Not on Embedded Device, Just do it on Docker container!
이번 글은 임베디드 디바이스의 환경을 Docker Container로 대체해서 사용하는 이야기에요.
Embedded Device에서 직접 작업을 하다보면 답답한 부분이 여러 곳에서 느껴집니다. 마우스 커서가 중간에 걸리기도 하고 딥러닝 inference를 진행할 때 너무 느려서 답답할 때가 많습니다. 그래서 생각을 해봤었어요. 임베디드 디바이스에서 작업하지 말고 차라리 더 빠른 서버에서 작업을 하고 코드만 옮기면 되지 않을까? 라는 거에요.
그래서 여기서는 Jetson Series의 디바이스를 Container로 만드는 Tutorial을 보여줄 거에요.
Requirement
- Linux GPU Machine(RTX TITAN, GTX도 가능)
- Ubuntu 18.04
- Docker 19.03.14
- Docker Compose 2.3
Docker compose 의 사용법은 숙지를 하셨으리라 가정할게요. 만약에 모르신다면 괜찮아요. 컨테이너를 만들 때 옵션 하나하나 다 정성껏 넣어주시면 되니까요.
Docker Compose 를 사용하신다면 먼저 폴더구조가
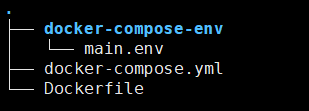
이렇게 보일거에요. 폴더구조를 위에 그림처럼 만들어주세요.
먼저 docker-compose-env 폴더에 들어있는 main.env 내용부터 보여드릴게요.
#main.env
NVIDIA_VISIBLE_DEVICES=all
이는 NVIDIA GPU를 모두 사용하겠다는 뜻입니다.
그리고 docker-compose.yml의 내용이에요.
#docker-compose.yml
version: '2.3'
services:
main:
container_name: tensorrt_cp
build:
context: ./
dockerfile: Dockerfile
runtime: nvidia
restart: always
env_file:
- "docker-compose-env/main.env"
volumes:
- /media/mmlab/hdd:/hdd
expose:
- "8000"
- "22"
ports:
- "22712:8000"
- "22912:22"
- "22412:6006"
mem_limit: '6144M'
memswap_limit: '6144M'
ipc: host
stdin_open: true
tty: true해당 내용 중 참고하실 부분은 mem_limit와 memswap_limit 입니다. 사용하시는 Jetson Series Device에 맞게끔 설정해주시면 됩니다. 더 빠른 테스팅을 원하시는 분이 있다면 알아서 더 크게 메모리를 사용하게 높은 값을 주시면 되겠죠? 그리고 open 할 port는 직접 결정해서 설정해주세요.
다음 내용은 Dockerfile 입니다.
#Dockerfile
FROM nvcr.io/nvidia/tensorrt:20.08-py3
#ARG DEBIAN_FRONTEND=noninteractive
RUN apt-get update \
&& apt-get -y install python3.6 \
python3-pip \
python3-dev \
git vim openssh-server
RUN DEBIAN_FRONTEND="noninteractive" apt-get -y install tzdata
#RUN pip install --upgrade pip
#RUN pip install setuptools
RUN sed -i 's/#PermitRootLogin prohibit-password/PermitRootLogin yes #prohibit-password/' /etc/ssh/sshd_config
WORKDIR /workspace
ADD . .
ENV PYTHONPATH $PYTHONPATH:/workspace
RUN chmod -R a+w /workspace여기서 가장 중요한 것은 어떤 OS의 image를 가져올지 인데요. 저는 NVIDIA에서 제공하는 OS중 TensorRT 7 버전을 사용하는 이미지를 가져오기로 결정했어요.
https://docs.nvidia.com/deeplearning/tensorrt/container-release-notes/rel_20-08.html
바로 위에 링크에 가시면 NVIDIA에서 릴리즈 별로 제공되는 이미지 파일을 보고 판단 할 수 있습니다.
그럼 이제 컨테이너를 만들어보자구요.
여기 폴더로 들어가주시고
sudo docker-compose up -d이렇게 명령어를 입력 해주시면, docker-compose.yml에서 설정한 container_name: tensorrt 으로 tensorrt 컨테이너가 만들어집니다.
그럼 이제 컨테이너로 들어가서 필요한 Repo를 받아줄게요.
컨테이너로 들어가는 명령어는 다음과 같습니다.
docker exec -it tensorrt /bin/bash이 명령을 실행하셨다면

이런 화면을 보게 될거에요. 이제 사용하는 Repo에서 필요한 몇가지 추가 라이브러리를 설치해주면 됩니다.
저 같은 경우는 딥러닝 네트워크 모델을 경량화하는 Repository를 사용합니다. 다음 과정은 예시입니다.
git clone https://github.com/jkjung-avt/tensorrt_demos.git위의 Repo를 돌리기 위한 방법을 간단하게 알려드릴게요. 전 여기에서 yolo계열을 사용하기에 그 쪽 설명만 하도록 하겠습니다.
$ cd tensorrt_demos/ssd
$ ./install_pycuda.sh이렇게 해주시면
** Install requirements
./install_pycuda.sh: line 17: sudo: command not found이런 에러를 볼 수 있어요. 이는 이미 root 권한의 계정이기 때문인데요. install_pycuda.sh 로 들어가서 sudo를 모두 없애주세요. 그리고 다시
./install_pycuda.sh이 명령어를 입력해주세요. 그러면 설치가 될 것입니다. 그리고 그 다음 명령어를 입력해줄게요.
pip3 install onnx==1.4.1이렇게 입력하면
Traceback (most recent call last):
File "/usr/local/bin/pip3", line 5, in <module>
from pip._internal.cli.main import main
ImportError: No module named pip._internal.cli.main이런 에러를 볼 수 있어요. pip이 설치가 안되어 있어서 그래요.
$ curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py
$ python3 get-pip.py --force-reinstall이 명령어를 사용해서 pip3를 설치해주세요. 그리고 다시
$ pip3 install onnx==1.4.1입력해주시면 설치가 될 거에요. 그러면 다음 단계로 가볼게요.이렇게 명령어를 입력해주세요.
$ /workspace/tensorrt_demos/plugins
$ makemake 이후 아래와 같은 메세지를 보신다면 정상입니다.
nvcc -ccbin g++ -I"/usr/local/cuda/include" -I"/usr/local/TensorRT-7.1.3.4/include" -I"/usr/local/include" -I"plugin" -Xcompiler -fPIC -c -o yolo_layer.o yolo_layer.cu
g++ -shared -o libyolo_layer.so yolo_layer.o -L"/usr/local/cuda/lib64" -L"/usr/local/TensorRT-7.1.3.4/lib" -L"/usr/local/lib" -Wl,--start-group -lnvinfer -lnvparsers -lnvinfer_plugin -lcudnn -lcublas -lcudart_static -lnvToolsExt -lcudart -lrt -ldl -lpthread -Wl,--end-group이제 그러면 실제로 yolo 모델을 변환해보는 작업을 할게요.
$ cd /workspace/tensorrt_demos/yolo
$ ./download_yolo.sh #이 코드는 기존의 pre trained된 모델을 받는 겁니다.
$ python3 yolo_to_onnx.py -m yolov4-416
$ python3 onnx_to_tensorrt.py -m yolov4-416기존 Jetson Nano에서는 Onnx 에서 TensorRT로 바꾸는데 약 40분 정도가 소요됩니다. 하지만 좋은 머신(컴퓨터)에서 이렇게 작업을 하면 변환이 약 10분 정도안으로 끝나게 됩니다. 정말로 모델이 잘 변환 되었는지 테스트를 해봐야겠죠?
테스트는 동영상을 inference하여 BBOX가 그려진 찍힌 영상으로 저장하는 프로그램을 사용하겠습니다. 해당 프로그램도 https://github.com/jkjung-avt/tensorrt_demos 여기에 있습니다.
$ cd /workspace/tensorrt_demos/
$ python3 trt_yolo_cv.py -v ./10_360p.mp4 -o ./result.mp4 -m yolov4-416-v 옵션은 입력영상까지의 경로이고 -o 옵션은 결과물의 파일까지의 경로부터 이름입니다. 이렇게 입력해 주시면
ModuleNotFoundError: No module named 'cv2' 라는 에러를 볼 수 있을거에요. 해결방법은 아래의 명령어를 입력해주세요.
pip3 install opencv-python설치가 끝나고 다시 실행해주시면 이번엔
ImportError: libGL.so.1: cannot open shared object file: No such file or directory이 에러를 볼 수 있을거에요. 해결방법은 아래의 명령어를 입력하여 주세요.
$ apt-get update
$ apt-get install ffmpeg libsm6 libxext6 -y
$ apt-get install libgl1-mesa-glx
$ apt-get install -y libgl1-mesa-dev이렇게 하면 모든 문제가 해결이 끝났습니다. 테스트 하실 영상을 준비해주시고 다시 아래의 명령어를 입력해주세요.
$ python3 trt_yolo_cv.py -v ./10_360p.mp4 -o ./result.mp4 -m yolov4-416그러면 결과 영상을 Filezilla와 같은 FTP 프로그램을 사용하여 꺼내서 모니터가 있는 환경에서 확인 할 수 있습니다. Jetson Nano의 경우 4FPS가 나왔는데 RTX TITAN에서는 135FPS가 나오는 것을 확인 할 수 있습니다. 훨씬 빠르죠?
Just Do it on Docker, not on Embedded Device!
