
본 포스트는 카카오 테크 캠퍼스 1기에서 제공하는 패스트캠퍼스 강의에서 배운 내용을 정리하였습니다.
1주차 동안 java 기초강의와 중급강의 1장을 들었다.
기본적으로 알고있는 내용이였지만, 헷갈리거나 확실히 몰랐던 내용들 위주로 블로그에 정리하기로 하였다.
다음 주차부터는 주차별 정리보단, 기술별, 주제별로 글을 포스트하는게 보는사람도, 스스로도 좋을거 같다.
2, 8, 16진수
설명
2, 8, 16진수의 개념과 그 표현방법은 기본적으로 알고 있을거라 생각한다.
자바에서는 2진수를 0b(또는 0B), 8진수를 0, 16진수를 0x(또는 0X)를 앞에 붙여 표현한다.
int binaryNum = 0b0101; // 1*2^2 + 1*2^0 = 5
int octalNum = 0171; // 1*8^2 + 7*8^1 + 1*8^0 = 121
int decimalNum = 0x89; // 8*16^1 + 9*16^0 = 137
System.out.println(binaryNum); //5
System.out.println(octalNum); //121
System.out.println(decimalNum); //137문자세트 및 인코딩
문자세트
문자를 숫자로 변환한 값의 세트
ex): ASKII code, UNICODE
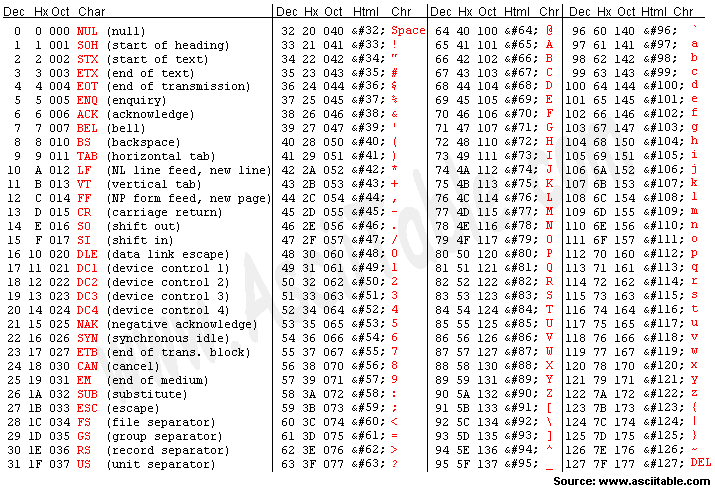
아스키코드
설명
아스키 코드는 알파벳과 숫자 특수 문자등을 1바이트에 표현하는데 사용하는 대표적인 문자세트이다. 1바이트로 구성되어 있는 아스키 코드는 8비트(==1바이트) 중 7개의 비트만 사용한다. 나머지 1비트는 Parity Bit이라고 불리는 오류 체크를 위한 비트로 통신 에러 검출을 위한 용도로 비워두었기 때문이다. Parity Bit를 제외한 7개의 비트 중 1의 개수가 홀수면 1, 짝수면 0으로 하는 식의 패리티 비트를 붙여서, 전송 도중 신호가 변질된 것을 수신측에서 검출해낼 수 있도록 하였다.
위 설명중 패리티 비트는 옛날에 방식이다.
gpt chat에게 물어본 결과 현재는 아래와 같다고 한다.
아스키 코드는 영문 알파벳을 사용하는 대표적인 문자세트가 맞습니다. 하지만, 1바이트로 구성되어 있는 아스키 코드는 8비트(==1바이트) 중 7개의 비트만 사용하며, 나머지 1비트는 Parity Bit가 아닌, 보통 0으로 채워져 있습니다. Parity Bit는 통신 에러 검출을 위한 용도로 사용되긴 했지만, 아스키 코드에는 적용되지 않습니다. Parity Bit를 제외한 7개의 비트 중 1의 개수가 홀수면 1, 짝수면 0으로 하는 식의 패리티 비트를 붙여서, 전송 도중 신호가 변질된 것을 수신측에서 검출해낼 수 있도록 하는 방식이 있었습니다. 하지만, 현재는 대부분의 통신 장비에서 에러 검출을 위한 CRC 방식 등이 사용되며, 패리티 비트는 거의 사용되지 않습니다.
즉 현재는 대부분의 통신 프로토콜이 오류 검출 및 수정 기능을 제공하기 때문에 패리티 비트는 거의 사용되지 않는다고 한다.
유니코드
설명
유니코드(Unicode)는 전 세계의 모든 문자를 컴퓨터에서 일관되게 표현하고 처리하기 위한 국제표준 문자셋이다.
이는 기존의 문자셋인 ASCII, ISO-8859 등이 영어와 유럽언어만을 지원하는 제한적인 문자셋이었다는 문제점을 해결하기 위해 제정되었다.
유니코드는 다양한 언어와 문자체계를 지원하기 위해 1바이트에서 4바이트까지 다양한 크기의 코드 포인트를 사용한다.
이를 통해 전 세계의 모든 문자를 표현할 수 있다. 유니코드에서는 한글, 중국어, 일본어와 같은 아시아권 문자부터 아랍어, 히브리어와 같은 우리나라에서는 쉽게 접하지 못하는 언어들까지 모두 지원한다.
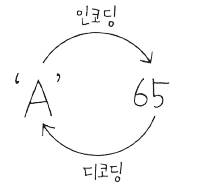
인코딩
인코딩
인코딩(Encoding)은 컴퓨터에서 텍스트 데이터를 이진 데이터(바이너리 데이터)로 변환하는 과정
디코딩
디코딩(Decoding)은 이진 데이터를 텍스트 데이터로 변환하는 과정
종류
-
UTF-8
UTF-8은 가변 길이 문자 인코딩 방식이다.
UTF-8은 1바이트에서 4바이트까지 다양한 길이의 코드 포인트를 사용하여 전 세계의 모든 문자를 표현할 수 있다.
ASCII 문자는 1바이트로 표현하고, 한글과 같은 다국어 문자는 3바이트로 표현한다.
UTF-8은 유니코드의 가장 일반적인 인코딩 방식이며, 인터넷에서도 널리 사용된다.
-
UTF-16
UTF-16 또한 유니코드의 인코딩 방식이며, 고정 길이 문자 인코딩 방식이다.
UTF-16은 2바이트 또는 4바이트로 구성된 코드 포인트를 사용하여 문자를 표현한다. 기본적으로 모든 문자가 2바이트로 표현되지만, SMP에 속한 문자는 4바이트로 표현된다.
SMP와 하위인코딩 문제
-
SMP
Supplementary Multilingual Plane은 유니코드(Unicode)에서 제공하는 문자 집합 중 하나로, 0x10000(65,536)부터 0x10FFFF(1,114,111)까지의 문자를 포함한다.
이 영역은 Basic Multilingual Plane(BMP) 이외의 문자들을 포함하고 있으며, 주로 이모지, 한자, 히브리어, 아랍어, 한글 등을 포함하고 있다
SMP은 BMP에 비해 상대적으로 적은 문자를 포함하지만, 이 모든 문자를 BMP와 같은 방식으로 처리할 경우 코드 유닛이 4바이트를 차지하게 된다.
이는 메모리 공간과 처리 속도에서 비효율적일 수 있기 때문에, 보통 UTF-16 인코딩에서 SMP의 문자를 처리할 때는 surrogate pair라는 방식을 사용한다.
-
Surrogate Pair
Surrogate pair는 2개의 2바이트 코드 유닛을 사용하여 4바이트 문자를 표현하는 방식이다.
첫 번째 코드 유닛은 0xD800에서 0xDBFF 사이의 값 중 하나를 사용하고, 두 번째 코드 유닛은 0xDC00에서 0xDFFF 사이의 값 중 하나를 사용한다.
이렇게하면 SMP의 문자를 2개의 코드 유닛으로 표현할 수 있다.
-
하위인코딩 문제
하위 인코딩 문제는 UTF-16에서 SMP에 속한 문자를 인코딩 할떄 surrogate pair방식에서 문제가 생기는 걸 의미한다.
위에서 말했듯이 2개의 2바이트 코드 유닛을 사용할떄, 2개의 코드 유닛이 쌍(pair)을 이루어야 하며, 이 순서가 바뀌게 되면 잘못된 문자를 표현할 수 있다.
또한, 이 surrogate pair 방식을 올바르게 사용하지 않거나 처리하지 않을 경우 하위 인코딩 문제가 발생할 수 있다.
이러한 하위 인코딩 문제는 UTF-16을 다룰 때 주의해야 할 문제 중 하나이다.
이를 방지하기 위해서는 surrogate pair 방식을 올바르게 처리하는 코드가 필요하며, 최신 버전의 프로그래밍 언어나 라이브러리는 이러한 문제를 해결하기 위한 함수나 메서드를 제공하고 있다.
하위인코딩, 왜 하필 UTF-16에서만?
=> UTF-16은 고정 길이방식이기 때문이다!
고정적으로 문자 표현을 2바이트로 사용하기 때문에, SMP의 문자를 처리할 때 surrogate pair 방식을 사용한다.
하지만 이 surrogate pair 방식에서 일부 구현에서는 하위 인코딩을 허용하면서 다양한 문제를 일으키게 된다.
예를 들어, 첫 번째 코드 유닛으로 0xDC00에서 0xDFFF 사이의 값을 사용하는 등의 문제가 있다.
반면에 UTF-8은 가변 길이 인코딩 방식으로, 1바이트에서 4바이트까지 다양한 길이의 코드 유닛을 사용한다.
SMP의 문자를 표현할 때에도 4바이트로 인코딩하며, 이 때 surrogate pair 방식을 사용하지 않기 때문에 하위 인코딩 문제가 발생하지 않는다.
Java Switch Expression
설명
Java 12부터 Switch Expression이라는 새로운 기능이 추가되어, switch문을 좀 더 간결하게 사용할 수 있게 되었다. 이전의 switch문과는 다르게, 값을 반환할 수 있는 형태로 사용할 수 있다!
Switch Expression의 기본 문법은 다음과 같다.
result = switch (value) {
case value1, value2, value3 -> result1;
case value4 -> result2;
case value5 -> result3;
...
default -> useless_result;
};원래 switch문과 크게 다른건 없고, 화살표(->)를 통해서 조건과 결과를 이어주면 된다.
간단하게 쉼표(,)로 조건을 구분하고 나열할 수 있다.
또한, Switch Expression에서는 yield 키워드를 사용하여 값을 반환할 수 있다.
public static void main(String[] args) {
int month = 3;
int day = switch (month) {
case 1, 3, 5, 7, 8, 10,12 -> {
System.out.println("한 달은 31일입니다.");
yield 31;
}
case 4,6,9,11 -> {
System.out.println("한 달은 30일입니다.");
yield 30;
}
case 2 ->{
System.out.println("한 달은 28일입니다.");
yield 28;
}
default->{
System.out.println("존재하지 않는 달 입니다.");
yield 0;
}
};
}
//출력 결과는 "한 달은 31일 입니다" 가 출력된다. 위 경우 month=3이므로 "한 달은 31일 입니다"가 출력되고,
31을 yield하기 떄문에 day=31이 된다.
Data 영역
설명
데이터 세그먼트는 컴퓨터 프로그램의 메모리 구조 중 하나로, 다양한 종류의 데이터가 저장되는 영역.
데이터 세그먼트에는 크게 스택 영역, 힙 영역, 데이터 영역, 코드 영역이 있다.
영역의 구분
스택 영역
스택 영역은 함수 호출 시 생성되는 지역 변수, 함수의 매개변수등이 저장되는 메모리 영역이다.
스택은 메모리의 높은 주소에서 낮은 주소로 증가하는 방향으로 할당된다.
함수가 호출되면 스택 프레임이 생성되어 스택에 할당되고, 함수가 종료되면 스택 프레임이 제거된다.
재귀 함수 호출과 같은 경우 스택의 깊이가 깊어져 스택 오버플로우가 발생할 수 있다.
힙 영역
힙 영역은 프로그램 실행 중 동적으로 할당되는 메모리 영역이다.
우리가 객체를 동적할당하면 힙 영역에 할당된다.
힙은 스택과는 달리 메모리의 낮은 주소에서 높은 주소로 할당된다.
프로그램이 실행되는 동안 필요한 만큼 메모리를 할당하고, 사용이 끝난 후 해제해야 한다. => Java에 경우는 가비지콜렉터가 자동 관리해줌.
동적 메모리 할당을 통해 필요한 메모리만 사용할 수 있어 효율적인 메모리 관리가 가능하다.
데이터 영역
데이터 영역은 전역 변수와 정적 변수를 저장하는 메모리 영역이다.
전역 변수와 정적 변수는 프로그램이 실행될 때 초기값이나 0으로 초기화되며, 전역 변수는 프로그램 전체에서 공유된다.
프로그램의 시작과 함께 할당되며 프로그램이 종료되면 소멸한다.
=> Java는 전역 변수 개념 없음
코드 영역(메서드 영역)
코드 영역은 실행 파일에 포함된 기계어 코드가 저장되는 메모리 영역이다.
우리가 에디터나 다른 IDE 에서 코드를 작성한 후,
그 코드를 컴파일하여 실행 파일을 만들때 코드 영역에 우리가 작성한 코드가 기계어로 저장된다.
그리고 프로그램이 실행될 때, 코드 영역에 저장된 기계어 코드가 CPU에 의해 실행된다.
이 영역은 컴파일 타임에 결정되고 중간에 코드를 바꿀 수 없게 Read-Only 로 지정돼있다.
메서드의 로직이 들어가는 영역이기도 해서 메서드 영역이라고도 한다.
