ref : https://www.youtube.com/watch?v=704qQs6KoUk&list=PLgXGHBqgT2TundZ81MAVHPzeYOTeII69j&index=5
목차
- 배달의민족 주문 시스템
- 성장하는 배민 주문 시스템
- 성장통
- 진화
- 요약
배달의민족 주문 시스템
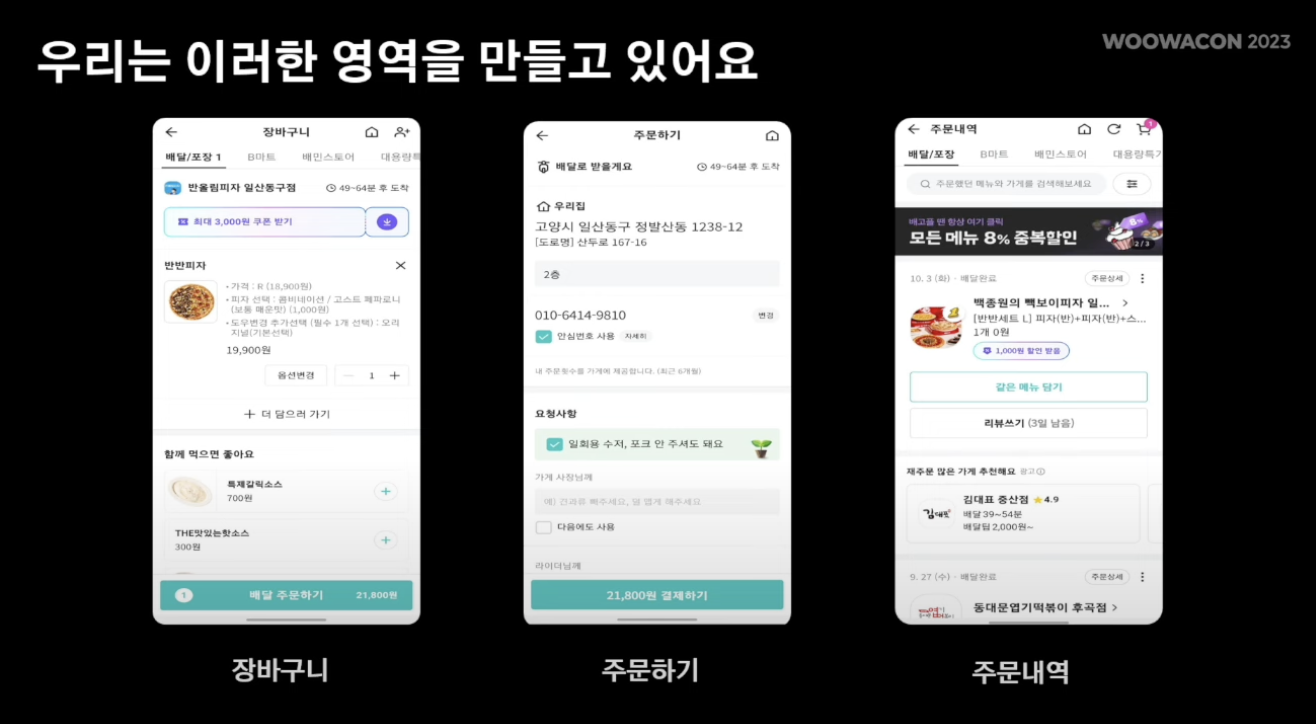
- 보는 화면과 같이 음식을 담는 장바구니, 음식 주문을 하는 주문 화면, 주문 내역에 대해 확인하는 주문 내역 화면이 존재
- 이러한 주문에 대한 로직을 해당 백엔드 팀에서 개발
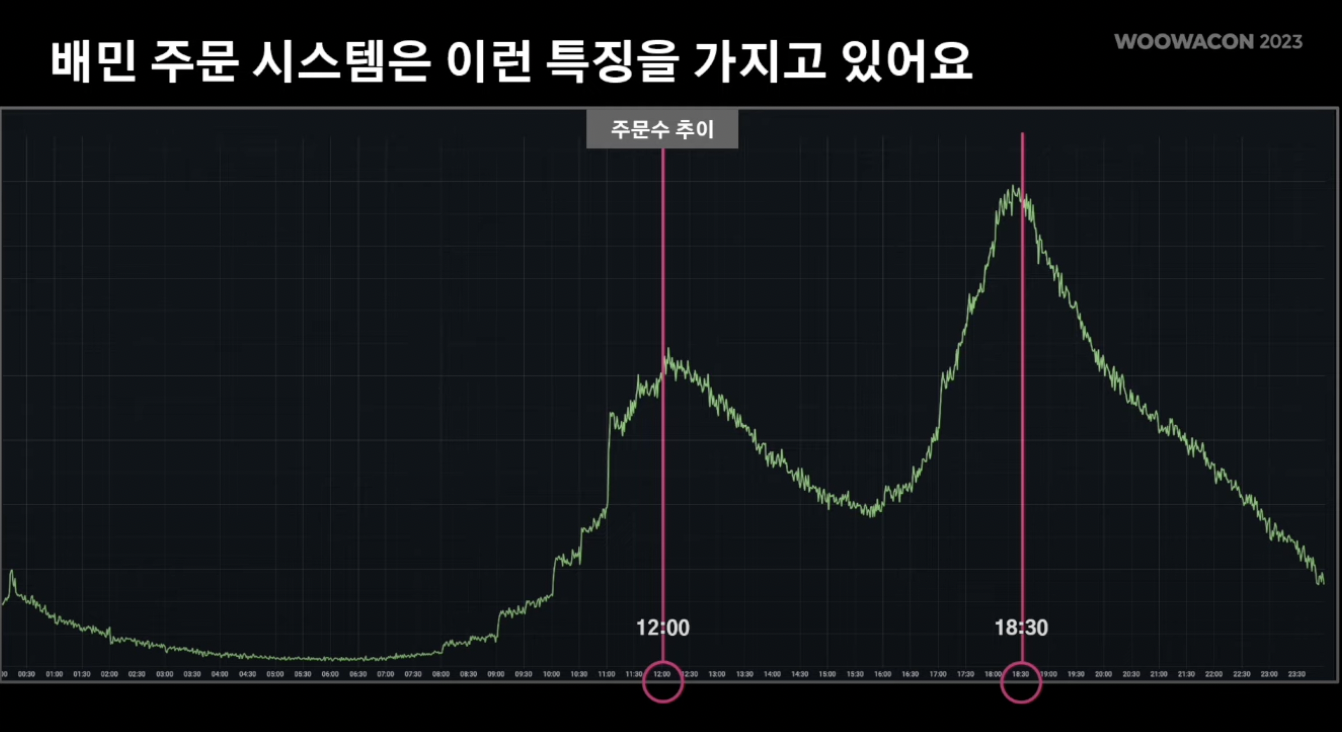
- 배민의 독특한 시스템
- 0-24시 (X축), 주문량 (Y축)
- 12시와 18시반에 주문량이 급격히 상승
- 따라서 유저 트래픽이 해당 시간대에 집중적으로 모임

- MSA
- 배민시스템은 "음식주문" 이라는 도메인과 연결된 뒷단의 많은 도메인이 존재하고 협업 수행 (배달, 결제, 가게, 메뉴 등)
- 따라서 특정 도메인 장애 시 SPOF 생기지 않게 노력

- 배민주문 시스템은 일평균 300만건의 주문 발생
- 또한 수년간의 데이터를 serving해야하는 의무 존재
- 따라서 이런 방대한 데이터를 "잘" 보존 & 서빙할지 고민

- 위에서 보여준 것처럼 특정 시간대에 몰리는 트래픽을 안정적으로 처리해야함
- 따라서 해당 트래픽에 대한 대규모 트랜잭션을 안정적으로 처리해야함

- MSA를 활용하다 보니 다양한 도메인과의 이벤트 기반의 소통이 잘 이루어져야함
- 느슨한 결합
- 따라서 특정 이벤트를 관리하는 여러 시스템 간의 소통 및 관리가 중요해짐
성장하는 주문 시스템

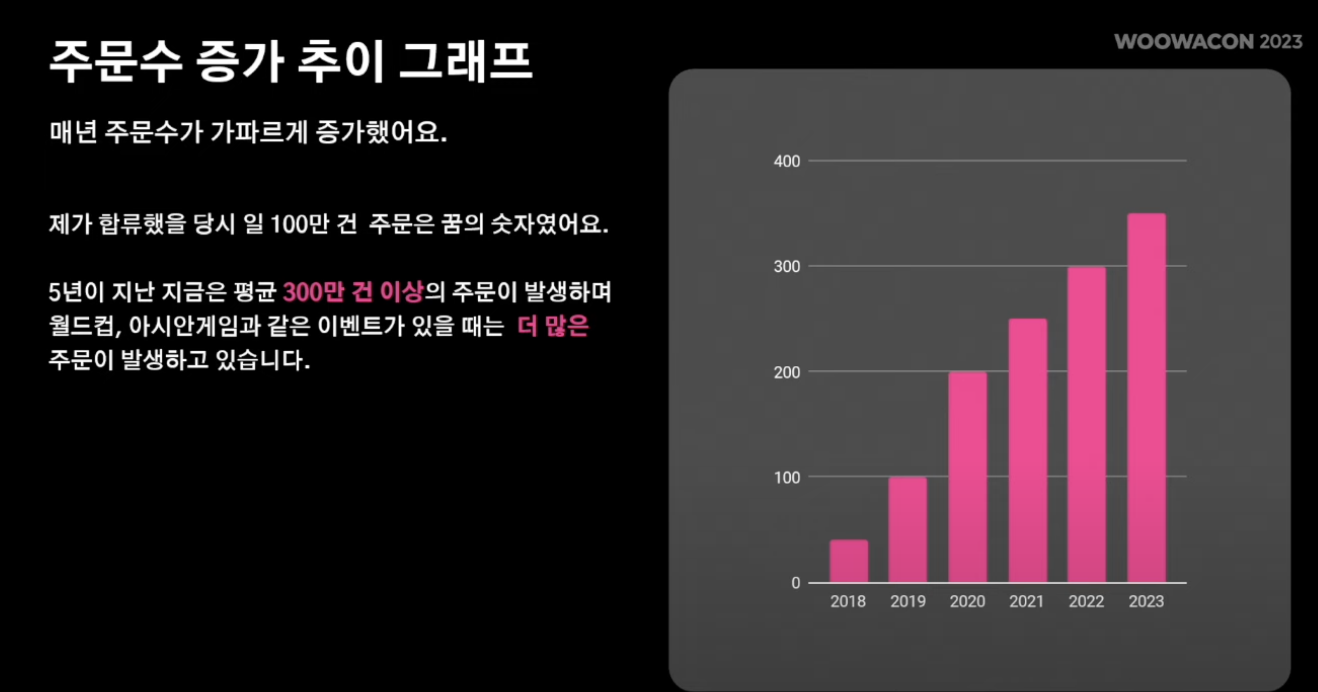
- 2018 - 2023년까지 일 평균 주문 수
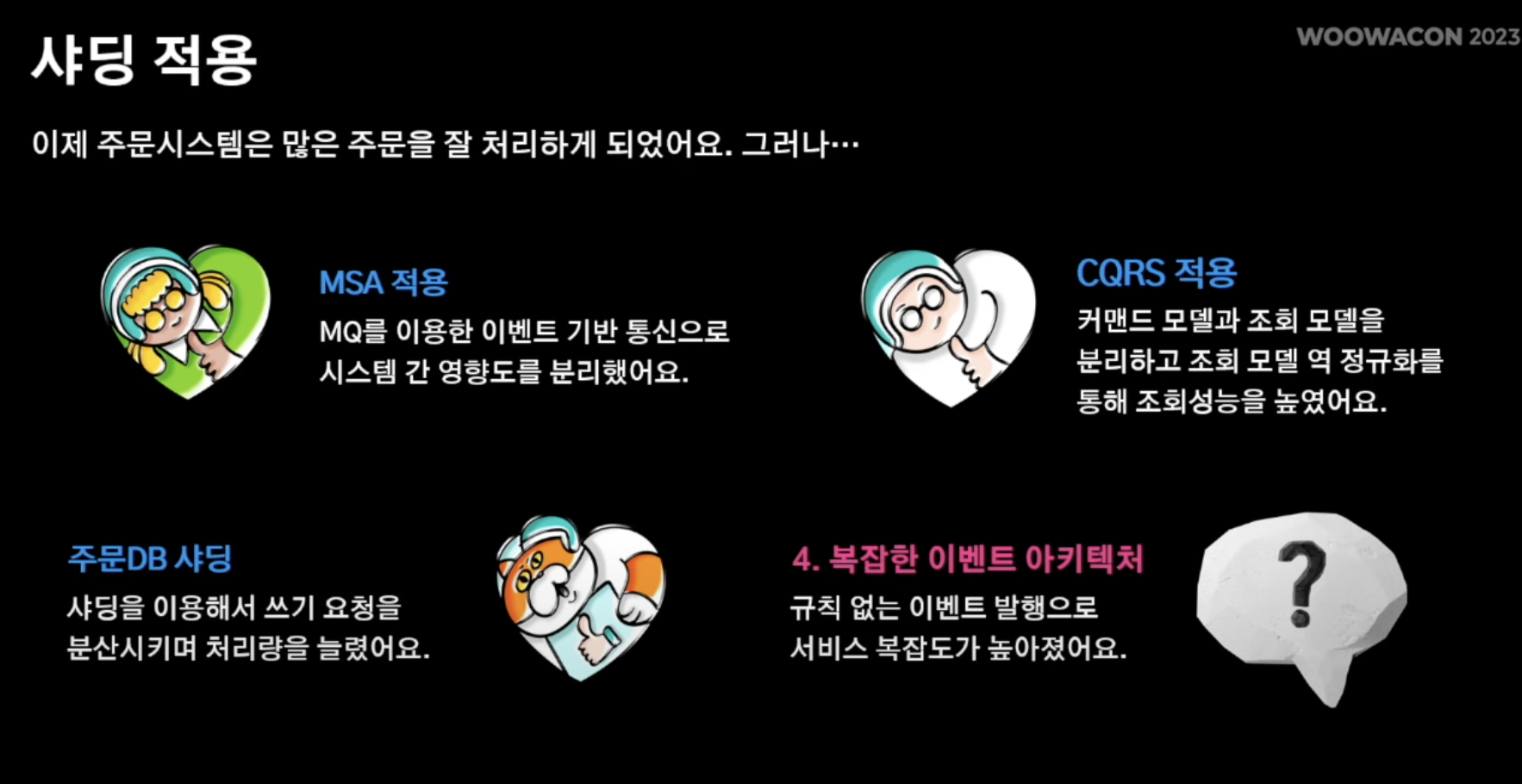
1. 단일 장애 포인트 - 하나의 시스템의 장애가 전체 시스템 장애로 이어짐.
2. 대용량 데이터 - RDMBS 조인 연산으로 인한 오버헤드
3. 대규모 트랜잭션 - 주문수증가로 저장소의 쓰기 처리량 한계 도달
4, 복잡한 이벤트 아키텍쳐 - 규칙 없는 이벤트 발행으로 서비스 복잡도 높아짐.

1. 단일 장애 포인트

- 중앙 DB의 장애가 전체 시스템 장애로 이루어지는 critical한 문제 존재
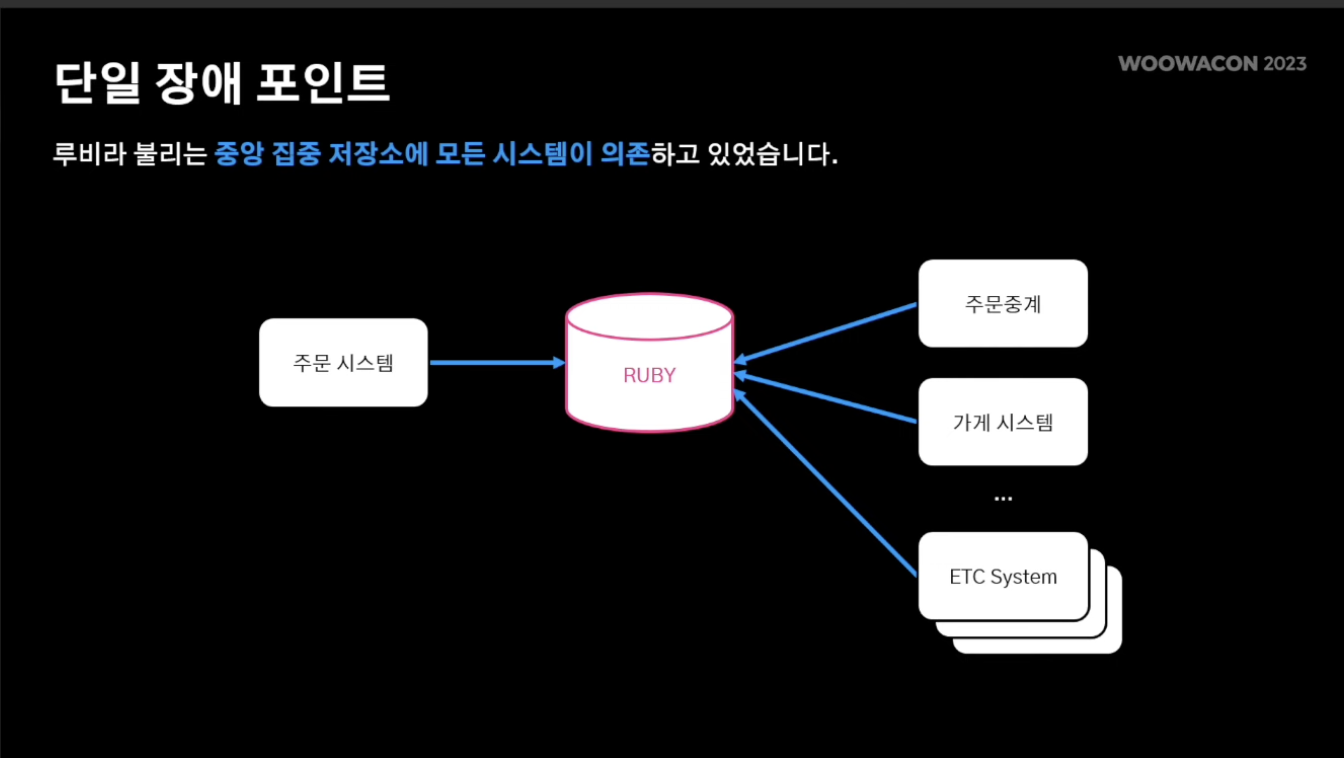
- 루비라는 중앙 시스템에 의존
- 특정 시스템 장애 시 루비의 부하로 이루어지고 기타 시스템들에게도 고스란히 이루어짐
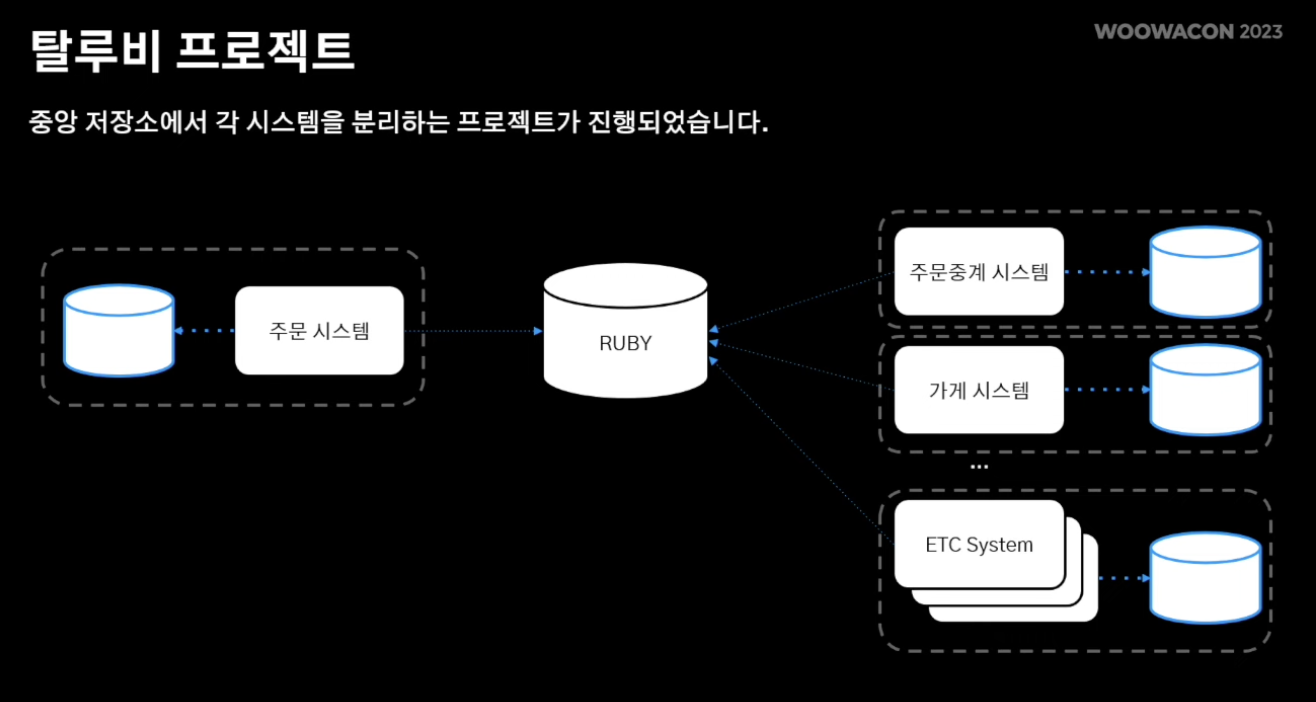
- 따라서, 루비에 의존성을 줄여가면서 각 시스템 별로 각각의 도메인에 맞게 저장소를 가져감
- 루비를 폐기 처리하고 시스템 간 통신은 Message Queue 기반으로 통신
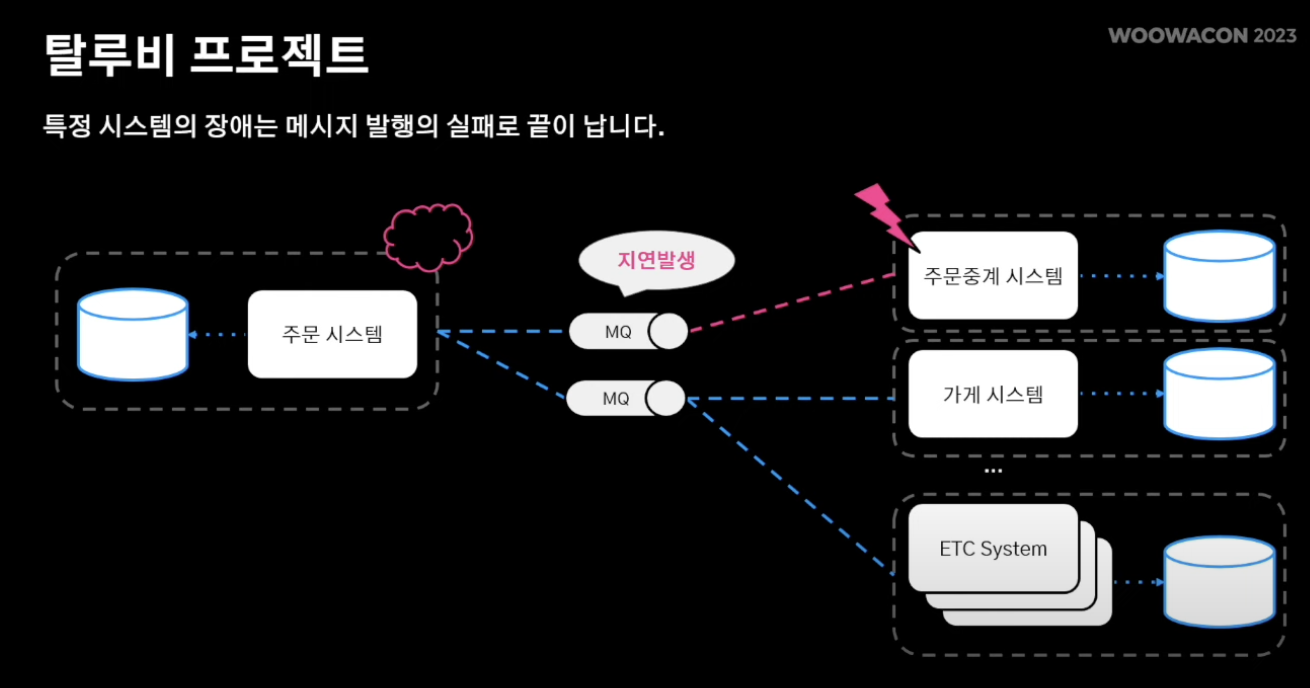
- 따라서 특정 시스템에 장애가 발생해도 다른 시스템까지 전파 X
- 또한 메시지큐에 지연이 발생해도 메시지 큐 특성상 이벤트 재소비가 가능해 빠르게 서비스 안정화 될 수 있음

2. 대용량 데이터

- 데이터가 증대될 수록 정규회된 DB간의 JOIN 성능이 나빠짐
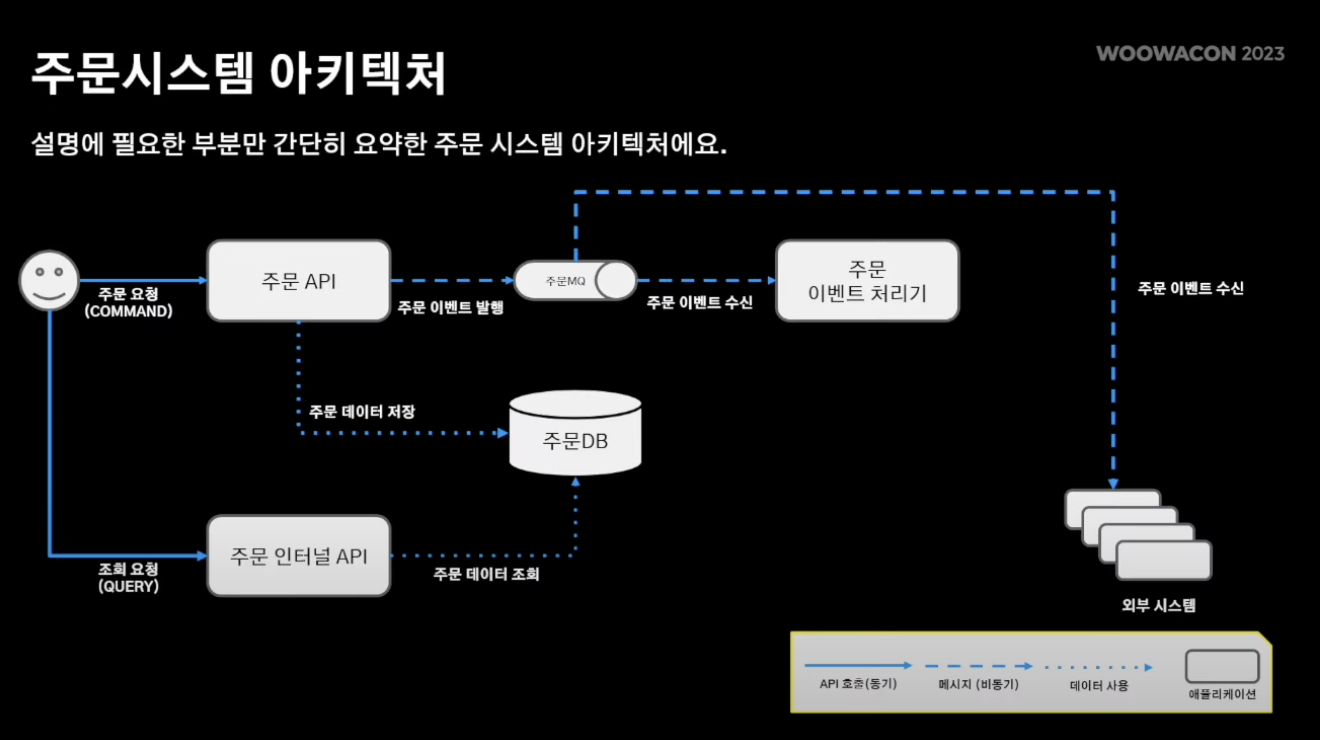
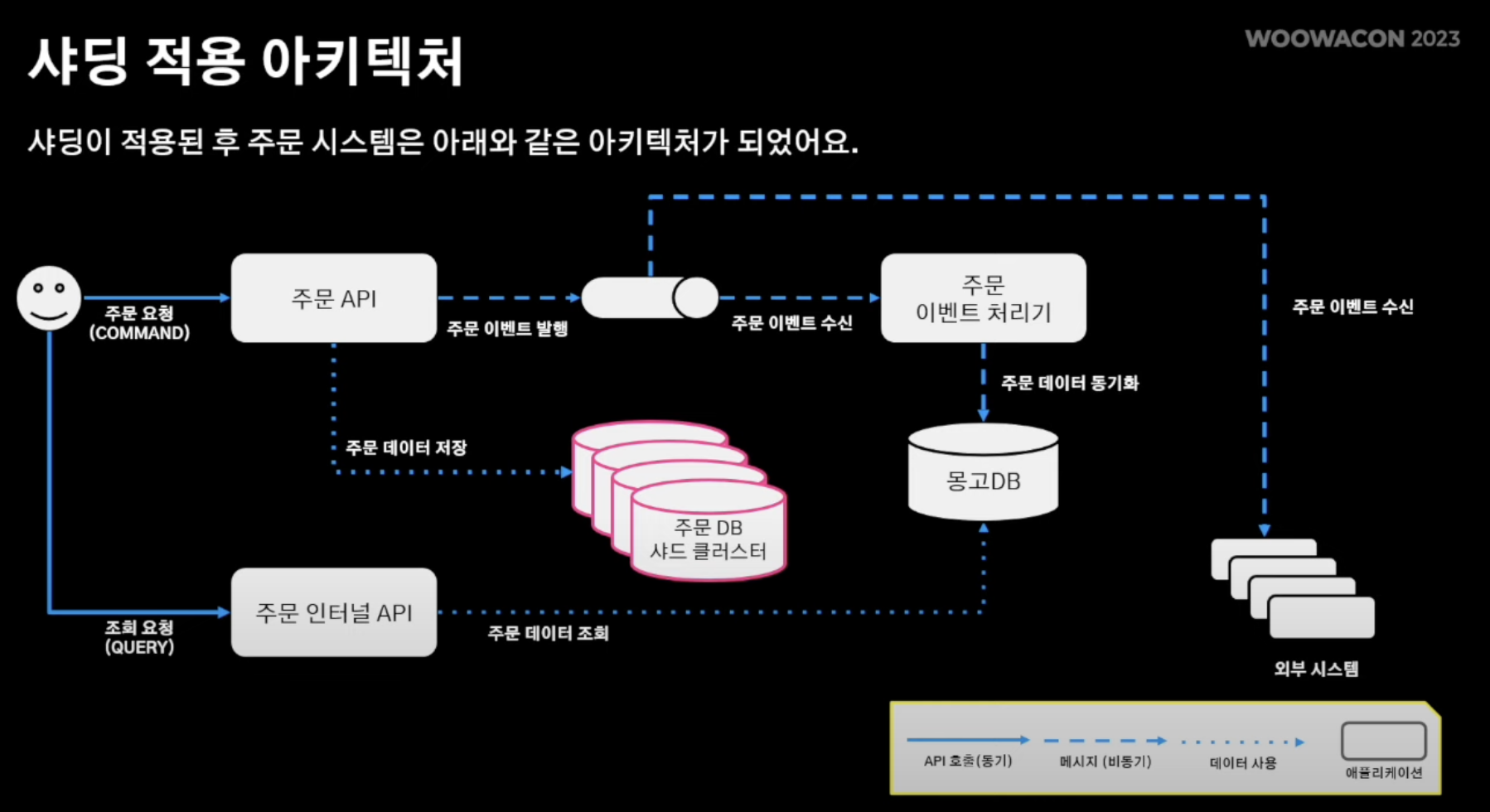
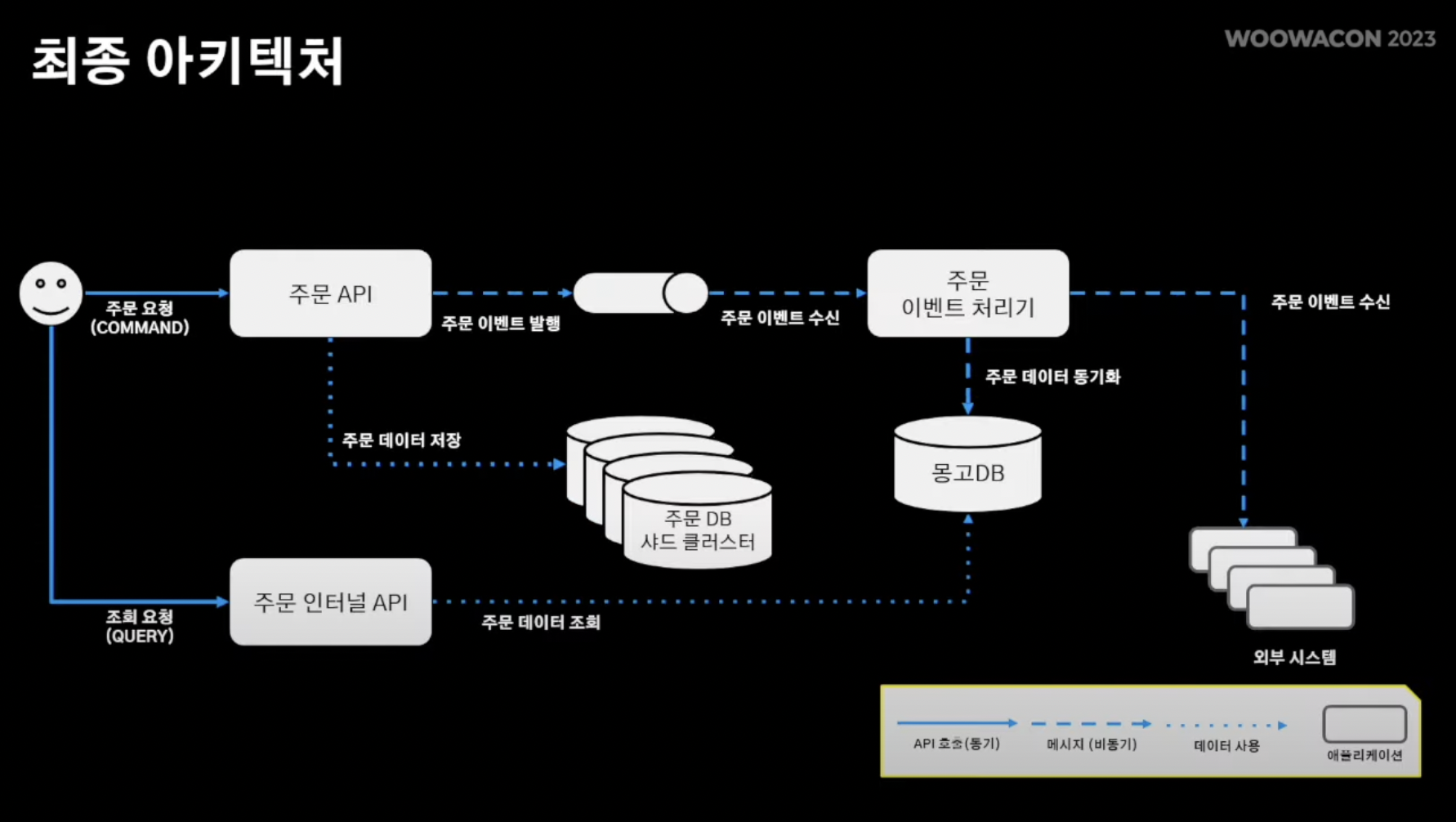
- 주문 시스템 아키텍쳐
- 주문 API, 주문 인터널 API, 주문 이벤트 처리기의 총 3가지 어플리케이션 존재
[흐름]
주문 생성 시 주문 생성을 받는 주문API endpoint를 통해 정규화된 DB에 기록됨 -> 주문 도메인 이벤트를 메시지큐에 발행 -> 주문 이벤트 처리기는 도메인 로직과 별개로 움직여야 하는 서비스 로직 수행 -> 또한 다른 외부 시스템이 메시지큐를 바라보면서 주문과 관련된 로직 수행 -> 부가적으로 주문 인터널 API는 주문 내역이 필요한 외부 시스템에 해당 정보 serving.
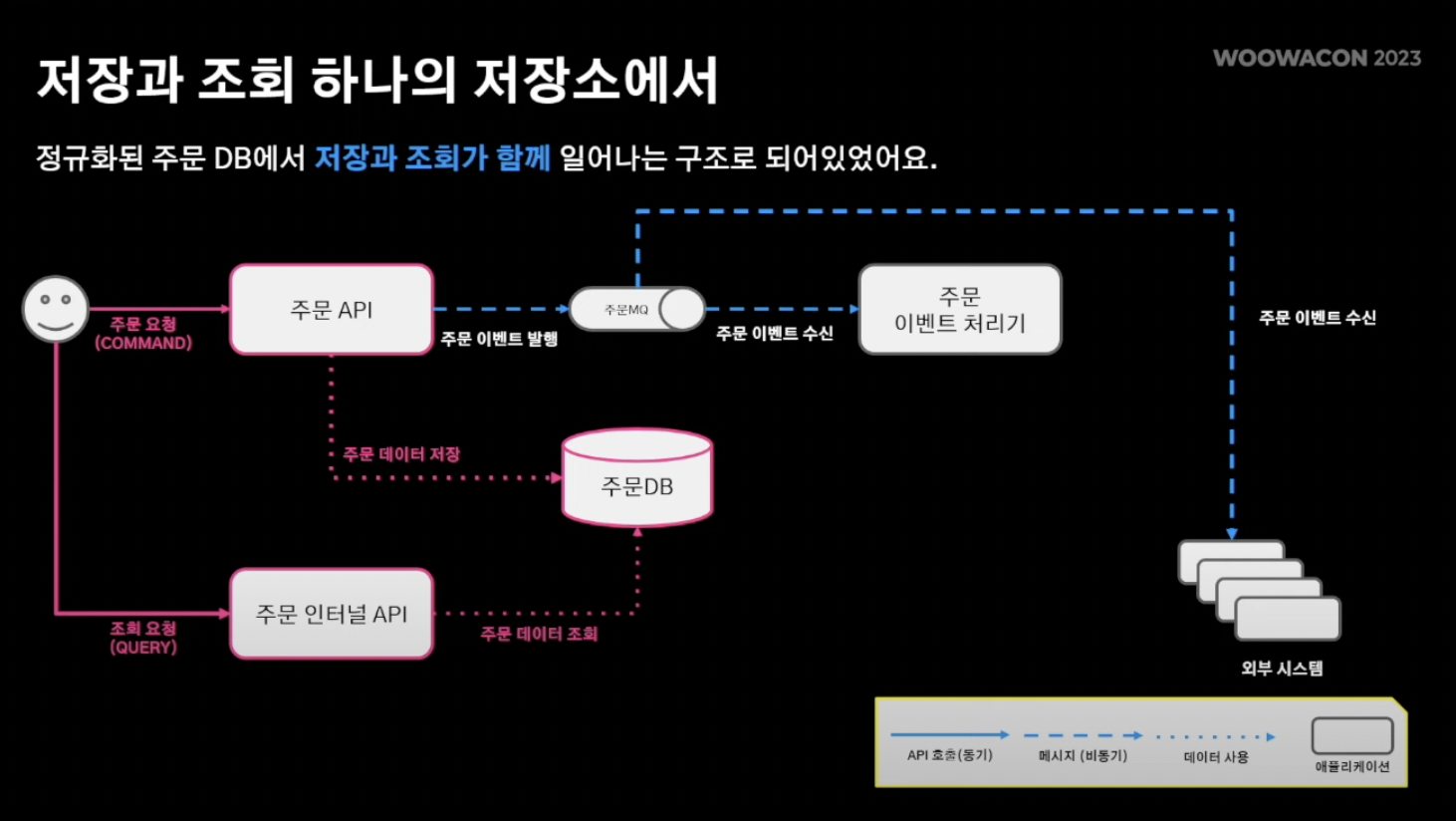
- 빨간색이 대용량 트래픽을 처리하면서 주의깊게 지켜봐야 할 부분
- 주목점 : 주문 시 주문 저장(write)과 조회(read)가 동시에 일어남
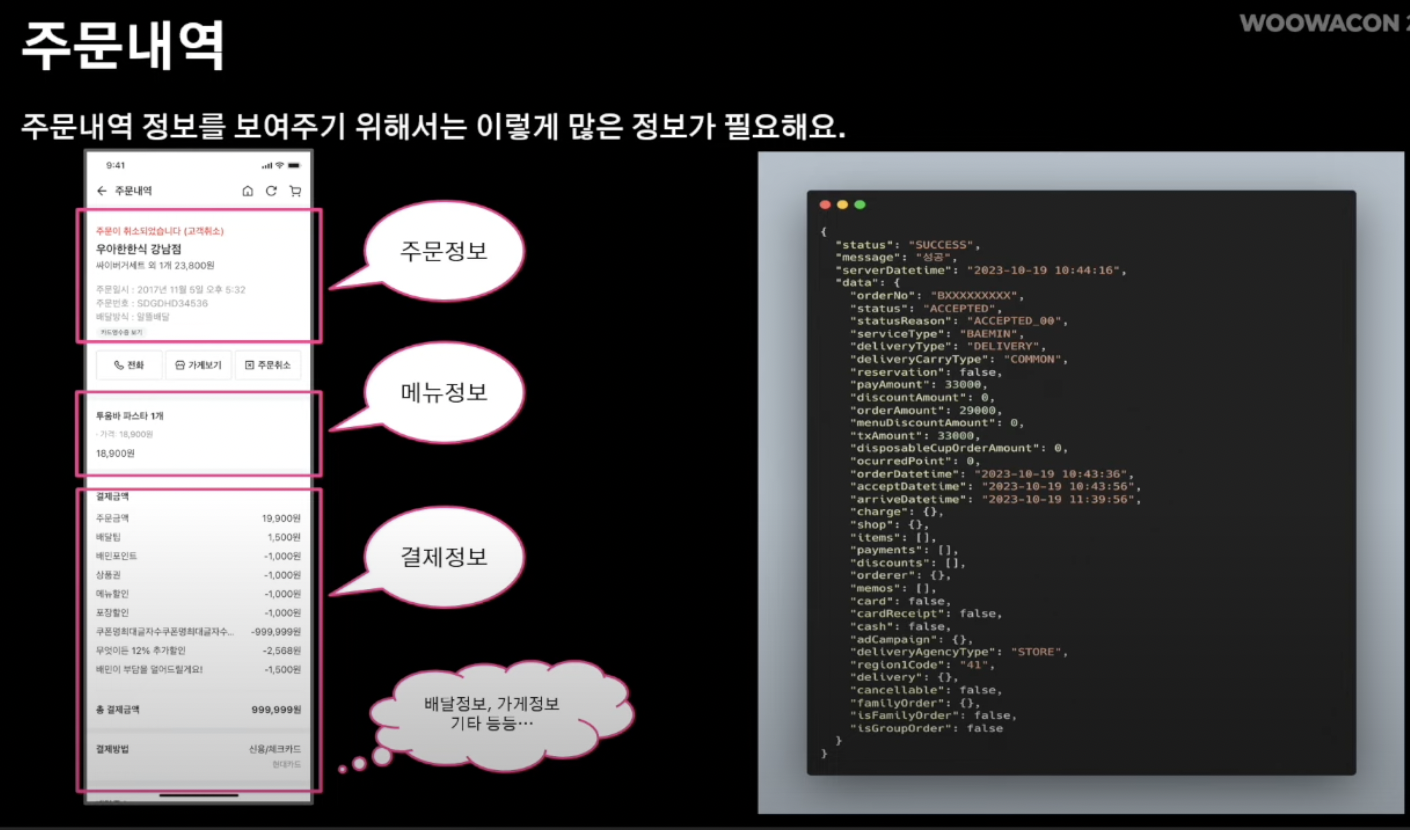
- 주문 정보 상세내역을 보여주기 위해서는 많은 데이터가 필요
- 주문,메뉴,결제 정보를 비롯 배달정보, 가게정보, 기타 등등..
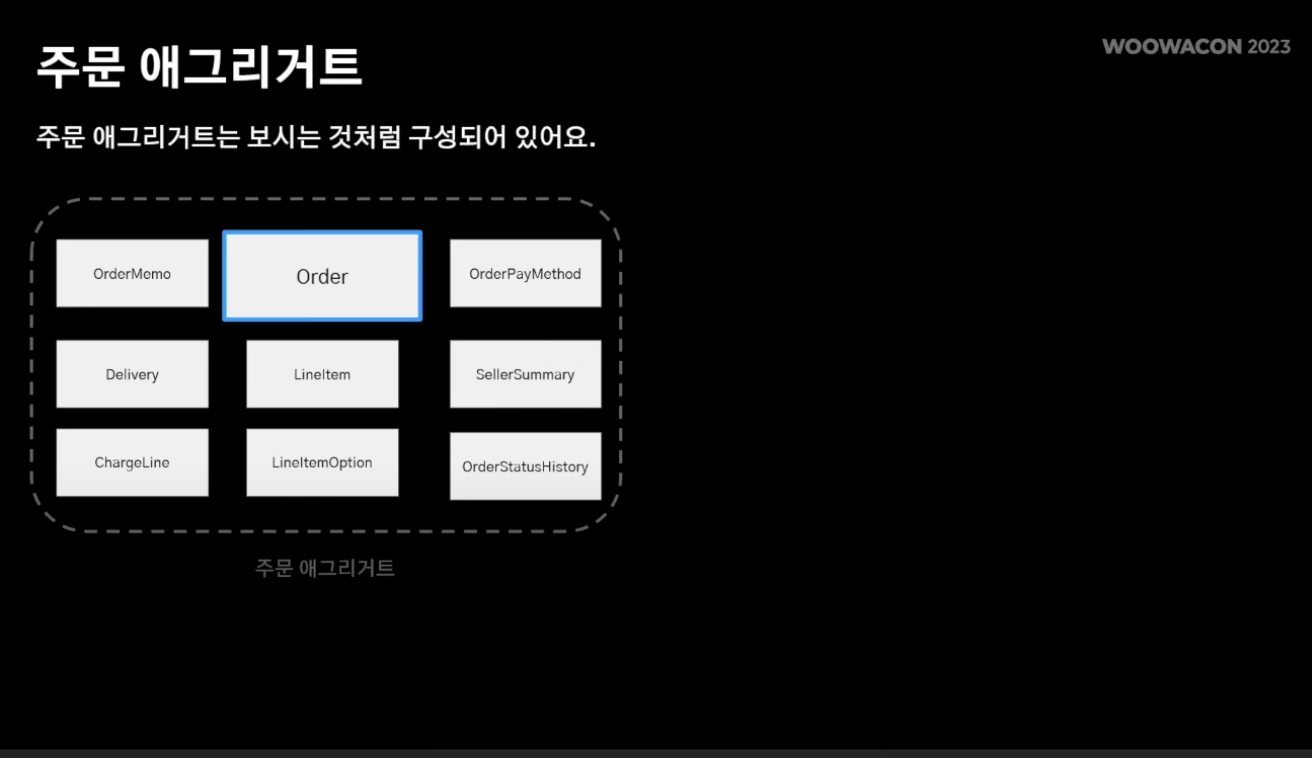
- 주문 애그리거트에는 order entity 내 메뉴,결제,배달 정보 등 다양한 정보가 필요
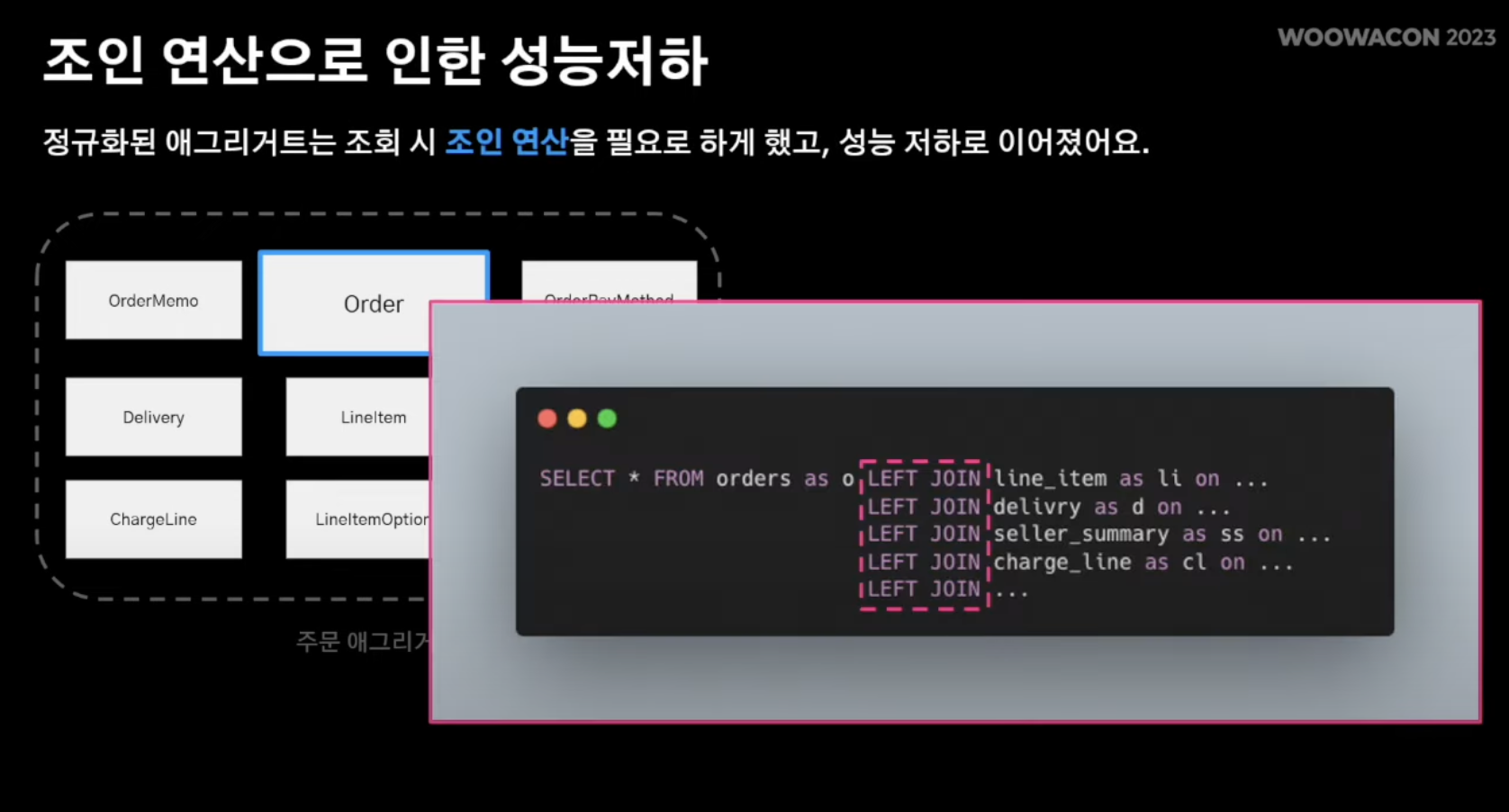
- 따라서 앞서 보인 주문 정보를 조회하기 위해서 위와같은 JOIN 연산 수행
- 이렇듯, 정규를 보장하는 데이터베이스 구조안에서는 성능저하로 이루어짐
해결포인트 : 역정규화
- 하나의 테이블로 유지
- NoSQL
- 따라서 단일 도큐먼트만 조회하면됨

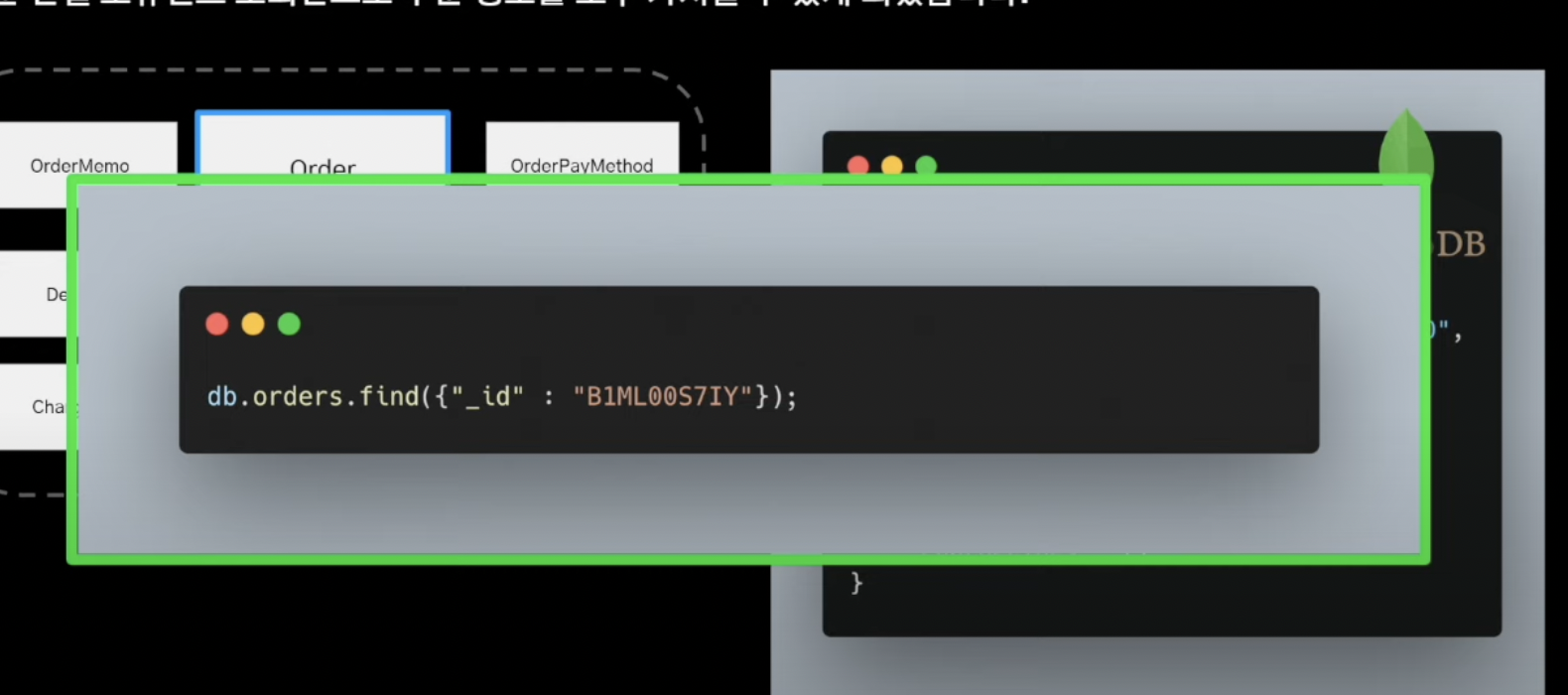
- id기반 조회 연산

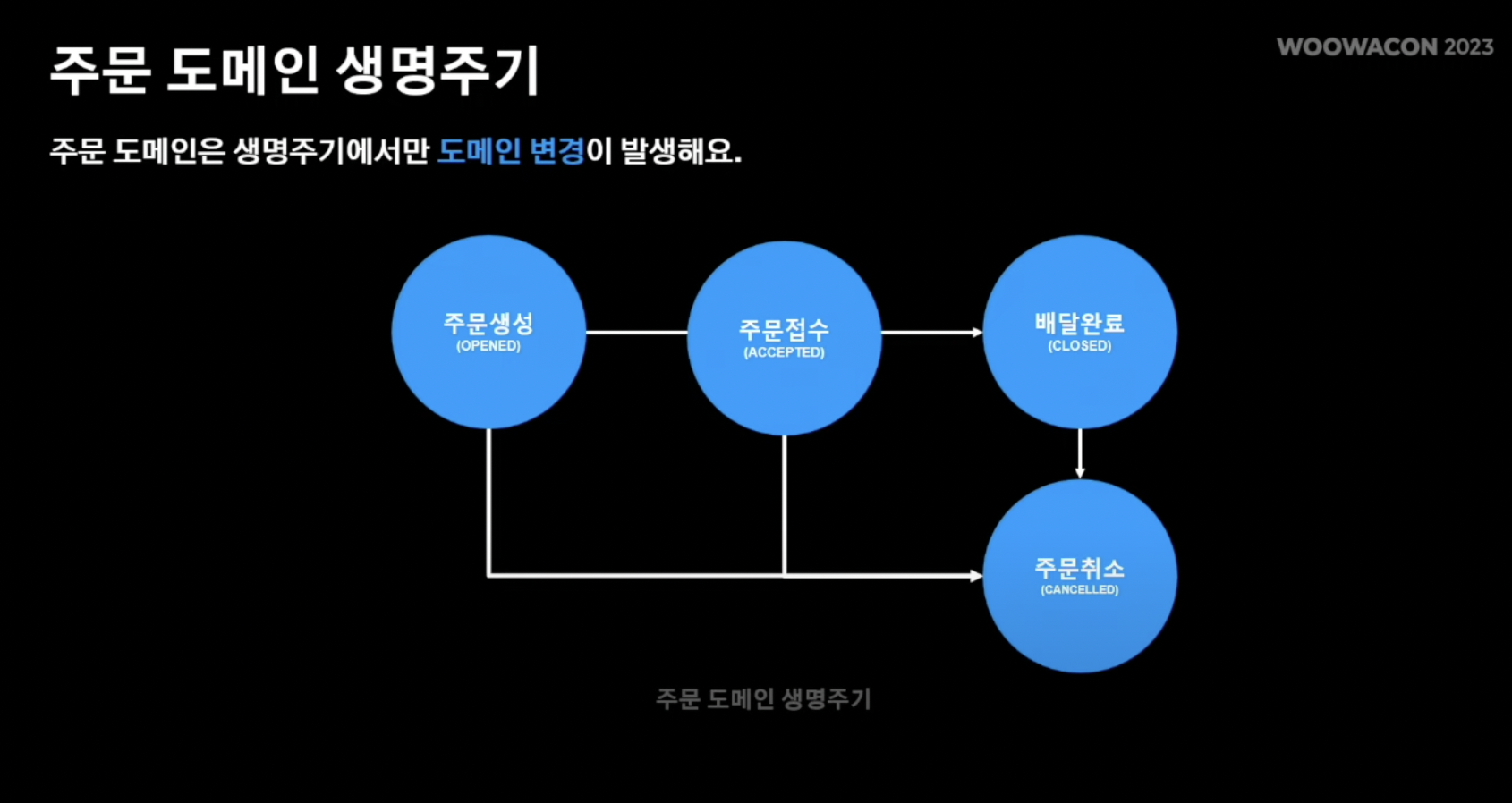
- 동기화 이슈를 살펴보기 전, 주문 생명주기를 살펴보면 주문 생성 -> 주문 접수 -> 배달완료 or 주문 취소 라는 사이클로 이루어짐
- 도메인의 변경은 "주문 사이클 내"에서만 이루어짐
- 즉, RDBMS의 데이터 변경은 도메인 사이클 변환 내에서만 이루어짐
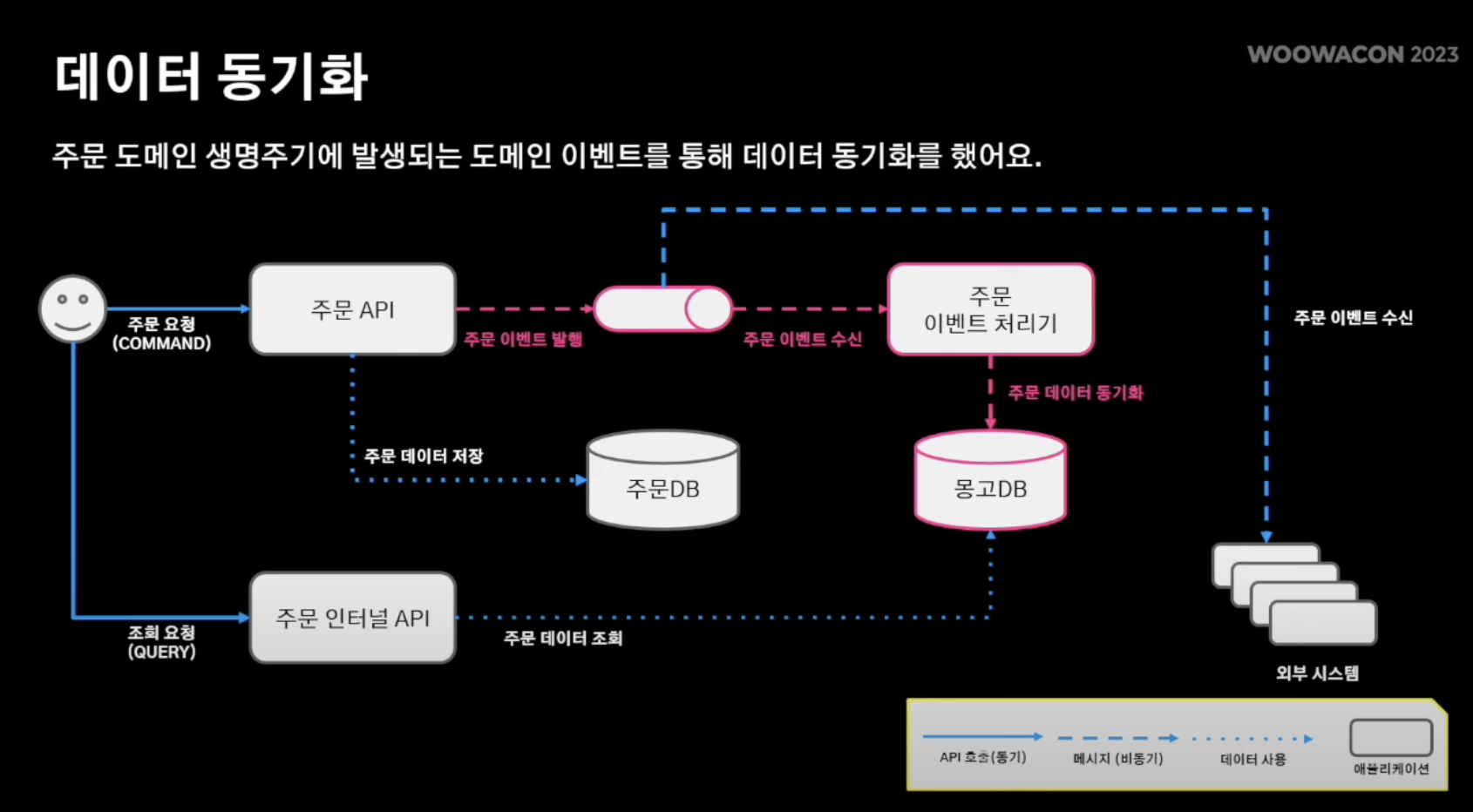
- 앞서 주문 도메인 변경이 일어날 때 마다 해당 이벤트를 MQ에 발행한다고 했었음.
- 따라서 도메인 이벤트가 생성되면 주문 이벤트 처리기에서 해당 이벤트를 구독해 데이터를 동기화 처리 후 NoSQL 데이터 저장.
따라서, 주문 요청 시 해당 주문정보에 대한 쓰기 연산은 RDBMS를 통해 이루어지고 주문 이벤트 처리기가 데이터 동기화 처리를 한 NoSQL의 정보를 활용해 주문 데이터 조회(Read연산)를 수행해 쓰기/조회의 동시다발적 연산을 분리 시킬 수 있었음.
좀 더 쉽게 얘기해보면, 길동이가 주문 접수 버튼을 누르면 해당 정보는 RDBMS에 기록되고 주문 후 자신이 무엇을 주문 했는지 + 주문 가게 정보가 어떠한 것인지 확인하기 위해 주문 내역 정보 조회를 수행한 결과를 serving하는 것은 NoSQL의 데이터를 통해 전달해주는 것이다.
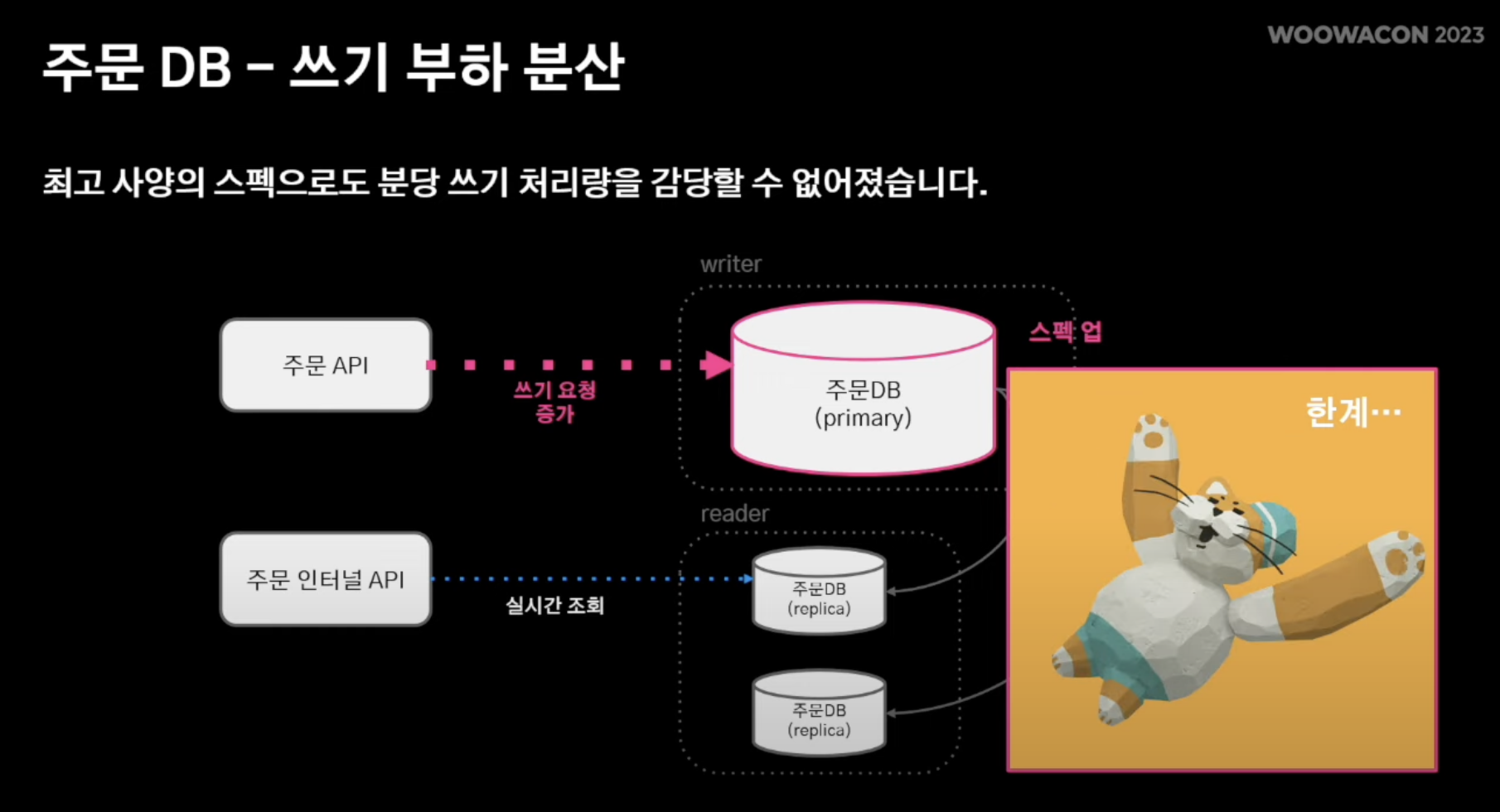
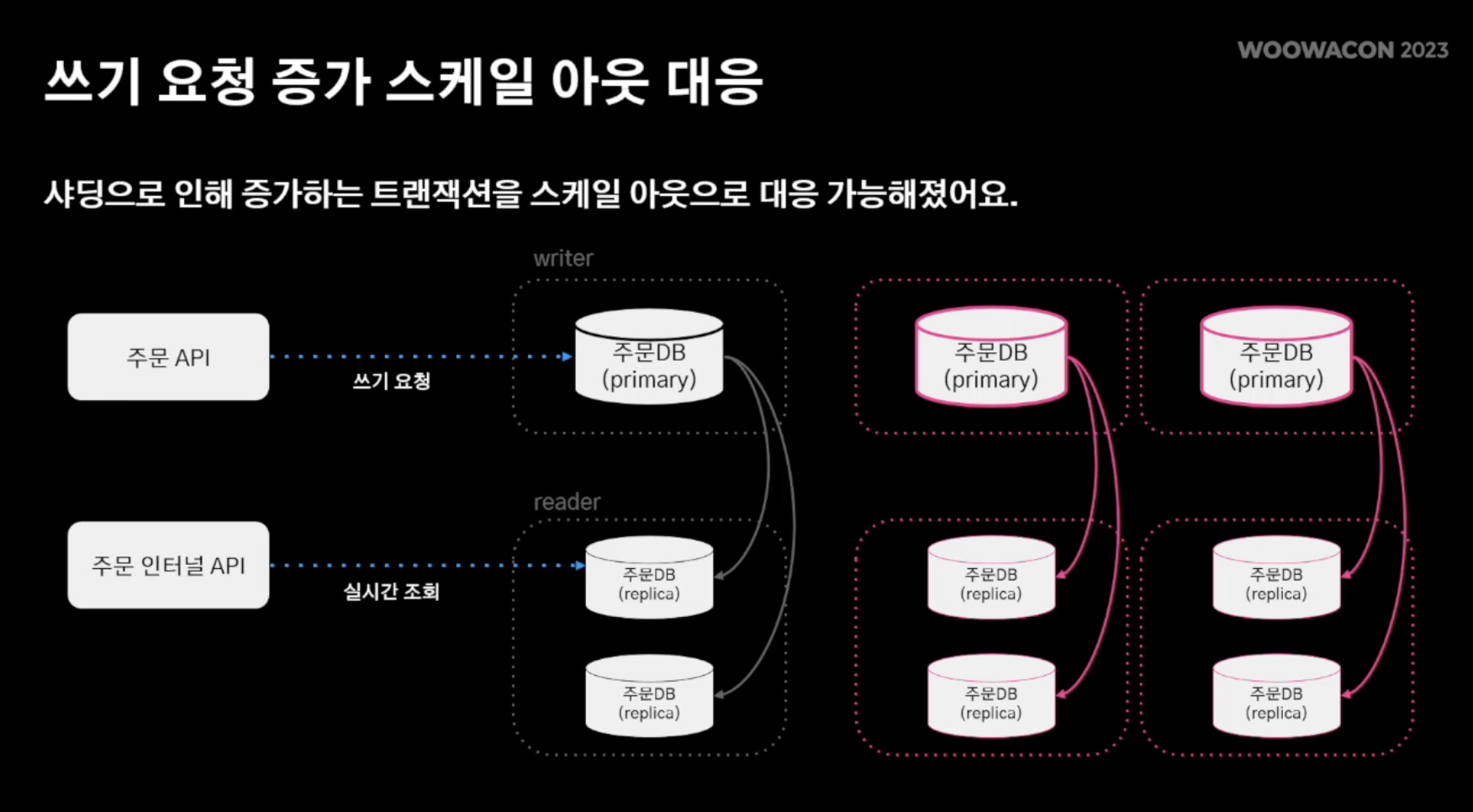
3. 대규모 트랜잭션

- 엄청난 주문량으로 인해 분당 쓰기 처리량을 감당할 수 없었음
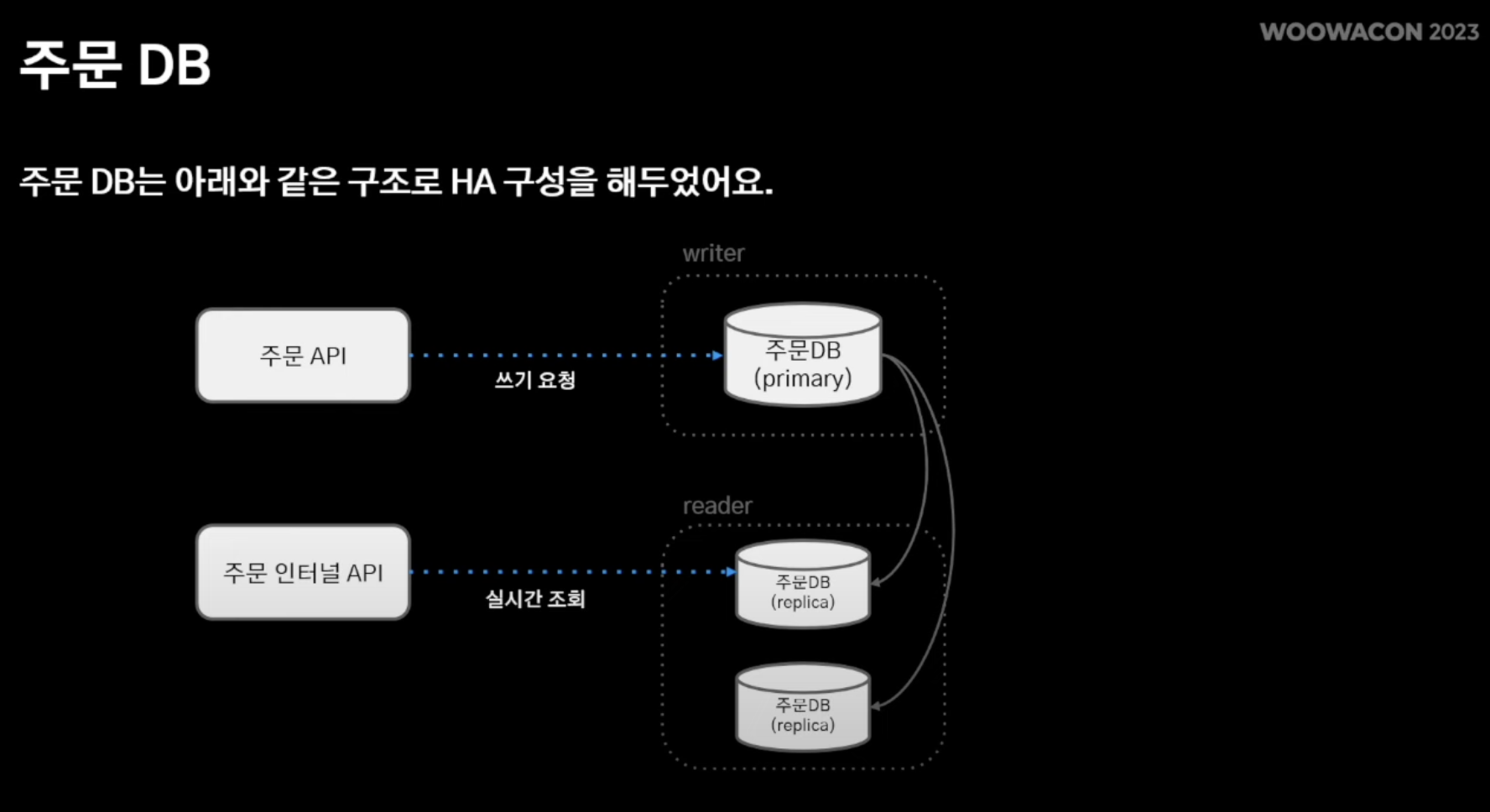
- 쓰기 요청은 주 DB 에서 수행하고 N개의 레플리케이션 DB를 통해 위에서 언급한 주문 인터널 API가 조회 연산 수행
- 조회 연산은 레플리케이션을 scale-out을 통해 처리
- 하지만 주 DB는 scale-out이 아닌 Spec Up을 통해 트래픽 처리 (역부족)
해결책 고민 : 샤딩
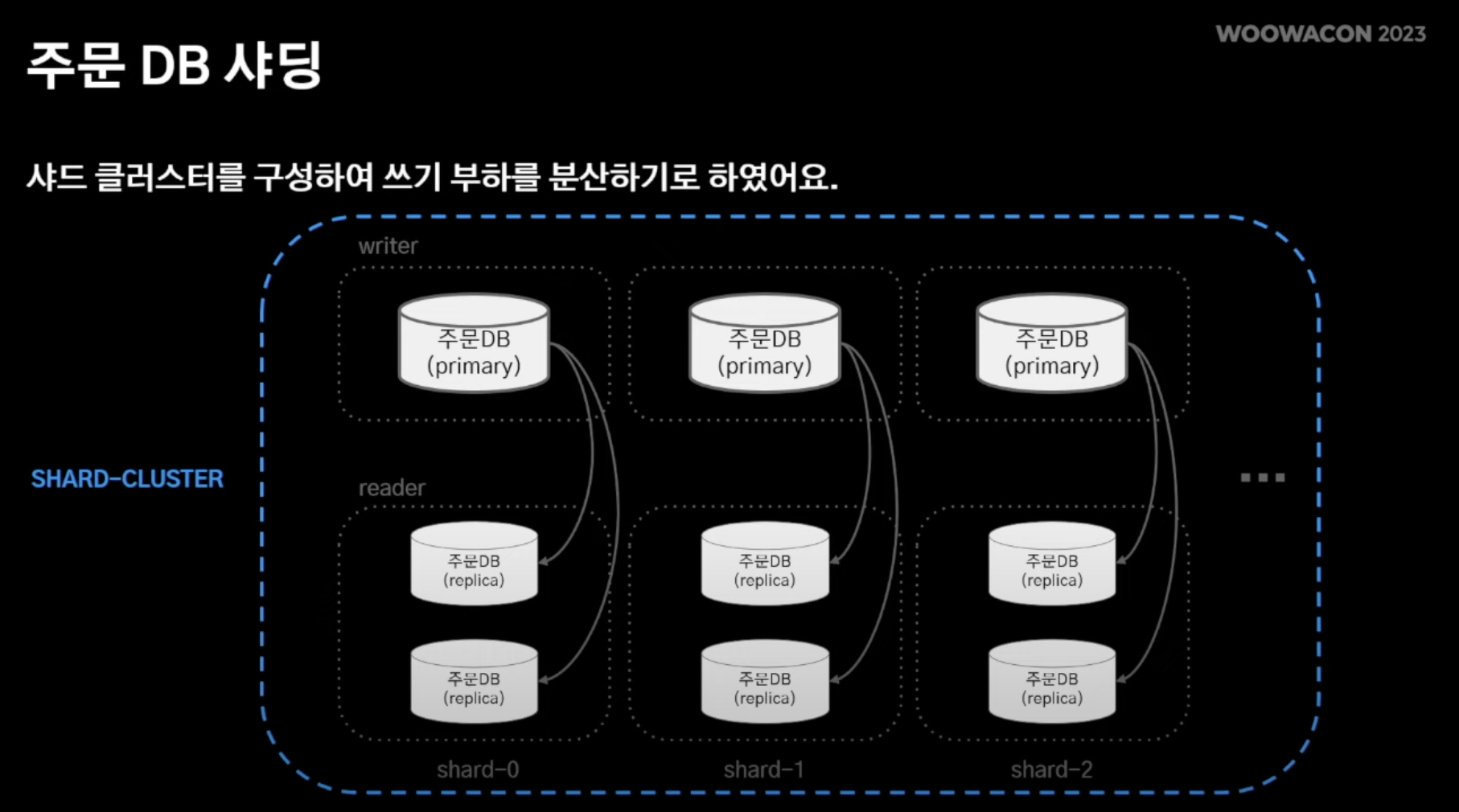
- 주DB역시 복제해서 트래픽을 분산처리 해보자!
!!! but,, 아마존 오로라는 해당 서비스를 지원X !!!
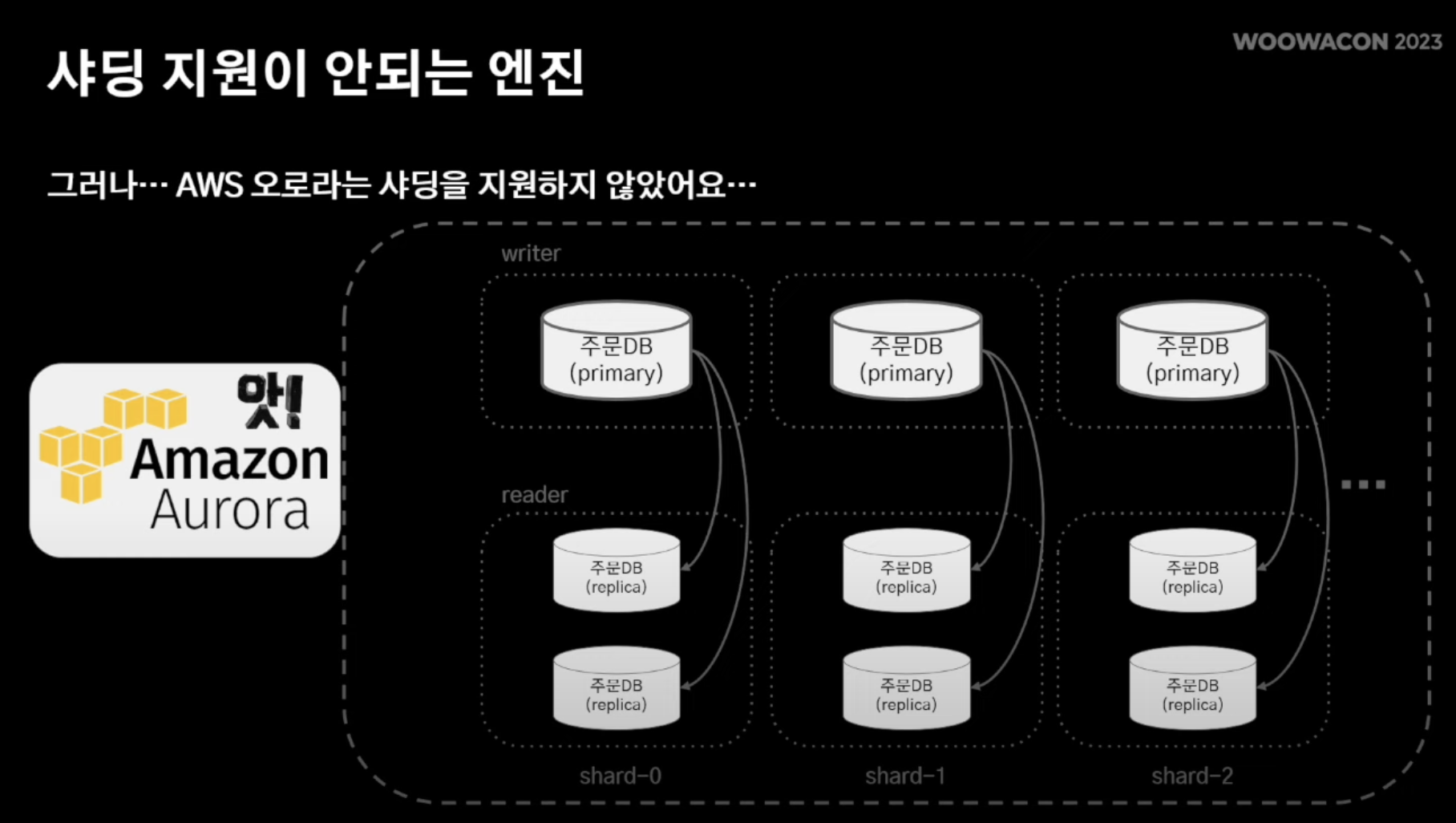


- 어플리케이션 단에서 샤딩 수행
- 따라오는 고민 1) 어느 샤드에 저장? 2) 샤딩된 데이터 간 애그리게이션 어떻게 수행?

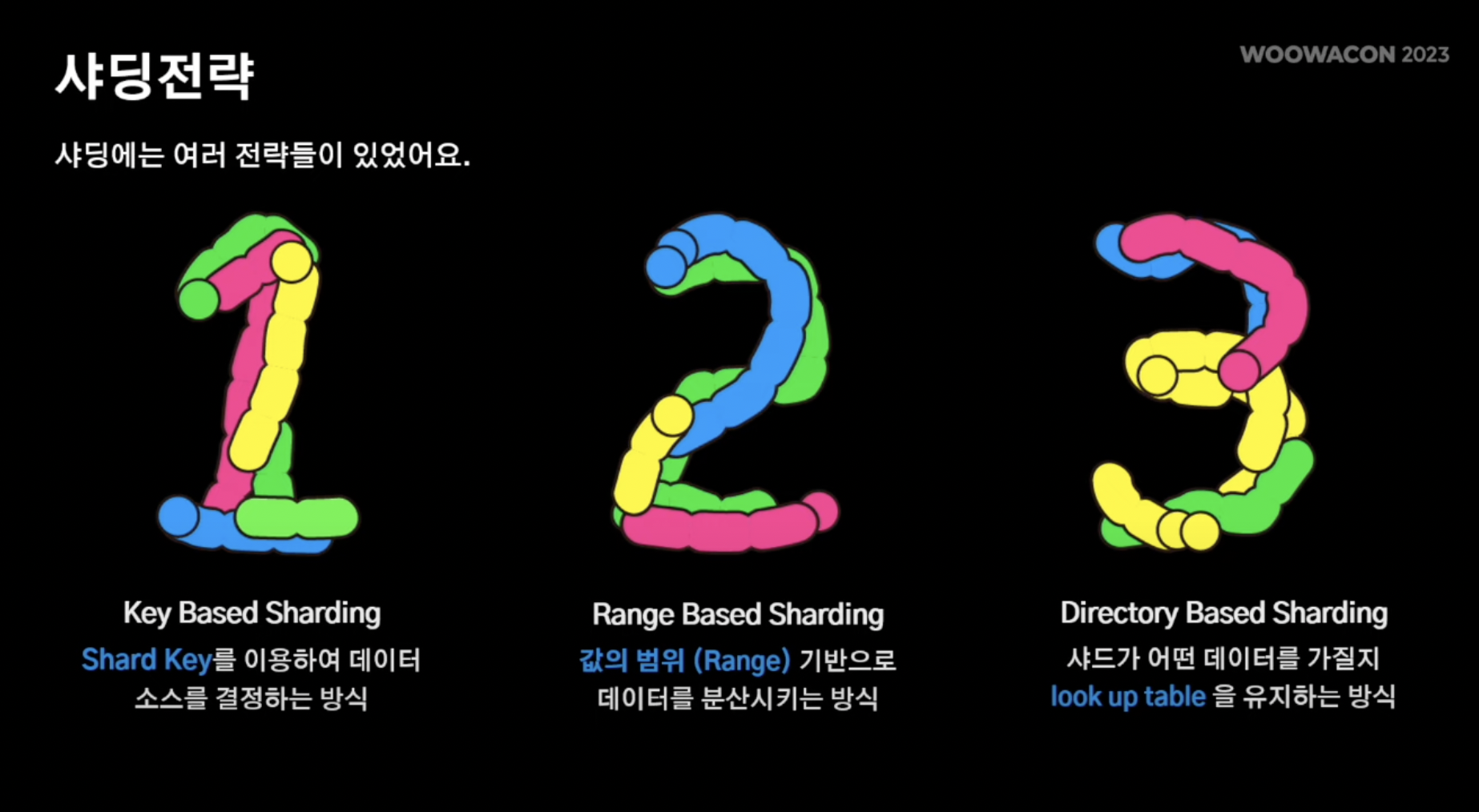
샤딩 전략
1. Key-Based Sharding
- 특정 샤드 키 해쉬맵 처럼 키 하나를 두고 데이터를 각각 분산시킴
2. Range-Based Sharding
- 특정 데이터가 어떠한 범위 내에 해당되면 해당 범위로 데이터가 전송되는 방식
3. Directory-Based Sharding
- 중간에 look-up테이블을 보고 특정 샤드키는 특정 샤드로 전송되는 방식
- Key-based sharding (a.k.a Hash Based Sharding)
- 해쉬 based 샤딩이라고 불리는데, 데이터의 특징 중 하나를 hash function에 돌려 각각 나오는 값에 따라 해당 샤드로 전송함.
장점: 구현이 간단, 데이터 고르게 전송가능
단점: 해시 함수에 강결합이 되어있어 데이터 추가/제거 시 유동성이 떨어짐
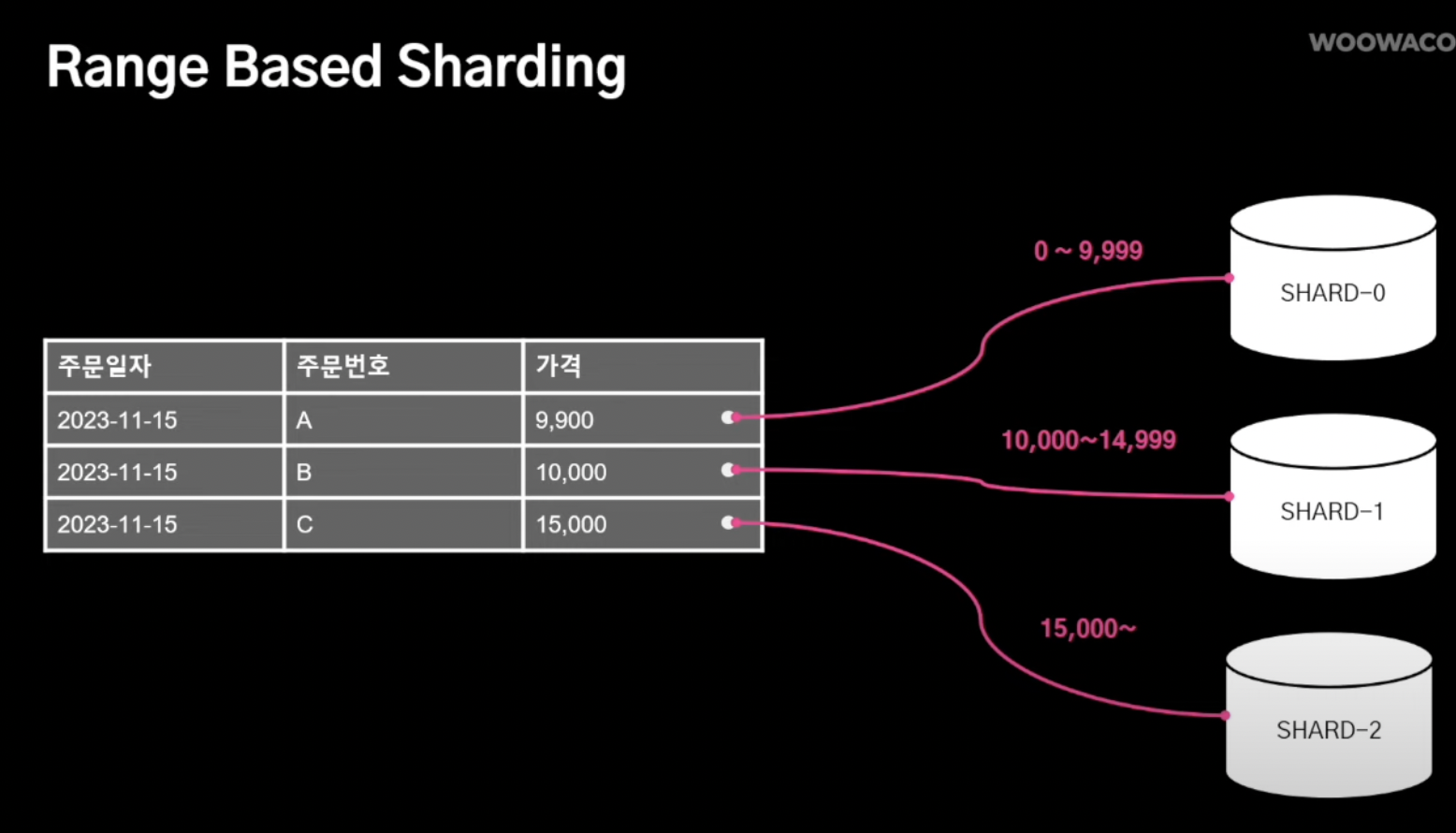
- Range-based Sharding
- 특정 데이터 특징에 범위를 매겨 해당 범위에 속하면 해당 샤드로 전송됨
장점: 구현 simple
단점: 데이터가 균등하게 배분 X, 특정 범위에 속하는 특정 데이터가 특정 샤드에만 몰릴 수 있음 (hotspot이슈)
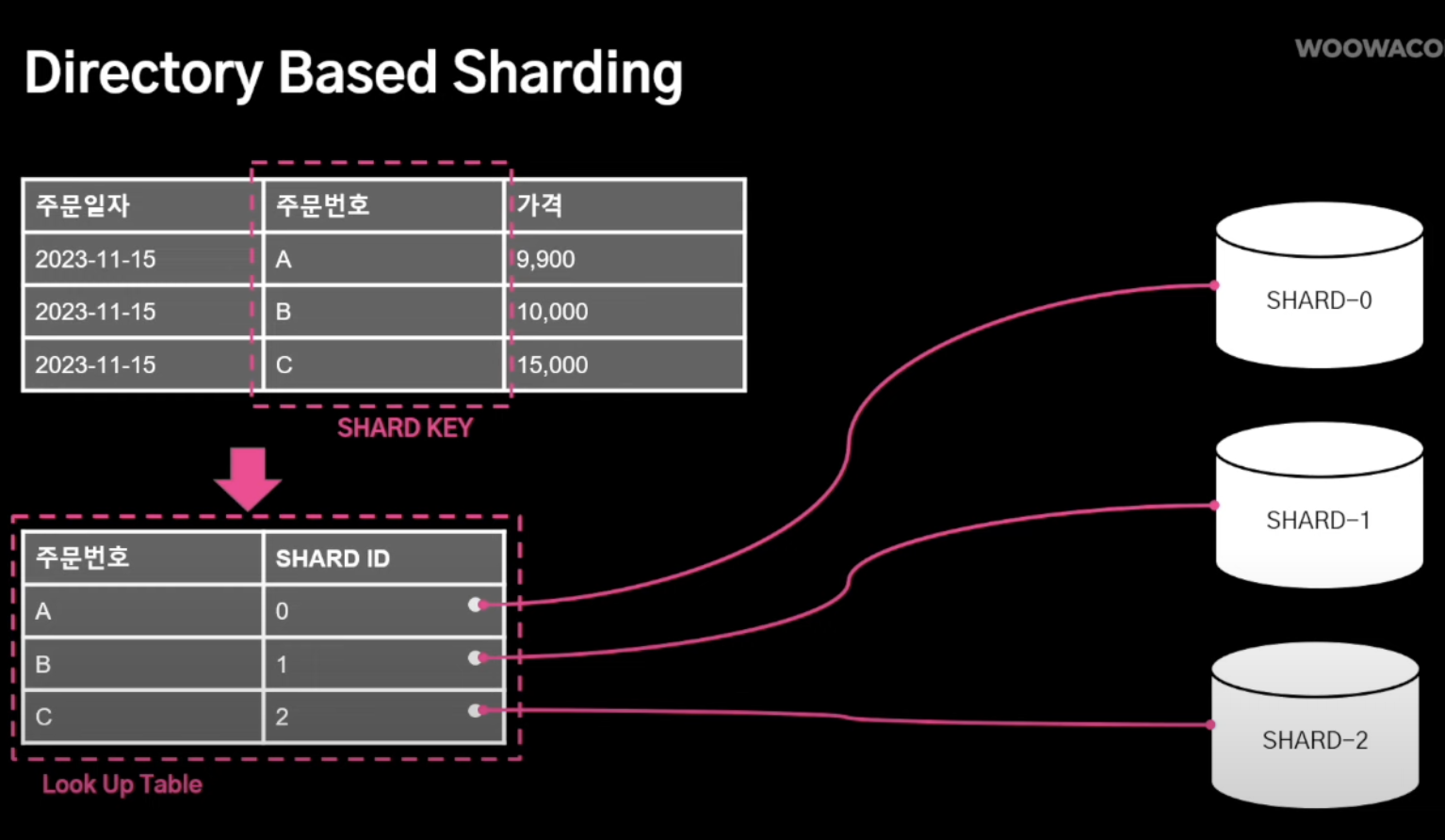
- Directory-based Sharding
- 1번 샤딩방식과 매우 유사한데 차이점은 중간에 룩업 테이블을 두고 어느 사드로 갈지 사전에 값을 정해놓음
장점: 샤드 키 추가/제거가 유연함 -> 룩업 테이블로 컨트롤
단점: 룩업 테이블이 SPOF 자체가 될 수 있음


의사결정을 하기 위해 서비스의 특징을 알아보자!
- 배달의 민족 고객은 "주문"이 제대로 이루어지지 않으면 "배민"의 장애로 인식함
- 최대 30일 이내에서만 주문 취소가 가능
- 주문 완료는 보통 1일 이내로 이루어지고 해당 데이터 상태 완료가 이루어지면 해당 데이터 상태의 스냅샷의 주기는 "하루"임

- 따라서, 단일 장애 포인트는 피하고 !
- 동적 데이트는 최대 30일 최소 1일 이내로 완결되기에 샤드 추가가 많이 이루어지지 않는다고 여겼으며 일어난다 해도 30일이 지나면 데이터는 결국 균등하게 분배될 것이라는 결론에 도달.
의사결정 : 1번 - hash-based sharding

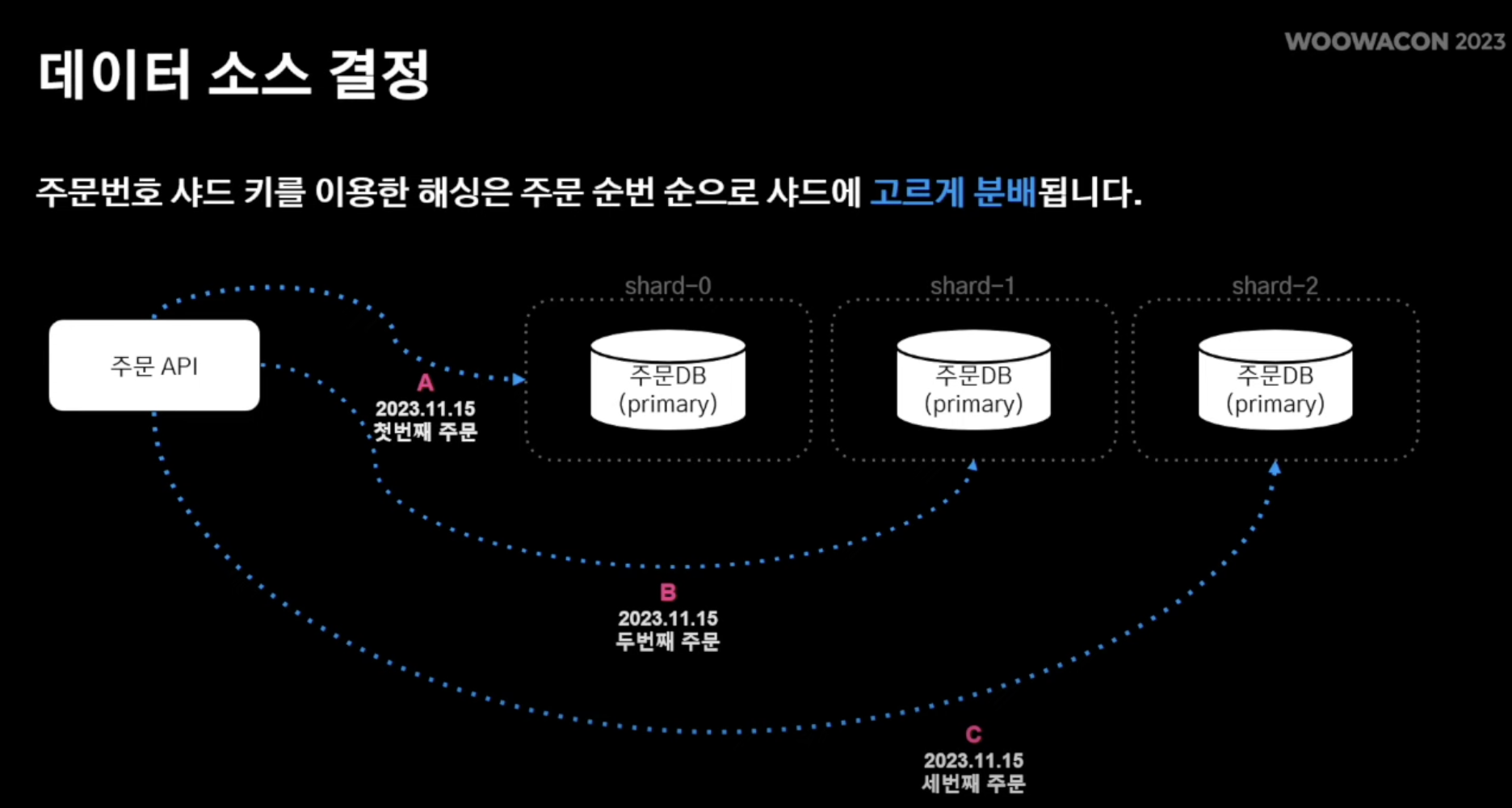
- 샤드키로 주문번호 설정 !
- 주문번호에는 특정 일자, 특정 순번에 대한 로직이 담겨있음
- 주문 순번 % 샤드 수 = 샤드 번호의 연산으로 이루어짐 !
- 따라서 위와같이 동일한 날짜에 주문 내역도 각기 다른 primary 샤드 DB에 저장이 될 수 있음 !
구현 방식
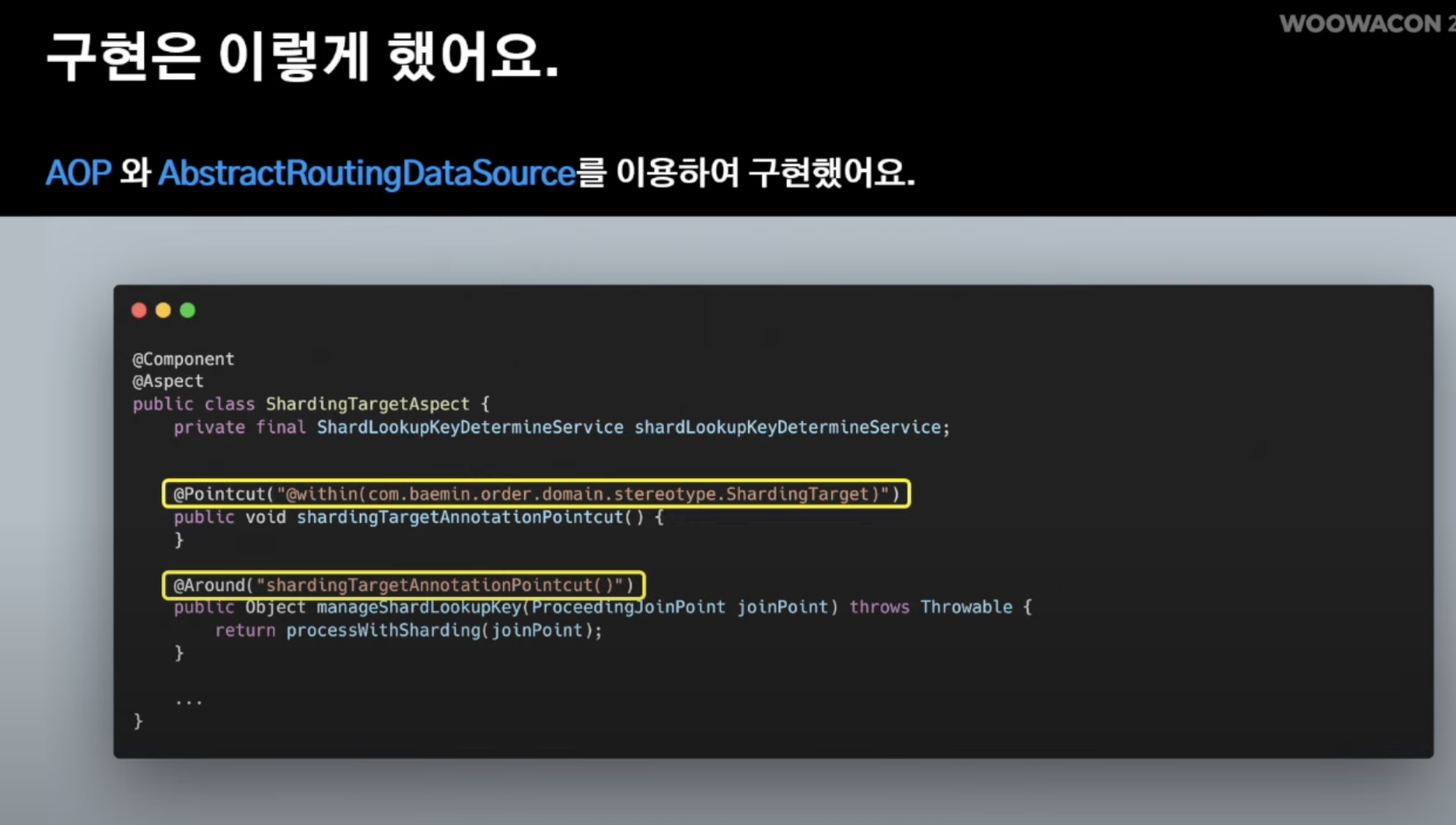
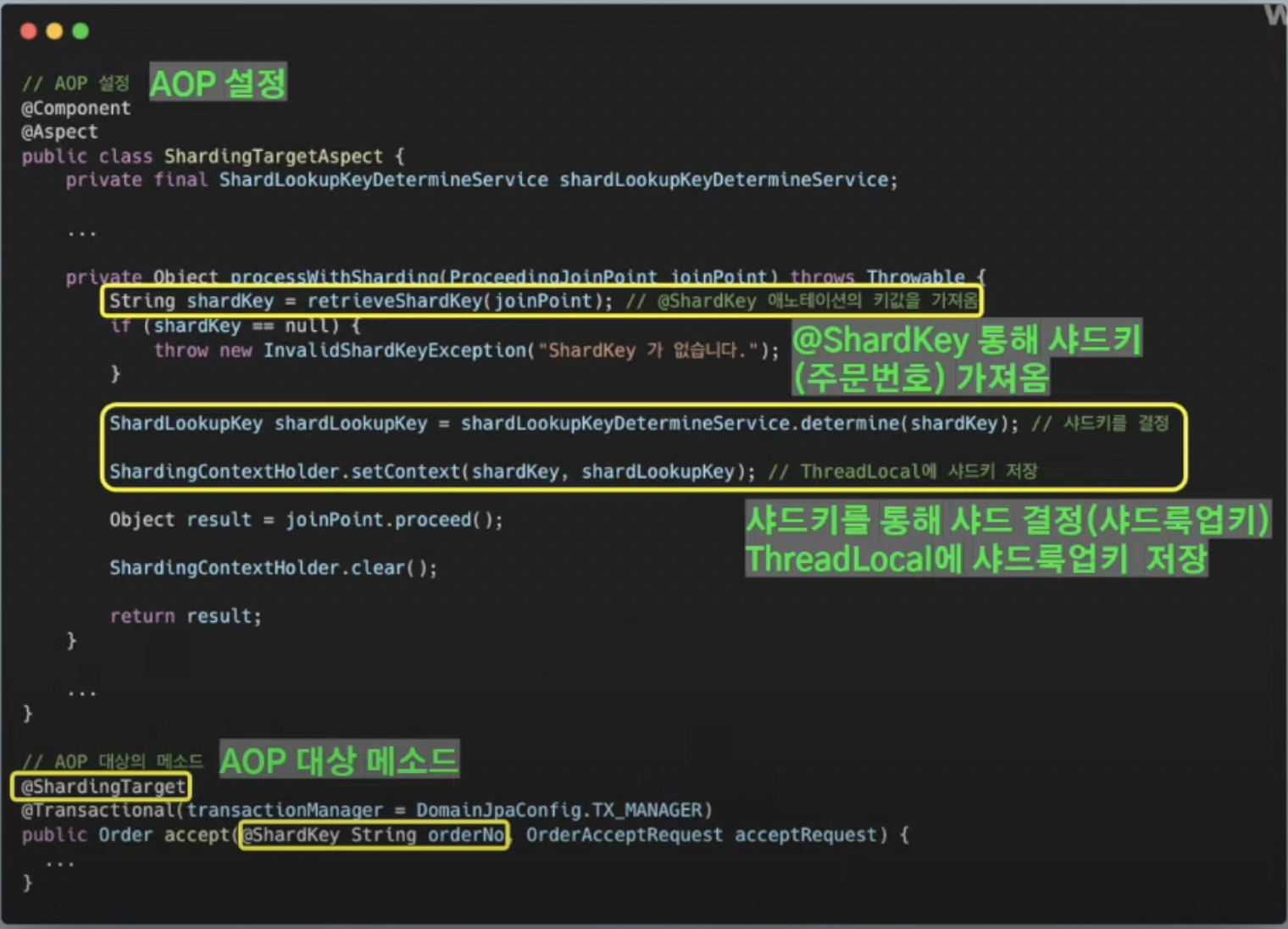
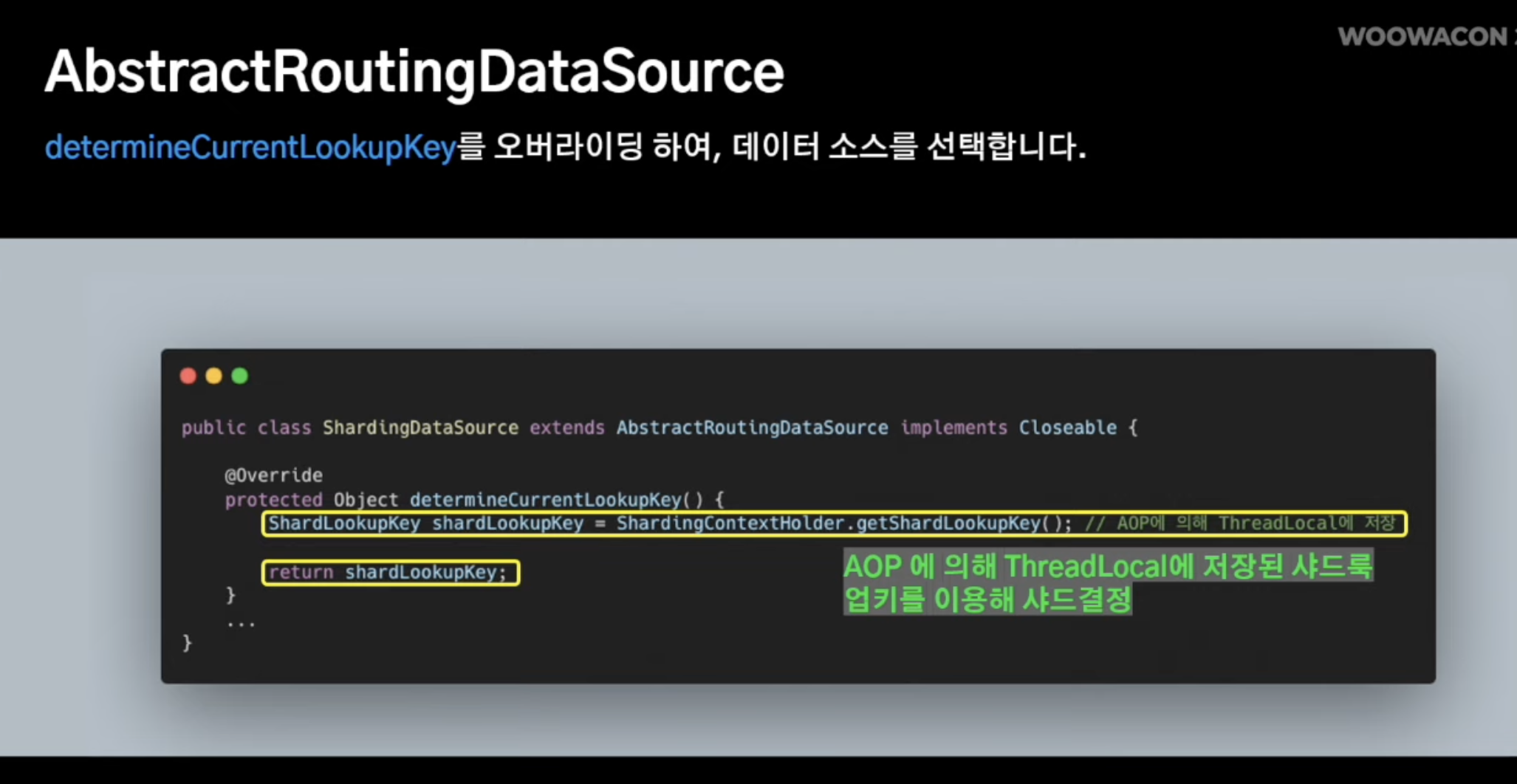
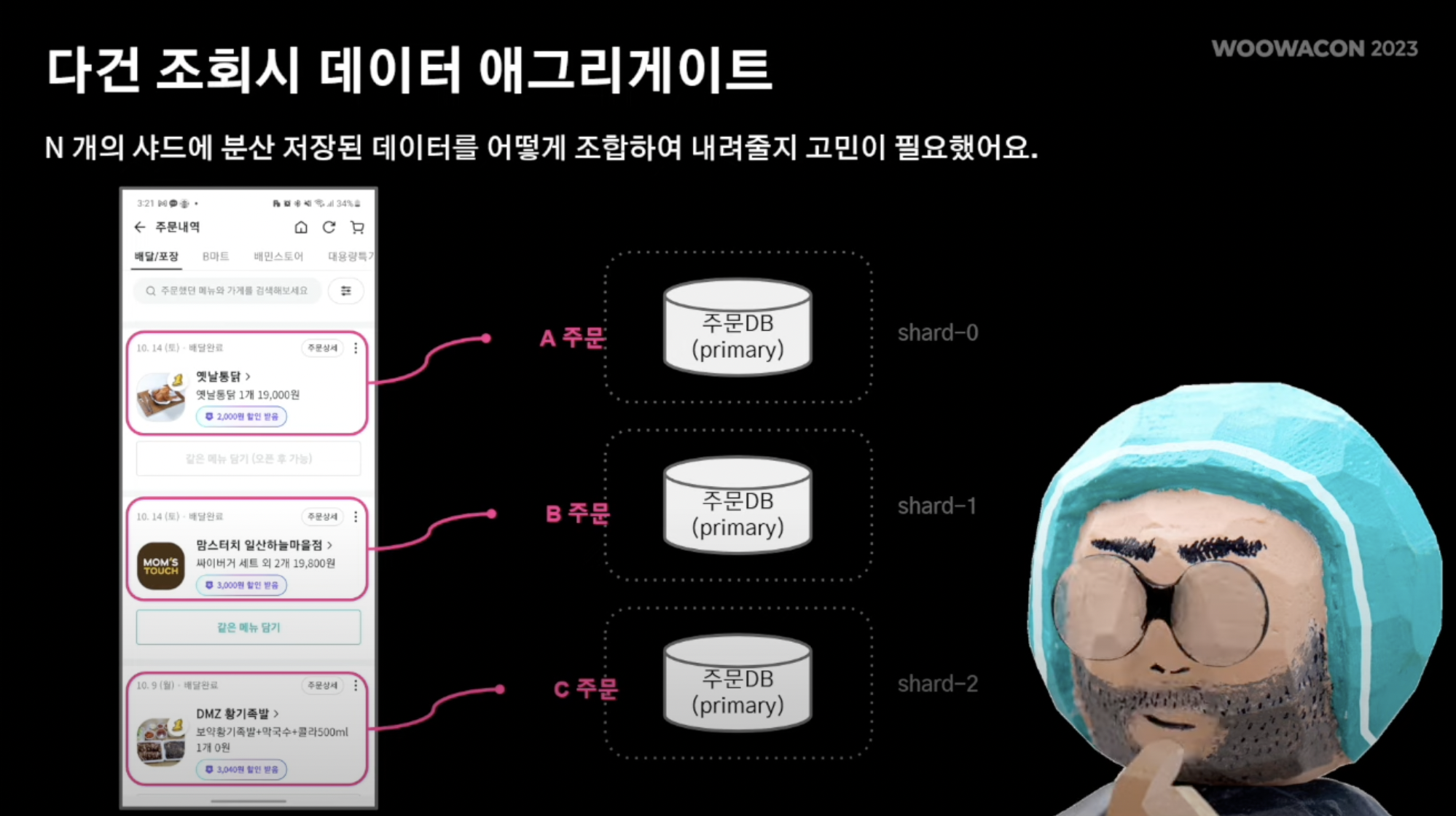
다건 조회 에그리게이션 로직 해결법
- 까먹음면 안된다!! 앞서 주 DB 샤딩 시, 흩어져 있는 테이블 간에 데이터 조회 시 데이터 에그리게이션을 어떻게 수행해야 하는지에 대한 이슈 역시 존재했다.
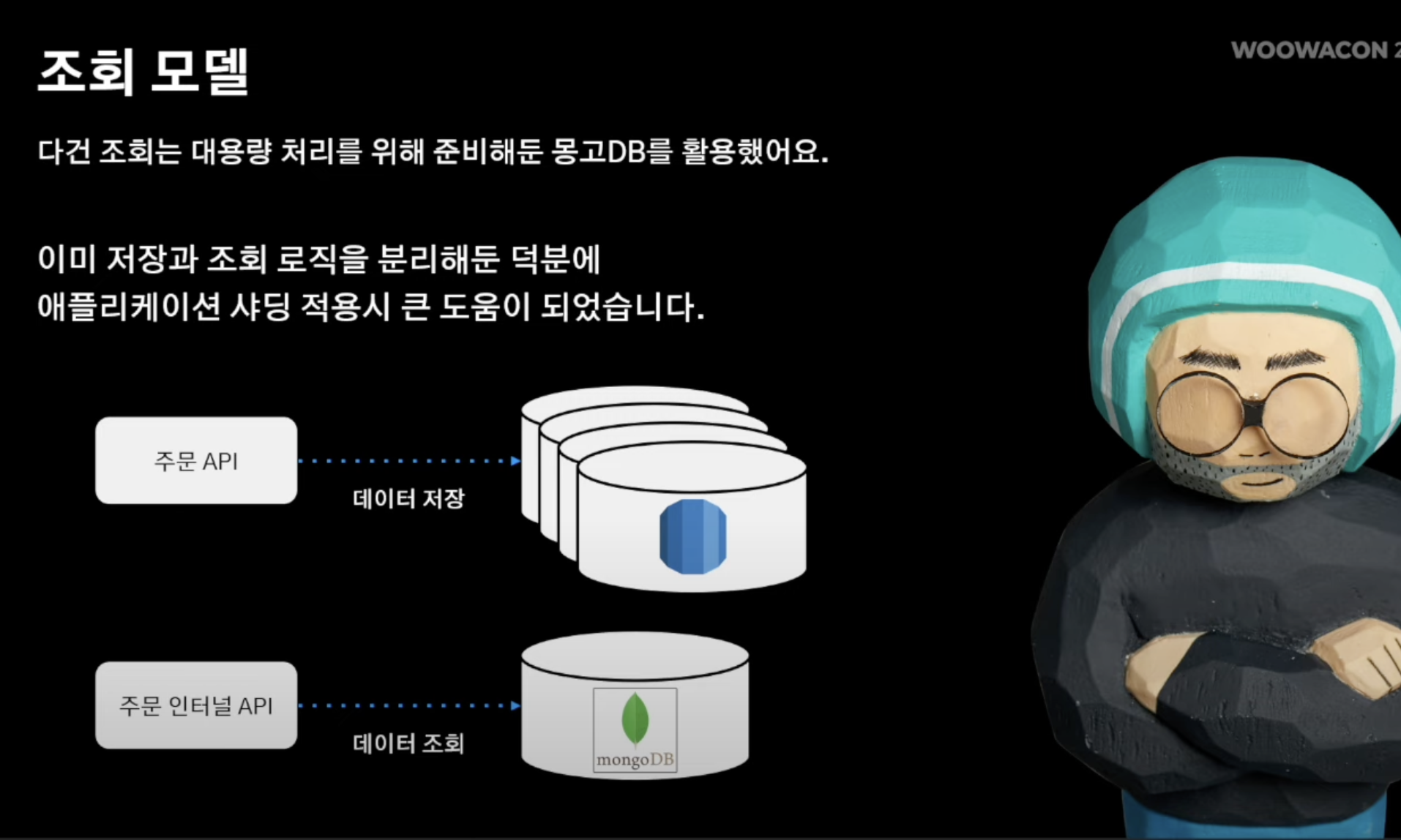
- 구체적으로 살펴보면 현재까지 내 주문 내역 조회 시 각각의 샤드에서 데이터 조회가 이루어진다.
- 이를 시간 순서에 맞게 목록에 serving 해줘야함.
- 위에서 몽고DB를 통해 조회 연산에 로직을 따로 처리했기에 다건 조회는 비관계형 데이터베이스를 활용해 손쉽게 해결이 가능해짐
- 따라서 위와같은 로직에서 쓰기 연산은 HA구성을 다중화 시켜 데이터를 고르게 분산 가능해짐

- 따라서 3번째 문제인 대규모 트랜잭션은 어플리케이션 샤딩을 적용시켜 쓰기 연산을 분산시켜 해당 문제 해소
4. 복잡한 이벤트 아키텍쳐

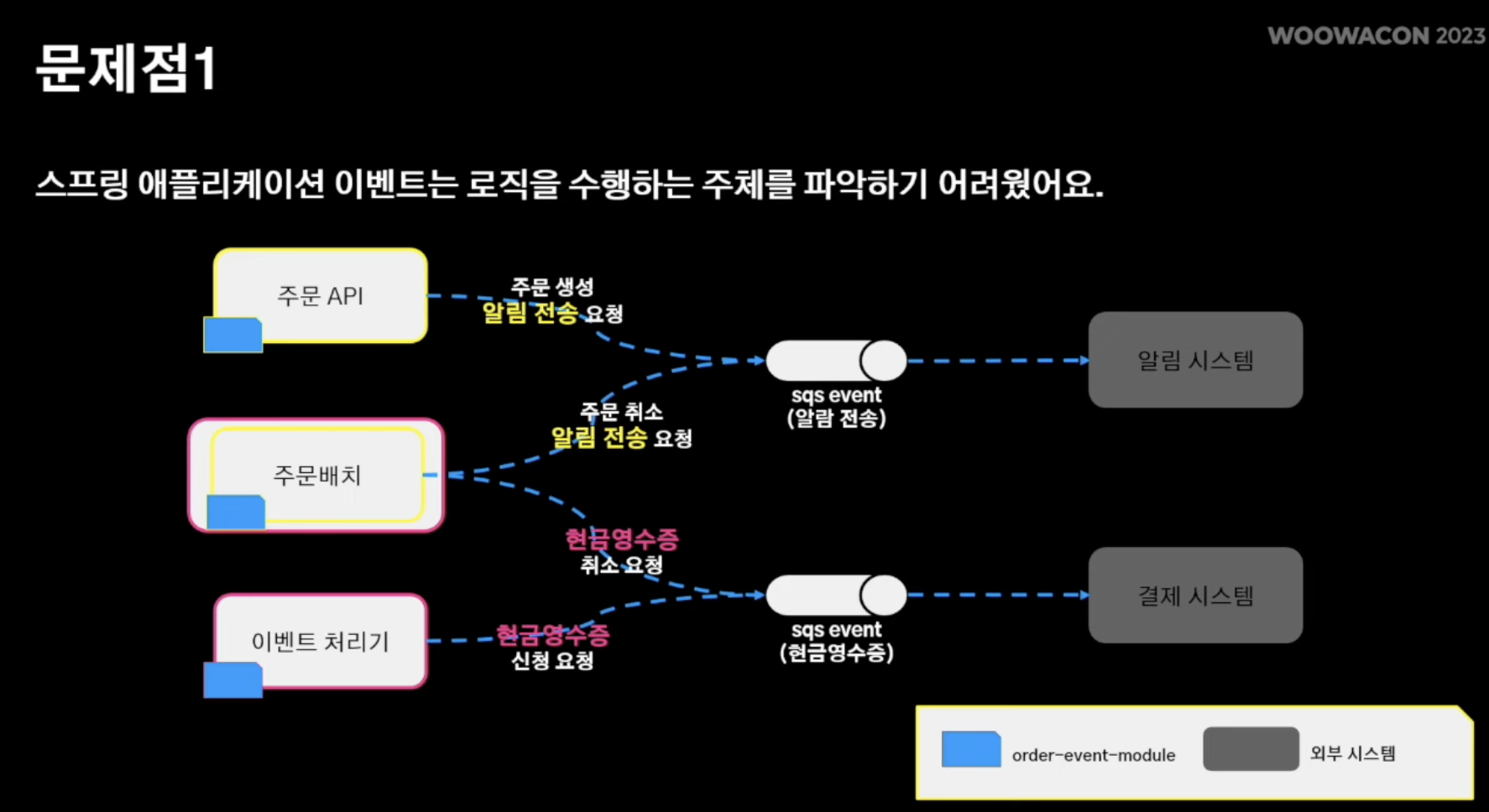
- 아무래도 주문 시스템이 핵심 로직이나 보니 많은 외부 시스템이 해당 주문 시스템을 많이 바라보고 있고 이벤트 발행 요청 역시 많음
- 이것은 규칙이 없는 무분별한 이벤트 발행으로 이루어짐
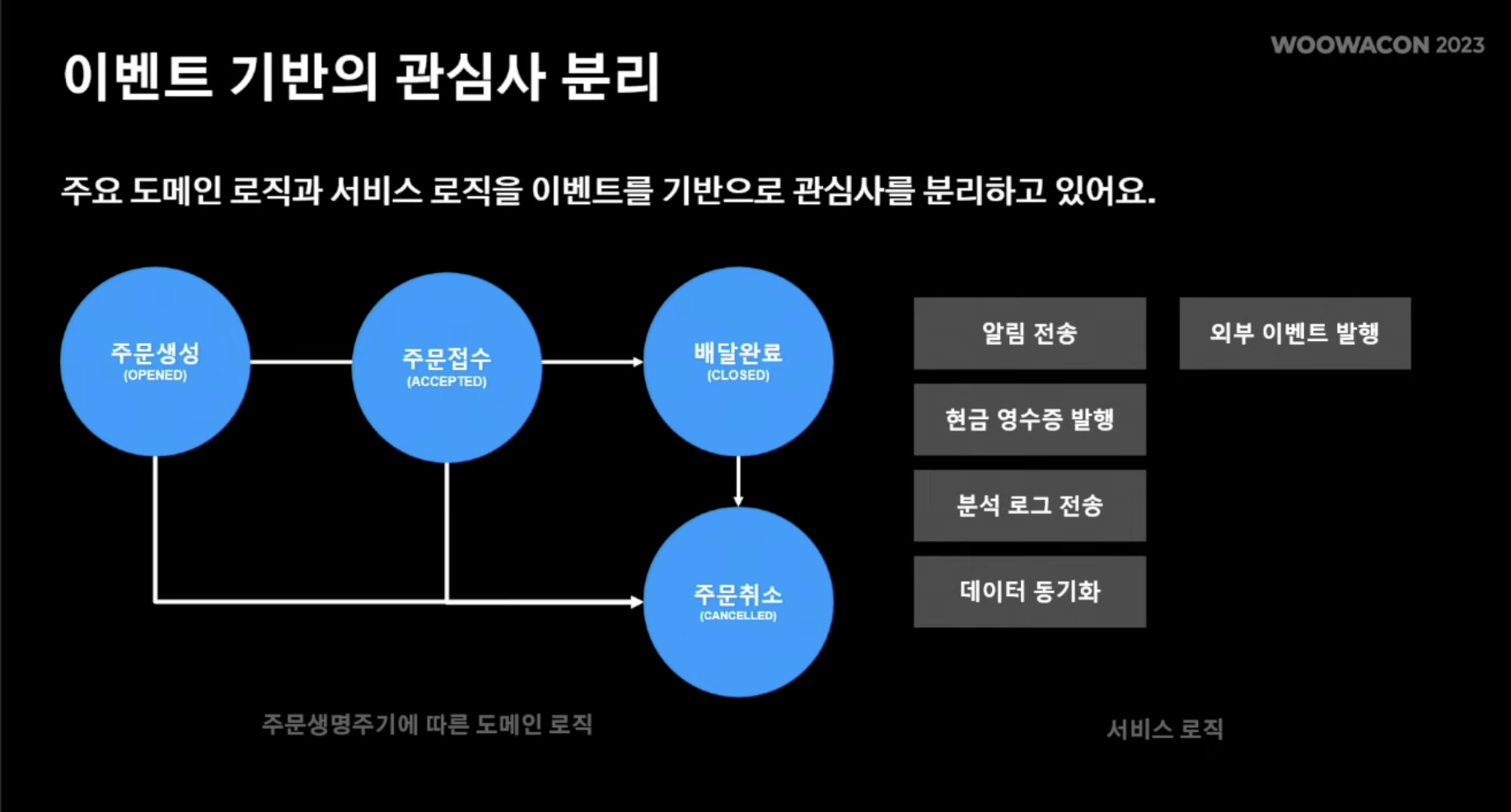
- 앞서 언급한 것처럼 주문 시스템은 주문 사이클이라는 형식으로 이루어지고, 기타 서비스 로직은 이벤트 기반으로 두어 도메인 로직과 서비스 로직을 경계 처리
- 하나의 예로 주문 생성 모듈을 들여다보자 (orderDomainService)
- orderDomainService는 주문 도메인을 수행
- 주문 도메인이 시작되면 앞서 사진에서 본 주문 생성/접수/취소/완료 이벤트가 라이프사이클에 맞는 도메인 로직 이벤트가 spring event에 발행됨
- 그러면 각 이벤트에 맞는 프로세스 서비스 레이어가 서비스 로직 처리
- 노란색 박스는 "알림 전송"을 수행하는 어플리케이션
- 빨간색 박스는 "현금 영수증 처리"를 수행하는 어플리케이션
- 하지만 이 경우 문제는 다수의 서비스를 처리할 떄 해당 서비스를 처리하는 주체의 어플리케이션이 달라짐에 따라 전체적인 프로세스를 파악하기 어려워짐
- 기능 추가 시 특정 어플리케이션에만 적용을 못하는 상황도 발생
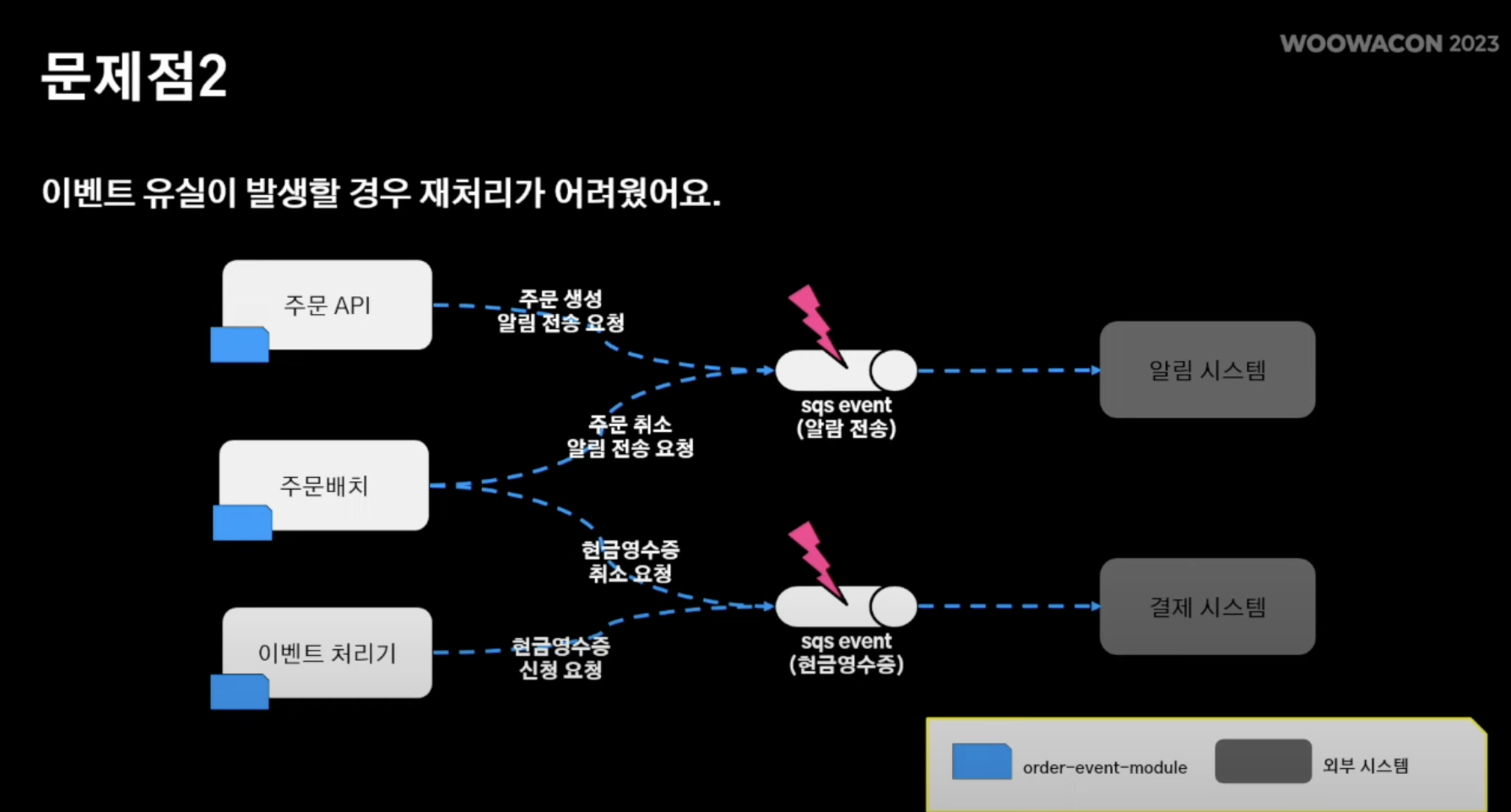
- spring event에 의존하다보니 서비스 로직 수행하기 위해 SQS에 문제 발생 시 도메인 로직 단에서 이벤트 재발행 수단이 뾰족히 없음
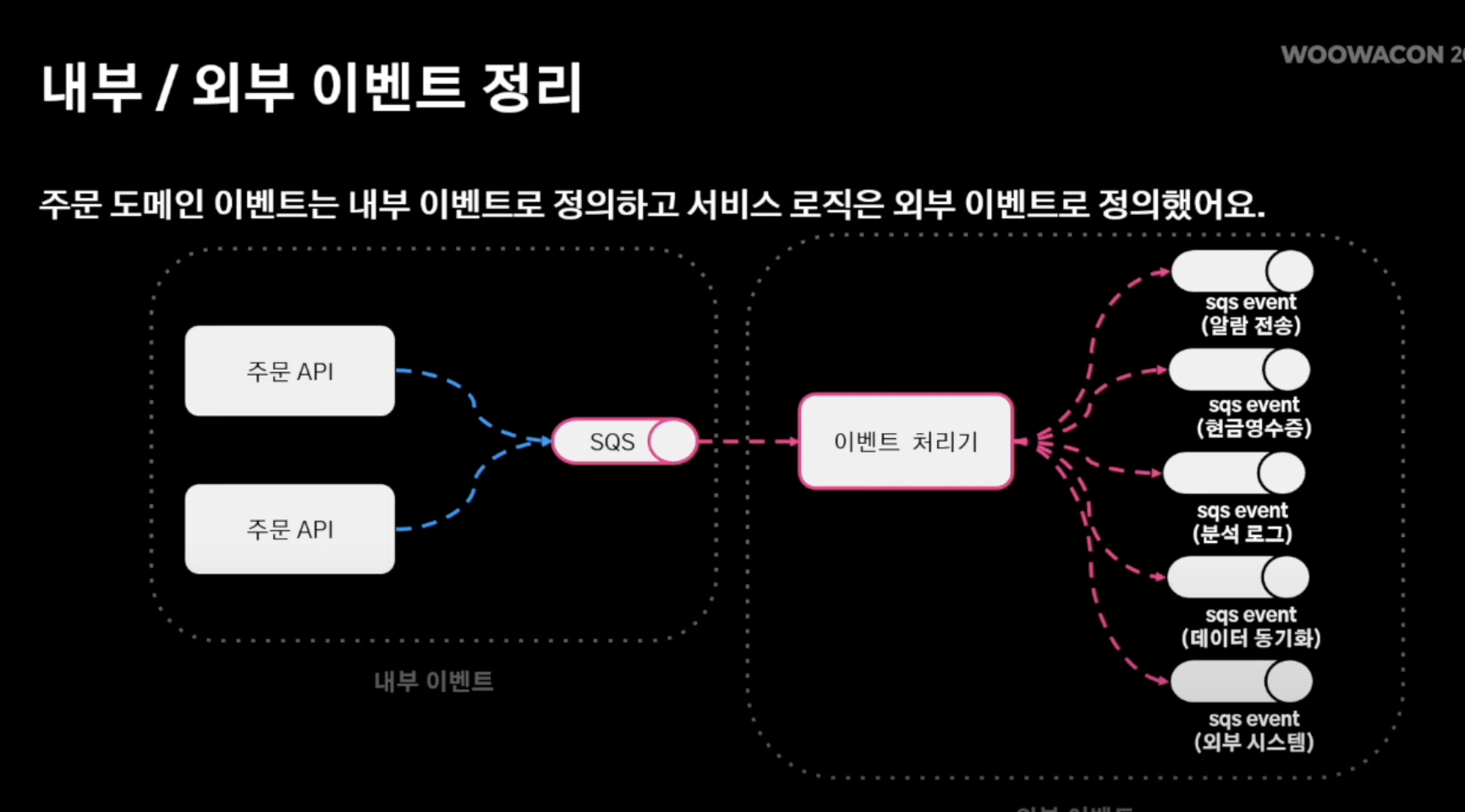
해결점: 내부/외부 이벤트 처리
- 주문 도메인 이벤트는 내부 이벤트로 정의
- 서비스 로직은 외부 이벤트로 정의
- 따라서, 주문 도메인 안에서의 도메인 로직은 SQS로 두고 해당 SQS를 바라보는 이벤트 처리기를 따로 두고 하위 서비스 로직은 이벤트 처리기 안에서 수행될 수 있도록 즉, 격리 환경을 구성
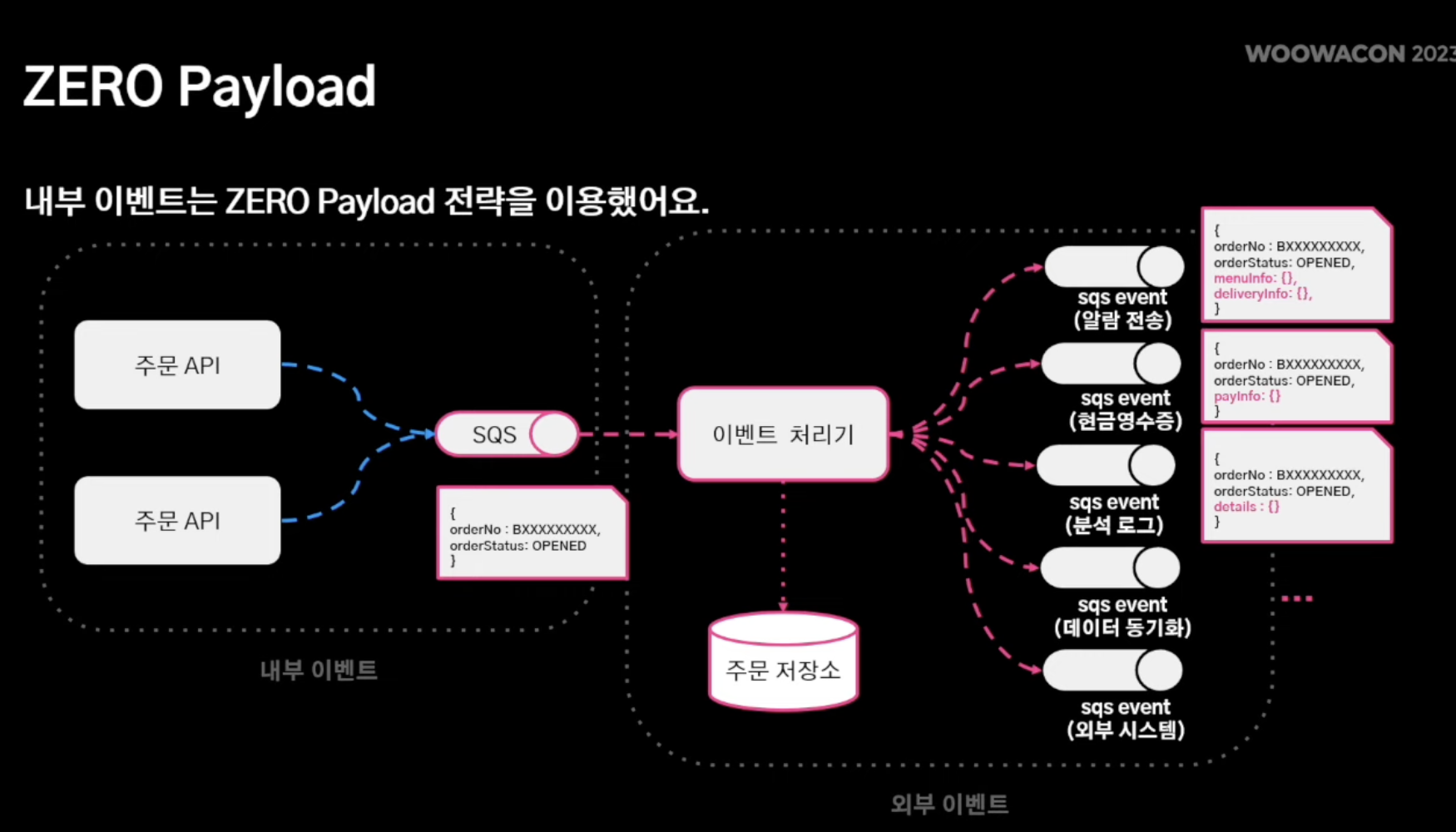
- 내부 이벤트 경우, ZERO Payload 전략 취함
- 이유: 내부 이벤트에는 애초에 서비스 로직 원천 차단
- 따라서 실질적으로 서비스 로직 처리가 필요한 부분은 이벤트 처리기가 주문 저장소에서 조회해서 특정 서비스 로직 (알람 전송, 현금 영수증 발행 등) 을 "그때 그떄" 처리하는 방식 채택
- NoSQL 방식을 가져가다 보니 큰 문제가 없다고 판단함
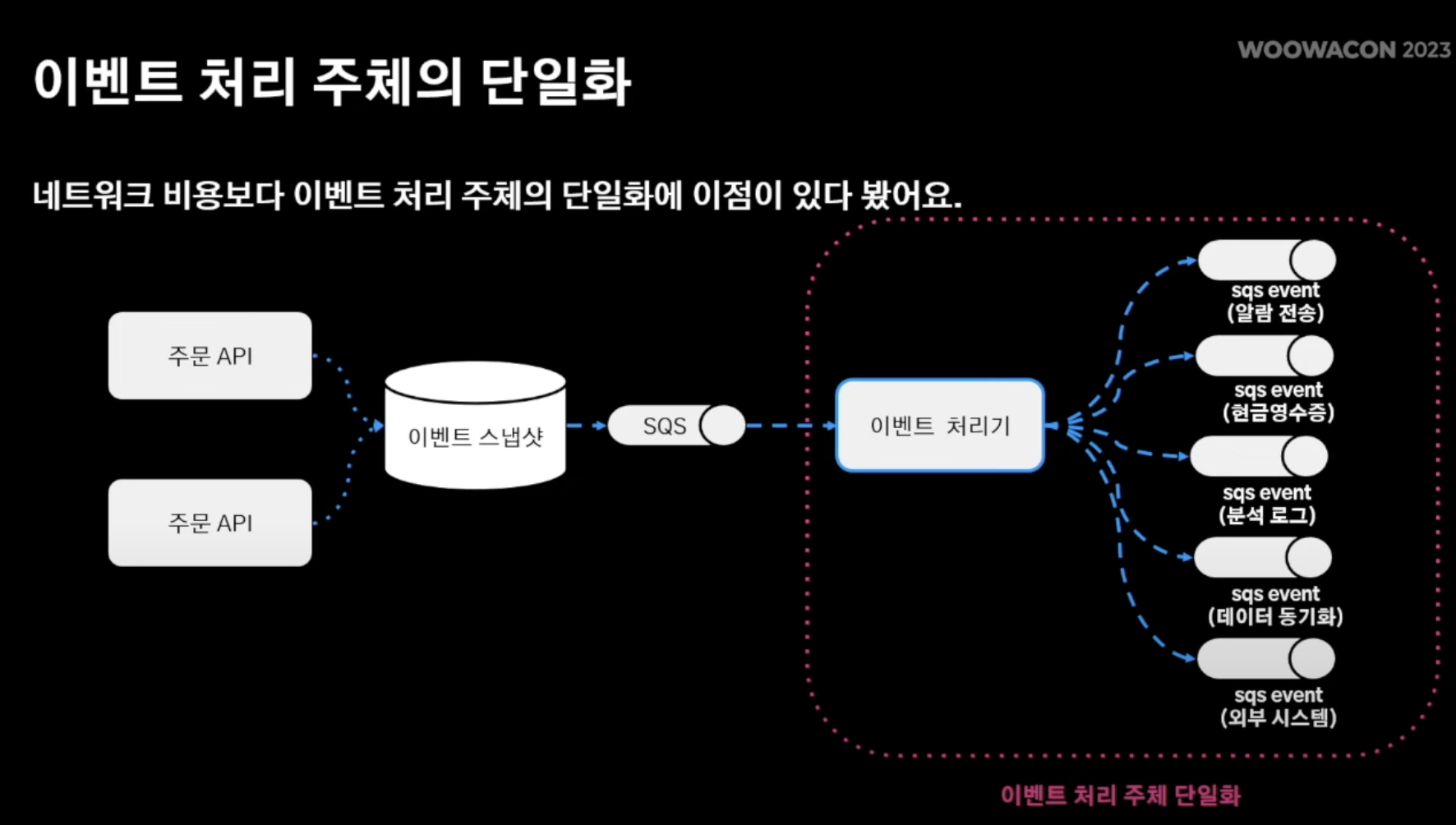
- 위처럼 서비스 로직을 처리하는 주체를 이벤트 처리기로 몰아줌
- 따라서 위에서는 어떤 어플리케이션이 어떤 서비스 로직을 처리하는지에 대한 복잡성이 존재했다면 위와 같은 구성에서는 특정 이벤트 처리기를 두고 해당 이벤트 처리기가 하위 서비스 로직을 처리하는 방식으로 채택할 수 있기에 (with NOSQL MongoDB) 훨씬 더 명확한 로직 처리가 가능해짐
- 물론 SQS를 사용함에 따라 네으워크 발행 비용이 들지만, 훨씬 더 효율적인 결정임
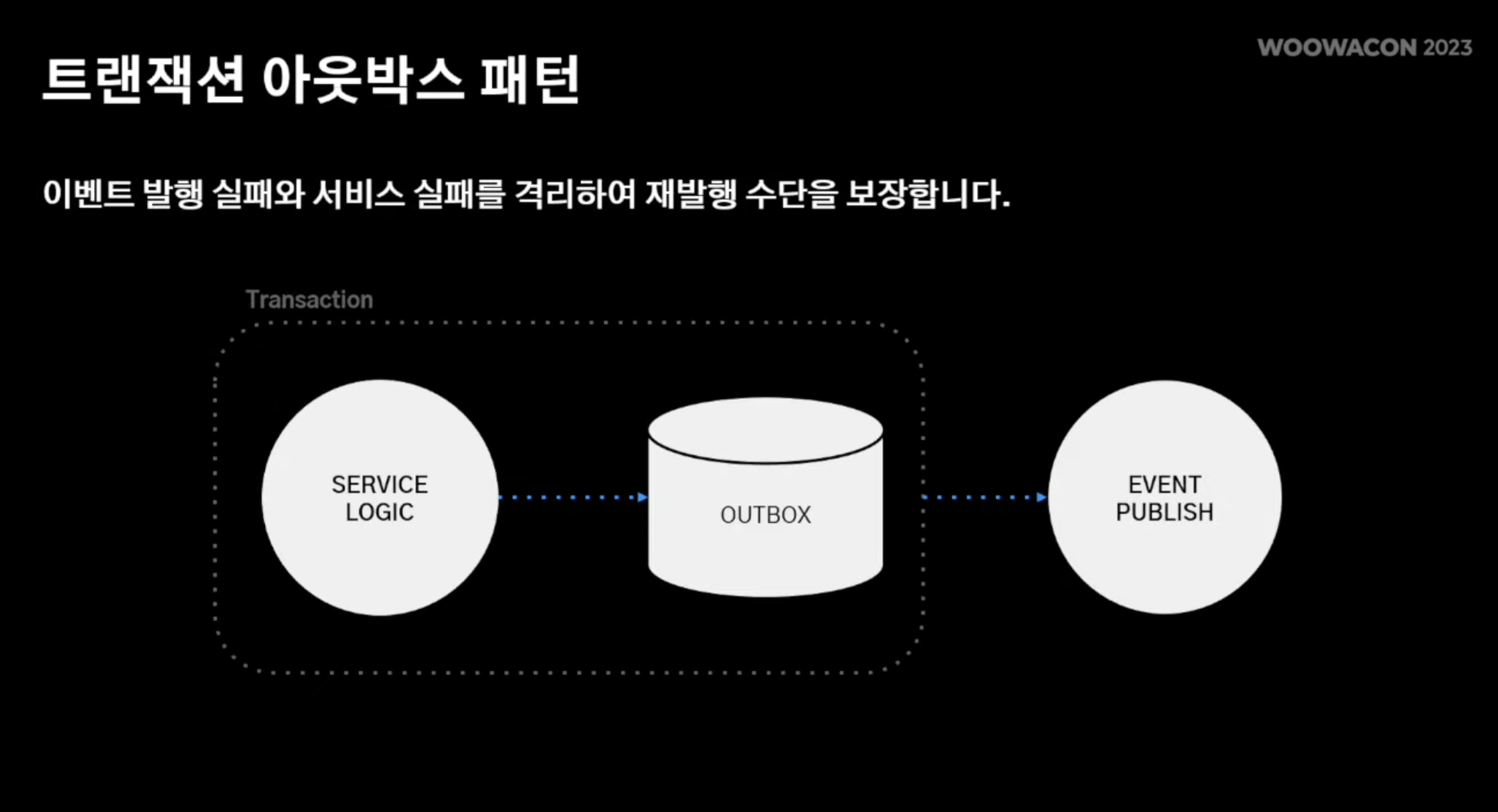
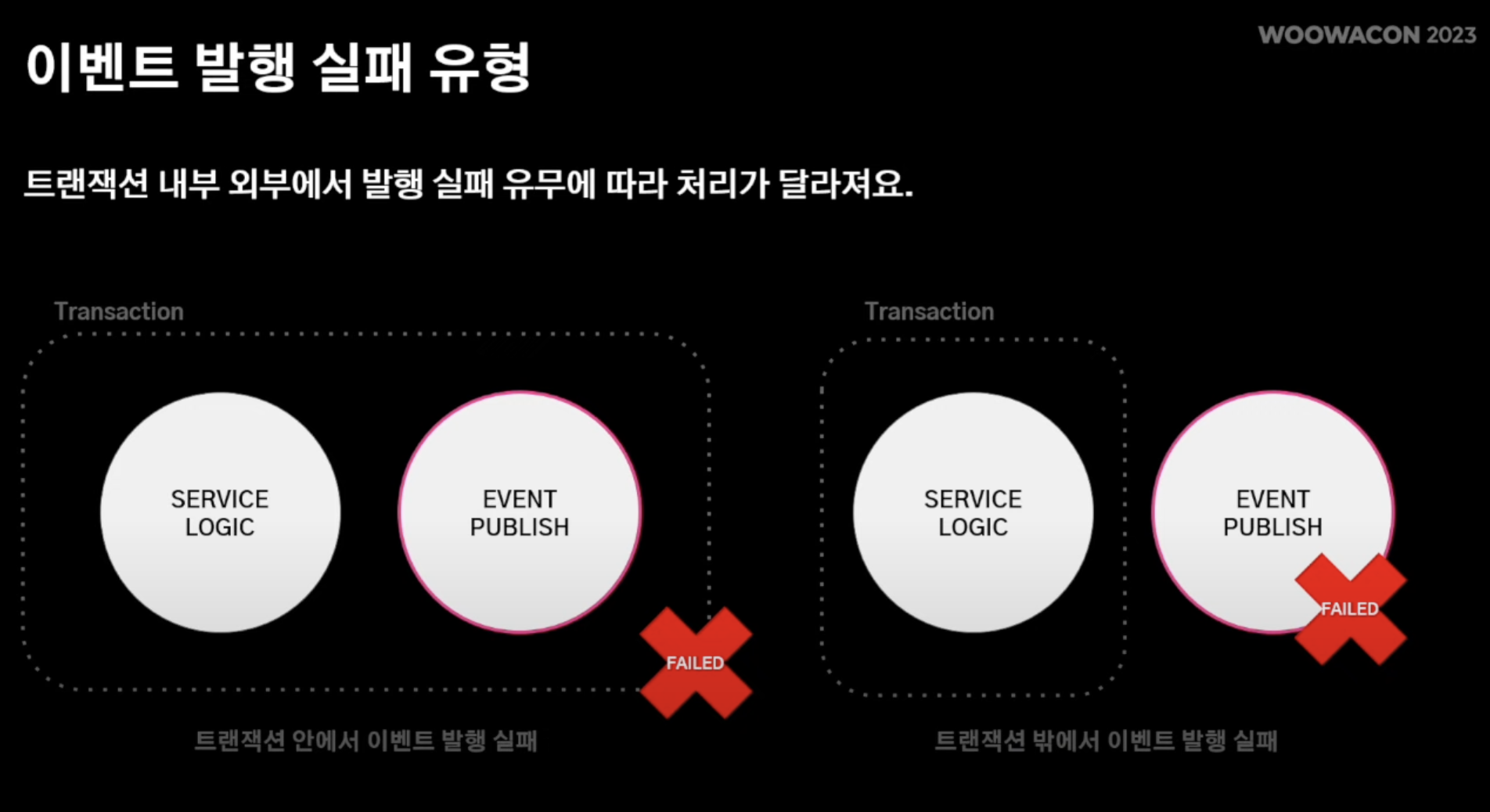
- 트랜잭션 실패 유형
- 트랜잭션 "내부"에서 도메인 로직 실패 -> 도메인 로직 자체가 실패되기에 한번에 처리 가능
- 트랜잭션 "외부"에서 서비스 로직 실패 즉, 도메인 로직은 성공했지만 서비스 로직이 실패 -> 서비스 일관성을 헤침
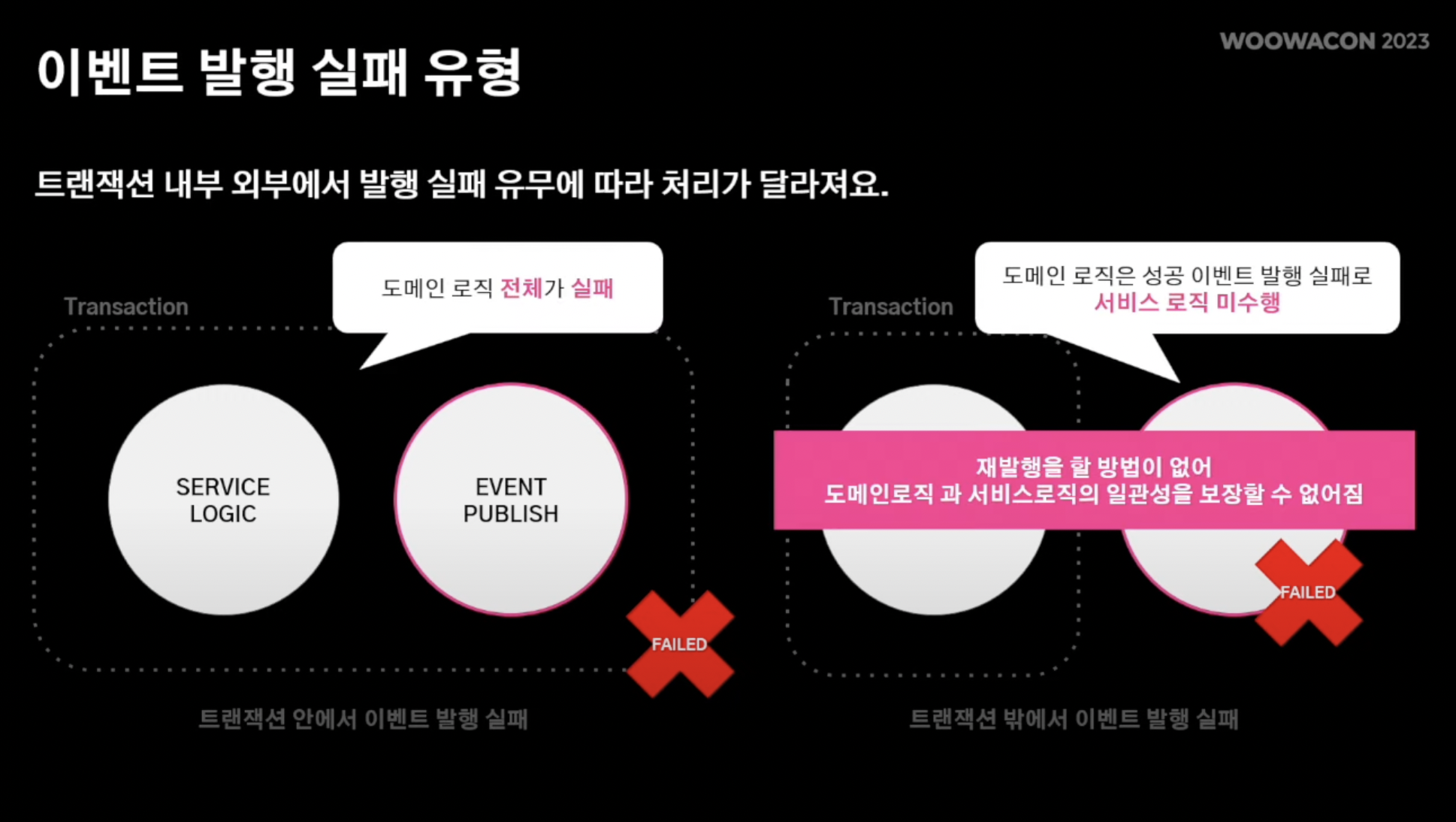
해결점: 트랜잭션 아웃박스 채택
- 트랜잭션 안에서 outbox entity를 둠
- 아웃박스 엔티티는 이벤트 로직을 처리하는 이벤트 처리기에 페이로드를 전달하는 주체
- 본격적인 이벤트를 도메인 로직에서 발행하기 "전" outbox에 기록
- 즉, 소실될 우려를 대비해 outbox entity에 미리 기록해두는 것
- 따라서 이벤트 발행이 실패되더라도 사전에 아웃박스에 기록해놨기에 이벤트가 유실이 되더라도 해당 이벤트 재발행이 가능해짐
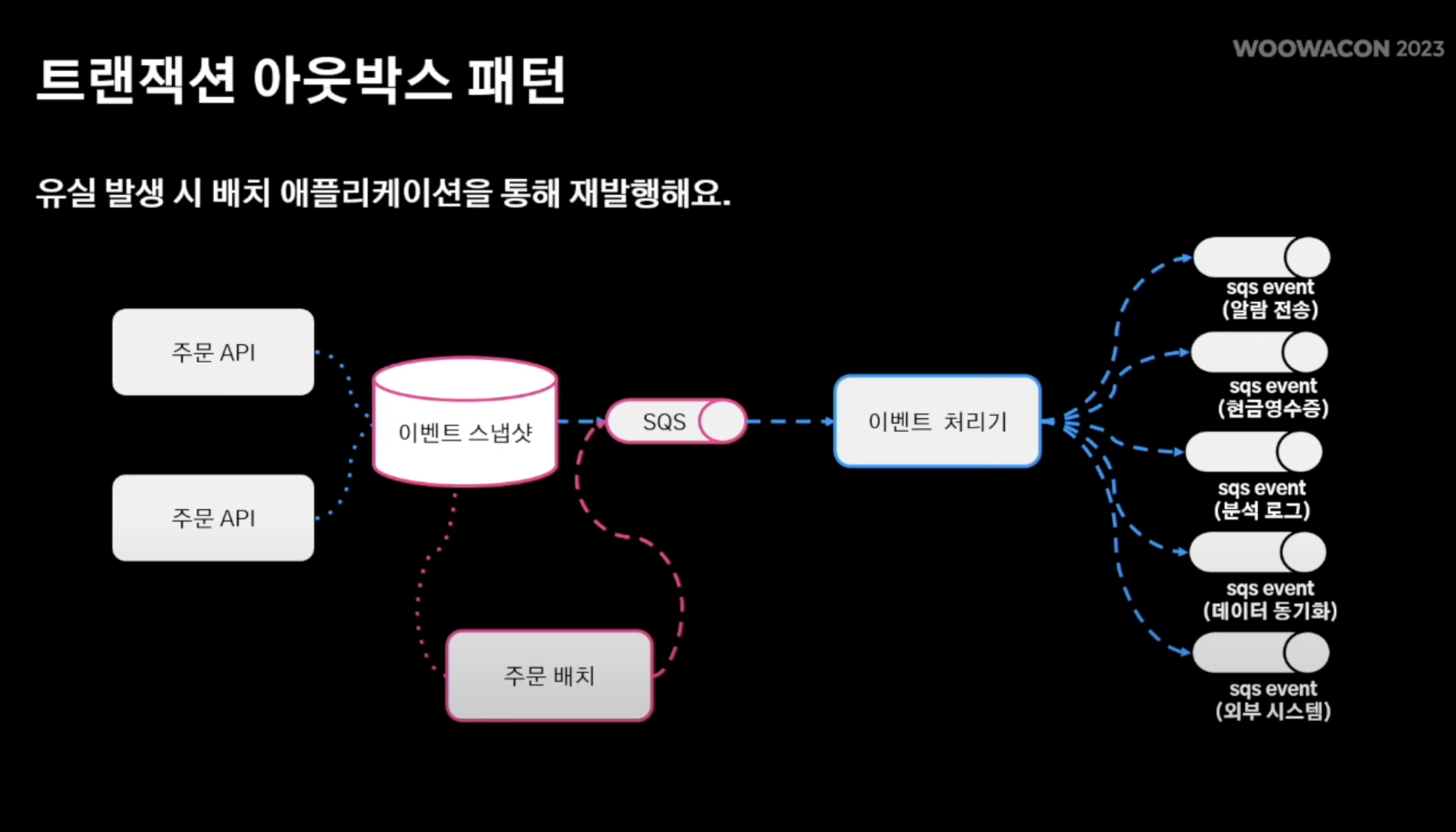
- 주문 배치를 둬 유실 발생 시 아웃박스 엔티티 즉, 트랜잭션 아웃박스 엔티티를 적용한 이벤트 스냅샷을 저장해놓은 테이블을 통해서 특정 키 혹은 특정 기간에 대해서 중복 발행은 될지 언정, 유실 방지를 꾀할 수 있게됨
느낀점
지금 현재 DB 스터디를 진행중인데, 스터디 하면서 나왔던 키워드들 -> 다중화, 샤딩, 레플리케이션, 정규화, 역정규화, Master<->Slave DB구조, 샤딩 시 JOIN에 대한 오버헤드 등 다양한 키워드들이 해당 영상에서 다뤄주어 매우 반갑고 실제 이론적으로 접한 내용이 현업에서도 동일하게 적용된다는 점이 굉장히 인상깊게 다가왔다.
특히 데이터베이스 샤딩 시 취한 의사결정 방식과 더불어 정규화된 RDBMS의 단점을 역정규화시킨 NoSQL DB구조를 채택해 조회 요청에 대한 로직 분리 및 성능 개선이 눈에 띄었다.
또한 도메인 로직부분과 도메인 로직 수행 시 필요한 부가적인 이벤트 로직을 MQ로 관리해 어플리케이션 단은 도메인 로직에만 집중이 가능하게 하고 더불어 해당 이벤트를 바라보고 있는 외부 시스템 역시 훨씬 더 분리된 환경 안에서 처리할 수 있도록 한 아키텍쳐 역시 인상 깊었다.

좋은 글 감사합니다! :)