import requests
from bs4 import BeautifulSoup
#<response[200]> 나오면 정상응답
#url 가져오기 + BeautifulSoup으로 html의 tag를 인식시키기
raw = requests.get("https://tv.naver.com/r")
html = BeautifulSoup(raw.text, "html.parser")
#1~3위의 컨테이너 수집
clips = html.select("div.inner")
#반복문 돌려버리기
for i in range(len(clips)):
# 데이터 수집부분
title = clips[i].select_one("dt.title")
chn = clips[i].select_one("dd.chn")
hit = clips[i].select_one("span.hit")
like = clips[i].select_one("span.like")
# 수집결과 출력부분
print(title.text.strip())
print(chn.text.strip())
print(hit.text.strip())
print(like.text.strip())
결과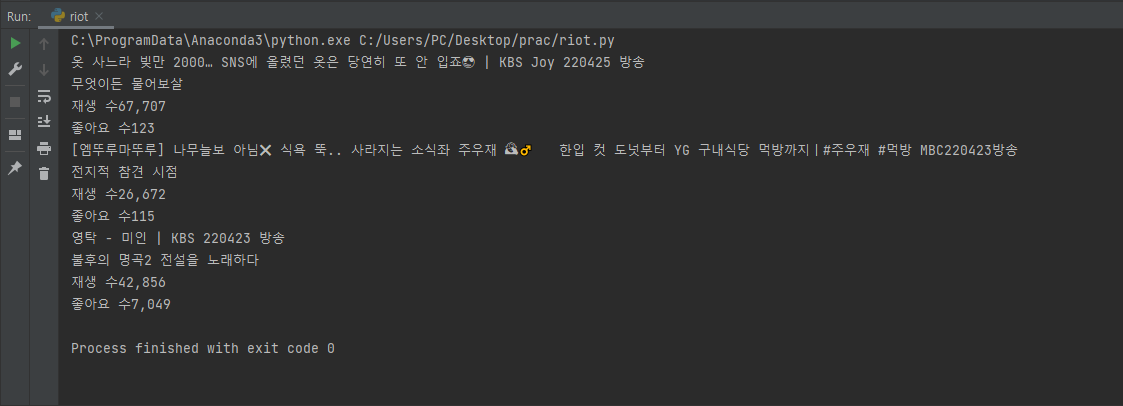
요런것도 있네.... 잼따 크롤링.....
(출처)https://book.coalastudy.com/data_crawling/week3/stage2

완료주의