
Alarm clock
기존의 PintOS의 timer_sleep()은 busy waiting 방식으로 동작하도록 구현되어 스레드가 CPU를 점유하는 동안 다른 스레드에서 점유를 요청한다면 작업이 완료될때까지 무의미하게 CPU 사이클을 소모하기 때문에 효율적인 방식이라고 말하기 어렵습니다.
이를 위해 기존의 busy waiting 방식으로 구현되어 있던 timer_sleep()을 busy waiting 없이 Timer interrupt와 Sleep waiting 방식으로 동작하도록 수정하여 성능을 개선하는게 Alarm clock의 목표입니다.
Timer interrupt와 Sleep waiting 방식은 서로 다른 기능을 수행하지만, 함께 사용되어 시스템의 효율성과 성능을 높일 수 있습니다. 두 방식은 다음과 같은 방식으로 서로를 보완하면서 효율적으로 동작합니다.
Timer interrput
Timer interrupt는 CPU가 동작하고 있는 상태에서 일정 시간이 지나면 발생하는 인터럽트입니다. 이 인터럽트는 OS가 CPU를 점유하고 있던 스레드의 실행을 중단하고, 다른 스레드 또는 OS 자체의 작업을 수행하도록 합니다. 이렇게 함으로써, 너무 오랜 시간동안 CPU를 점유하는 작업이 다른 작업에게 CPU를 넘겨주는 것이 가능해지며, 전체적인 시스템의 효율성을 높일 수 있습니다.
또한, Timer interrupt를 이용하여 작업의 우선순위를 조절할 수도 있습니다. 예를 들어, 오랜 작업 시간이 걸리는 작업과 짧은 시간이 걸리는 작업이 동시에 수행될 때, 우선순위가 높은 작업에게 CPU를 우선적으로 할당할 수 있습니다. 이렇게 함으로써, 더 중요한 작업에 대한 처리를 빠르게 할 수 있으며, 전반적인 시스템의 반응성을 향상시킬 수 있습니다.
따라서, Timer interrupt는 CPU 자원을 효율적으로 사용하기 위한 중요한 기술 중 하나입니다. 이를 통해 시스템의 성능을 최적화하고, 작업 처리 시간을 단축시켜 높은 효율성을 가진 시스템을 구축할 수 있습니다.
Sleep waiting
Sleep waiting은 Busy waiting의 단점을 보완하는 기술 중 하나입니다. Busy waiting은 스레드가 어떤 작업을 수행할 때, 해당 작업이 완료될 때까지 반복적으로 검사하는 방식으로 CPU를 계속해서 점유하는 방식입니다. 따라서, Busy waiting은 CPU 자원을 많이 사용하며, 다른 스레드나 프로세스가 실행될 기회를 줄이는 문제가 있습니다.
반면에, Sleep waiting은 스레드가 어떤 작업을 수행할 때, 해당 작업이 완료될 때까지 대기하는 방식으로 CPU 자원을 효율적으로 사용합니다. 스레드가 어떤 작업을 수행하다가 대기해야 할 경우, 해당 스레드를 block 상태로 전환하고, 작업 중인 스레드의 CPU 점유가 끝나면 block 상태로 전환된 스레드를 unblock 상태로 바꾸어서 CPU를 점유할 수 있도록 합니다. 이를 통해, 다른 스레드나 프로세스가 실행될 때 스레드가 대기하고 있으므로 효율를 높일 수 있습니다.
컨텍스트 스위칭 시간이 block, unblock에 걸리는 시간 보다 짧거나 멀티 코어 프로세스인 경우에는 busy waiting이 더 효율적인 경우도 있습니다. 그러나 pintos 환경에서는 멀티 코어 프로세스가 아닌 단일 코어 프로세스이기 때문에, sleep waiting이 더 효율적인 방식으로 사용됩니다. 이를 통해, CPU 자원을 더 효율적으로 사용하여 시스템의 성능을 최적화할 수 있습니다.
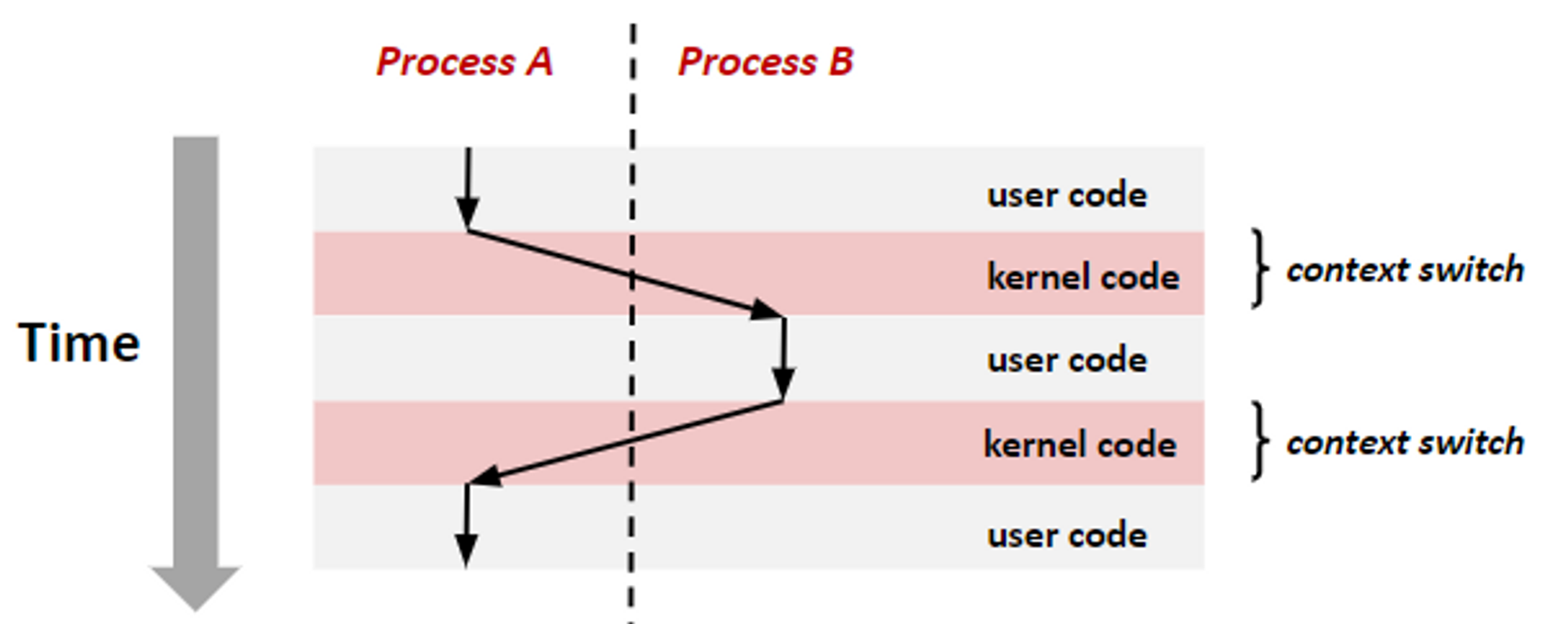
Context Switching
하나의 사용자 프로세스로부터 다른 사용자 프로세스로 CPU의 제어권이 이양되는 과정이다. 커널에 의해 일어난다. 이전 프로세스 상태(문맥)을 보관하고 새로운 프로세스의 문맥을 적재하는 작업이다.
Priority Scheduling
PintOS에는 기존에 라운드로빈 스케줄러가 구현되어 있습니다. 하지만, 이 방식은 모든 스레드가 동일한 우선순위를 가지기 때문에, 우선순위가 높은 스레드가 실행되어야 할 때에도 높은 우선순위를 가진 스레드가 계속해서 기다려야 하는 문제가 있습니다. 이는 전체적인 시스템 성능을 저하시킬 수 있습니다.
이에 대해, 스레드의 우선순위에 따라 스케줄링하는 우선순위 스케줄러로 수정할 예정입니다. 이를 위해 실행 중인 스레드의 우선순위가 변경될 때, 이에 따라 스케줄링이 이루어지도록 합니다. 이 방식은 높은 우선순위를 가진 스레드가 먼저 실행되어, 더 중요한 작업에 대한 처리를 우선적으로 수행할 수 있습니다. 또한, 우선순위가 낮은 스레드가 계속해서 기다려야 하는 문제도 해결할 수 있습니다. 따라서, 우선순위 스케줄러는 시스템의 성능을 향상시킬 수 있습니다.
그러나, 우선순위 스케줄링 방식은 우선순위 역전 현상이 발생할 수 있는 문제점이 있습니다. 이를 방지하기 위해서는 Priority Donation, Multiple Donation , Nested Donation 기능을 구현해야 합니다.
Priority기반 Scheduling
각 스레드가 자신의 우선순위를 확인하고 변경할 수 있도록 thread_set_priority(int new_priority)와 thread_get_priority(void) 두 가지 함수를 구현할 예정입니다. 이를 통해, 스레드가 자신의 우선순위를 변경하거나, 다른 스레드의 우선순위를 확인할 수 있습니다. 이러한 기능을 추가함으로써, 스레드 우선순위 관리에 더욱 편리성을 높일 수 있습니다.
Priority Scheduling-Synchronization
synchronization 동기화
멀티 프로세스 시스템에서 여러 프로세스(쓰레드)들이 같은 공유 자원을 사용할 때, 동시에 동일한 공유 자원에 접근하지 못하도록 하는 것.
쓰레드 간 동기화를 하는 가장 단순한 방법은 한 쓰레드가 CPU를 사용할 때 일시적으로 CPU에 들어오는 인터럽트들을 막는 것이다.
인터럽트 방지를 동기화에 사용하는 경우는 다음과 같다.
여러 스레드가 lock, semaphore, condition variable 을 얻기 위해 기다릴
경우 우선순위가 가장 높은 thread가 CPU를 점유 하도록 구현
Semaphore를 요청 할때 대기 리스트를 우선순위로 정렬
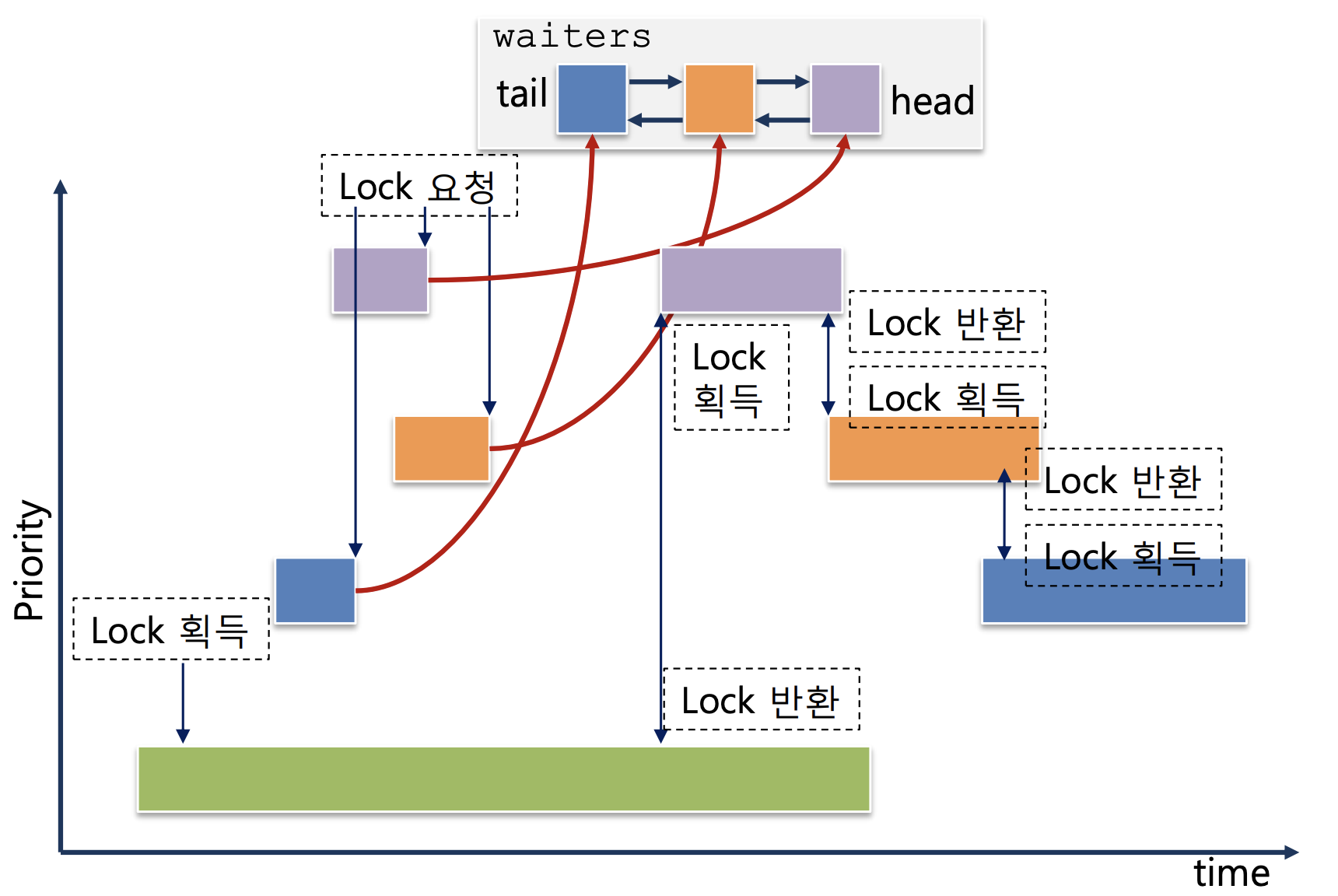
Priority Inversion Problem
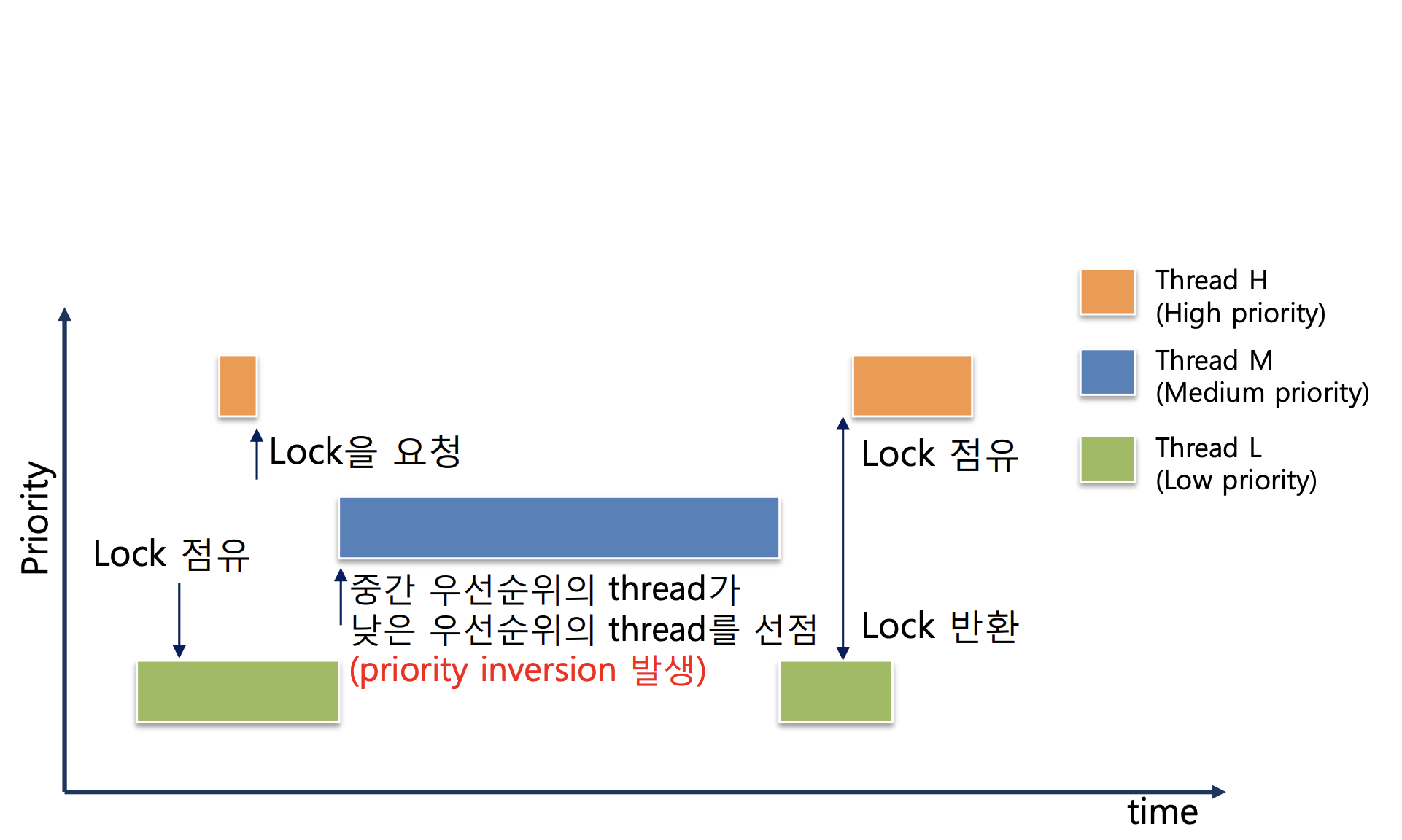
우선순위 스케줄링 시 발생할 수 있는 우선순위 역전 (priority inversion) 을 방지할 수 있는 priority inheritance(donation)기능을 구현합니다.
Priority Donation
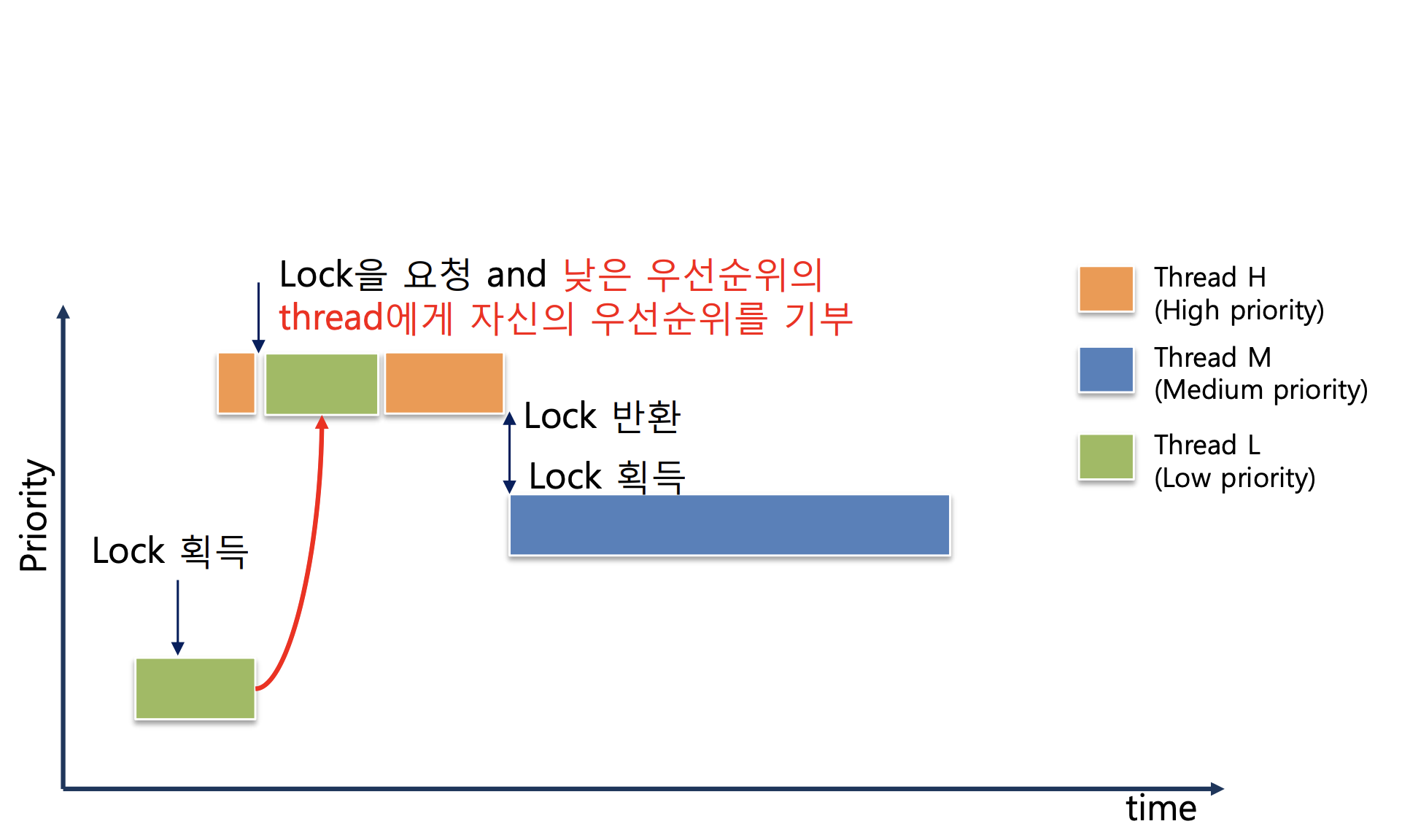
우선순위 역전 현상을 방지하기 위한 기술 중 하나로, 높은 우선순위의 스레드가 낮은 우선순위의 스레드에게 자신의 우선순위를 임시적으로 전달하는 것입니다. 이를 통해, 낮은 우선순위의 스레드가 높은 우선순위의 스레드에게서 필요한 자원을 받을 수 있도록 합니다.
Multiple Donation
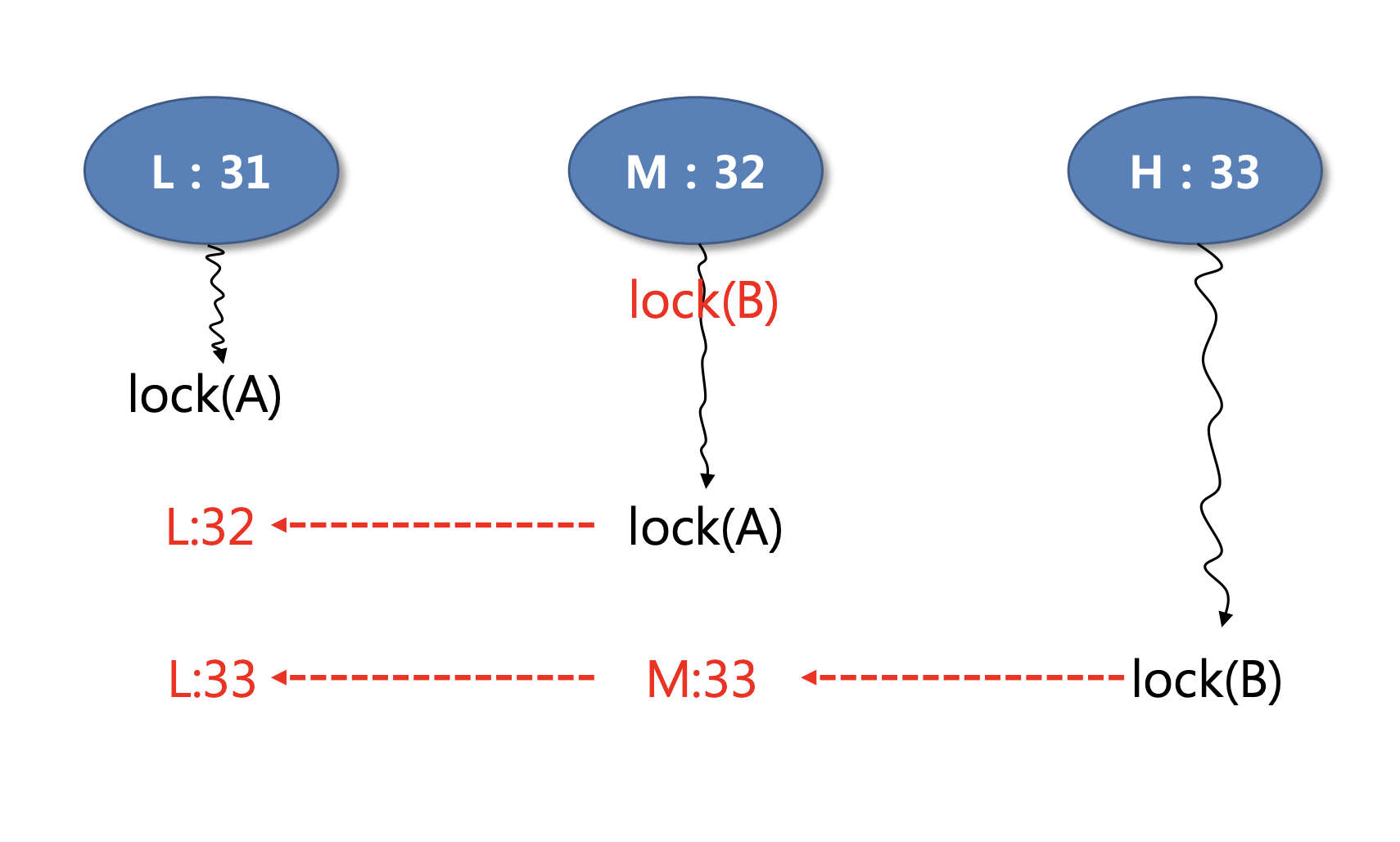
Priority Donation의 확장된 개념으로, 한 스레드가 여러 스레드에게 우선순위를 전달하는 것을 의미합니다. 이를 통해, 더 복잡한 우선순위 역전 상황에서도 스케줄링이 원활하게 이루어질 수 있습니다.
Nested Donation
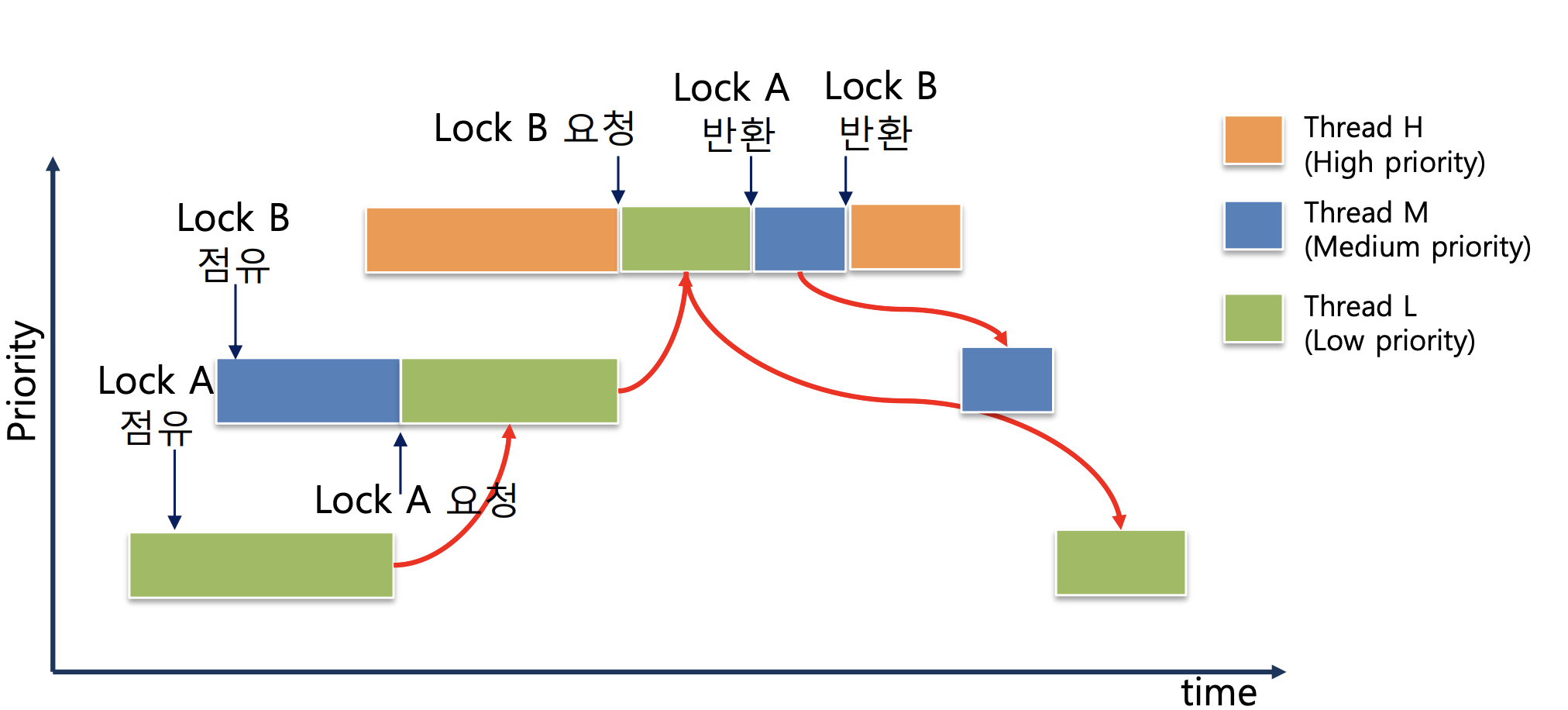
Multiple Donation을 더 발전시킨 개념으로, 스레드 간에 우선순위를 전달할 때, 그 우선순위가 다른 스레드에게 계속해서 전달되는 것을 말합니다. 이러한 방식을 통해, 우선순위 역전 상황이 더욱 복잡한 경우에도 스케줄링이 원활하게 이루어질 수 있습니다.
이러한 Priority Donation, Multiple Donation, Nested Donation은 모두 우선순위 역전 현상을 해결하기 위한 기술로, 스레드 간에 우선순위를 전달하는 방식을 활용합니다. 이를 통해, 더 효율적이고 원활한 스케줄링을 구현할 수 있으며, 시스템의 성능을 향상시킬 수 있습니다.
WIL
PintOS Week08
priority-fifo FAIL 발생
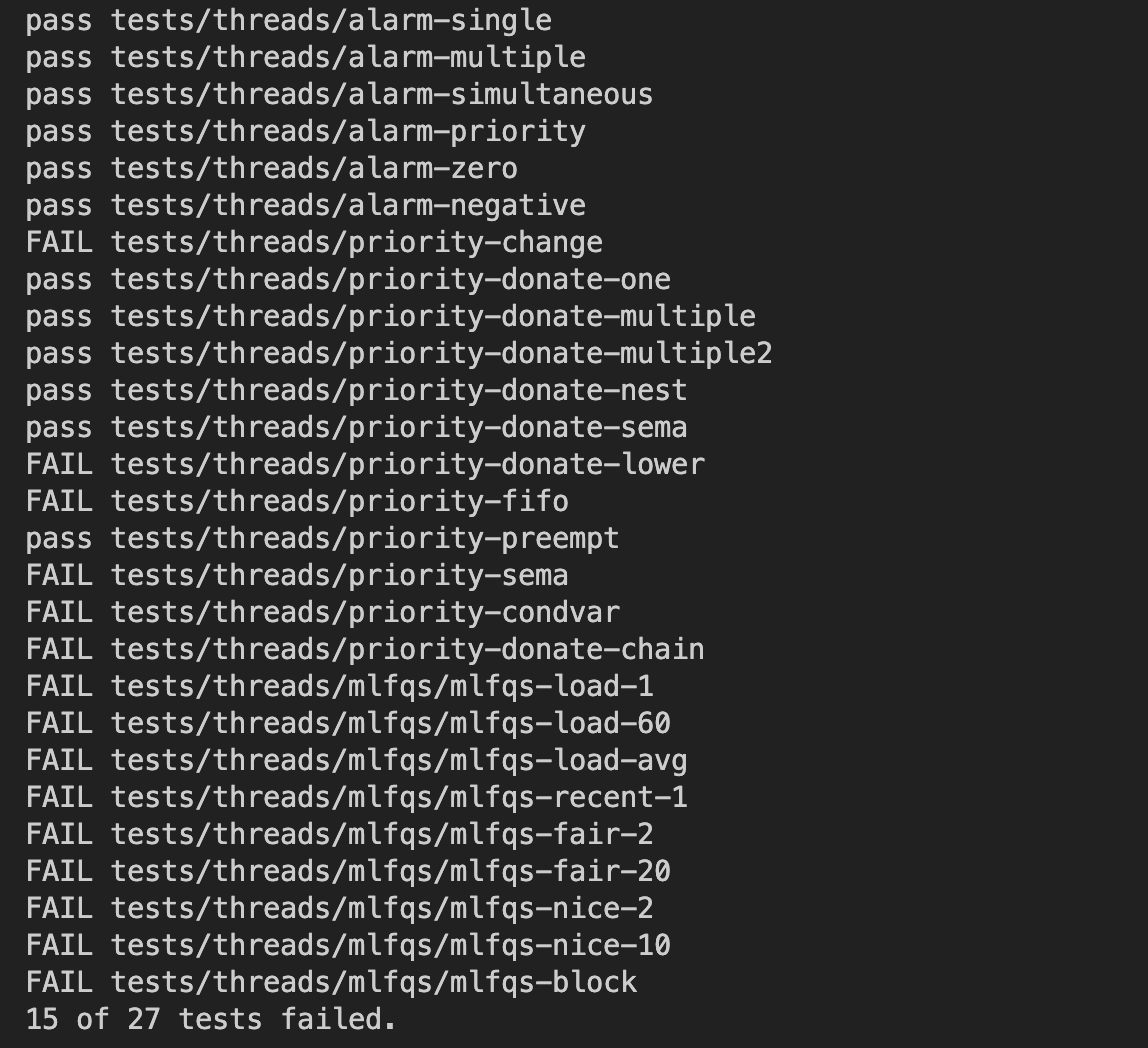
처음 우선순위 리스트를 만들고 테스트를 진행했을 때, priority-fifo가 통과되었지만
어느 순간부터 더 이상 통과하지 못하는 상황이 발생했습니다.
First iteration does not list all threads 0...15
pintos -v -k -T 60 -m 20 -- -q run priority-preempt < /dev/null 2> tests/threads/priority-preempt.errors > tests/threads/priority-preempt.output
perl -I../.. ../../tests/threads/priority-preempt.ck tests/threads/priority-preempt tests/threads/priority-preempt.result에러 메시지는
'첫 번째 반복에서 모든 스레드가 0부터 15까지 나열되지 않았음'
이라고 나와 있었지만, 단순히 메시지만으로는 어떤 문제가 발생한 것인지 파악하기가 쉽지 않았습니다
WHY?
왜 통과되던 테스트 케이스가 갑자기 실패한 것일까요?
priority-fifo .c
동일한 우선순위를 가진 여러 스레드가 일정한 순서로 실행되도록 스케줄링이 제대로 동작하는지 확인하는 데 사용
#include <stdio.h>
#include "tests/threads/tests.h"
#include "threads/init.h"
#include "devices/timer.h"
#include "threads/malloc.h"
#include "threads/synch.h"
#include "threads/thread.h"
/* 스레드 데이터를 저장하기 위한 구조체 */
struct simple_thread_data
{
int id; /* Sleeper ID. */
int iterations; /* Iterations so far. */
struct lock *lock; /* Lock on output. */
int **op; /* Output buffer position. */
};
#define THREAD_CNT 16 /* 스레드 개수 */
#define ITER_CNT 16 /* 반복 횟수 */
/* 스레드 함수 정의 */
static thread_func simple_thread_func;
void
test_priority_fifo (void)
{
struct simple_thread_data data[THREAD_CNT];
struct lock lock;
int *output, *op;
int i, cnt;
/* This test does not work with the MLFQS. */
ASSERT (!thread_mlfqs);
/* 우선 순위가 기본값인지 확인 */
ASSERT (thread_get_priority () == PRI_DEFAULT);
msg ("%d threads will iterate %d times in the same order each time.",
THREAD_CNT, ITER_CNT);
msg ("If the order varies then there is a bug.");
output = op = malloc (sizeof *output * THREAD_CNT * ITER_CNT * 2);
ASSERT (output != NULL);
lock_init (&lock);
/* 현재 스레드의 우선 순위를 NEW_PRIORITY로 설정 */
thread_set_priority (PRI_DEFAULT + 2);
for (i = 0; i < THREAD_CNT; i++)
{
char name[16];
struct simple_thread_data *d = data + i;
snprintf (name, sizeof name, "%d", i);
d->id = i;
d->iterations = 0;
d->lock = &lock;
d->op = &op;
/* 새로운 스레드를 생성하고 초기화하는 함수 */
thread_create (name, PRI_DEFAULT + 1, simple_thread_func, d);
}
thread_set_priority (PRI_DEFAULT);
/* All the other threads now run to termination here. */
ASSERT (lock.holder == NULL);
cnt = 0;
for (; output < op; output++)
{
struct simple_thread_data *d;
ASSERT (*output >= 0 && *output < THREAD_CNT);
d = data + *output;
if (cnt % THREAD_CNT == 0)
printf ("(priority-fifo) iteration:");
printf (" %d", d->id);
if (++cnt % THREAD_CNT == 0)
printf ("\n");
d->iterations++;
}
}
/* 매개변수로 전달된 데이터를 처리 */
static void
simple_thread_func (void *data_)
{
struct simple_thread_data *data = data_;
int i;
for (i = 0; i < ITER_CNT; i++)
{
lock_acquire (data->lock); /* 락 획득 */
*(*data->op)++ = data->id; /* 출력 버퍼에 스레드 ID 기록 */
lock_release (data->lock); /* 락 해제 */
thread_yield (); /* 스레드 양보 */
}
}먼저 simple_thread_data 라는 구조체를 선언합니다. 이 구조체는 새로 생성될 스레드 구조체입니다.
매크로를 통해 생성될 스레드의 갯수와 반복문이 실행될 횟수를 지정해줍니다. 이제 테스트가 실행되는 test_priority_fifo 함수를 보겠습니다.
변수들을 선언한 후, 우선순위의 기본값을 확인하고 메모리 할당 및 실패 여부를 체크하고 있습니다. 그리고 lock_init 함수로 락을 초기화합니다. 이어서 thread_set_priority 함수를 사용하여 현재 실행 중인 스레드의 우선순위를 디폴트값 31에서 2 올린 33으로 설정하고, 반복문을 실행합니다.
반복문을 통해 id 값이 0인 스레드부터 15까지의 스레드를 생성한 뒤, 반복문이 종료되면 다시 thread_set_priority 을 통해서 현재 실행 중인 스레드의 우선순위를 디폴트 값인 31로 변경합니다.
현재 스레드의 우선순위 값을 디폴트 값인 31로 변경하면 현재 스레드의 우선순위 값이 위에서 생성한 스레드들의 우선순위인 디폴트 +1 , 즉 32보다 작아져서 현재 작업 중인 스레드는 cpu점유 권한을 뺏기고 레디 리스트로 들어가야 합니다.
이제 생성된 simple_thread_data가 cpu를 점유하고 아래의 반복문을 수행하면서 각 요소들의 ID 값을 출력하고, 반복문이 완료되면 락을 가지고 있지 않은 테스트 스레드는 ASSERT에 의해 종료되면서 테스트가 통과될 것이라고 생각했습니다.
thread_set_priority
/* Sets the current thread's priority to NEW_PRIORITY. */
void
thread_set_priority (int new_priority) {
thread_current ()-> priority = new_priority;
/* 해당 스레드가 donation을 받고 있다면, 초기 우선 순위보다 더 큰 값으로 우선 순위가 갱신 */
refresh_priority();
/* 스레드를 비교하여, 현재 스레드의 우선순위가 더 낮을 경우 스레드 교체 */
test_max_priority();
}marefresh_priority
void refresh_priority(void)
{
struct thread *cur = thread_current();
cur->priority = cur->original_priority; /* 미리 저장해둔 진짜 우선순위*/
/* donation을 받고 있다면 */
if (!list_empty(&cur->donators_list)) {
list_sort(&cur->donators_list, cmp_donator_priority, NULL);
struct thread *top_pri_donator = list_entry(list_front(&cur->donators_list), struct thread, d_elem);
if (top_pri_donator->priority > cur->priority) { /* 만약 초기 우선 순위보다 더 큰 값 */
cur->priority = top_pri_donator->priority;
}
}
}thread_set_priority 함수와 refresh_priority 함수를 확인해보았습니다.
현재 스레드의 우선순위 값을 변경하기 위해 priority에 new_priority를 할당해 주고 있었지만, 해당 스레드가 도네이션을 받고 있다면, 초기 우선 순위보다 더 큰 값으로 우선 순위가 갱신 시킨다는 fresh_priority함수에서 다시 한번 original_priority라는 값을 현재 스레드의 우선순위에 할당해주고 있다는 문제를 발견했습니다.
priority-fifo .c
void
test_priority_fifo (void)
{
struct simple_thread_data data[THREAD_CNT];
struct lock lock;
int *output, *op;
int i, cnt;
/* This test does not work with the MLFQS. */
ASSERT (!thread_mlfqs);
/* Make sure our priority is the default. */
ASSERT (thread_get_priority () == PRI_DEFAULT);
msg ("%d threads will iterate %d times in the same order each time.",
THREAD_CNT, ITER_CNT);
msg ("If the order varies then there is a bug.");
output = op = malloc (sizeof *output * THREAD_CNT * ITER_CNT * 2);
ASSERT (output != NULL);
lock_init (&lock);
thread_set_priority (PRI_DEFAULT + 2);
for (i = 0; i < THREAD_CNT; i++)
{
char name[16];
struct simple_thread_data *d = data + i;
snprintf (name, sizeof name, "%d", i);
d->id = i;
d->iterations = 0;
d->lock = &lock;
d->op = &op;
thread_create (name, PRI_DEFAULT + 1, simple_thread_func, d);
}
thread_set_priority (PRI_DEFAULT);
/* All the other threads now run to termination here. */
ASSERT (lock.holder == NULL);
cnt = 0;
for (; output < op; output++)
{
struct simple_thread_data *d;
ASSERT (*output >= 0 && *output < THREAD_CNT);
d = data + *output;
if (cnt % THREAD_CNT == 0)
printf ("(priority-fifo) iteration:");
printf (" %d", d->id);
if (++cnt % THREAD_CNT == 0)
printf ("\n");
d->iterations++;
}
}즉 지금까지 테스트는 현재 스레드가 thread_set_priority 함수를 통해 인자로 주어진 new_priority로 갱신하지 못한 채 기본값인 31인 상태로 반복문을 실행하게 되었고, 그 결과 새로 생성된 스레드들이 32의 우선순위 값을 가지게면서 디폴트 값인 31의 우선순위를 가지고 있는 현제 스레드를 bolck시키고 새로 생성된 스레드가 CPU를 점유하고 반복문이 완료되기전에 생성된 스레드가 실행되고 있어서 테스트에 실패하고 있다는 사실을 확인했습니다.
thread_set_priority 수정
/* Sets the current thread's priority to NEW_PRIORITY. */
void
thread_set_priority (int new_priority) {
// thread_current ()-> priority = new_priority;
thread_current ()->original_priority = new_priority;
refresh_priority();
test_max_priority ();
}그래서 thread_set_priority 함수에 현재 스레드의 priority를 재할당 해주는 부분인 thread_current의 priority를 original_priority로 수정하고 테스트한 결과, 통과한 것을 확인할 수 있었습니다.
