지도 학습(supervised learning), 비지도 학습(unsupervised learning),
준지도 학습(semisupervised learning), 강화 학습(reinforcement learning)
지도 학습- 훈련데이터에 레이블(즉, 답)이 포함되며, 이것에 기반해 모델이 학습한다.
- 이 때, feature를 가지고 target을 예측한다. 분류(classification), 회귀(regression)가 대표적인 경우이다.
- ex)
k-최근접 이웃(k-Nearest Neighbors),선형 회귀,로지스틱 회귀,SVM,결정 트리,랜덤 포레스트(random forests),신경망(neural network)등
-
비지도 학습- 훈련데이터에 레이블이 없다.
비지도 학습중, 중요한 학습이 이상치 탐지이다. 예를 들어, 부정 거래를 막기 위해 이상한 신용카드 거래를 감지하고, 제조 결함을 잡아내고, 학습 알고리즘에 주입하기 전에 데이터셋에서 이상한 값을 자동으로 제거하는 것 등이다. 그렇게 된다면, 시스템은 정상 샘플로 훈련되고, 새로운 샘플이 정상 데이터인지 혹은 이상치인지 판단한다.- ex)
군집: k-means, 계층군집(hierarchical clustering, HCA), 기댓값 최대화(Expectation Maximization)
시각화와 차원축소: dPCA, 커널PCA, 지역적 선형 임베딩(LLE), t-SNE
연관 규칙 학습: 어프라이어리(apriori), 이클렛(eclat)
Tip🔔) 지도 학습 알고리즘 시, 차원 축소를 먼저 사용해서 훈련 데이터의 차원을 중이면 실행 속도도 엄청 빨라지고 리소스도 덜 쓸 수 있어 좋음💪
-
준지도 학습- 레이블이 일부만 있는 데이터를 다룬다.
- 보통은 레이블이 대부분 없고 레이블이 있는 데이터는 아주 조금이다.
지도 학습과비지도 학습의 조합으로 이루어져 있다.
ex)심층 신뢰 신경망(DBN)은 여러 겹으로 쌓은 제한된 볼츠만 머신(RBM)을 순차적으로 훈련하고, 전체 시스템이 지도 학습 방식으로 세밀하게 조정된다.
-
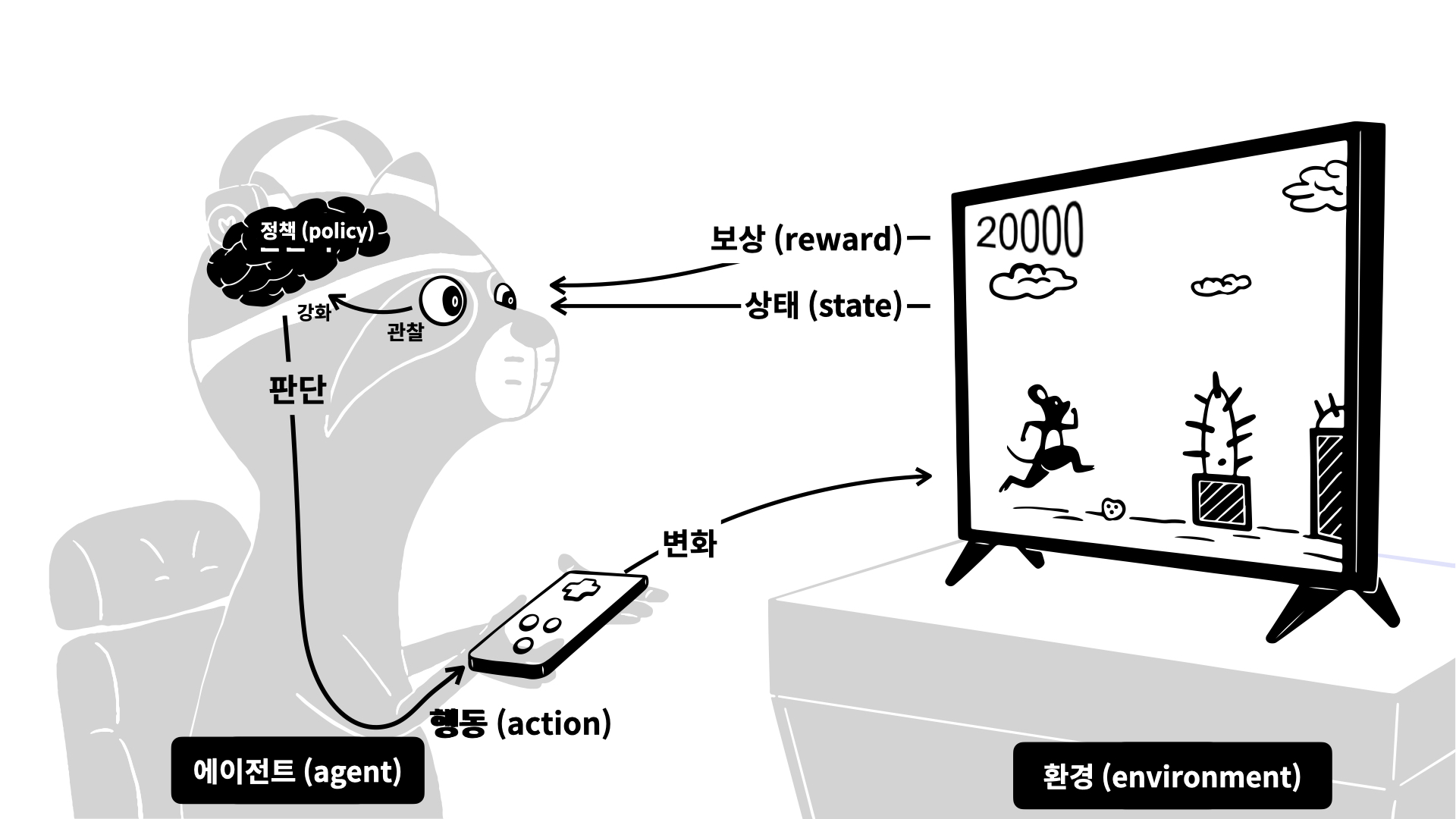
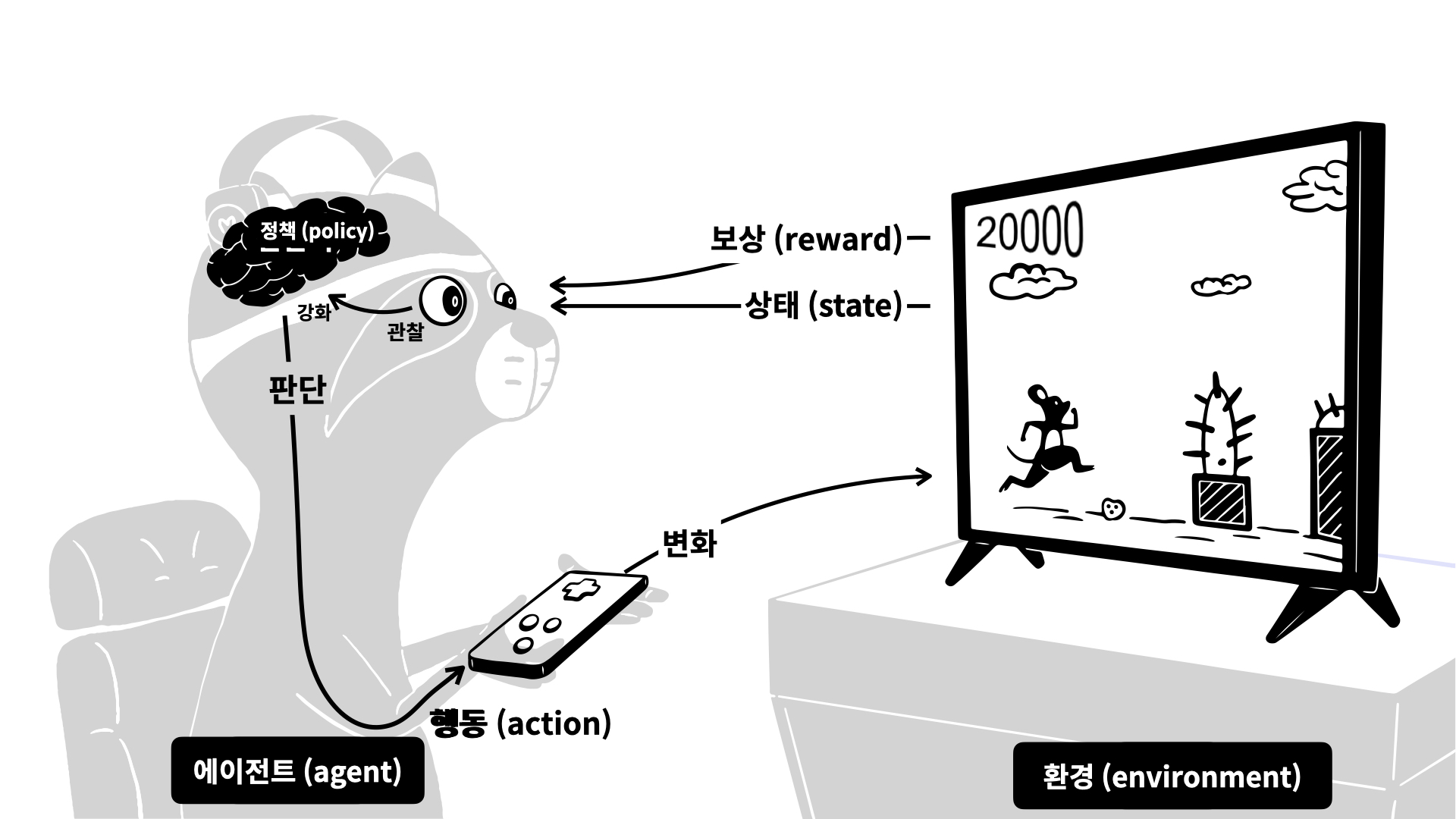
강화 학습- 에이전트(agent)라 불리는 학습 시스템이 환경(environment)를 관찰해서 행동(action)하고, 그 결과로 보상(reward) 혹은 벌점(penalty)를 받는다.
- 시간이 지나면서 가장 큰 보상을 얻기 위해 정책(policy)라는 최상의 전략을 스스로 학습한다.
ex)알파고
배치 학습(batch learning)과 온라인 학습(online learning)
배치 학습- 리소스가 많이 소모되므로 보통 오프라인에서 수행된다.
- 점진적으로 학습 할 수 없고, 가용한 데이터를 모두 사용해 훈련해야 한다.
- 먼저 시스템을 훈련시키고 다음 제품 시스템에 적용하면 더 이상의 학습이 이루어지지 않는다.
- 오프라인 학습(offline learning)이라고 한다.
- 새로운 데이터를 학습하려면 새로운 데이터 + 이전 데이터 를 모두 사용해서 새로운 버전을 처음부터 다시 훈련시켜야 한다.
- 많은 컴퓨터 자원이 필요하다.
-
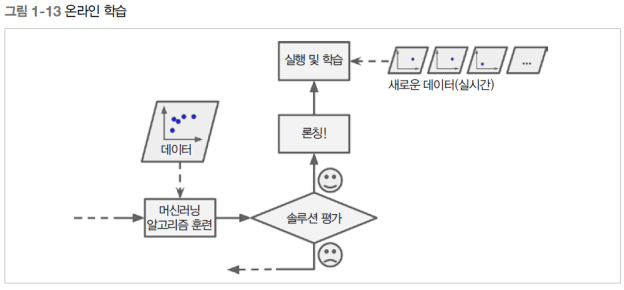
온라인 학습-
데이터를 순차적으로 한 개씩 또는 미니배치라고 부르는 작은 묶음 단위로 주입하여 시스템을 훈련시킨다.
-
매 학습 단계가 빠르고 비용이 적게 들어 시스템은 데이터가 도착하는 대로 즉시 학습할 수 있다.
-
빠른 처리가 필요한(주식 가격 등) 경우 적합하다. 혹은 컴퓨팅 자원이 제한된 경우에도 좋다.
-
점진적 학습(incremental learning)이라고 한다.
-
학습률(learning rate)이 중요한 파라미터이다.
- 학습률이 높으면 데이터에 빠르게 적응하지만 예전 데이터를 금방 잊어버린다.
- 학습률이 낮으면 시스템의 관성이 더 커져서 더 느리게 학습된다. 하지만 새로운 데이터에 있는 데이터에 있는 잡음이나 대표성이 없는 데이터 포인트에 덜 민감해진다.
-
사례 기반 학습(instance-based learning)과 모델 기반 학습(model-based learning)
-
사례 기반 학습- 시스템이 사례를 기억함으로써 학습한다.
- 그리고 유사도 측정을 사용해 새로운 데이터에 일반화한다.
-
모델 기반 학습-
샘플들의 모델을 만들어 예측에 사용한다.
-
모델이 얼마나 좋은지 측정하는 효용 함수(utility function)와 얼마나 나쁜지 측정하는 비용 함수(cost function)을 가지고 학습한다.
-
머신러인의 주요 도전 과제
- 충분하지 않은 양의 훈련 데이터
- → cross validation으로 해결 가능!
- 대표성이 없는 훈련 데이터
- → 데이터가 누락되면 모델이 크게 변형될 수 있다.
- 낮은 품질의 데이터
- → 에러, 이상치, 잡음 등으로 가득찬 경우 제대로 된 예측이 어렵다.
- 관련 없는 특성
- → 특성 공학을 통해 훈련에 사용할 좋은 특성들을 찾는다.
- 훈련 데이터 과대적합
- → 훈련 데이터는 잘 학습했지만, 새로운 데이터는 잘 예측하지 못 할 수 있다.
- → 그래서 규제(regularization)를 잘 사용한다.
- 훈련 데이터 과소적합
- → 모델 파라미터가 더 많은 강력한 모델을 선택 or 특성 공학 or 모델 제약을 줄인다.

완료주의