https://www.youtube.com/watch?v=C6MX5u7r72E
1406 바킹독 python
참고 https://velog.io/@chez_bono/Python-백준-1406-에디터
연결리스트란 ?
원소들을 저장할 때 그 다음 원소가 있는 위치를 포함시키는 방식으로 저장하는 자료구조이다.
원소들은 이곳 저곳에 흩어져있다.
-실생활의 예시
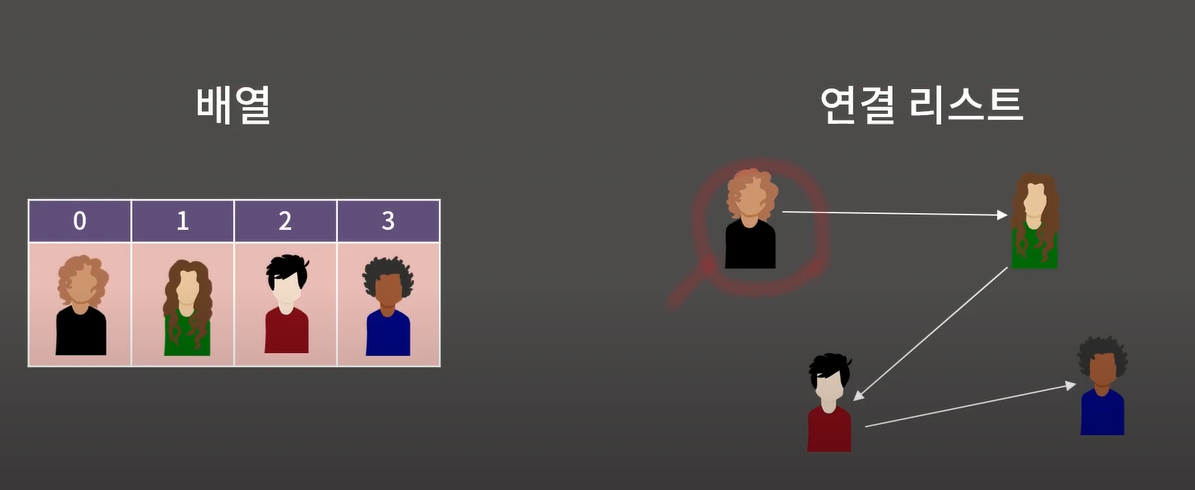
각각의 0 1 2 3 학생들을 기억하고싶다!
배열 → 4칸짜리 배열을 만들고 4명을 저장
그러나 연결리스트 관점에서는 0 → 1 기억 , 1 → 2 기억 2 → 3 기억
배열과다르게 연결리스트에서는 0번만기억해줘도 다기억할수있는 장점이있다.
-성질

- 3번째원소인
72를 찾고싶다면
3을거치고 13을 거쳐서 찾기때문에
⇒ O(k)가 걸린다.
-
임의의 위치에
원소를 추가/ 임의 위치에원소 제거는 O(1)이다.→ 연결리스트의 가장 큰 장점 (중요)
- 메모리상 연속 x 이므로
cache hit rate가 낮지만 할당이 다소 쉽다.
cache hit rate ⇒ 데이터 임시 저장 영역인 캐시의 효율성을 측정한 것
-연결 리스트의 종류

단일 연결리스트는 각원소가 다음의 원소위치값을 들고있음

이중연결리스트는 이전의 원소위치값, 다음의 원소위치값 도 들고있다.
원소가 가지고 있어야 하는 정보가 1개 더 추가되니 메모리가 더 든다는 단점이 있다.

원형 연결리스트는 끝이 처음과 연결되어있다.
그림상에서는 단일연결리스트로 표현되어있지만 이전주소를 연결해줘도 되는 이중연결리스트로도 상관이없다.
연결리스트는 원소들 사이에 선후 관계가 일대일로 정의가 된다.
즉 원소들 사이에서 첫번째원소 두번째 원소 … 이런개념이 존재
→선형 자료구조
선형 구조(Linear)선형 구조란,
자료를 구성하는 원소들을 하나씩 순차적으로 나열시킨 형태
자료들간의 앞, 뒤 관계가 1:1의 관계로 배열과 리스트가 대표적이며 스택과 큐도 이에 해당됩니다.
추가적으로 필요한 공간
: overhead 생각해보면 배열은 데이터만 딱딱 저장하면 될 뿐 딱히 추가적으로 필요한 공간이 없다.
하지만 연결리스트의 경우 다음원소의 주솟값을 가지고있어야하니 또는 이전과 다음
컴퓨터가 32bit(=4byte) 라면 4N 바이트가 필요
→ 즉, N에 비례하는 만큼의 메모리를 추가로 쓰게된다.
기능 구현
1.확인/변경
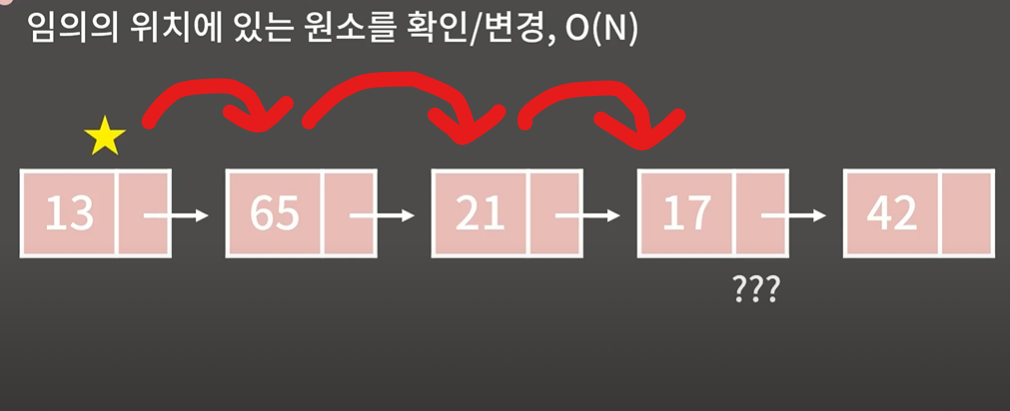
ex) 4번째 위치의 원소에 접근/ 변경
첫번째원소의 기록 주소 → 두번째
두번째 원소의 기록 주소 → 세번째
네번째로 이동하게된다.
k번째 원소를 확인하려면
O(k)의 시간이 필요하다.
평균적으로 O(N/2) 가걸릴테니 O(N)이라고 생각하면된다.
2.추가 (중요)
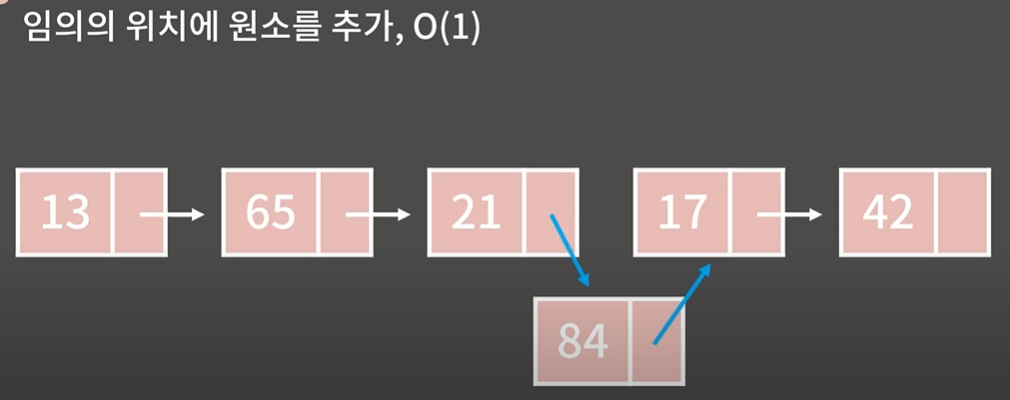
뒤의 원소들을 전부 옮기는 작업을 할필요 X
→ 그냥 21과 84에서 다음원소의 주소만 변경을 해주면 되기 때문에 O(1)의 시간이 걸린다.
추가하고 싶은 위치의 주소를 앍고 있을 경우에만 O(1)
만약 21의 주소를 준것이아니라
84라는값을 3번째 원소뒤에 찾아가라하면 찾아가는 시간이 걸리므로 더 걸린다.
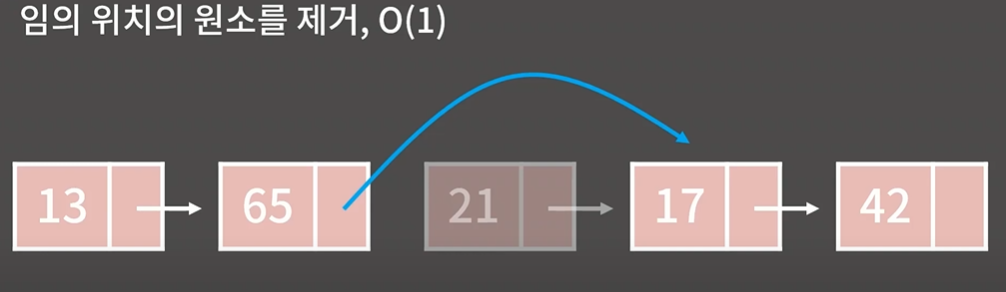
3.제거
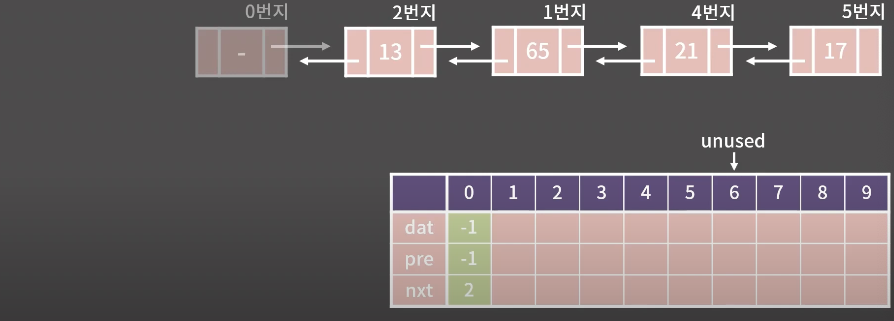
21을 지우라고 하면 65에다가 다음원소가 17이라고 알려주면됨
21은 메모리에서 없애줌 (메모리 누수원인)
연결리스트는 메모장과 같은 텍스트 에디터 문제에 사용하기 좋다
커서를 옮기고 글자를 지우는 것과 같은 연산들이 다양하게 주어진후 결과를 출력하라는 문제가 그 예시다.
⇒ 임의의 위치에서 원소를 추가하거나 임의 위치의 원소를 제거하는 연산을 많이 해야 할경우에는
-연결리스트의 사용
하지만 python에서도 라이브러리인 queue를 제공한다.
긴박한 코딩테스트에서는 해당 라이브러리를 이용하지만
구현난이도가 괜찮은 야매 연결리스트를 직접 구현해보자.
야매 연결리스트
-
원소를 배열로 관리
-
pre와 nxt에 이전/다음 원소의 포인터 대신 배열상의 인덱스를 저장하는 방식으로 구현한 연결 리스트
→ 메모리 누수때문에 실무에서는 절때 쓸 수 없는 방식
→ 코테에서는 일반적인 연결 리스트보다 낮고 시간복잡도도 동일하기 때문에 애용
필요한것
- dat[i] : i번지 원소의 값,
- pre[i] : i번지 원소에 대해 이전 원소의 인덱스
- nxt[i] : 다음 원소의 인덱스
pre나 nxt 값이 -1이면 해당원소의 이전 / 다음원소가 존재 x
-
unused : 현재 사용되지 않는 인덱스 → 새로운 원소가 들어갈 수 있는 인덱스
원소가 추가된 경우에는 1씩 증가
특별히 0번지는 연결 리스트의 시작 원소로 고정
→ 0번지는 값이 들어가지않고 시작점을 나타내기 위한 dummy code
길이가 필요하다면 len 변수를 두고 길이가 증가할때마다 + 1 줄어들때마다 -1 하면 된다.
ex) 연결 리스트는 13,65,21,17이라는 값을 가진다.
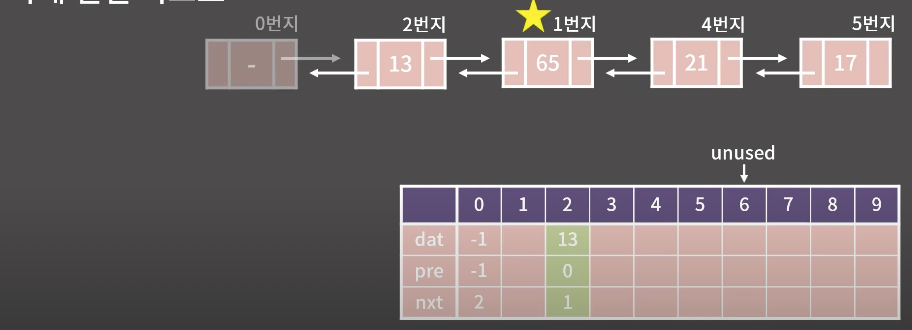
각각의 원소가 임의의 위치에 저장되어 있다고 가정한다.
실제로는 unused 가리키는 위치 한칸 전까지 사이에서 아무데나 위치함
0번지는 시작원소로 고정
→dummy code가 없다면 삽입과 삭제등의 기능을 구현할 때 원소가 아예 없는 경우에 대한 예외처리를 하기위함
dat는 의미가 없으니 -1
pre는 이전원소가 없으니 -1
nxt는 13이 들어있는 주소인 2번지의 2가된다.
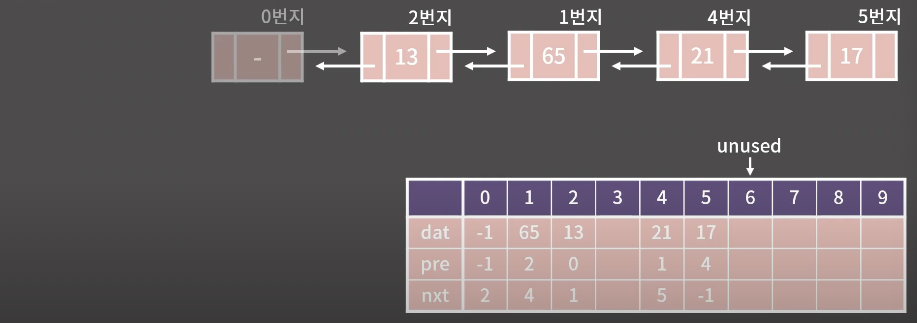
dat = 13
pre = 0
nxt = 1
-나머지는 손으로 다 채워넣어보자
기능 구현
insert(1,70)
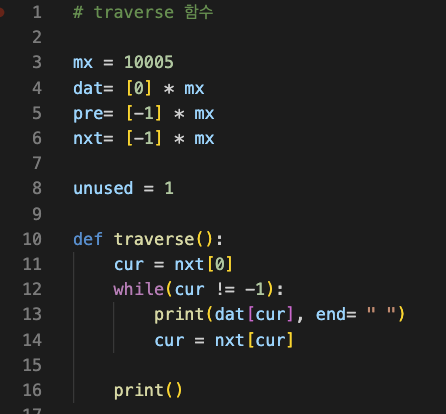
1. traverse 함수
:traverse함수는 연결리스트의 모든원소를 출력
연결리스트에서는 0번지에서 출발해 nxt에 적힌 값을 보고 계속 넘어가면서 dat를 출력하는 방식으로 구현
(배열에서는 dat[0] dat[1] dat[2] …을 출력하면 되겠지만)
반복되다가 17까지 출력하고 cur에 nxt[5] = -1이 담기면 끝에 도달후 종료.
2.insert, erase 함수
두 함수에 공통으로 있는 인자인 addr는 앞에서 말한 각 원소의 주소
→ 즉, 배열 상에서 몇 번지인지를 의미합니다
예를 들어 )
원소 13이 2번지이고 13 뒤에 20을 새로 추가하고 싶은거면 insert(2, 20)을 호출해야 하고,
13을 지우고 싶으면 erase(2)를 호출해야 합니다.
** addr = 2가 의미하는 것이 연결 리스트 상에서 2번째 원소라는 것이 아니라,
해당 **원소의 주소가 2번지**라는 점을 꼭 헷갈리면 안됩니다.2.1 insert 함수
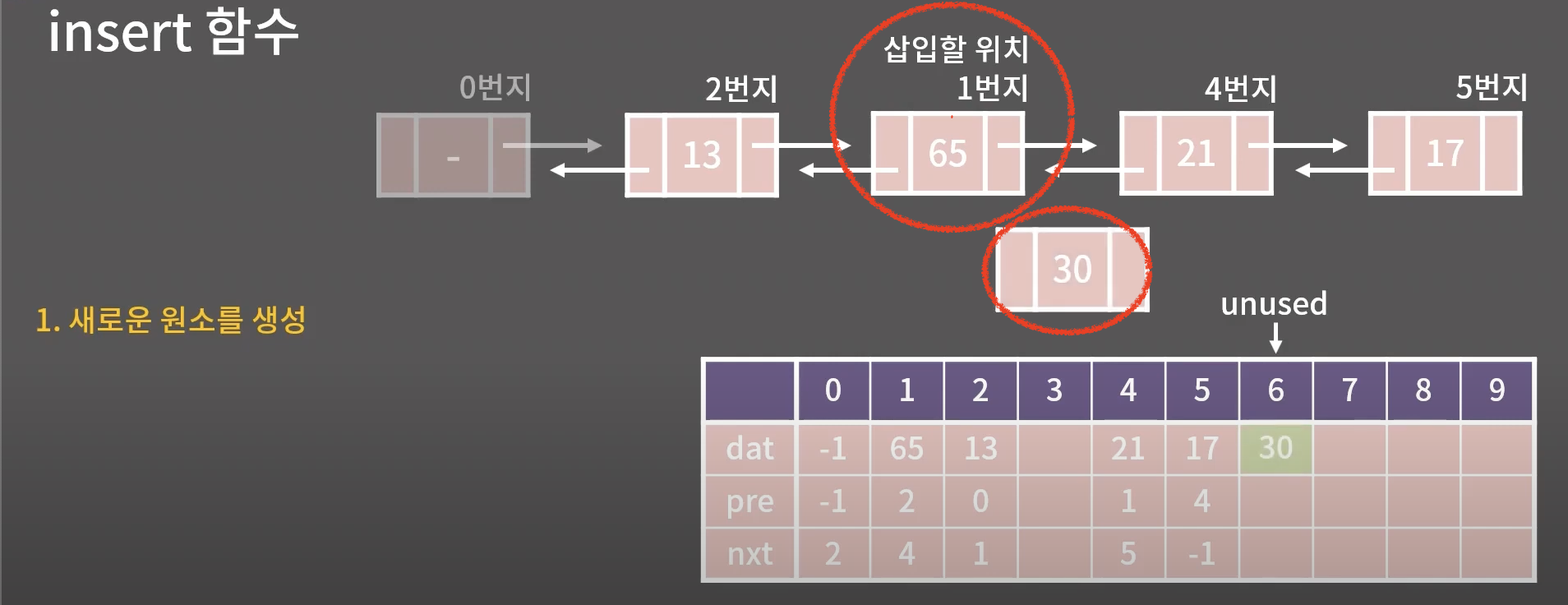
예 ) 65뒤에 35를 추가하고 싶다.
65가 1번지이니 insert(1,30)이 호출된다.
편의를위해 65를 삽입할 위치라고 생각
1. 30이 들어갈 새로운 원소를 만든다.
unused이 가리키는 곳이 바로 새로운 원소가 들어갈 자리
그곳의 dat에 30을 쓰면 관념적으로 원소가 생성한 것과 똑같이 된다.
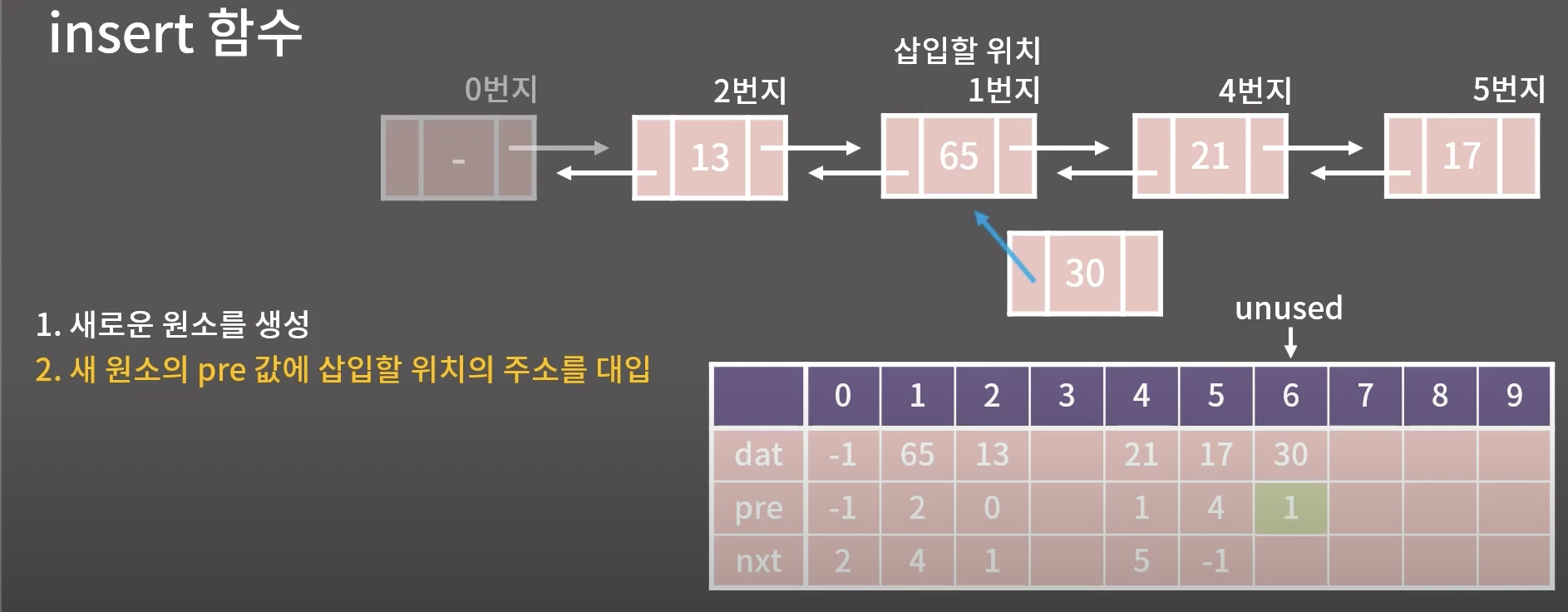
2,3.새 원소의 pre값, nxt 값 대입
pre → 1번지를 대입
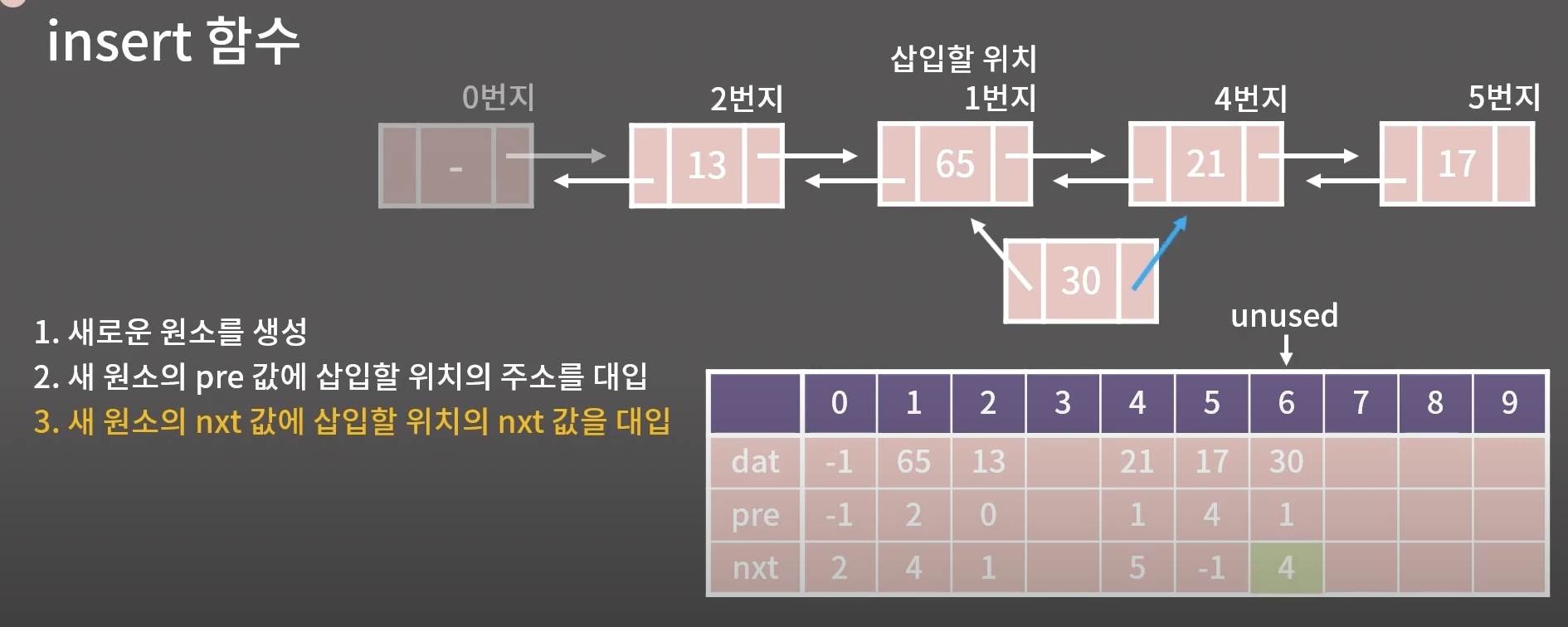
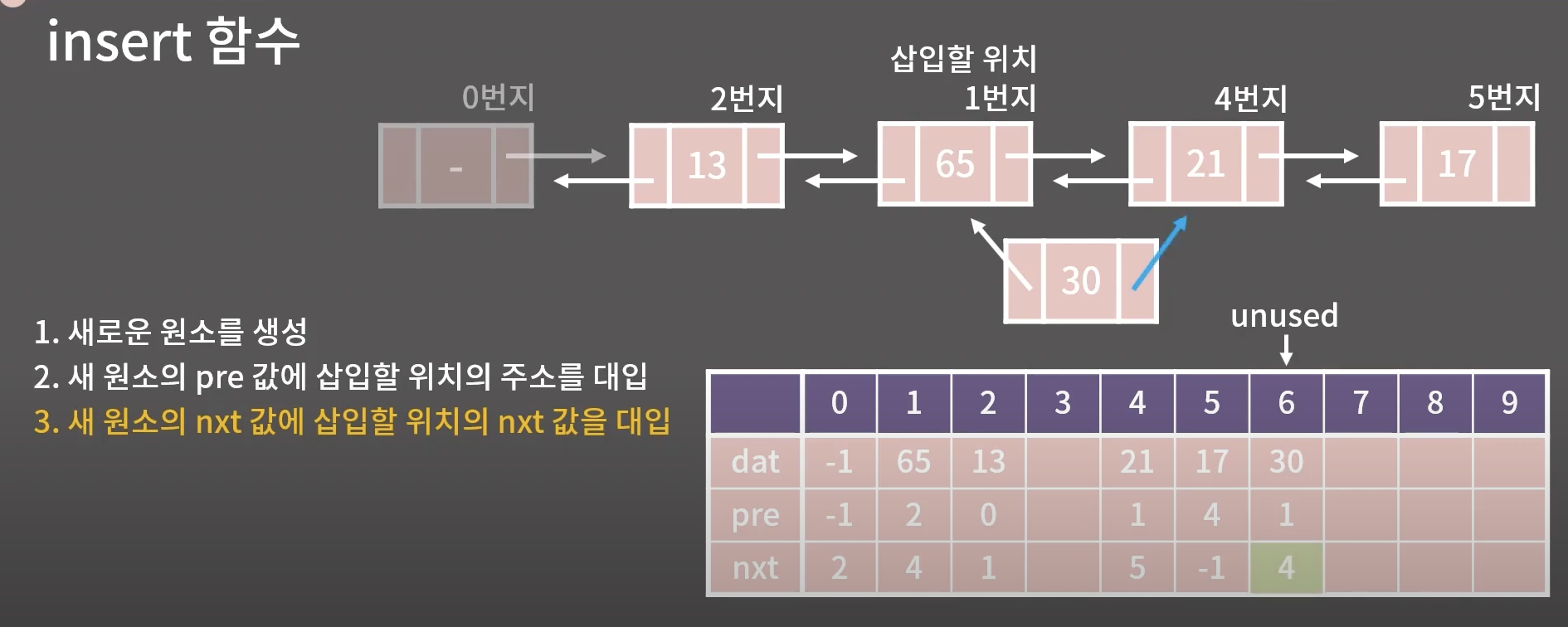
nxt → 4번지 대입
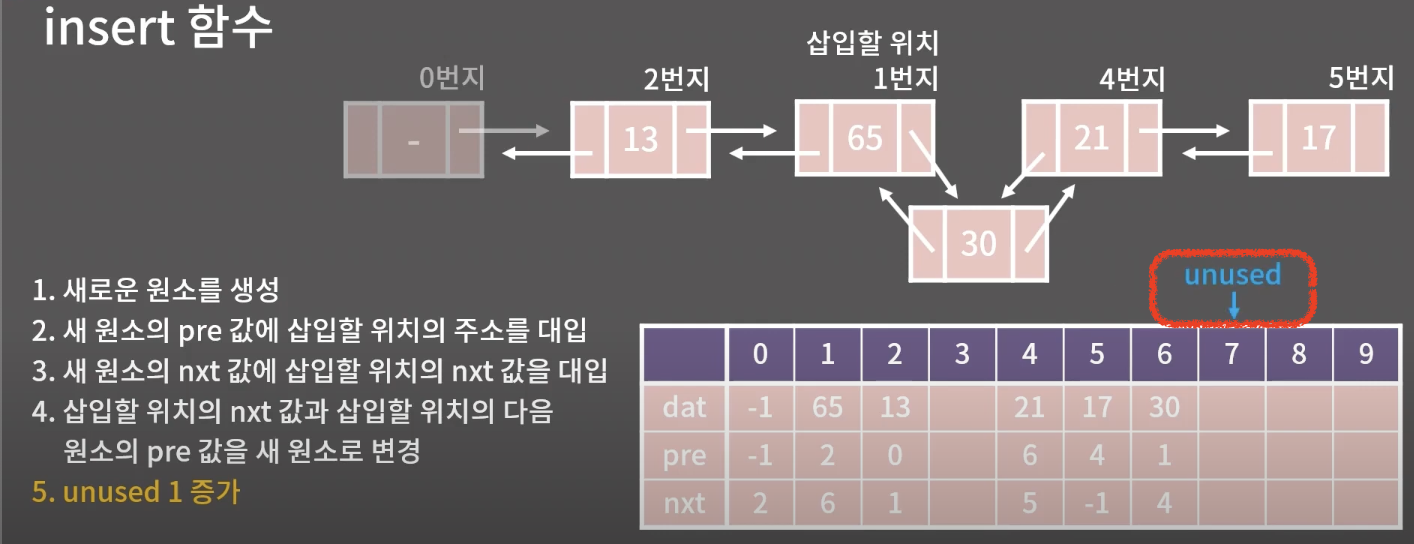
4.삽입할 위치의 nxt값과 삽입할 위치의 다음 원소의 pre 값을 새원소로 변경
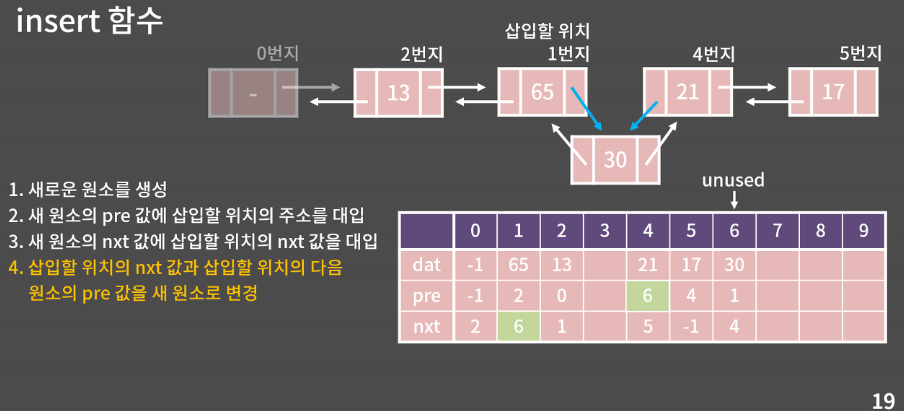
- 입력받을 번지의 addr 을 기준으로 전번지 수정 그러나 -1값이면 중간에 들어오는 값이 아니므로 if문
그게아니라면 넘어가고
전번지의 nxt 다음값을 unused로 변경
5. unused 1 증가
insert 구현)
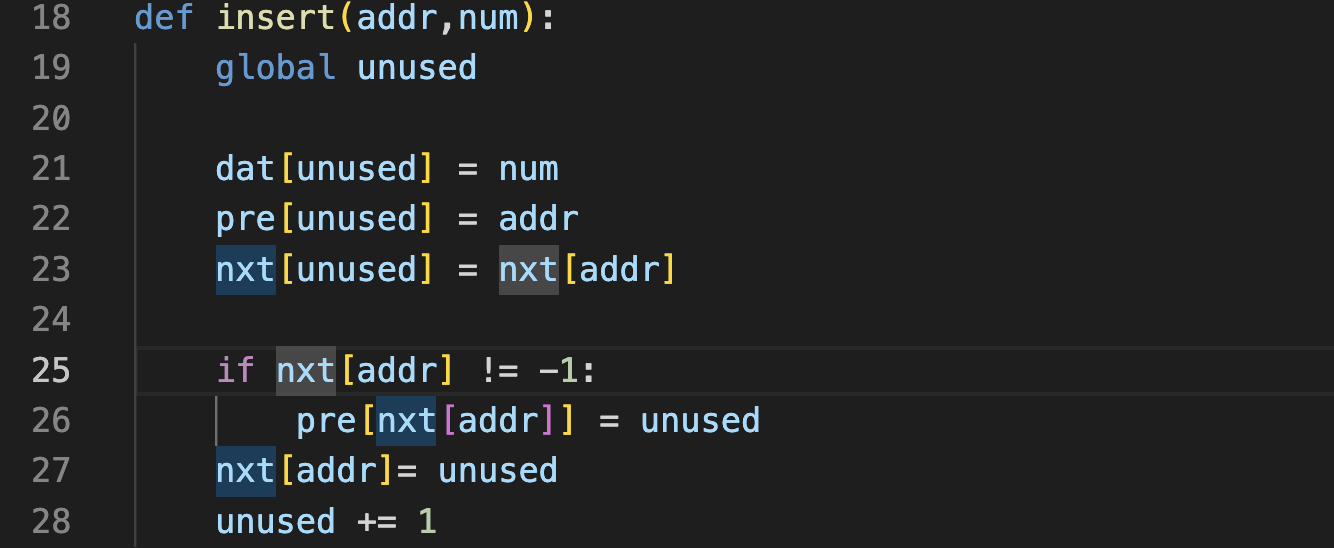
주의 해야할것은 25째 줄이다.
맨 마지막 원소의 뒤에 새 원소를 추가해야하는 상황이라면
“삽입할 위치의 다음 원소”가 존재하지 않는다.
해당 가정문이 없으면 pre[-1]에 접근하게 되어버린다.
따라서, nxt[addr]이 -1이 아닐때만 pre[nxt[addr]]에 unused를 대입하도록 하였다.
(손으로 따라가보자)
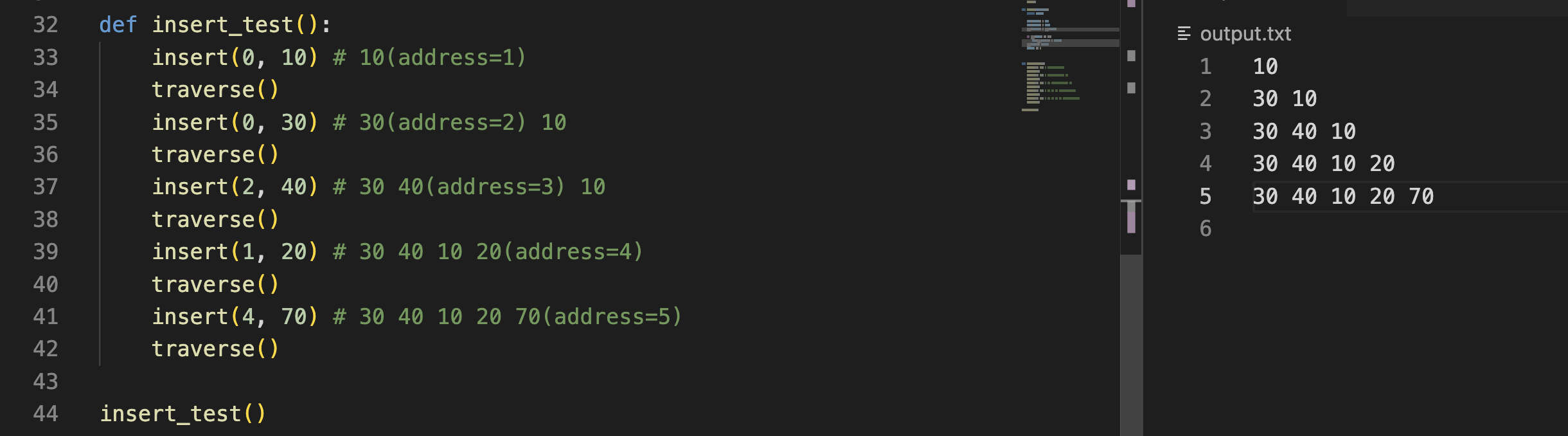
test)
2.2 erase 함수
설명의 편의를 위해 65를 지우고 싶다고 가정한다.
65를 삭제할 위치, 앞의 원소를 이전 위치, 뒤의 원소를 다음 위치
erase(1)
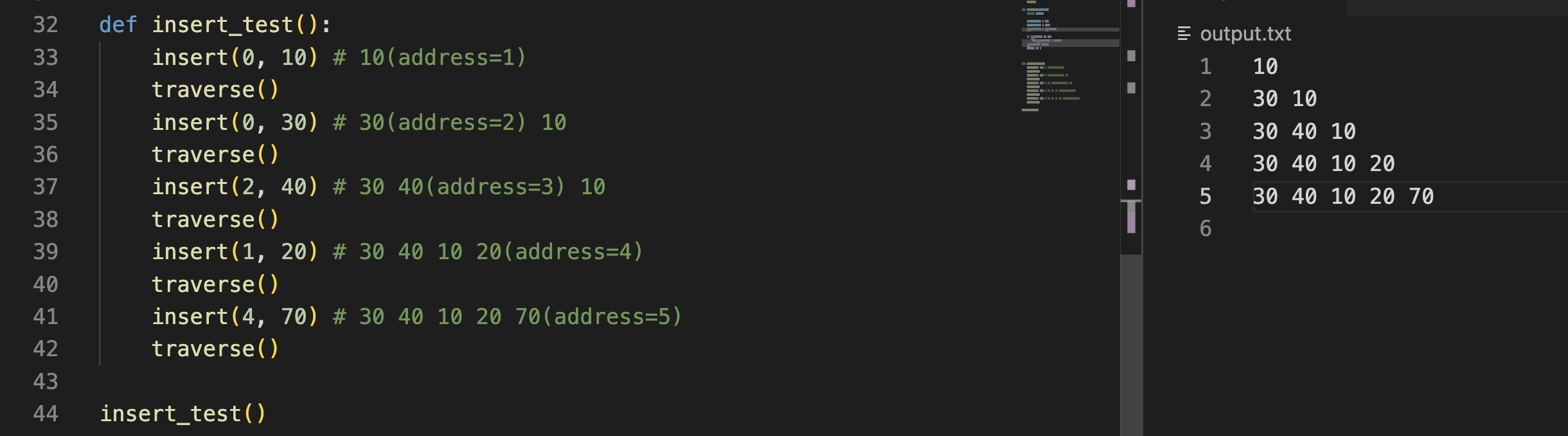
1) 이전 nxt를 삭제할 위치의 nxt로 변경
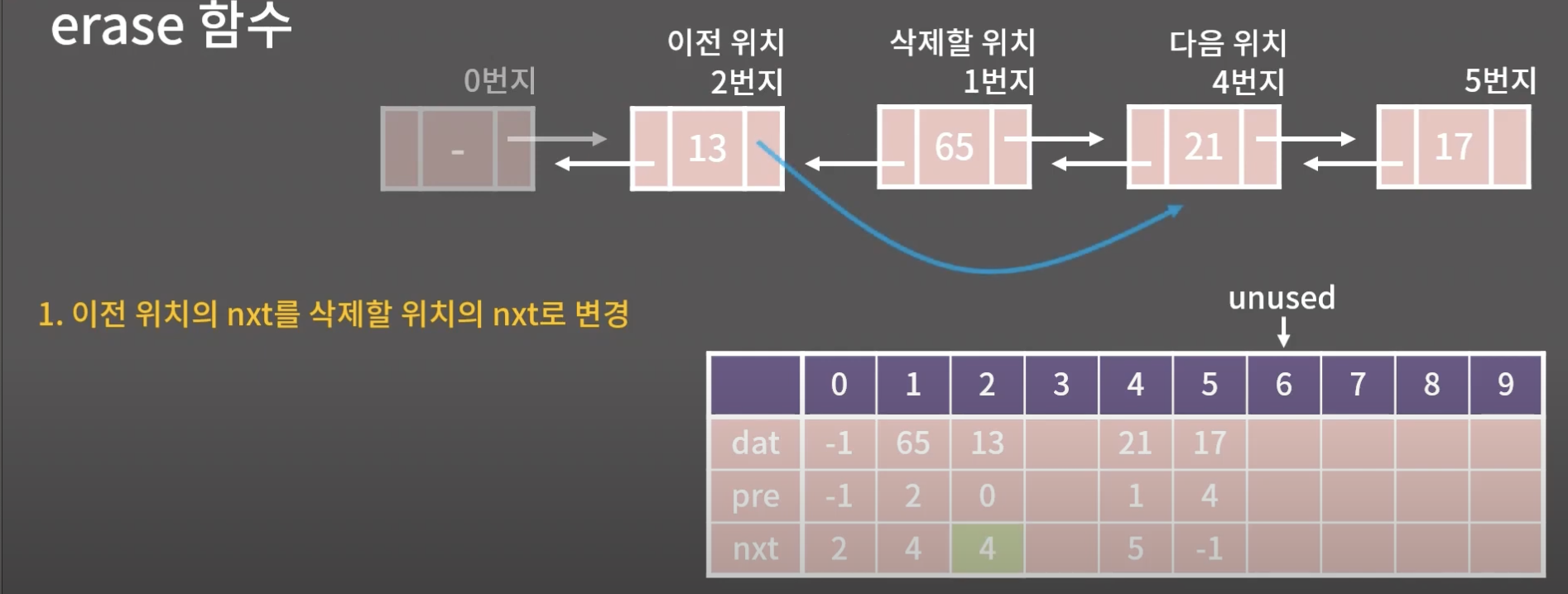
2) 다음 pre를 삭제할 위치의 pre로 변경
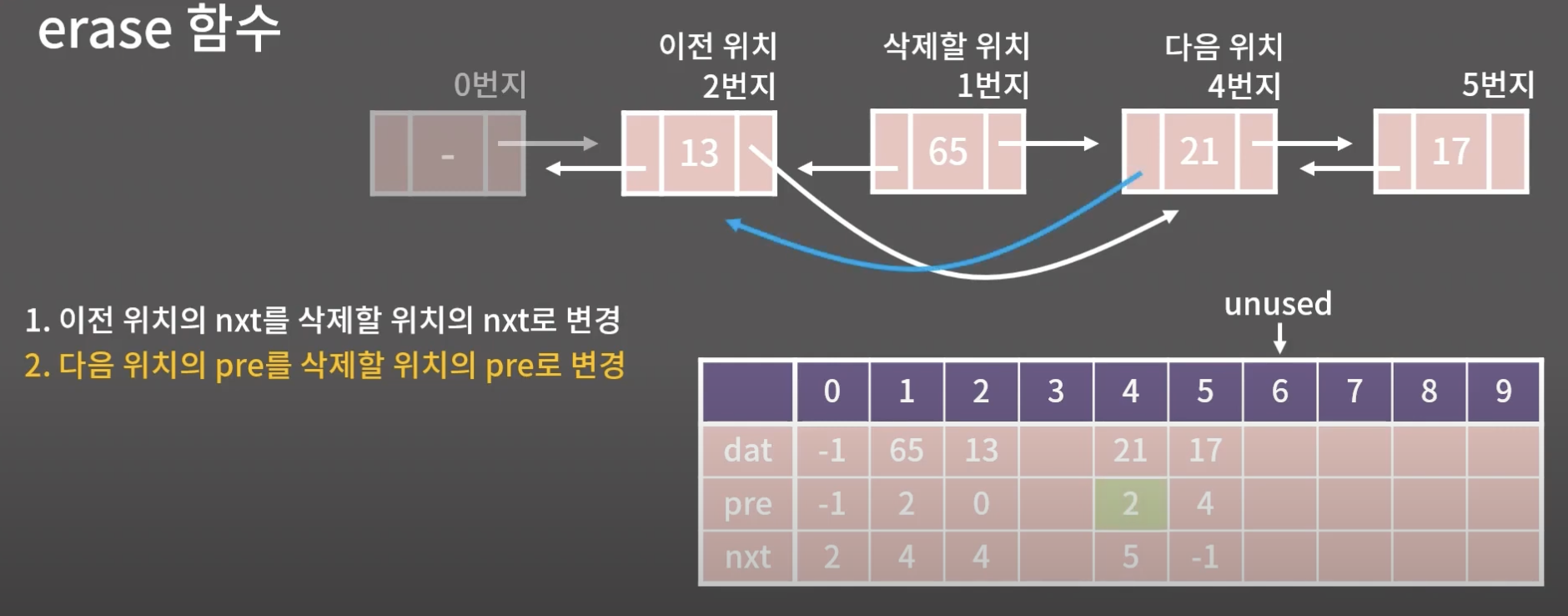
해당 두과정을 거치면 삭제가 끝이난다.
삭제할 위치인 1번지는 데이터를 전혀 건드리지 않는다.
앞으로 이값들은 아무 의미가 없다.
앞으로 그 어떤 nxt나 pre도 1번지를 가리키지 않는다.
해당 상황이 되면 굳이 dat, nxt, pre값을 -1과 같은 다른 값으로 덮을 필요가 없고,
그냥 내버려두면 된다.
따라서 이 야매 연결리스트는 제거된 원소가 프로그램이 종료될 때까지 메모리를 점유하고 있고, 따라서 실무에서는 사용할 수 없는 구현 방식이다.
알고리즘 문제에서는 insert의 횟수가 10만 혹은 100만 번 같이 제한이 있고,
그럴 때에는 그냥 배열을 그 제한에 넉넉히 잡자
구현
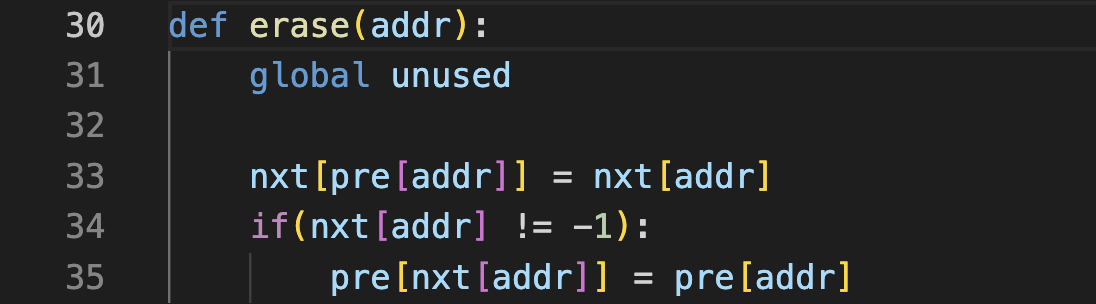
34번째줄에 가정문으로 처리된것을 볼수있다.
pre[addr]이 -1 인지는 체크를 하지 않아도 되는데
nxt[addr]이 -1인지는 체크를 해야하는지 생각해보자
dummy code의 존재로 인해 그 어떤 원소를 지우더라도
pre[addr]은 보장을 받지만
nxt[addr]는 제일 마지막 원소를 지우는 상황에서 값이 -1일수 있기 때문
손코딩
-문제 1)

정답 !
- = 동일한 노드가 나올 때 까지 계속 다음 노드로 가면 됨 공간복잡도 O(1), 시간 복잡도 O(N)
-문제 2)

정답 !
- = 일단 두 시작점 각각에 대해 끝까지 진행시켜서 각각의 길이를 구함 그 후 다시 두 시작점으로 돌아와서 더 긴 쪽을 둘의 차이만큼 앞으로 먼저 이동시켜 놓고 두 시작점이 만날 때 까지 두 시작점을 동시에 한 칸씩 전진시키면 됨. 공간 복잡도 O(1), 시간복잡도 O(A+B)
-문제 3)

정답 !
- Floyd’s cycle-finding aloritm, 공간복잡도 O(1), 시간복잡도 O(N)
한 칸씩 가는 커서와두 칸씩 가는 커서를 동일한 시작점에서 출발시키면 사이클이 있을 경우 두 커서는 반드시 만나게 된다. 만약 사이클이 없으면 커서가 만나지 못하고 연결리스트의 끝에 도달하게 된다.
연결리스트가 코테에서 자주 등장하지는 않지만 안하고 가기에는 그런 자료구조이다.
배열 vs 연결리스트
자료구조- 메모리 구조 - 캐시 친화도
배열 :
1. 메모리에 연속됨
2. ⬆️ 높음 (cache hit 잘 됨)
연결리스트 :
1. 메모리에 불연속
2. ⬇️ 낮음 (cache miss 자주 남)
cache hit rate ?
연속된 메모리 = 캐시 효율 좋음
불연속 메모리 = 캐시 효율 떨어짐 (cache hit rate 낮음)
✅ 캐시는 어떻게 동작하냐면...
CPU는 메모리 접근이 느리니까, 데이터를 가까운 캐시에 미리 가져다 놓고 사용하는데
공간지역성(spartial locality) 개념 사용
어떤 주소에 접근했으면, 그 근처도 곧 접근할 확률이 높다!
그래서 한번에 메모리를 한 덩어리(block)로 캐시에 가져온다
-> 이걸 캐시라인(cache line)
예를 들어 한 캐시 라인이 64바이트면:
어떤 배열의 0번째 요소를 읽는다
→ 그 뒤 1~15번째까지의 요소도 자동으로 캐시에 들어옴따라서 배열은 연속된 메모리에 있기때문에 공간지역성 좋음
연결리스트는 아니여서 cache miss가 많이남.
