네이버 영화 사이트 이용
https://movie.naver.com/movie/search/result.naver?query=%EB%B6%80%EC%82%B0%ED%96%89§ion=all&ie=utf8
import request #페이지 가져오는 라이브러리
from bs4 import BeautifulSoup #html에서 원하는 정보만 가져오는 라이브러리 (파싱)1. 페이지 가져오기
1. 페이지 가져오기
page = requests.get(url)
2. 파싱(그냥 가져오면 하나의 string으로 가져와지기때문에 html.parser로 파싱해줘야함
soup = BeautifulSoup(page.content, 'html.parser')
3. 페이지 가져오는거 성공했다는거 알고싶으면
print(page.status_code) --> 200
or
print(page) --> <Response [200]>
#200이 나왔다는건 성공했다는 뜻2. BeautifulSoup을 이용해 내가 원하는 정보에 접근하기
- find, find_all VS select_one, select
둘 다 내가 원하는 정보에 접근하는 것이지만 방식이 다르다. 둘 중 select가 더 편하다.
- find, select_one VS find_all, select
find와 select_one은 가장 먼저 나오는 정보만을 가져오는 것이고,
find_all과 select는 해당하는 모든 정보를 가져 오는 것 - 참고: https://desarraigado.tistory.com/14
* soup은 1번에서 해당 페이지의 html정보 가져온 것
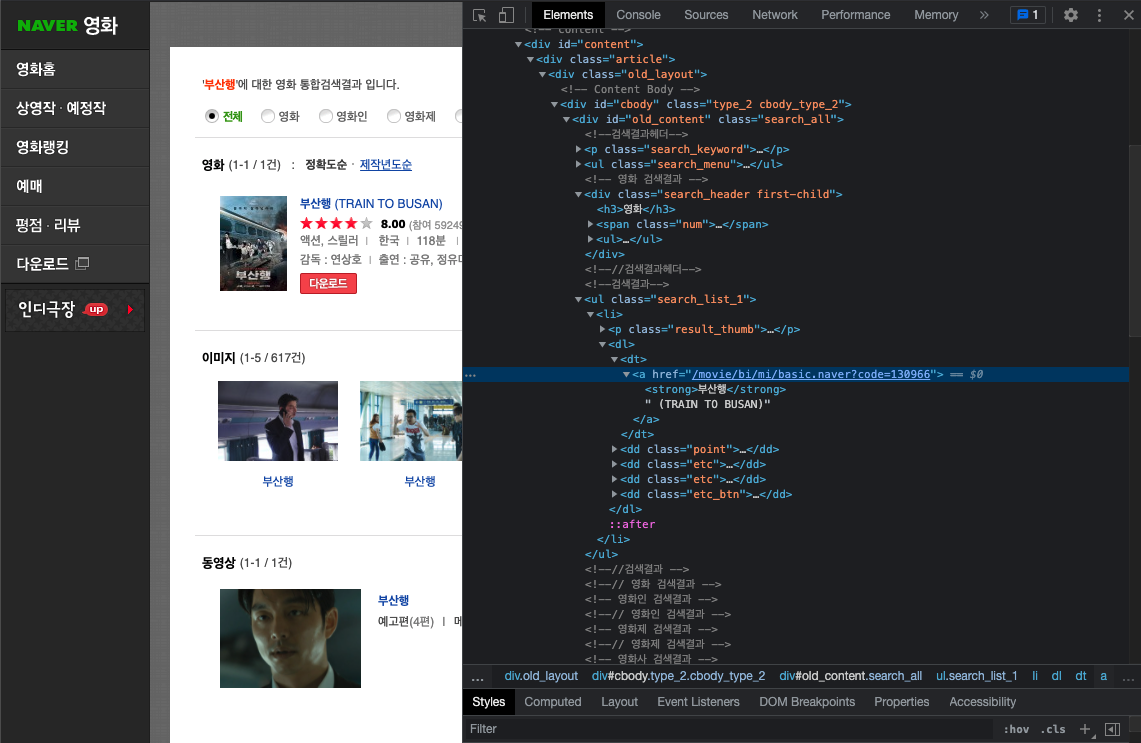
2.1 dt 태그 내의 a태그에 접근하고자 한다.
- find, find_all VS select_one, select
1. find를 이용할 경우
soup.find('dt').find('a')
#우선 dt태그에 접근한 후 a태그에 다시 접근함
2.select_one을 이용할 경우
soup.select_one('dt > a')
#한번에 a태그로 들어감
둘 다 같은 결과 : <a href="/movie/bi/mi/basic.naver?code=130966"><strong>부산행</strong> (TRAIN TO BUSAN)</a>
** a태그는 dt태그안에서만 사용하는게 아니라 다른 곳에서도 사용하고 있다.
** 따라서, 처음부터 a태그로 들어가면 나한테 필요없는 정보들이 많이 들어가기 때문에 정확하게 위치를 지정해주는 것이 좋다.
- find, select_one VS find_all, select
1. find, select_one을 이용할 경우
#해당 페이지에 존재하는 dt>a태그 중 가장 상위 값 가져옴
#결과는 위와 같다
--------------------------------------
--------------------------------------
2. find_all또는 select를 사용할 경우
#해당 페이지에 존재하는 모든 dt태그를 가져온다.
* find_all
dts = soup.find_all('dt')
#dt태그에 해당하는 모든 값을 가져온다.
for i in dts:
i.find('a')
#a태그에 해당하는 모든 값을 가져온다.
결과:
<a href="/movie/bi/mi/basic.naver?code=130966"><strong>부산행</strong> (TRAIN TO BUSAN)</a>
<a href="/movie/bi/mi/media.naver?code=130966"><strong>부산행</strong></a>
결과값의 타입:
<class 'bs4.element.Tag'>
<class 'bs4.element.Tag'>
--------------------------------------
*select
soup.select('dt>a')
결과:
[<a href="/movie/bi/mi/basic.naver?code=130966"><strong>부산행</strong> (TRAIN TO BUSAN)</a>,
<a href="/movie/bi/mi/media.naver?code=130966"><strong>부산행</strong></a>]
결과값의 타입:
<class 'bs4.element.ResultSet'>- 결과값 타입들...
- 참고: https://sondho.tistory.com/48
1. find_all, select:
<class 'bs4.element.ResultSet'>
2. find:
<class 'bs4.element.Tag'>
3. for i in find_all or select:
<class 'bs4.element.Tag'>
# i의 타입
1번 타입은 list처럼 사용할 수 있다.
2.2 태그 내 정보를 가져오고자 한다.
* select_one or select를 사용할 때
1. select_one
soup.select_one('dt>a')['href']
결과: /movie/bi/mi/basic.naver?code=130966
결과값 타입: str
2. select #리스트처럼 사용가능
soup.select('dt>a')[0]['href']
결과:
/movie/bi/mi/basic.naver?code=130966
결과값 타입: str* find or find_all
1. find
soup.find('dt').find('a')['href']
2. find_all
dts = soup_title.find_all('dt')
for i in dts:
print(i.find('a')['href'])
결과:
/movie/bi/mi/basic.naver?code=130966
/movie/bi/mi/media.naver?code=130966
결과값 타입:
str
str주의
- find_all이나 select는 여러개의 값을 가져오는 것이기 때문에 무작정 사용하면 에러가 뜨기 쉽다.
- find_all의 경우에는 for문을 이용해 결과값들에 접근하는 것이 좋고,
select의 경우에는 for문을 이용하거나 list 속성을 이용해 결과값들에 접근하는 것이 좋다....? 그런가...? 아직 select는 많이 이용해보지 못해 모르겠다.
2.3 태그 벗겨서 text가져오기
soup.select_one().text
결과값 타입: str- 위에서 말했듯이, find_all이나 select를 이용할 경우 for문을 이용해 각각의 값들에 접근해야한다.
