 줄었고, 420초 정도가 걸렸다.
남은 문제
비용이 문제다. 만약 t4g.medium 인스턴스 여러대를 돌려 채널리스트를 크롤링 한다면 기존의 t4g.large 하나로 다 돌리는 것보다는 시간적인 측면에서 나을 수는 있다. 실제로 기존의 경우는 우리가 갖고있는 모든 키워드를 수집하는데 333시간이 걸린다는 계산이었고, medium으로 여러대 돌릴 경우엔 33시간으로 무려 10배나 빨라질 것으로 계산되었지만, 수집이 24시간 내에 끝나야 하기때문에 인스턴스를 더 늘려야 한다는 계산이 나왔지만, t4g 인스턴스 특성상 너무 비싸서 비용이 큰 문제가 될 것 같았다.
따라서, 우리는 t3.small로 20대 가까이 인스턴스를 늘리는 것으로 합의를 보았다.
