Database Performance Tuning Guide
SQL 파싱과 최적화
구조적, 집합적, 선언적 질의 언어
SQL 은 structured, set-based, declarative 언어
procedural 과 다름
결과집합을 구조적, 집합적으로 선언하지만,
결과집합을 만드는 과정은 절차적일 수 밖에 없음
DBMS 에서 이러한 프로시저를 만드는 역할을 하는 것이 옵티마이저
SQL 최적화
- 과정
- SQL 파싱: SQL Parser 가 파싱을 진행
- 파싱 트리 생성: SQL 문의 개별 요소 분석, 트리 생성
- Syntax 체크: 문법 오류 확인. 키워드, 순서
- Semantic 체크: 의미상 오류 확인. 올바른 이름, 권한 유무
- SQL 최적화: Optimizer 가 실행경로를 수립
- 옵티마이저는 미리 시스템 및 오브젝트 통계를 수집
- 통계정보를 바탕으로 실행경로들을 생성, 비교 후 선택
- 로우 소스 생성: Row-Source Generator 가 프로시저로 포맷팅
- 옵티마이저가 선택한 실행경로를 실행 가능한 코드나 프로시저 형태로 포맷팅
SQL 옵티마이저
⚠️ 옵티마이저는 프로세스가 아니다. SQL 서버의 기능이다.
- 최적화 단계
- 실행 계획 후보군 생성
- Data Dictionary 에서 통계정보를 가져와 예상비용을 산정
- 최저 비용의 실행계획 선택
실행계획과 비용
- Execution Plan: SQL 실행경로 미리보기, 트리 구조
- 통계정보를 활용해 예상 비용을 계산하고, 최소 비용의 실행경로를 선택
EXPLAIN PLAN FOR
SELECT * FROM T
WHERE DEPTNO = 10
AND NO = 1;
SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY);옵티마이저 힌트
- 옵티마이저는 완벽하지 않음
- 옵티마이저 힌트를 통해 데이터 엑세스 경로를 바꿀 수 있음
- SELECT 뒤의 주석에 '+' 기호를 붙인다
- 힌트와 힌트 사이는 공백, 인자를 나열할 때에는 공백 혹은 ','
- 스키마명을 제외한 테이블명부터 명시
- ALIAS 를 지정했다면 반드시 ALIAS 를 사용
- 힌트 목록
- ⚠️ '--+...' 가 아닌 '/*+...*/'를 사용할 것, 줄바꿈 오류가 발생할 수 있음
- ⚠️ 힌트를 사용한다면 옵티마이저의 자율 판단이 없게, 빈틈 없이 기술하는 것이 좋다
-- 권장
SELECT /*+ INDEX(A 고객_PK) */
고객명, 연락처, 주소, 가입일시
FROM 고객 A
WHERE 고객ID = '000000008'// 아래의 라인이 모두 주석 처리됨
SQLStmt = "SELECT --+ INDEX(A 고객_PK) "
+ " 고객명, 연락처, 주소, 가입일시 "
+ "FROM 고객 A"
+ "WHERE 고객ID = '000000008'";SQL 공유 및 재사용
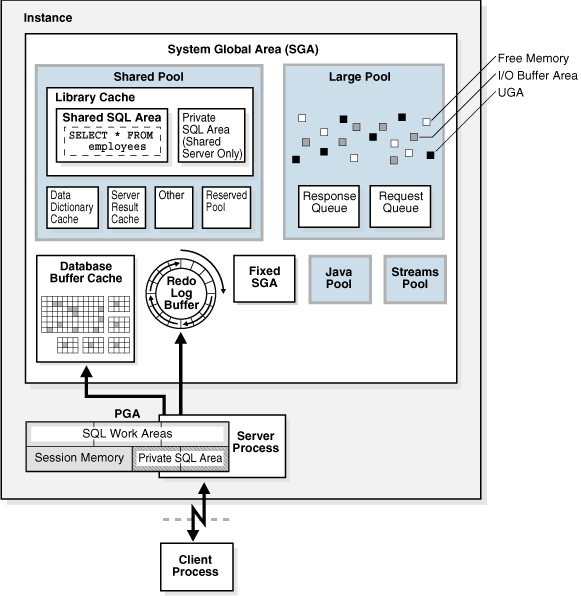
- SGA(System Global Area): 서버 프로세스, 백그라운드 프로세스의 공통 엑세스 캐싱을 위한 메모리 공간
- DB Buffer Cache: 데이터 블록을 메모리에 저장
- Shared Pool: SQL 문장과 실행계획, 데이터 딕셔너리 캐시 등 저장
- Library Cache: SQL 파싱 결과를 캐싱(정확히는 프로시저를 포함한 컴파일 결과)
- Data Dictionary Cache: 메타데이터 정보 캐싱
- Redo Log Buffer: 트랜젝션 로그 임시 저장. 복구 시 사용
- PGA(Program Global Area): 개별 서버 프로세스에 할당 되는 작업 공간
- SQL Work Area: 메모리를 많이 사용하는 작업들을 위한 공간
- Sort Area, Hash Area, Bitmap Merge Area
- SQL Work Area: 메모리를 많이 사용하는 작업들을 위한 공간
소프트 파싱 VS 하드 파싱
- 소프트 파싱: SQL 이 캐시에 있다면 곧바로 실행단계로 넘어감
(이름이 소프트 파싱인 이유: 간단한 파싱작업후 캐시를 확인함) - 하드 파싱: 캐시에 없으면 파싱, 최적화, 로우 소스 생성 단계를 모두 수행
- 대부분의 DB 작업은 I/O 이지만, 하드 파싱은 CPU 를 많이 소비함
- 무수히 많은 실행경로들을 도출하고 모두 효율성을 따져 실행계획을 결정함
- 이렇게 생성한 프로시저를 한번만 사용하는 것은 비효율 -> 캐시
바인드 변수의 중요성
- SQL 은 이름이 따로 없어 문장 그 자체가 이름이고,
따라서 캐싱하기에 비효율적 - 라이브러리 캐시에서 키 값이 SQL 문 그 자체
- 동작이 같은 쿼리라도 한 글자만 바뀌어도 캐싱이 안됨
- 자주 사용되는 WHERE 절 비교를 통한 조회도
비교값이 달라질 때 마다 다른 SQL 로 인식 - 바뀌는 부분을 변수로 해서 SQL 하나만 캐시에 저장하려면
바인드 변수를 사용
-- 프로시저 생성
CREATE OR REPLACE PROCEDURE SEARCH_EMP (
P_ENAME IN EMP.ENAME%TYPE,
P_RESULT OUT SYS_REFCURSOR
)
IS
BEGIN
OPEN P_RESULT FOR
SELECT EMPNO, ENAME, JOB, SAL
FROM EMP
WHERE ENAME = P_ENAME;
END;
/
-- 바인드 변수를 활용한 실행
VARIABLE RC REFCURSOR;
EXEC SEARCH_EMP('SMITH', :RC);
PRINT RC;
-- 라이브러리 캐시 확인
SELECT *
FROM V$DB_OBJECT_CACHE
WHERE TYPE = 'PROCEDURE';- ⚠️ JDBC 의 PreparedStatement 를 사용하면 PROCEDURE 를 개발자가 생성해서 최적화할 필요는 없다.
데이터 저장 구조 및 I/O 메커니즘
SQL 이 느린 이유
- 대부분 디스크 I/O 작업이 시간 측면에서 지배적
- CPU 가 외부 시스템과 데이터를 주고 받는 일은 상대적으로 매우 느림
- 프로세스는 I/O 작업이 끝날 때 까지 waiting 상태가 된다 (sleep)
데이터베이스 저장 구조
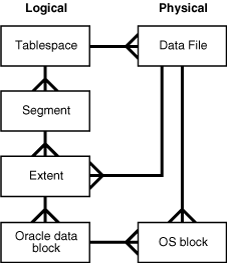
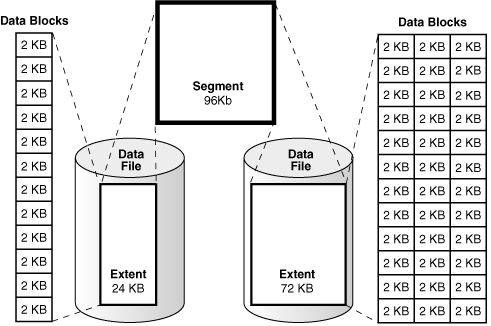
- 테이블 스페이스: 세그먼트를 담는 컨테이너
- 세그먼트: 테이블, 인덱스 처럼 데이터 저장공간이 필요한 오브젝트.
파티션 구조라면 파티션이, 그렇지 않으면 테이블 전체가 세그먼트- 익스텐트: 공간 확장 단위. 연속된 블록의 집합
하나의 익스텐트에는 같은 테이블의 블록만 저장
저장하다 공간이 부족하면 테이블 스페이스에서 익스텐트를 할당받음- 블록: 사용자가 입력한 레코드를 실제로 저장하는 공간
한 블록에는 같은 테이블의 레코드들만 저장- 로우: 레코드
- 블록: 사용자가 입력한 레코드를 실제로 저장하는 공간
- 익스텐트: 공간 확장 단위. 연속된 블록의 집합
- 세그먼트: 테이블, 인덱스 처럼 데이터 저장공간이 필요한 오브젝트.
⚠️ 논리적으로 같은 세그먼트에 할당된 익스텐트들은 물리적으로는 다른 데이터파일에 위치할 가능성이 높다
⚠️ 데이터파일의 접근을 분산시켜 성능 향상
⚠️ 동일한 익스텐트에 속한 블록들끼리는 논리적·물리적으로 연속된 위치에 저장
-- 세그먼트에 할당된 익스텐트 목록 조회 방법
SELECT OWNER, SEGMENT_TYPE, SEGMENT_NAME, TABLESPACE_NAME, EXTENT_ID, FILE_ID, BLOCK_ID, BLOCKS
FROM DBA_EXTENTS
WHERE OWNER = USER
ORDER BY SEGMENT_NAME, EXTENT_ID;블록 단위 I/O
- DBMS 는 블록 단위로 데이터를 읽고 쓴다
- 테이블과 인덱스 모두 마찬가지
-- 기본 블록 크기 확인 방법
SHOW PARAMETER BLOCK_SIZE;
SELECT VALUE FROM V$PARAMETER WHERE NAME = 'db_block_size';
-- 결과 예시 8192 - 8KB시퀀셜 액세스 VS 랜덤 액세스
- 시퀀셜 액세스
- 논리적 또는 물리적으로 연결된 순서에 따라 차례대로 블록을 읽음
- 인덱스의 리프 블록은 링크드 리스트 처럼 연결 되어 있음
- 인덱스와 달리 테이블은 연결이 없음
-> 세그멘트 헤더 맵에서 테이블별로 익스텐트 목록을 관리.
-> 이를 이용한 것이 Full Table Scan
- 랜덤 엑세스
- 논리적, 물리적 순서를 다르지 않고, 레코드 하나를 읽기 위해 한 블록씩 접근
논리적 I/O VS 물리적 I/O
- 디스크 I/O 가 성능을 결정하며, 자주 읽는 블록을 매번 디스크에서 읽는 것은 비효율
- 따라서 데이터 캐싱은 필수
DB 버퍼 캐시
- SGA 의 핵심 구성요소
- 디스크에서 읽은 블록을 캐싱함
- SGA 이기 때문에 다른 프로세스도 캐싱 효과를 본다
논리적 I/O VS 물리적 I/O
- 논리적 블록 I/O: SQL 처리 과정에서 발생한 블록 I/O 의 총량
- 물리적 블록 I/O: 디스크 블록 I/O
- 물리적 I/O 는 논리적 I/O 의 부분집합. hit 못하면 논리적=물리적
- Direct Path 방식을 제외하고 모든 블록은 DB 버퍼 캐시를 경유
-> HIT 에 실패한 디스크 I/O 를 제외하면, 대부분 메모리 I/O = 논리적 I/O
BCHR(Buffer Cache Hit Rate)
- BCHR = 캐시에서 곧바로 찾은 블록 수 / 총 읽은 블록 수
= (논리적 I/O - 물리적 I/O) / 논리적 I/O
= 1 - (물리적 I/O / 논리적 I/O) - 물리적 I/O = 논리적 I/O * (1 - BCHR)
- 물리적 I/O 는 통제 가능한 대상이 아니지만, 논리적 I/O 는 통제 가능한 대상
- BCHR 을 높이기 위해 물리적 I/O 를 줄이려면 논리적 I/O 자체를 줄여야함
- SQL 튜닝은 논리적 I/O 를 줄임으로써 물리적 I/O 를 줄이는 것
Single Block I/O VS Multiblock I/O
- Hit 에 실패한 데이터 블록은 I/O Call 을 통해 디스크에서 DB 버퍼캐시로 적재후 읽음
- Single Block I/O: 한번에 한 블록씩 요청해서 메모리에 적재
- 소량의 데이터를 읽을 때 효율적(인덱스)
- Multiblock I/O: 한번에 여러 블록씩 요청해서 메모리에 적재
- 대량의 데이터를 읽을 때 효율적(Full Table Scan)
- 대용량 테이블을 Full Scan 할 때 Multiblock I/O 단위를 크게 하면 좋음(sleep 횟수가 줄어든다)
- OS 의 I/O 단위도 따로 있고, 테이블 전체를 읽을 때는 Multiblock 단위를 OS 만큼 크게 하는게 좋다
- ⚠️ Multiblock I/O 방식으로 읽어도 익스텐트 경계를 넘지는 못함.
한번의 I/O 에는 같은 익스텐트만
Table Full Scan VS Index Range Scan
- Table Full Scan: 테이블 전체를 스캔해서 읽는 방식
- Sequential access + Multiblock I/O
- OLAP 에서 효과적
- Index Range Scan: 인덱스를 이용해서 읽는 방식
- Random access + Single Block I/O
- OLTP 에서 효과적
- ⚠️ 인덱스가 튜닝의 핵심이긴 하지만,
Table Full Scan 이 더 효과적인 경우도 있다
캐시 탐색 메커니즘
- DB Buffer Cache 는 해시 구조로 관리
- 찾고자 하는 블록 번호의 해시값을 구하고
- 해당하는 해시 체인을 탐색(버퍼 헤더로 구성되어 있음, 블록의 메타 데이터)
- (Hit 가정)찾은 버퍼 헤더를 이용해서 실제 버퍼 블록을 찾아감
메모리 공유자원에 대한 액세스 직렬화
- 블록 정합성 문제: 하나의 버퍼 블록에 두 개 이상의 프로세스가 동시에 접근
- 직렬화가 필요하다
- 캐시 버퍼 체인 래치(Latch): DB 버퍼 캐시에 직렬화 기능을 지원해줌
- 해시 체인을 스캔하는 동안 체인 구조 변경을 막는다
- 체인에 Lock 을 걺
- 모든 SGA 의 캐시에는 래치가 있음
- 버퍼 Lock
- 체인 뿐만 아니라 버퍼 블록 자체에도 직렬화 메커니즘 존재
- 버퍼 헤더에 Lock 을 걺
- Lock 이 많아서 캐시 I/O 도 빠르지 않을 수 있음
- 캐시 경합을 줄이려면 논리적 I/O 를 줄이자

백엔드 개발자 지망생입니다.