
여름방학동안 연구실에서 매주마다 각자 일주일동안 공부한 내용에 대해 발표하는 세미나를 가졌다.
방학동안 공부한 내용에 대한 기록도 할겸 나중에 복습도 할겸 적어보려고 한다.
1차 세미나
오늘은 2023년 7월 5일에 발표한 내용에 대해 정리하려고 한다.
1차 세미나에서는 스탠포드 대학교에서 진행한 cs231n강의를 수강하고,
정리한 내용과 추가로 공부한 내용에 대해 발표를 진행했다.
발표 contents는 다음과 같다.
1. Image classification
2. Image classification algorithm
3. Loss function
4. Optimizer
1. Image classification
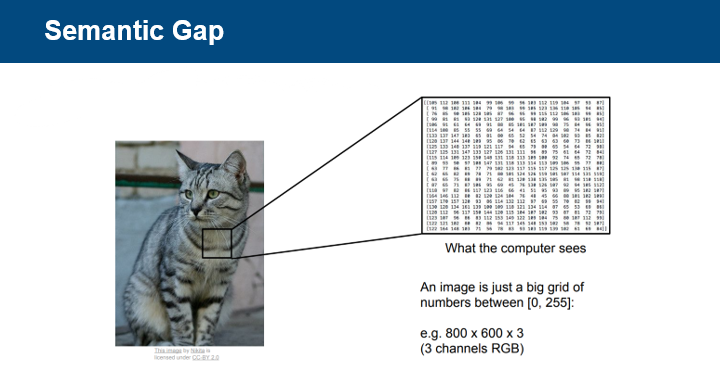
사람은 이미지를 보면, 이미지 속 객체를 바로 인식하지만, 컴퓨터에게 이미지는
0-255사이의 값을 갖는 거대한 숫자 격자일 뿐이다.
이미지 분류 task를 컴퓨터가 수행하기 위해선
이러한 sementic gap(의미적 차이)을 극복하기 위한 방법이 필요하다.

semantic gap을 극복하기 위한 방법으로 Data-Driven Approach를 택했다.
1. 이미지 데이터를 수집
2. 분류를 위한 모델 학습
3. 새로운 이미지를 이용한 분류 평가
2. Image classification algorithm

분류 알고리즘으로 Nearest Neighbor알고리즘을 소개한다.
NN알고리즘의 원리는 Test data와 모든 train data간의 대응되는 픽셀 값을 이용하여
거리를 계산하고 가장 거리가 가까운 train data 이미지의 class를 예측값으로 반환한다.
강의에서는 distance metric으로 L1 distance와 L2 distance를 소개하였다.

NN알고리즘의 한계는 모든 train data와의 거리를 계산해야 하기에 예측시간이 오래걸린다.

왼쪽 그림에서 각각의 점들은 train data를, 색칠된 영역은 예측 바운더리를 의미한다.
녹색 영역에 가운데를 보면, 노란점 하나의 영향을 받아 이상치에 약한 NN알고리즘 한계도 볼 수 있다.
오른쪽 그림은 이미지의 픽셀값의 차이로 이미지를 분류하는 distance metric이
이미지 분류에 좋은 성능을 내지 못한다는 한계 또한 보여준다.
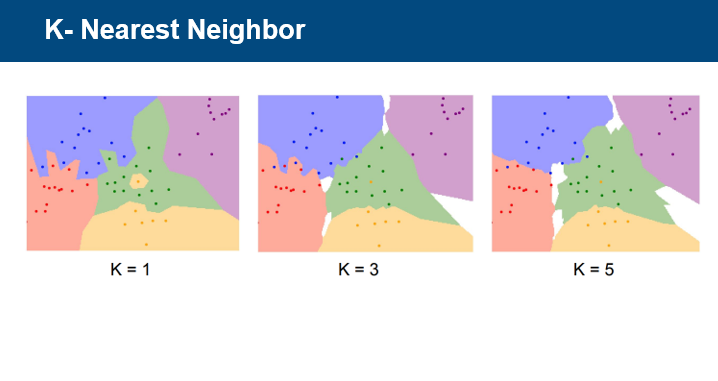
NN알고리즘을 극복하기 위해 k개의 점을 보는 KNN알고리즘에 대해 설명한다.
k의 값에 따라 예측 바운더리가 변하는 것을 확인할 수 있고,
k=3을 보며, 이상치에 강인하다는 특징을 확인할 수 있다.
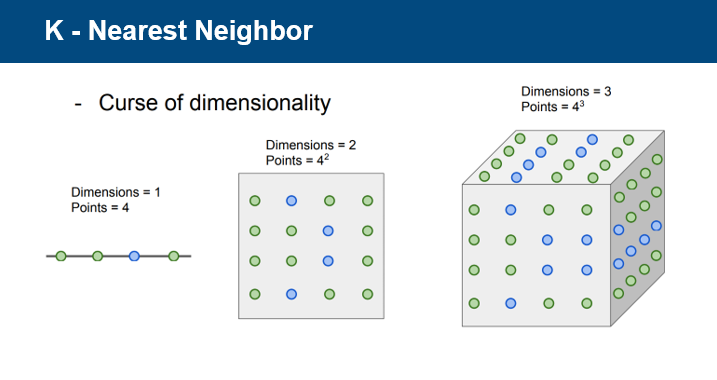
그러나 차원이 지수단위로 증가하여 차원을 밀도있게 채우는 것이 힘들다는 한계가 존재한다.
그래서 knn알고리즘 논문 유사도 검사와 같은 task에 많이 활용된다.
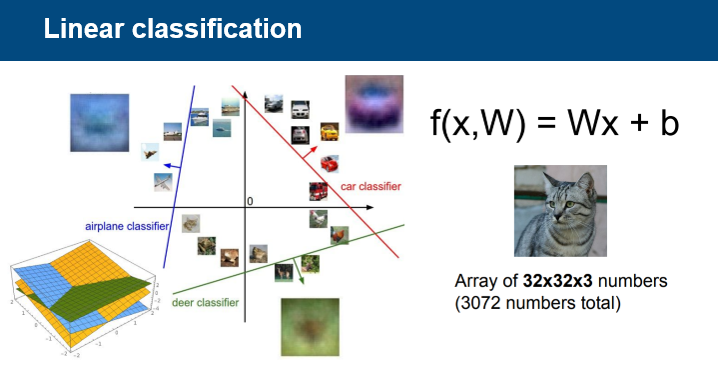
다음은 Linear 알고리즘에 대해 설명한다.
Linear 알고리즘은 데이터를 선형 모델을 이용하여 섹션을 나눠 분류 작업을 수행한다.
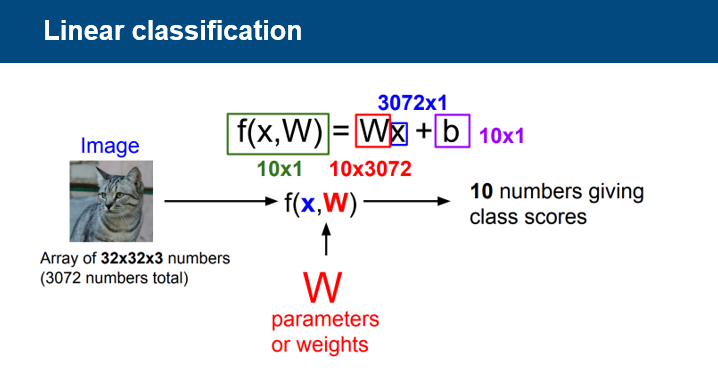
이미지 픽셀값을 열벡터로 전환하고, 가중치 w와의 내적 계산을 통하여 class갯수만큼의 값을 도출한다.
도출된 값들 중에서 제일 높은 값을 갖는 class가 예측 class이다.
3. Loss function

분류기가 잘 작동하는지, 성능이 최선인지 확인하는데 필요한 Loss함수에 대해 설명한다.
Loss값은 해당 분류기가 얼마나 성능이 나쁜지 알려주는 것으로
0에 가까울수록 분류 성능이 좋은것을 의미한다.
Loss값은 가중치 w에 대한 함수인 Loss함수에 의해 정해진다.

Loss함수로 다중분류 svm에 대해 설명한다.
다중분류 svm은 정답 카테고리를 제외한 나머지 카테고리에 대한 점수를 비교하는 원리이다.
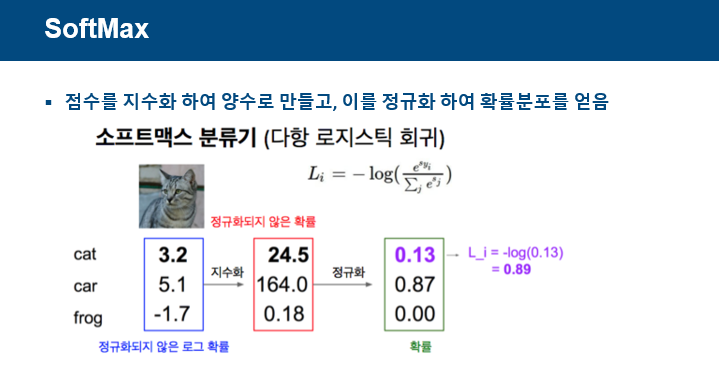
Loss함수로 softmax에 대해 설명한다.
softmax는 점수를 지수화하여 양수로 만들고, 이를 정규화하여 확률분포를 얻는다.
이를 통해 각 class에 대한 확률값이 나오게 되고, 확률값에 log를 취해 Loss값을 얻는다.
4. Optimizer

이미지 분류의 목표는 성능이 좋은 모델을 만드는 것이고,
성능이 좋은 모델은 Loss값이 제일 작은 모델을 의미한다.
Optimizer는 Loss값이 제일 작은 값을 도출하는 가중치 W를 찾기 위한 방법을 의미한다.
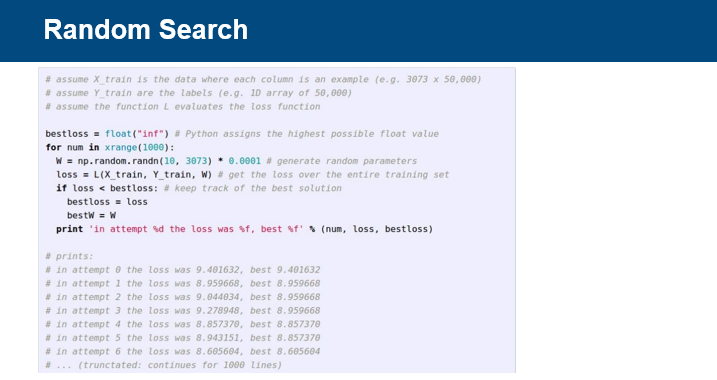
다차원 함수인 Loss함수의 최저점을 찾는 방법은 다양하다.
모든 값을 계산하여 최저인 지점을 찾는 방법이 있다.
그러나 이 알고리즘은 시간이 매우 오래걸린다는 단점이 있다.

시간을 단축하기 위해 경사를 이용한다.
경사하강법이란 미분을 이용하여 임의값에서의 손실함수의 gradient를 계산하고,
함수가 감소하는 방향을 찾아, 해당 방향으로 방향성을 잡고, 최저점을 찾아가는 방법이다.

SGD방법은 모든 샘플의 gradient를 계산하는 것이 아닌 한 개의 샘플을 무작위로 뽑아
해당 샘플의 gradient를 계산하여 시간을 단축시키는 방법이다.

그러나 SGD의 한계로 Local minimum에 빠져 학습이 지연되는 문제,
saddle point에 빠져 학습이 지연되는 문제가 발생하는 한계가 존재한다.
이런 한계를 극복하기 위해 다양한 Optimizer들이 존재한다.

mometum이란 가중치를 업데이트 할 때 이전의 움직여왔던 방향도 고려하여 반영하는 것으로,
이전 움직였던 방향에서 속도를 가져와 local minimum에 빠지지 않고, 탈출하는 원리이다.
알파 값은 속도 v의 반영률을 의미하며, 그래프를 보면 점점 속도가 붙어서 가중치가 큰 폭으로
업데이트가 되고, 이를 통해 local minimum에 탈출하는 것을 확인할 수 있다.
그러나 global minimum또한 지나쳐서 오히려 학습이 지연되는 문제가 발생할 수 있다.
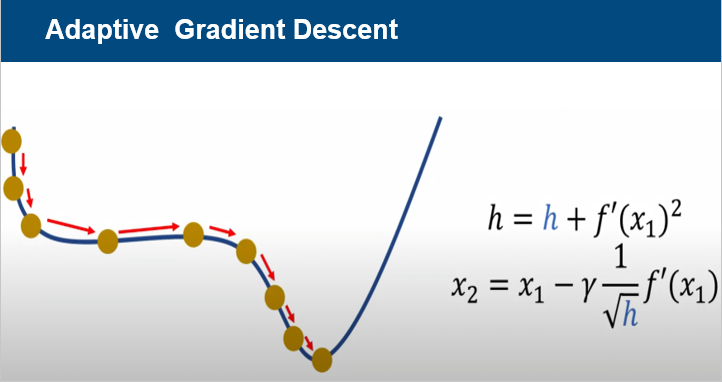
Adapitve gradient descent는 가중치를 업데이트 할 때 gradient들의 history를 반영하여
학습률에 변화를 주자는 원리이다.
gradient의 history가 작은 곳에서는 학습률을 크게 만들어 빨리 지나가고,
gradient의 history가 큰 곳에서는 학습률을 작게 만들어
global minimum을 지나치는 문제를 해결하는 방법이다.
그러나 학습이 오래 진행되면 gradient history가 계속해서 커져서 학습률이 매우 작아져
학습이 지연되는 문제가 발생할 수 있다.
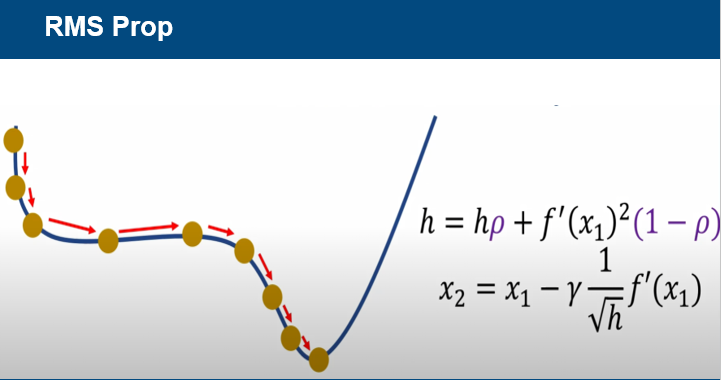
RMS Prop은 gradient의 history의 반영률을 조절하여 가중치를 업데이트하자는 원리이다.
rho값을 이용하여 H값이 계속해서 커지는 것을 방지하고, 과거의 기울기들은 조금 반영하고,
최근 기울기를 많이 반영해서 학습률이 작아져 발생하는 학습 지연을 극복할 수 있다.
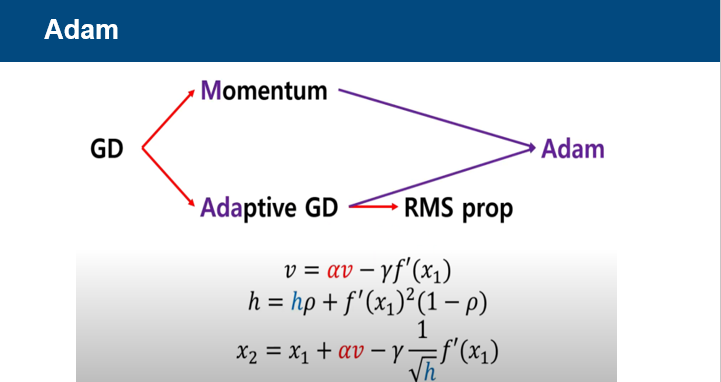
Adam은 이전 gradient의 방향을 고려하는 속도 v도 이용하고,
gradient의 history도 고려하는 h도 이용하여 가중치를 업데이트하는 원리이다.
요즘에는 Optimizer를 선택함에 있어 Adam을 기본값을 사용하는 추세라고 한다.
참고자료 출처
cs231n - https://www.youtube.com/watch?v=vT1JzLTH4G4&list=PLC1qU-LWwrF64f4QKQT-Vg5Wr4qEE1Zxk
optimizer - https://www.youtube.com/watch?v=sbyh5RCGB9k
마무리
세미나 리뷰
지도 교수님
방학동안 다양한 활동을 계획한것과 cs231n을 수강하는 것은 매우 좋은 선택
발표를 준비할 때, 대본을 준비하는 것은 당연하지만,
발표를 진행할 때는 대본과 소통하는 것이 아닌 청강하는 사람들과 소통을 해야한다.
Loss함수에 대한 내용은 지도교수님 강의를 수강하고 내용을 보충하면 좋을것 같다.발표자
인생 처음으로 했던 세미나여서 많이 걱정했다.
주제 선정부터 발표 내용 정리, 발표 준비 과정 모두 쉽지 않았다.
발표를 진행하면서 발표 자세와 발표 내용, 청강하는 사람들을 이해시키기 위한
발표 자료 준비 등의 피드백을 받아보니 왜 세미나가 중요한지를 알게 되었다.
세미나 준비를 하며 다른 사람들을 이해시키기 위해 공부를 하다보니
사소한 부분을 넘어가지 않고, 분명하게 이해하고 넘어가려는 공부가 진행되어 만족스러웠다.
