글의 목적
로그를 남길 때 System.out 이 아닌 Logger를 이용하라는 글들을 보았습니다.
하지만 명확한 이유는 알 수 없어, 이 글을 통해 코드를 분석하며 그 이유를 파악하고자 합니다.
System.out 과 Logger의 출력 방식을 분석해보며 차이를 알아보겠습니다.
System.out 출력 방식
public void println(String x) {
if (getClass() == PrintStream.class) {
writeln(String.valueOf(x));
} else {
synchronized (this) {
print(x);
newLine();
}
}
}
private void writeln(String s) {
try {
synchronized (this) {
ensureOpen();
textOut.write(s); // 1
textOut.newLine();
textOut.flushBuffer();
charOut.flushBuffer(); // 2
if (autoFlush)
out.flush(); // 3
}
}
catch (InterruptedIOException x) {
Thread.currentThread().interrupt();
}
catch (IOException x) {
trouble = true;
}
}System.out.println() 함수의 내부 코드입니다. PrintStream 이용해서 출력하는 경우만 가져왔습니다.
동작은 아래와 같습니다.
1. textOut 이 char 의 형태로 버퍼에 저장합니다.
2. charOut 이 byte 의 형태로 버퍼에 저장합니다.
3. out이 flush() 를 통해 출력합니다.
동기적이고 println 메소드를 호출하는 즉시 출력하는 것을 알 수 있습니다.
(out = null, autoFlush = false 로 정의되어 있지만, JNI 를 이용하여 JVM 이 out 값을 할당하고 autoFlush = true 로 변경하는 것 같습니다)
- 동기화 문제
Spring Boot는 대부분 멀티스레딩 환경에서 돌아갑니다. 멀티 스레딩 환경에서System.out을 사용하여 로그를 남길 경우, 다른 스레드가 로그를 남길 동안 기다리는 시간이 발생하여 애플리케이션 처리 속도가 느려질 수 있습니다. - 버퍼 문제
메소드를 호출할 때마다 출력하므로 I/O 작업을 자주 요청하게 되어 컨텍스트 스위칭, I/O 작업으로 인한 대기 시간 등으로 성능이 저하될 가능성이 있습니다.
Logger 출력 방식(Logback)
Springboot에서 Logger는 Slf4j 라는 추상화 레이어를 제공하고 기본적으로 Logback 을 채택하고 있습니다. 예제에서도 Logback을 기준으로 진행하겠습니다.
자바 프로젝트에 Logback 설정
// build.gradle
dependencies {
implementation 'org.slf4j:slf4j-api:1.7.25'
implementation 'ch.qos.logback:logback-classic:1.4.12'
}<!-- src/main/resources/logback.xml-->
<configuration>
<!-- Appender의 이름을 STDOUT으로 지정합니다. 이 이름은 로그 설정 내에서 이 Appender를 참조할 때 사용됩니다.-->
<!-- ConsoleAppender 클래스를 사용하여 로그를 콘솔에 출력합니다. 표준 출력(콘솔)으로 출력하도록 합니다. -->
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
<!-- 루트 로거의 레벨을 설정합니다-->
<!-- DEBUG 레벨 이상의 모든 로그(예: DEBUG, INFO, WARN, ERROR)가 기록합니다.-->
<root level="debug">
<!-- 루트 로거에 이름이 STDOUT인 로거를 연결합니다. 이는 루트 로거가 생성하는 로그를 STDOUT으로 보냅니다.-->
<!-- (로그 메시지를 콘솔에 출력하도록 설정합니다)-->
<appender-ref ref="STDOUT" />
</root>
</configuration>위와 같이 Logback을 의존성 추가하고 로그 처리 방식을 정의하였습니다.
public class Main {
public static void main(String[] args) {
Logger logger = LoggerFactory.getLogger(Main.class);
logger.info("Example log from {}", Main.class.getSimpleName());
}
}
설정하고 난 뒤 로그를 남기게 되면 출력하는 것을 볼 수 있습니다.
정상적으로 출력을 뱉었으니 코드를 분석하여 동작 방식을 알아보겠습니다.
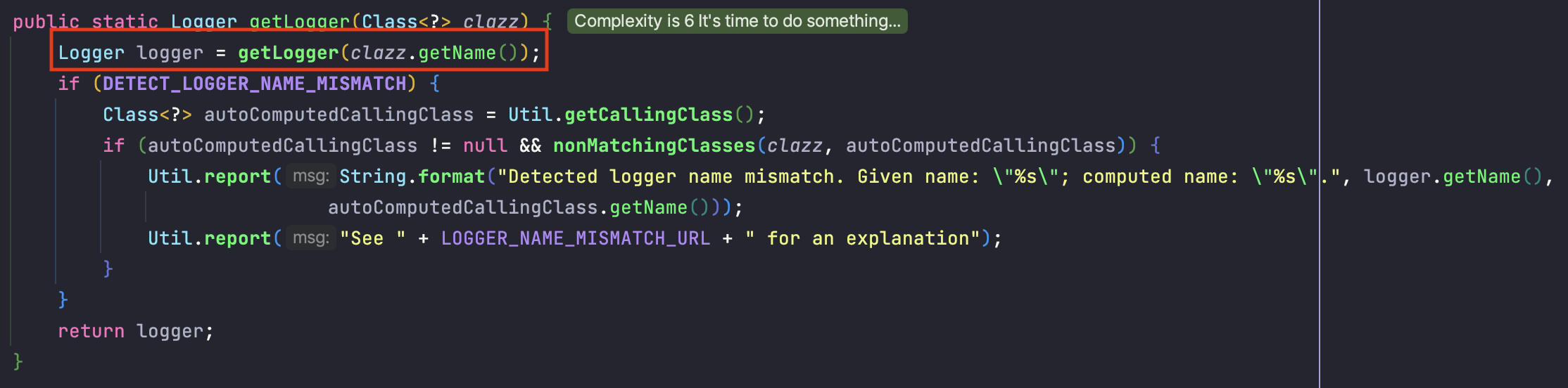
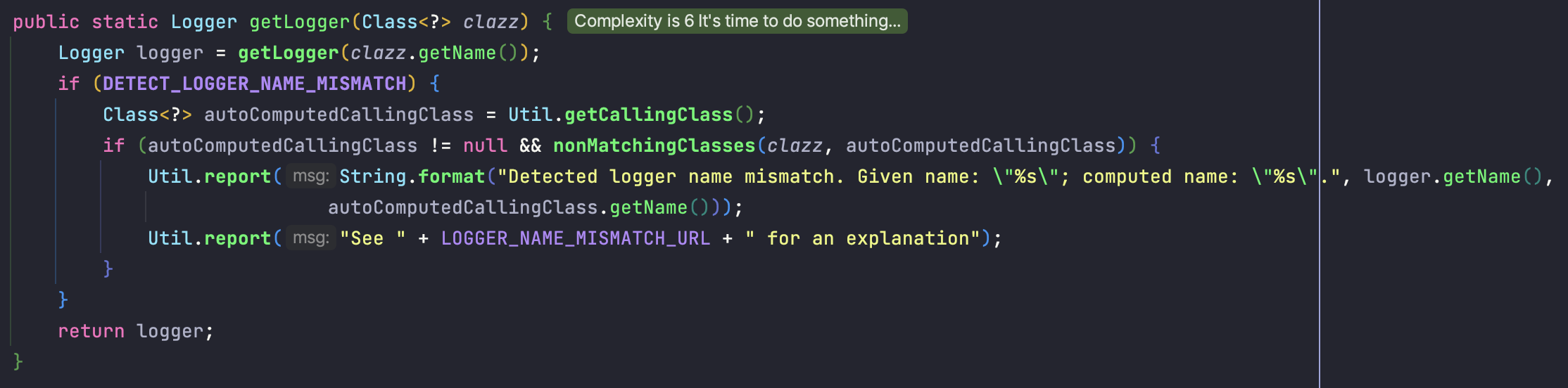
빨간 박스를 제외한 곳은 호출한 클래스와 전달된 클래스가 일치하는지 검사하는 것이므로 빨간 박스만 살펴보겠습니다.
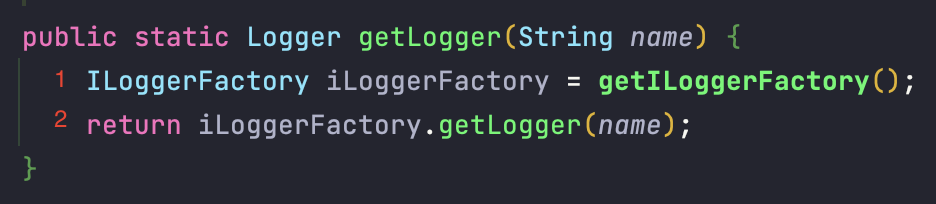
1 - logger를 생성할 팩토리를 얻습니다.
2 - logger 인스턴스를 생성합니다.
logger를 어떻게 생성하여 넘겨주는지를 알아보겠습니다. logger를 매번 생성하는 것은 리소스 낭비가 심할 테니 아마도 생성된 logger를 넘겨줄 것 같습니다.
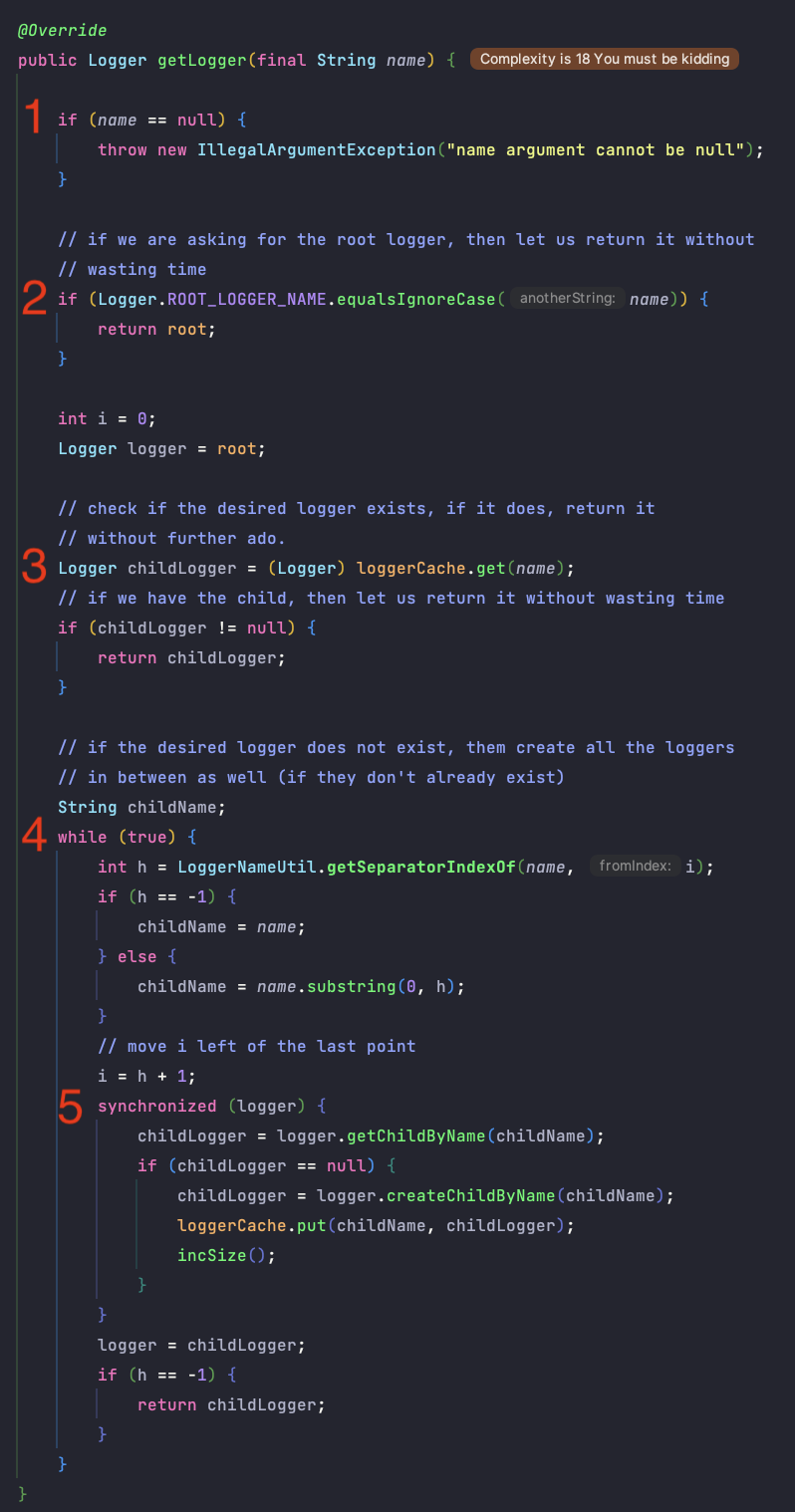
1 - 이름이 null일 경우 예외를 발생시킵니다.
2 - 루트 네임과 일치한다면 바로 리턴합니다.(루트 네임은 생성하는 것이 아닌 처음에 만들어져 있는 것 같습니다)
3 - 로거캐시에서 전달받은 네임을 찾습니다.(예상했던대로 매번 생성하는 것이 아닌 저장하고 있습니다)
4 - 아직 생성이 되지 않은 로거라면 생성합니다.
'.' 위치를 찾아 h에 할당합니다. '.' 기준으로 이름을 파싱합니다.
5 - 로거를 찾고 존재하지 않는다면 생성하여 로거캐시 계층 맵에 넣습니다.
여러 스레드에서 생성하는 것을 방지하기 위해 동기화 블록 안에서 진행합니다.
파싱한 이름에 해당하는 로거가 자식 로거로 존재하는지 확인합니다.
존재하지 않는다면 로거에 파싱한 이름으로 자식 로거를 생성하여 추가합니다.
(로거는 상위 로거의 설정을 하위 로거에 자동적으로 적용합니다. 또한 패키지, 모듈적으로 관리할 때도 효율적이라 계층적으로 관리하는 것 같습니다)
로거를 어떻게 관리하고 있는지 확인했습니다. 이제 로그를 어떻게 출력하는지 확인해보겠습니다.

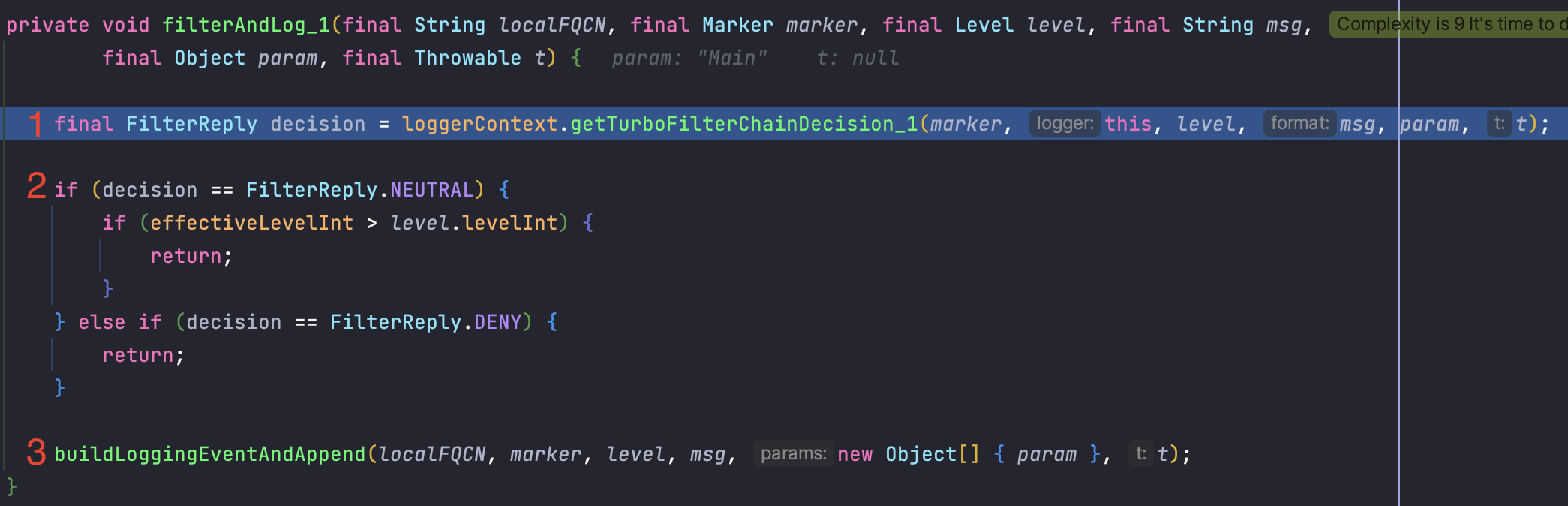
매개변수 설명
FQCN: 클래스 이름
marker: 마커, 로그 이벤트에 태그를 답니다.(긴급, 보안, 성능 등) 이를 기반으로 필터링을 하거나 특정 액션을 취할 수 있습니다.
level: 로그 레벨
msg: 메시지
param: 메시지의 매개변수
t: 예외

1 - 터보 필터 리스트에 필터가 없는 경우 중립으로 리턴합니다.(로그 이벤트에 대한 결정을 내리지 않음) 필터가 존재한다면 필터를 순회하며 로그 이벤트를 수락할지, 거부할지, 중립으로 할지를 결정합니다.

2 - 중립이라면 effective level 에 따라 이벤트 처리 여부를 결정합니다. 위 그림처럼 설정되어 있습니다.(각 레벨과 숫자를 매핑하여 바로 비교할 수 있습니다, OFF가 Integer.MAX_VALUE로 가장 높고 TRACE가 5000으로 낮습니다.)
그래서 effective Level 를 OFF로 설정하였다면 ERROR ~ TRACE 까지는 로그 이벤트를 처리하지 않고 리턴합니다.

3 - 로그 이벤트를 생성하고 Appender 에게 전달합니다.
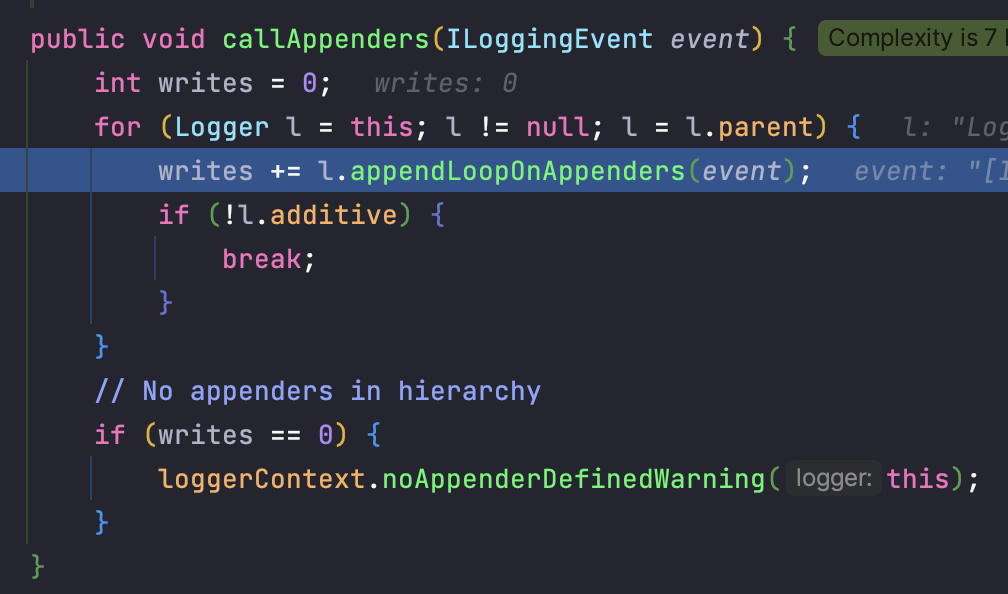
부모 로거로 올라가면서 해당 로거에 등록된 모든 Appender 에게 로그 이벤트를 전달합니다.
additivity == false 일 경우 전달을 멈춥니다.
appendLoopOnAppenders() 메서드를 살펴보며 로그 이벤트 처리에 대해 자세히 알아보겠습니다.

aai 는 아마도 Appender Attachment Information 의 약자 같습니다. aai 는 null 이 기본 값인데, Appender 가 설정되면 값이 할당됩니다.
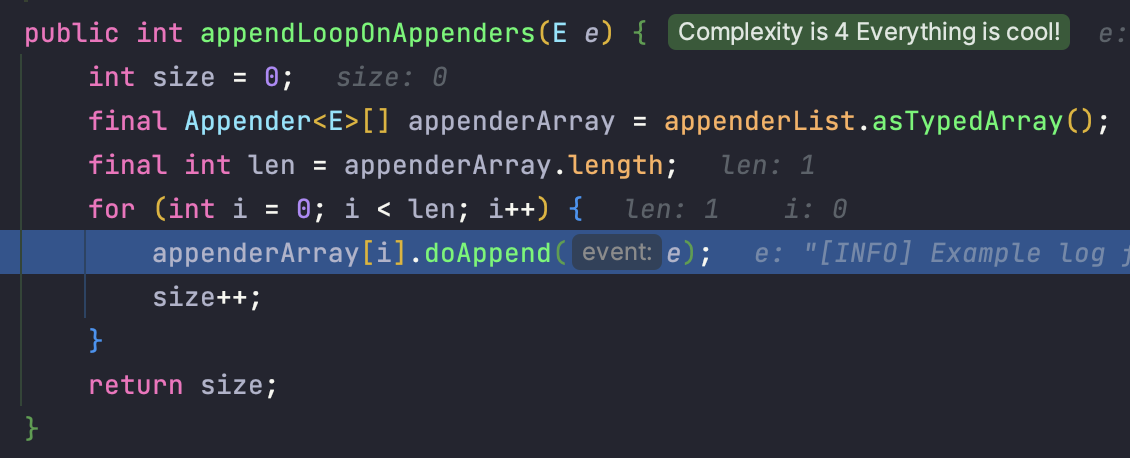
aai 가 할당되었다면 해당 로거의 모든 Appender 에게 로그 이벤트를 처리하도록 요청합니다.
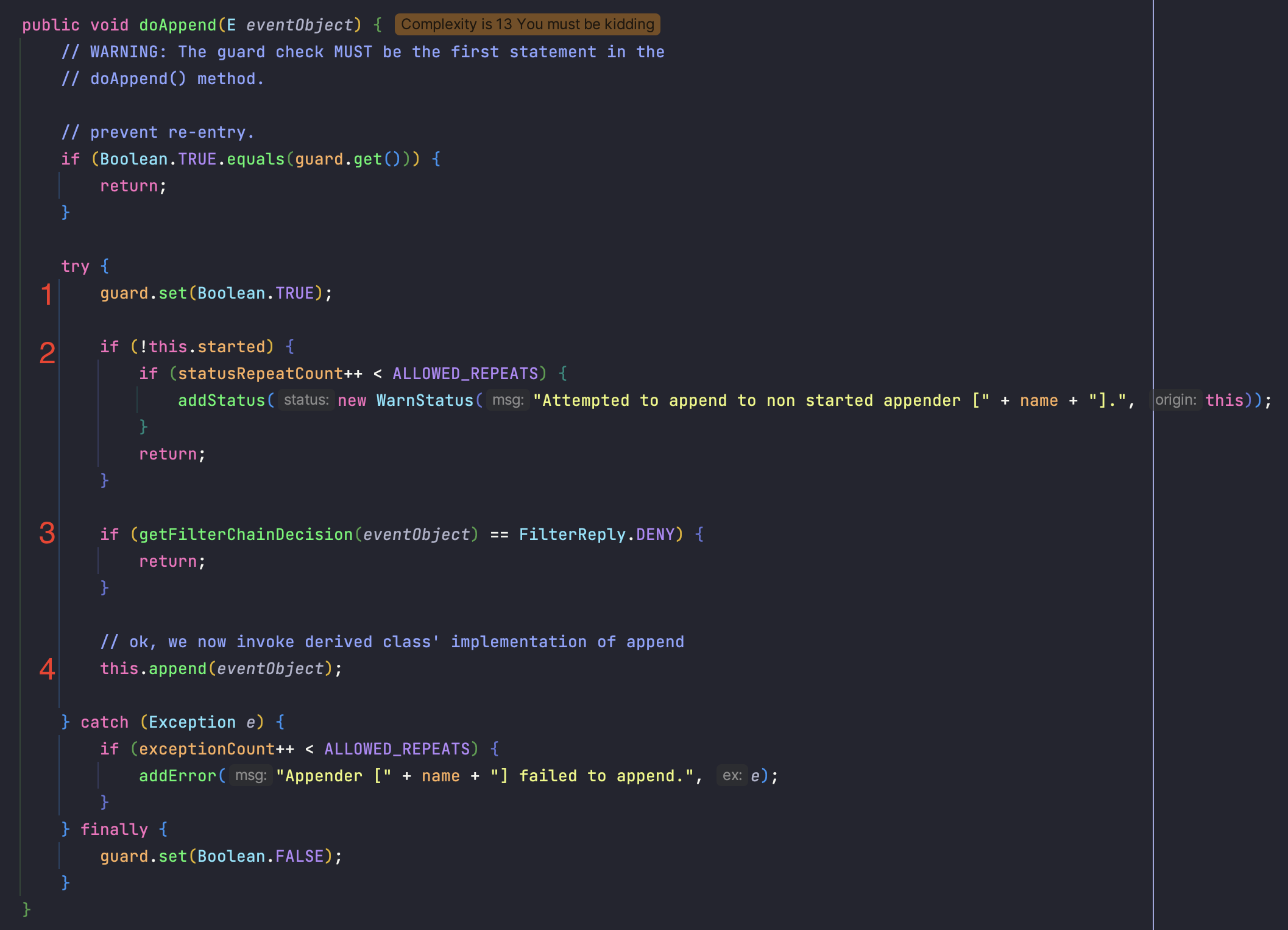
실제 로그 이벤트를 처리하는 메소드입니다.
1 - guard 라는 ThreadLocal 변수값을 true 로 변경합니다.
로깅 과정에서 다시 로깅을 호출하는 재귀적 상황을 막기 위해 사용합니다.
2 - 어떠한 이유에서 Appender 가 실행되지 않았을 때 경고 메시지를 추가하고 리턴합니다.(만약 지속적으로 실행되지 않는다면 많은 경고 메시지는 쌓일 수 있습니다. ALLOWED_REPEATS 크기까지만 경고 메시지를 추가합니다)
3 - 필터 체인이 DENY 상태라면 로그 이벤트를 무시하고 리턴를 반환합니다.
4 - 로그 이벤트 처리를 합니다.(이 부분에서 로그를 남깁니다)
로그 남기는 부분을 더 들어가보겠습니다.

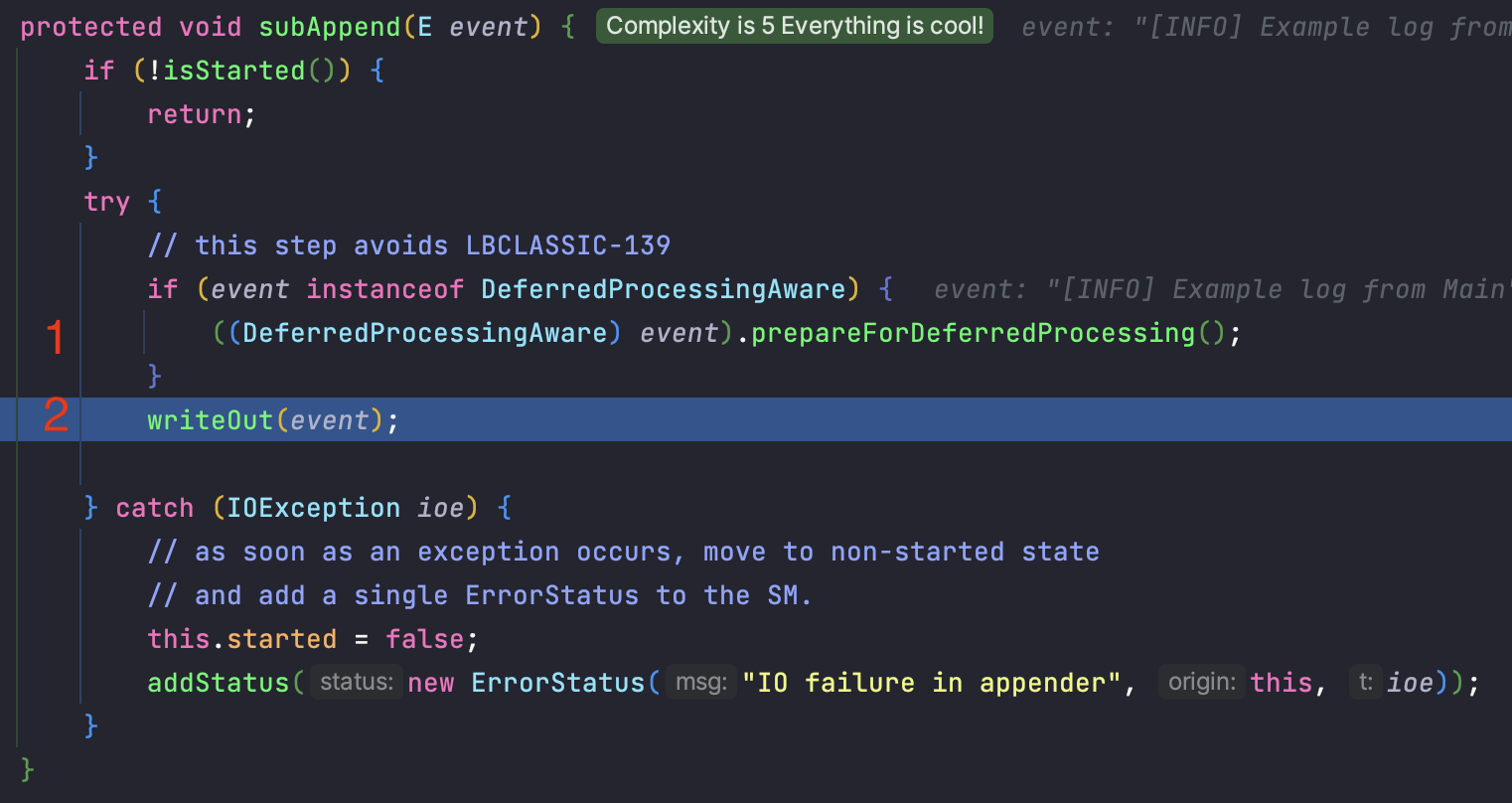
1 - 로그 이벤트를 전처리합니다.
2 - 로그를 실제로 기록합니다.
로그를 기록하는 부분이 궁금하니 writeOut() 메소드로 들어가보겠습니다.
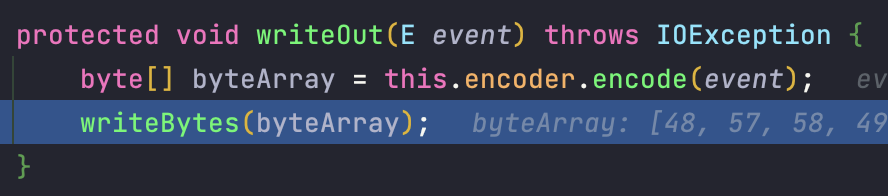
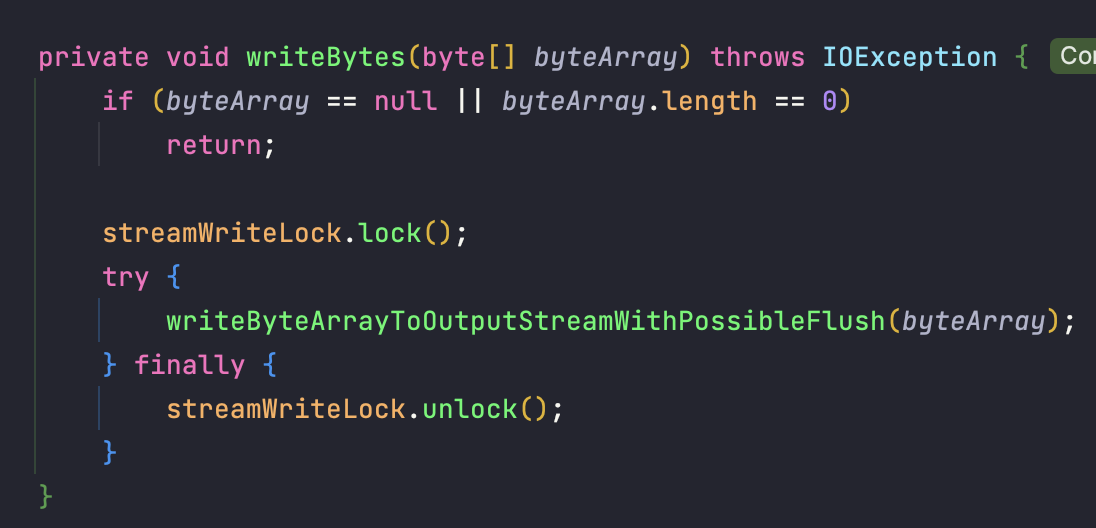

로그를 실제로 기록하는 메서드 흐름입니다.
전달한 문자열을 바이트로 변환하여 outputStream 에 씁니다.
이 때 streamWriteLock 에 락을 걸어 여러 스레드들이 출력 스트림에 접근하는 것을 막습니다. (단순히 동기화를 하여 기다리는 것이 아닌 실패할 때의 대응이나 대기 시간 설정 등 동기화보다 유연하게 전략을 가져갈 수 있습니다)
Logger 출력 방식에 대한 생각 정리
Logger를 까보기 전까지는 Logger는 동기화와 버퍼 문제를 우회해서 빠르게 처리할 것 같았습니다. 하지만 System.out 과 동일하게 동기화와 버퍼문제를 가지고 있습니다. 파일이나 콘솔에 시간 순서대로 출력을 하여야 하고 버퍼에 쌓아 두는 것도 메모리 점유 문제가 있으니 어떻게 보면 당연한 것 같습니다.
그래도 확실한 장점은 존재한다고 생각합니다.
Logger를 계층별로 관리하여 여러 곳에 로그를 남길 수 있습니다.
로그를 남기기 위한 여러 전략을 택할 수 있습니다.
또한, 락을 바이트를 출력하는 부분에만 걸어 동시성 문제를 최소화하고 있습니다.(System.out 은 String 변환부터 동기화 처리)
비교 생각 정리
글을 작성하기 전에는 System.out 은 느리고 Logger를 통한 로그는 빠를 줄 알았습니다. 하지만 실제 코드를 분석하고 참조에 첨부된 글(로그 성능 비교)의 테스트를 보며 그렇지 않다는 것을 알 수 있었습니다.
Logger의 구동 방식에 대해 대략적 이해하였으므로 현재 내가 택하고 있는 로그 전략을 인지하고 다른 전략을 필요할 경우 고민할 수 있을 것 같습니다.
결론
로깅은 애플리케이션의 진단, 모니터링에 있어 중요한 역할을 하지만, 너무 많은 로그는 시스템의 성능을 저하시킬 수 있습니다.
로그 환경에 따라 적절한 로그 레벨 설정과 필터링, 로그의 양을 조절하는 것이 중요합니다.
또한, 잘 구성된 로그 전략은 필요한 정보를 효과적으로 기록하면서 성능을 유지할 수 있습니다.
참조
System.out
System.out 동작 원리 까보기 - Devvy
System.out.flush()는 언제 되는가?
Logger
Logback 공식 문서
로그백 가이드 - baeldung
로그 성능 비교 - sebastiandaschner
