[Programmers]실리콘밸리에서 날아온 DE 스타터 키트3️⃣주차
🈯 숙제 해설
2주차 복습
- 사용자별 처음/마지막 채널 쿼리 : Subquery에 대한 공부 보충!
# 모범답안 : Subquery + 자기참조
WITH tmp AS (
SELECT userid
, channel
, (ROW_NUMBER()
OVER
(PARTITION BY userid ORDER BY ts asc)) AS arn
, (ROW_NUMBER()
OVER
(PARTITION BY userid ORDER BY ts desc)) AS drn
FROM 테이블1
JOIN 테이블2
ON 테이블1.컬럼 = 테이블2.컬럼
)
SELECT userid, tmp1.channel AS first, tmp2.channel AS last
FROM tmp tmp1
JOIN tmp tmp2 ON tmp1.userid = tmp2.userid
WHERE tmp1.arn = 1 and tmp2.drn = 1
ORDER BY 1;
# 내가 푼 방식 : WINDOW
SELECT
DISTINCT u.userid,
FIRST_VALUE(u.channel)
OVER (
PARTITION BY u.userid
ORDER BY s.ts
ROWS BETWEEN
UNBOUNDED PRECEDING
AND UNBOUNDED FOLLOWING # userid로 파티션되었기때문에 UNBOUNDED로 전체 다 봐줘야함
) as first_channel,
LAST_VALUE(u.channel)
OVER (
PARTITION BY u.userid
ORDER BY s.ts
ROWS BETWEEN
UNBOUNDED PRECEDING
AND UNBOUNDED FOLLOWING
) as last_channel
FROM raw_data.user_session_channel u
JOIN raw_data.session_timestamp s
ON u.sessionid = s.sessionid
ORDER BY 1;- Gross Revenue랑 Net Revenue : Net Revenue는 Refunded가 False인 것들만 더해줘야 함.
# SUM과 COUNT는 NULL을 0 취급함.
SELECT userID
, SUM(amount) gross_revenue
, SUM(CASE WHEN 테이블2.refunded is not TRUE THEN amount END) net_revenue
FROM 테이블1
JOIN 테이블2 ON 테이블1.컬럼 = 테이블2.컬럼
GROUP BY 1
ORDER BY 2 DESC;🧐 3주차
데이터 파이프라인과 ETL
-
비구조화된 데이터 처리하기
- raw data ▶ S3 ▶ Spark / ATHENA ▶ REDSHIFT
- 비구조화된 raw data가 쌓임.
- 별 다른 처리를 하지 않고 웹하드디스트같은 느낌의 저렴한 S3에 적재.
- 데이터를
- 데이터프레임 형태로 저장하는 Spark나
- SQL로 처리하는 ATHENA
로 전처리 해서 데이터를 구조화하고 의미 있는 데이터만
- DW인 REDSHIFT에 적재.
-
대용량 데이터를 빠르게 머신러닝 모델과 계산해서 반환해야 하는 경우(넷플릭스처럼)
- S3나 DW에 적재된 데이터를 Spark를 통해 미리 feature들을 다 읽기 빠른 NoSQL에 적재해두고
- 사용자가 API를 통해 결과값을 호출하면
- 그 때 ML모델과 NoSQL DB에 들어가있는 data를 이용해 결과값을 빠르게 리턴.
- ETL과 ELT
- ETL
- Extract ▶ Transform ▶ Load
- Airflow에선 한 번의 ETL 과정을 DAG라고 부름.
- DAG : 방향성이 있는 비순환 그래프.
- 외부에서 DW로 데이터를 가져오는 프로세스.
- ELT
- DW내의 데이터를 가지고 새로운 데이터를 만드는 프로세스.
- 이 경우 DL을 쓰기도 함.
- DA가 주로 하며, ELT를 위해 DBT라는 유명한 툴도 존재.
- ETL
- Data Lake(DL)와 Data Warehouse(DW)
- Data Lake
- 비구조화된 다양한 형태의 대량의 데이터를 적재.
- 오래된 데이터가 많음.
- Storage의 개념이 강함.
- Data Warehouse
- 정제되고 구조화된 의미있는 데이터를 적재.
- BI툴과 연동이 쉬움.
- 용량제한이 있음.
- 한국에선 Data Mart랑 혼용.
- Data Lake
- Data Pipeline : 코딩과 SQL을 통해 데이터를 소스로부터 목적지까지 복사하는 작업
- 소스의 예시 : Click stream, call data, transactions, sensor data, production db, log data 등
- 목적지의 예시 : DW, 캐시 시스템(Redis 등), production db, NoSQL, S3 등
- 종류
- Raw Data ETL : 내/외부의 raw data를 데이터 포맷 변환 후 DW에 로드하는 ETL
- Summary/Report : DW/DL로부터 데이터 읽고 Summary report 형태로 다시 DW에 쓰는 ETL
- Production Data : DW에서 데이터를 읽어 다른 Storage(대부분 production 환경)로 쓰는 ETL
- 간단한 ETL : 웹상에 있는 csv를 redshift로 옮기기
# 테이블 생성
DROP TABLE IF EXISTS 본인db.테이블명;
CREATE TABLE 본인db.테이블명 (
name varchar(32),
gender varchar(8)
);
# Postgre랑 연결
import psycopg2
def get_Redshift_connection():
host = "호스트"
redshift_user = "아이디"
redshift_pass = "비밀번호"
port = 5439
dbname = "db이름"
conn = psycopg2.connect("dbname={dbname} user={user} host={host} password={password} port={port}".format(
dbname=dbname,
user=redshift_user,
password=redshift_pass,
host=host,
port=port
))
conn.set_session(autocommit=True)
return conn.cursor()
# 함수정의
import requests
def extract(url):
f = requests.get(url)
return (f.text)
def transform(text):
lines = text.split("\n")
return lines
def load(lines):
cur = get_Redshift_connection()
for r in lines:
if r != '':
(name, gender) = r.split(",")
sql = "INSERT INTO db.테이블명 VALUES ('{n}', '{g}')".format(n=name, g=gender)
cur.execute(sql)
# 실행
link = "https://s3-geospatial.s3-us-west-2.amazonaws.com/name_gender.csv"
data = extract(link)
lines = transform(data)
load(lines)
# 결과
SELECT *
FROM db.테이블;
# name gender
# name gender
# Adaleigh F
# Amryn Unisex
# Apurva Unisex
# Aryion M
# Alixia F
# Alyssarose F
# Arvell M- ✅ 멱등성 : 몇 번을 실행해도 소스의내용과 DW의 내용이 동일한 성질(즉, 실행 횟수에 관계없이 중복 없어야함)
🧐 3주차
Airflow
- Airflow : 데이터 파이프라인을 위한 플랫폼. 데이터 파이프라인의 프레임워크이자 라이브러리.
- 궁극적인 목표는 좋은 ETL 작성을 위한 모든 지원
- DAG : Airflow에서 얘기하는 Data pipeline
- DAG = (Operater로 구현되는)TASK들의 모음 = ETL 한 세트
- 빠르게 발전되기 때문에 버전 업데이트가 많으나 큰 회사에서 선택한 airflow 버전을 확인 후 그거 사용. 예를 들면 구글
- 5개의 컴포넌트 : Web Server + Scheduler + Worker + Database + Queue(멀티노드일 경우)
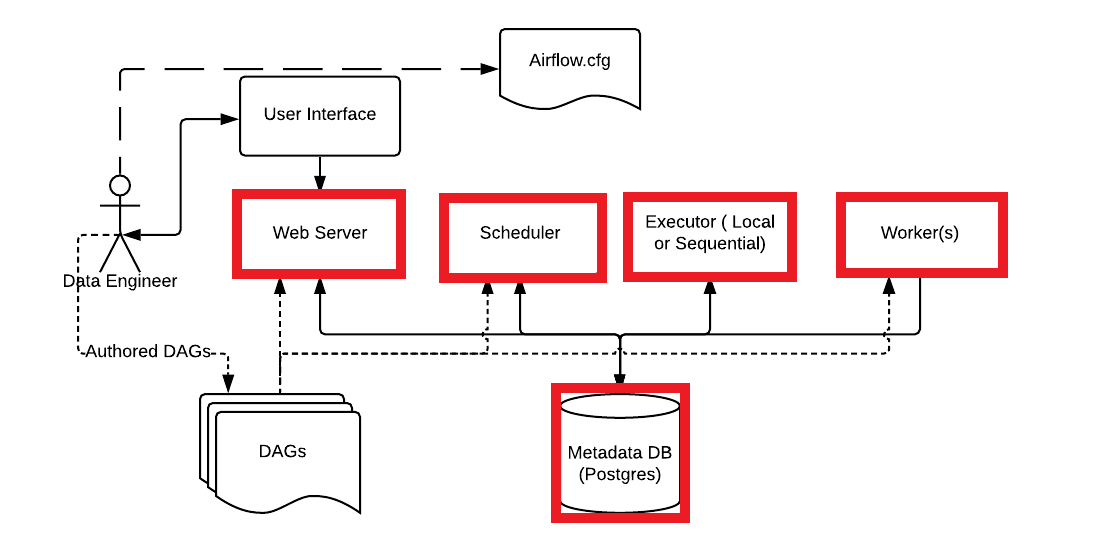
- 서버가 한 개면 Web Server ~ Database가 필수 구성요소
- Database는 디폴트가 Sqlite. 근데 너무 느려서 MySQL이나 PostgreSQL을 씀.
- Database에는 DAG 실행 결과가 기록됨.
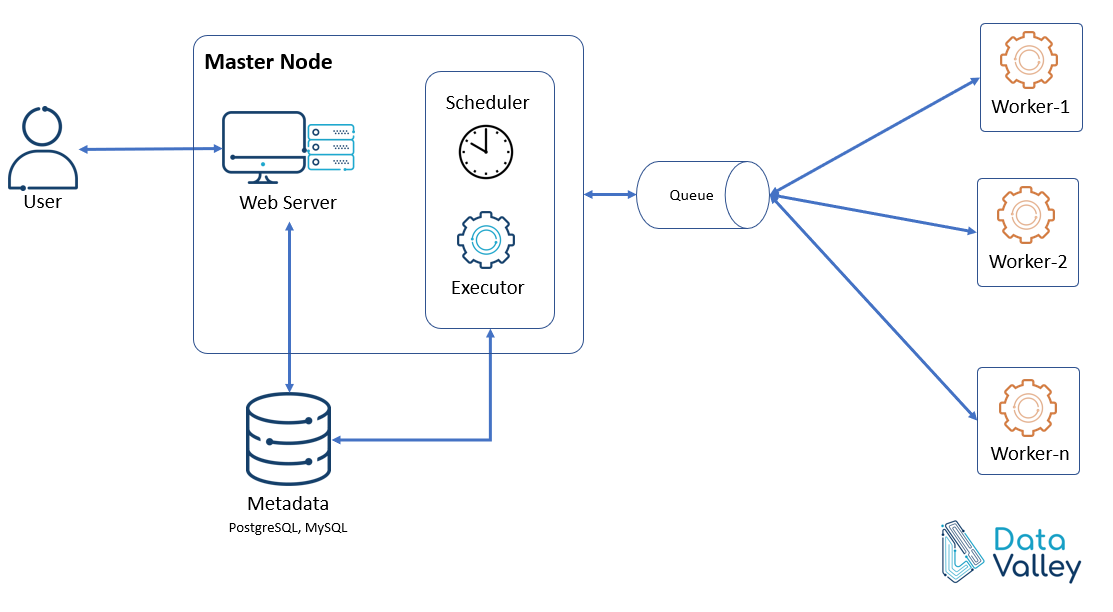
- Scaling Airflow
- Scale Up : 더 좋은 사양의 서버 사용 (한계가 존재)
- Scale Out : Worker node를 추가. worker만 따로 떼어내서 더 추가. 스케쥴 확인해서 큐를 봐서 놀고있는 worker한테 DAG 할당.
- Airflow의 장단점
- 장점
- 세분화된 DAG 및 종속성 제어
- 데이터 가용성을 감지하는 다양한 오퍼레이터 및 센서
- 더 쉬운 backfill
- 인기 있는 데이터 소스를 즉시 지원하는 프로그래밍 가능한 DAG 프레임워크
- 단점
- 혼동하기 쉬운 컨셉이 많음
- 개발환경 구축이 상대적으로 복잡
- (멀티 노드의 경우)유지가 힘들 수 있음 → 그래서 GCP에는
Cloud Composer/ AWS에는MWAA가 있음.
- 장점
- 간단한 DAG configuratuion 예시
from datetime import datetime, timedelta
from airflow import DAG
default_args = {
'owner': '누가 실행하는지',
'start_date': '언제 데이터를 넣을것인지',
'end_date': '언제까지 넣을것인지',
'email': ['에러가 나면 누구한테 이메일 보낼 것인지'],
'retries': '몇 번 다시 시도할 것인지',
'retry_delay': timedelta(minutes='몇 분 뒤 다시 시도할 것인지'),
}- 더 간단한 DAG 생성 예시
test_dag = DAG(
"DAG 이름",
schedule_interval = "0 2 * * *",
default_args = default_args
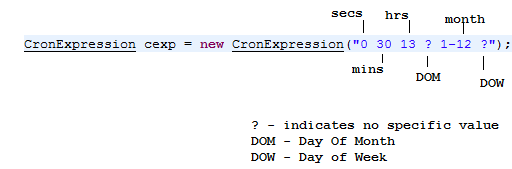
)- cron expression
- Operator : Task를 실제로 실행하는 역할.
- Action Operator
- 기능이나 명령을 실행하는 Operator.
- Bash Operator, Python Operator, etc..
- Transfer Operator
- 데이터를 Source에서 Destination으로 전송해주는 Operator.
- 예를 들어, Presto에서 MySQL로 데이터를 전송하는데에 사용
- Sensor Operator
- 특정 조건을 Sensing하여 실행되는 Operator.
- 다른 Operator들과는 달리 조건이 만족할 때까지 기다렸다가, 조건이 충족되면 다음 Task를 실행하도록 함.
- 예를 들어, 특정 위치에 파일이 생성되었을 때 다음 Task를 실행하도록 File sensor를 사용할 수 있음
- Action Operator

- Operators의 구현
task1 >> task 2
task 1 >> [task2, task3] >> task 4- 데이터 파이프라인을 만들 때 주의할 점
- 데이터 파이프라인은 많은 이유로 실패하기 때문에 항상 주의해야 함(버그, 외부 API, 의존도 이해 부족 등)
- 가능하면 데이터가 작으면 매번 통채로 복사해서 테이블 만드는
Full Refresh작업이 좋음. - 만약
Incremental update(바뀐것만 읽기)만 가능하다면create, modified, deleted이 세 가지 필드가 존재해야 함. - 멱등성을 보장하는 것이 중요.
- 실패한 데이터 파이프라인은 재실행이 쉬워야 함.
- 과거 데이터를 다시 채우는
Backfill이 쉬워야 함(Incremental update의 경우에만). 이 때, catchup 파라미터가 True가 되어야 하고 start_date와 end_date가 적절하게 설정되어야 함. - 쓸모없는 데이터는 제때제때 삭제하기.
- 중요한 데이터 파이프라인의 입력과 출력 체크
- Airflow에서의
Backfill❗❗start_date로 지정한 시점에 시작이 아니라, 그 다음 날부터 시작- 만약
start_date=2022-10-01이면 실제 시행 날짜는2022-10-02. 1일부터 2일까지의 데이터가 쌓이는 시간이 필요하니까. start_date과execution_date는 항상 차이가 있음.

완료주의