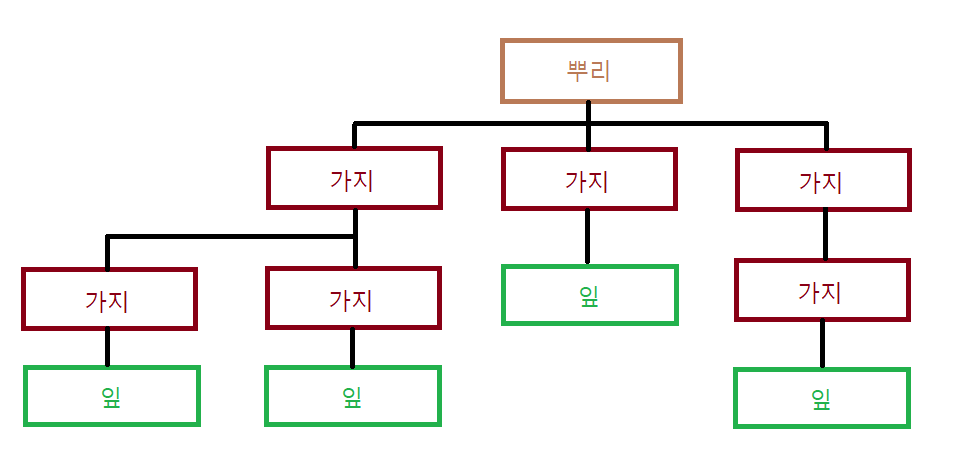
트리란 무엇인가? 마치 나무처럼 뿌리를 두고 가지가 뻗어 나가고, 그 가지에는 다시 잎이 맺는 그런 형상을 말한다. 그림으로 보면 다음과 같다.
뿌리, 가지, 잎은 모두 똑같은 노드이다. 트리 내의 위치에 따라서 명칭만 달라질 뿐이다. 뿌리인 루트는 트리 자료구조의 가장 위에 있는 노드이고, 잎은 끝 노드, 가지는 그 사이에 있는 노드들이다. 우선 트리를 이루는 각 구성 요소의 명칭과 관계를 알아야 한다.
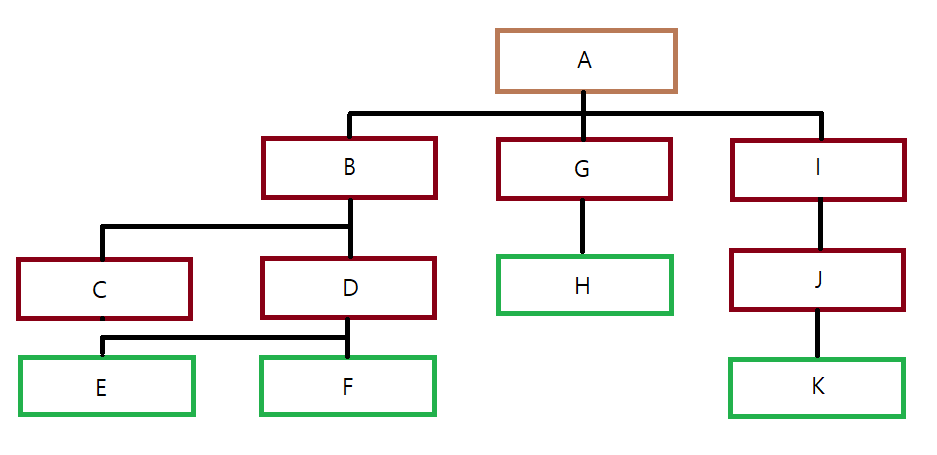
노드 B, G, I는 모두 A로부터 나왔다. 이런 관계를 부모 자식 관계라고 한다. A가 부모, B, G, I가 자식이다. 마찬가지로 C, D는 B의 자식이고, E, F는 D의 자식이다. 그리고 같은 부모를 공유하고 있는 노드들을 형제라고 한다. 여기서 형제는 (B,G,I), (C,D), (E,F)라 할 수 있다. 그럼 B랑 K는 뭐 친척 관계인가? 그런 건 없다.
이제 '경로(Path)'라는 단어를 알아보자. 트리에서 경로는 한 노드에서부터 다른 한 노드까지 이르는 길 사이에 놓여있는 노드들의 순서이다. 예를 들어서 위의 그림에서 B 노드에서 F 노드를 찾아간다고 한다면, B → D → F 순서로 갈 것이다. 이걸 "B, D, F"를 B에서 F까지의 경로라고 한다.
경로는 '길이(Length)' 속성을 가지는데, 출발 노드에서 목적지 노드까지 거쳐야 하는 노드 개수를 말한다. 방금 말한 B,D,F는 경로의 길이가 2라고 할 수 있다.
노드의 '깊이(Depth)'는, 루트 노드에서 해당 노드까지의 경로의 길이를 말한다. 다음 그림을 보면 쉽게 이해할 수 있다.
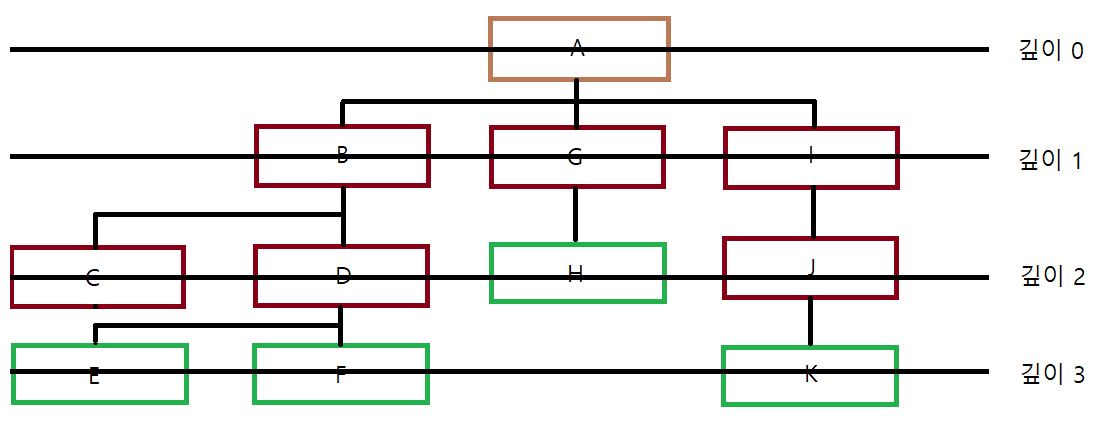
G 노드는 루트 노드인 A로부터 경로의 길이가 1이라 깊이가 1이고, K 노드는 A 노드로부터 경로의 길이가 3이라 깊이가 3이다. 그럼 루트의 깊이는? 0이다.
이와 비슷한 개념으로 '레벨(Level)'과 '높이(Height)'가 있다. 레벨은, 같은 깊이에 있는 노드들을 말한다. 위 그림에서 (B,G,I)는 같은 레벨 1에 있다고 할 수 있다. 높이는 '가장 깊은 곳'에 있는 잎 노드까지의 깊이를 뜻한다. 마치 실제 나무의 높이랑 비슷하다. 위 그림의 트리의 높이는 가장 깊은 곳에 있는 잎 노드들이 E,F,K라 3이다.
마지막 개념은 "차수(Degree)"이다. 이는 주어에 따라 다른데, 노드의 차수는 그 노드의 자식 노드 개수이고, 트리의 차수는 트리 내에 있는 노드들 가운데 자식 노드가 가장 많은 노드의 차수를 말하는 것이다. 위 그림에서 A 노드는 자식 노드 개수가 3이므로 차수가 3이고, B 노드는 자식 노드 개수가 2이므로 차수가 2이다. 가장 많은 자식 노드를 소유한 노드가 A므로, 트리의 차수는 3이 된다.
트리 표현하기
노드는 여러 가지 방법으로 표현할 수 있다. 먼저 '중첩된 괄호(Nested Parenthesis)' 표현법은, 같은 레벨의 노드들을 괄호로 같이 묶어 표현하는 방법이다. 위의 노드들은 이런 식으로 표현이 될 것이다.
(A(B(C)(D(E)(F)))(G(H))(I(J(K))))
이는 읽기는 어렵지만, 트리를 하나의 공식처럼 표현할 수 있다.
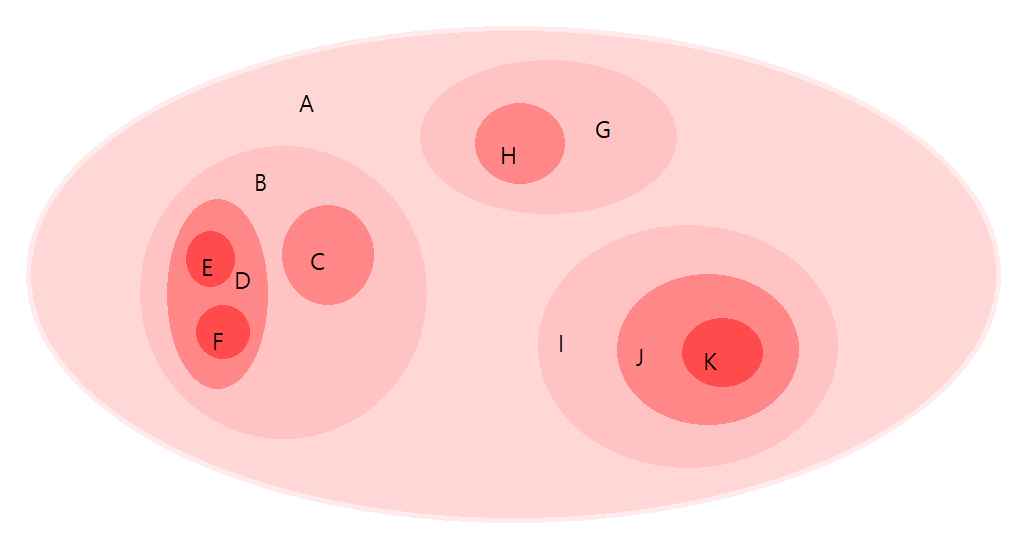
다음은 '중첩된 집합(Nested Set)'으로도 표현할 수 있다.
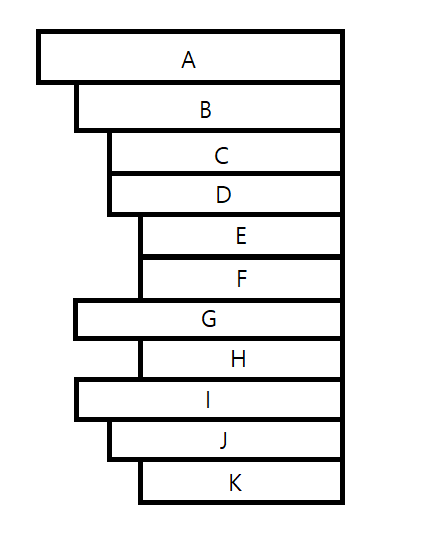
마지막으로, 트리는 들여쓰기(Indentation)로도 표현이 가능하다. 윈도우 탐색기가 폴더 트리의 들여쓰기 예시이다.
노드 표현하기
앞에서 살펴본 것은 트리를 표현하는 다양한 방법이다. 이제 '노드'를 표현하는 방법을 알아보자. 노드의 표현볍은 붐와 자식, 형제 노드를 연결 짓는 방법을 뜻한다. 이 방법에는 두 가지가 있는데, 첫 번째 방법인 'N-링크(N-Link)' 표현법 먼저 알아보자.
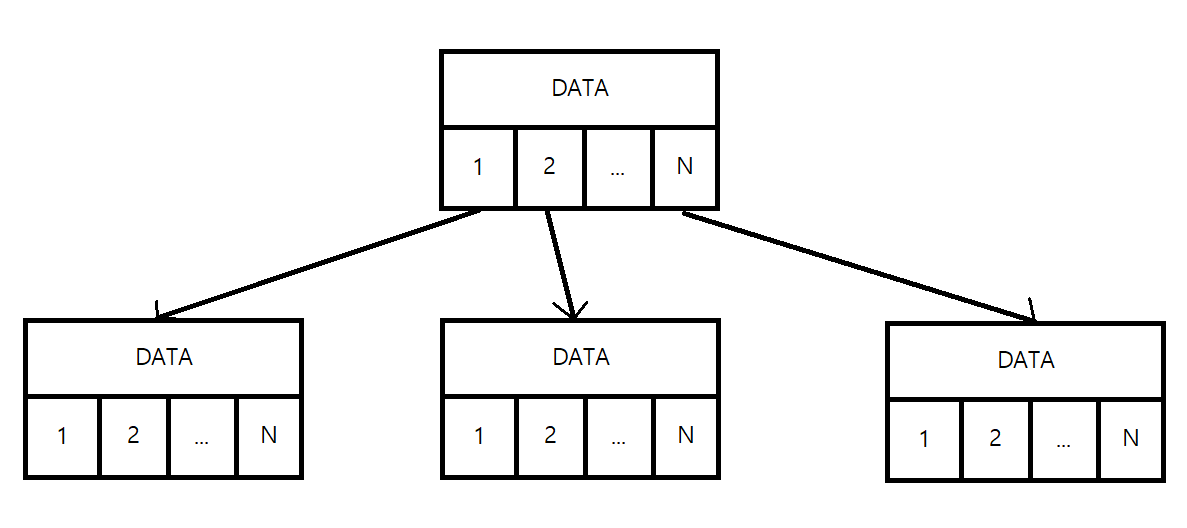
n-링크의 노드의 차수가 N이라면, 노드가 N개의 링크를 가지고 있어서 이 링크들이 각각 자식 노드를 가리키도록 노드를 구성하는 방법이다. 하지만 이 표현은 자식 노드의 수가 노드마다 달라지는 트리에는 사용하기가 어렵다는 단점이 있다. 이런 문제점을 해결한 게 두 번째 방법이다.
두 번째 방법은 '왼쪽 자식-오른쪽 형제(Left Child Right Sibling)' 표현법이다. 왼쪽에는 자식, 오른쪽에는 형제에 대한 포인터를 갖고 있는 노드의 구조이다. 이는 다음과 같다.
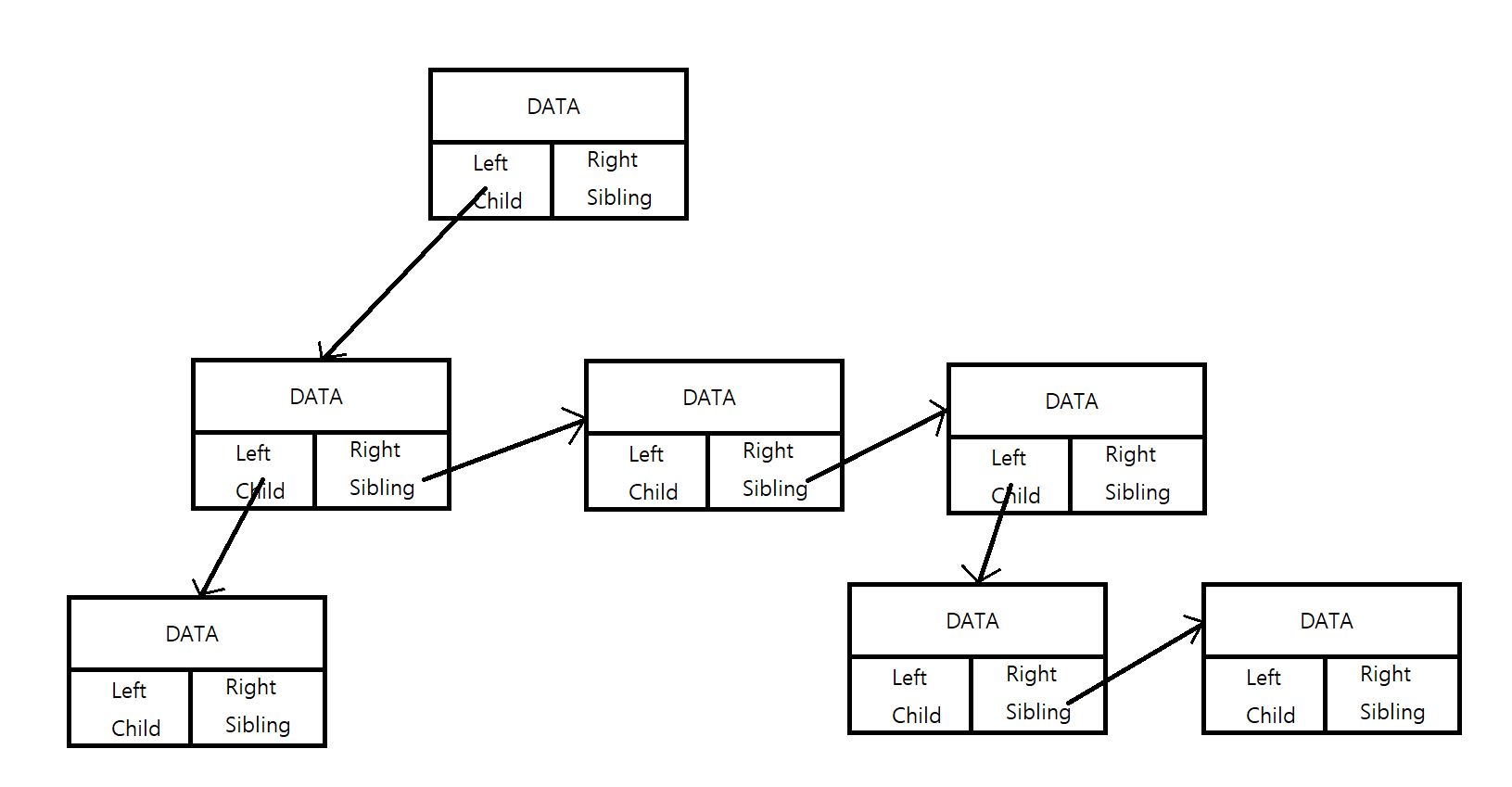
이 표현법을 사용하는 트리에서 어느 한 노드의 모든 자식 노드를 얻으려면, 일단 왼쪽 자식 노드에 대한 포인터만 있으면 된다. 왼쪽 자식 노드의 주소를 얻은 후, 오른쪽 형제 노드를 계속해서 얻어나가면 결국 모든 자식 노드를 얻을 수 있다.
트리 구현하기
이제 트리를 구현해보자.
typedef char ElementType;
struct LCRSNode
{
struct LCRSNode* leftChild;
struct LCRSNode* rightSibling;
ElementType data;
};
LCRSNode* LCRS_CreateNode(ElementType newData)
{
LCRSNode* newNode = new LCRSNode;
newNode->leftChild = nullptr;
newNode->rightSibling = nullptr;
newNode->data = newData;
return newNode;
}
void LCRS_DestroyNode(LCRSNode* node)
{
delete node;
}
void LCRS_DestroyTree(LCRSNode* root)
{
if (root->leftChild)
LCRS_DestroyTree(root->leftChild);
if (root->rightSibling)
LCRS_DestroyTree(root->rightSibling);
root->leftChild = nullptr;
root->rightSibling = nullptr;
LCRS_DestroyNode(root);
}재귀형식으로 간단하게 파괴할 수 있다.
void LCRS_AddChildNode(LCRSNode* parent, LCRSNode* child)
{
if (!parent->leftChild)
parent->leftChild = child;
else
{
LCRSNode* temp = parent->leftChild;
while (temp->rightSibling)
temp = temp->rightSibling;
temp->rightSibling = child;
}
}부모에게 자식을 대입하는 방법은, 부모의 왼쪽 자식부터 차례차례 검사 하다가 없으면 넣는 것이다.
void LCRS_PrintTree(LCRSNode* node, int depth)
{
int i = 0;
for (i = 0; i < depth; i++)
std::cout << " ";
std::cout << node->data << std::endl;
if (node->leftChild)
LCRS_PrintTree(node->leftChild, depth + 1);
if (node->rightSibling)
LCRS_PrintTree(node->rightSibling, depth);
}파괴와 마찬가지로 들여쓰기 출력도 재귀 형식으로 할 수 있다.
이 코드를 확인하는 예제이다.
int main()
{
LCRSNode* root = LCRS_CreateNode('A');
LCRSNode* b = LCRS_CreateNode('B');
LCRSNode* c = LCRS_CreateNode('C');
LCRSNode* d = LCRS_CreateNode('D');
LCRSNode* e = LCRS_CreateNode('E');
LCRSNode* f = LCRS_CreateNode('F');
LCRSNode* g = LCRS_CreateNode('G');
LCRSNode* h = LCRS_CreateNode('H');
LCRSNode* i = LCRS_CreateNode('I');
LCRSNode* j = LCRS_CreateNode('J');
LCRSNode* k = LCRS_CreateNode('K');
LCRS_AddChildNode(root, b);
LCRS_AddChildNode(b, c);
LCRS_AddChildNode(b, d);
LCRS_AddChildNode(d, e);
LCRS_AddChildNode(d, f);
LCRS_AddChildNode(root, g);
LCRS_AddChildNode(g, h);
LCRS_AddChildNode(root, i);
LCRS_AddChildNode(i, j);
LCRS_AddChildNode(j, k);
LCRS_PrintTree(root, 0);
LCRS_DestroyTree(root);
int debug = -1;
}문제로 나온 특정 레벨에 있는 노드 출력하기 함수도 만들어봤는데, 좀 고민하다가 나왔다. 트리는 재귀인가보다.
void LCRS_PrintNodesAtLevel(LCRSNode* root, int level)
{
if (level == 0)
{
std::cout << root->data << " , ";
if (root->rightSibling)
LCRS_PrintNodesAtLevel(root->rightSibling, level);
}
else
{
if (root->leftChild)
LCRS_PrintNodesAtLevel(root->leftChild, level - 1);
if (root->rightSibling)
LCRS_PrintNodesAtLevel(root->rightSibling, level);
}
}실행 결과.
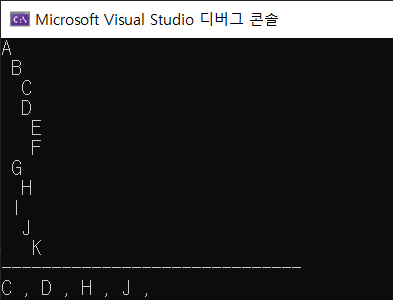
이진 트리
이진 트리(Binary Tree)는, 모든 노드가 최대 2개의 자식을 가질 수 있는 트리다. 이런식으로 생겼다.
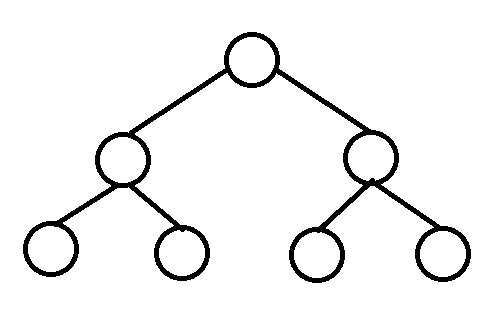
이진 트리는, 우리가 앞에 배웠던 일반 트리처럼 데이터를 담는 용도 사용하기에는 좀 불편하지만, 이진 트리만의 장점도 존재한다.
이진 트리에서 내에서도 새로운 분류를 할 수 있다. '완전 이진 트리(Complete Binary Tree)', '포화 이진 트리(Full Binary Tree)', '높이 균형 트리(Height Balanced Tree)', '완전 높이 균형 트리(Completely Height Balanced Tree)'가 그것이다. 포화 이진 트리는, 잎 노드들이 모두 같은 깊이에 존재하는 것이 특징이다.
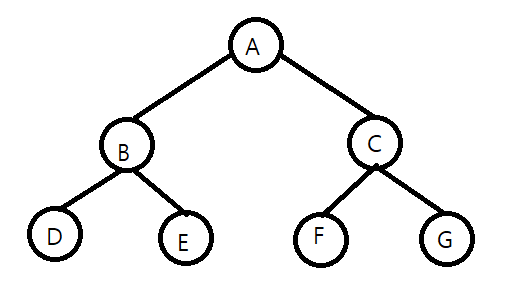
완전 이진 트리는, 포화 이진 트리 전 단계를 의미한다. 잎 노드들이 트리의 왼쪽부터 차곡차곡 채워져 있으면, 이것을 완전 이진 트리라고 부른다.
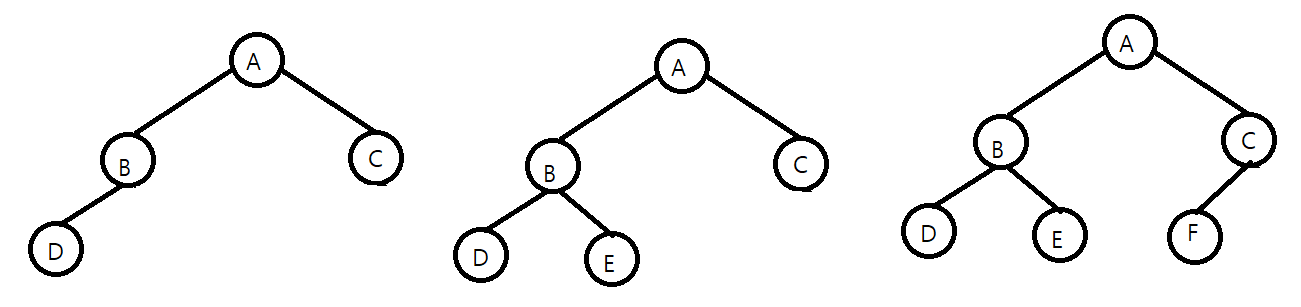
그래서 다음과 같은 것은 완전 이진 트리라 부르지 않는다. 그냥 일반 트리이다.
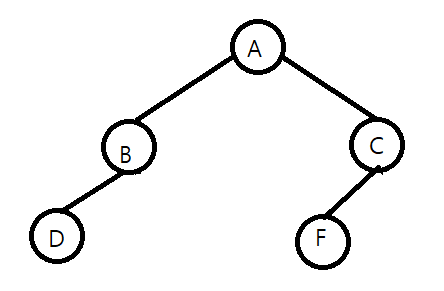
높이 균형 트리는 루트 노드를 기준으로 왼쪽 하위 트리와 오른쪽 하위 트리의 높이가 1이상 차이나지 않는 이진 트리를 말한다. 예를 들어 다음과 같다.
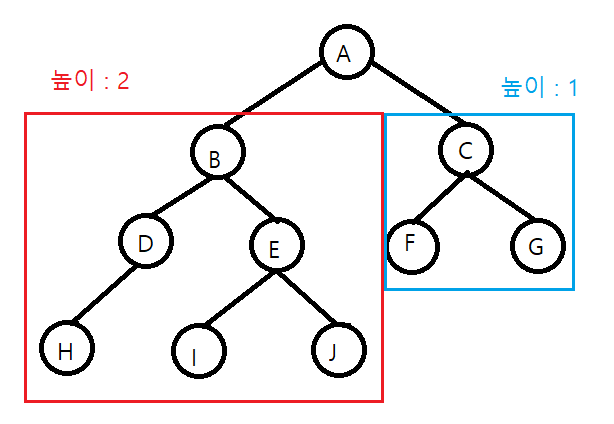
완전 높이 균형 트리는 루트 노드 기준으로 왼쪽 하위 트리와 오른쪽 하위 트리의 높이가 같은 이진 트리를 말한다.
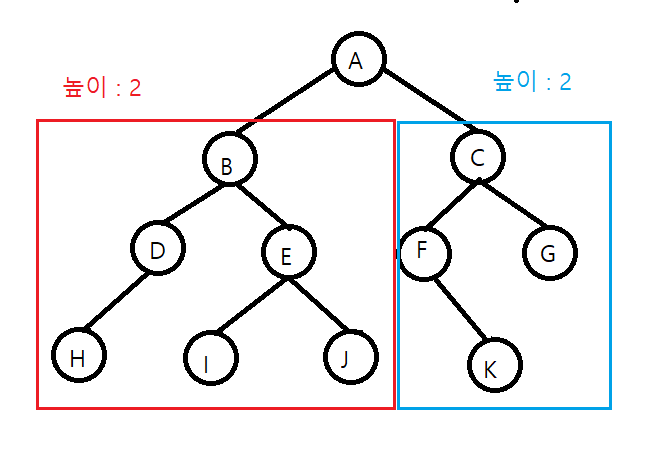
이진 트리의 순회
이진 트리만의 특징으로 인해, 트리 내부를 효율적으로 돌아다니며 원하는 방법으로 데이터에 접근할 수 있다. 그걸 '순회(Traversal)'이라 부른다. 순회에는 '전위 순회(Preorder Tarversal)', '중위 순회(Inorder Traversal)', '후위 순회(Postorder Traversal)' 세 가지가 있다. 하나하나 보겠다.
전위 순회는 루트 노드부터 시작해서 아래로 내려오면서 왼쪽 하위 트리를 방문하고, 왼쪽이 끝나면 오른쪽을 방문하는 방식이다. 아래 그림 처럼 A-B-C-D-E-F-G 순이다.
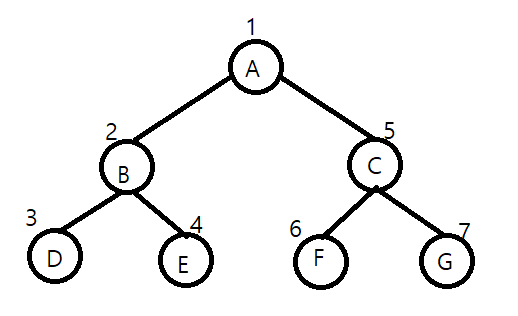
중위 순회는 왼쪽 하위 트리부터 시작해서 루트를 거쳐 오른쪽 하위 트리를 방문하는 방법이다.
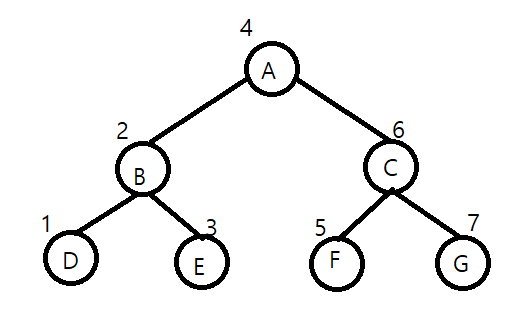
이건 어디에 쓰이는가? 이건 마치 사칙 연산 수식과 비슷하다.
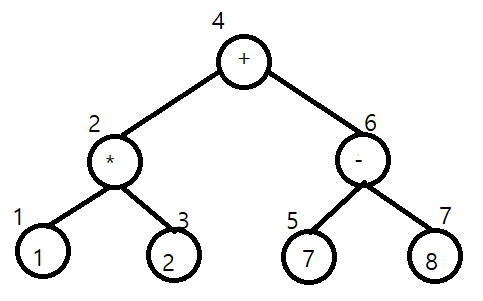
후위 순회는 전위 순위와 반대로 작동한다. 왼쪽 하위 트리, 오른쪽 하위 트리, 그리고 루트 노드 순이다.
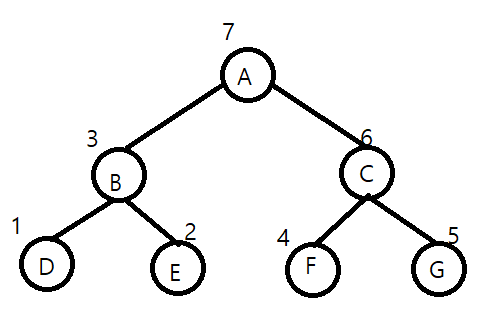
이제 다 배웠으니 이진 트리를 구현해보겠다.
#include <iostream>
typedef char ElementType;
struct Node
{
Node* left;
Node* right;
ElementType data;
};
Node* TB_CreateNode(ElementType newData)
{
Node* node = new Node;
node->left = nullptr;
node->right = nullptr;
node->data = newData;
return node;
}
void TB_DestroyNode(Node* node)
{
delete node;
}
void TB_DestroyTree(Node* root)
{
if (root == nullptr)
return;
TB_DestroyTree(root->left);
TB_DestroyTree(root->right);
TB_DestroyNode(root);
}
void TB_PreorderPrintTree(Node* node)
{
if (node == nullptr)
return;
std::cout << " " << node->data;
TB_PreorderPrintTree(node->left);
TB_PreorderPrintTree(node->right);
}
void TB_InorderPrintTree(Node* node)
{
if (node == nullptr)
return;
TB_InorderPrintTree(node->left);
std::cout << " " << node->data;
TB_InorderPrintTree(node->right);
}
void TB_PostorderPrintTree(Node* node)
{
if (node == nullptr)
return;
TB_PostorderPrintTree(node->left);
TB_PostorderPrintTree(node->right);
std::cout << " " << node->data;
}재귀를 활용하면 그렇게 어렵지 않다. 특히 순회를 구현할 땐 출력 위치만 바꿔주면 된다. 역시 트리는 재귀다.
확인용 예제 코드.
#include "TreeBinary.h"
using namespace std;
int main()
{
Node* A = TB_CreateNode('A');
Node* B = TB_CreateNode('B');
Node* C = TB_CreateNode('C');
Node* D = TB_CreateNode('D');
Node* E = TB_CreateNode('E');
Node* F = TB_CreateNode('F');
Node* G = TB_CreateNode('G');
A->left = B;
B->left = C;
B->right = D;
A->right = E;
E->left = F;
E->right = G;
cout << "--- Preorder ---" << endl;
TB_PreorderPrintTree(A);
cout << endl << endl;
cout << "--- Inorder ---" << endl;
TB_InorderPrintTree(A);
cout << endl << endl;
cout << "--- Postorder ---" << endl;
TB_PostorderPrintTree(A);
cout << endl << endl;
TB_DestroyTree(A);
int debug = -1;
}실행 결과.

수식 트리
수식 트리(Expression Tree)는 수식을 표현하는 이진 트리이다. 그래서 수식 이진 트리(Expression Binary Tree)라고 부르기도 한다. 수식 트리로는, 중위 표기식보다 후위 표기식을 이용해 트리를 구축하는 것이 훨씬 쉽다.
다음은 그 코드이다. 생성 및 파괴 함수는 이진 트리랑 같으니 후위 표기식을 트리로 만드는 함수 및 계산하는 함수를 만들어보겠다.
후위 표기식을 트리로 만드는 함수이다. 오른쪽부터 읽어서 숫자면 그대로 노드를 생성하면 되고, 연산자면 노드 생성 뒤, 오른쪽 왼쪽으로 다시 재귀함수를 돌려주면 된다. 왜? 피연산자 밑에는 연산자나 피연산자가 있을 수 없고, 연산자 밑에는 피연산자가 반드시 있어야 하기 때문이다. 그래야 계산이 된다.
void TE_BuildTreeExpression(char* postfixExpression, Node** node)
{
int len = strlen(postfixExpression);
char token = postfixExpression[len - 1];
postfixExpression[len - 1] = '\0';
switch (token)
{
case '+': case '-': case '*': case '/':
(*node) = TE_CreateNode(token);
TE_BuildTreeExpression(postfixExpression, &(*node)->right);
TE_BuildTreeExpression(postfixExpression, &(*node)->left);
break;
default:
(*node) = TE_CreateNode(token);
break;
}
}다음은 트리를 계산하는 방식이다. 현재 노드가 연산자면, 왼쪽 아래와 오른쪽 아래의 피연산자를 받아서, 연산자 계산하면 된다.
double TE_Evaluate(Node* tree)
{
if (tree == nullptr)
return 0;
char temp = tree->data;
double value[2];
switch (temp)
{
case '+': case '-': case '*': case '/':
value[0] = TE_Evaluate(tree->left);
value[1] = TE_Evaluate(tree->right);
break;
default:
return atof(&temp);
break;
}
if (temp == '+')
return value[0] + value[1];
else if (temp == '-')
return value[0] - value[1];
else if (temp == '*')
return value[0] * value[1];
else
return value[0] / value[1];
}다음은 확인용 예제 코드다.
#include "TreeExpression.h"
using namespace std;
int main()
{
Node* root = nullptr;
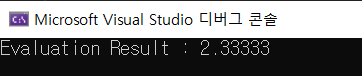
char postfixExpression[20] = "71*52-/";
TE_BuildTreeExpression(postfixExpression, &root);
cout << "Evaluation Result : " << TE_Evaluate(root) << endl;
TE_DestroyTree(root);
int debug = -1;
}실행 결과.
분리 집합
분리 집합(Disjoint Set)은 서로 공통된 원소를 갖지 않는 집합들을 말한다. 분리 집합에는 '교집합(Intersection)'은 있을 수 없고 오직 '합집합(Union)'만이 있다. 우리가 지금까지 배운 일반 트리나 이진 트리는 모두 부모가 자식을 가리키는 포인터를 갖고 있다. 분리 집합은 이와는 반대로 자식이 부모를 가리킨다. 가령 다음과 같은 식이다.
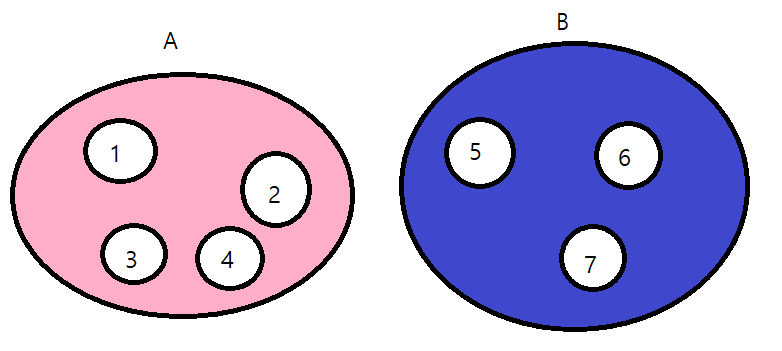
이런 분리 집합은
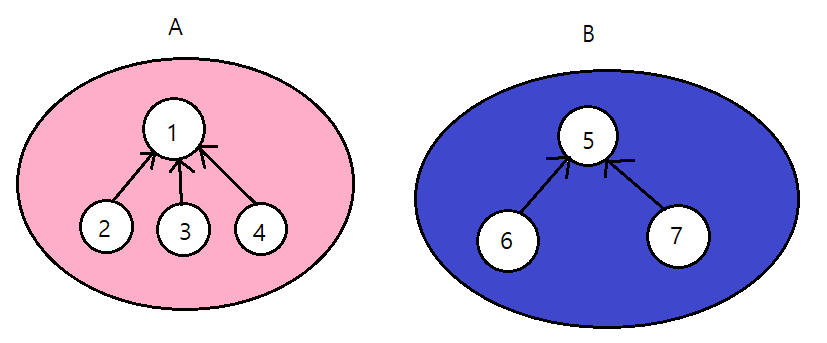
이렇게 부모를 가리킨다. 그래서 분리 집합 노드도 다음과 같이 부모를 가리키는 포인터, 멤버 데이터 이렇게 변수 2개만 있다.
struct DisjointSet
{
DisjointSet* parent;
void* data;
}분리 집합의 연산
분리 집합은 딱 두 가지 연산만 있다. 합집합과 집합 탐색이다. 왜 두 가지밖에 없을까? 분리 집합의 목적은 어떤 원소가 어느 집합에 속해있는지 알기 위함이기 때문이다. 먼저 합집합을 알아보자.
합집합은 두 집합을 더하는 연산이다. 어떻게 합치는가? 가령 위의 분리 집합은 오른쪽의 집합의 루트 노드를 왼쪽에 있는 루트 노드의 자식 노드로 만들면 된다.
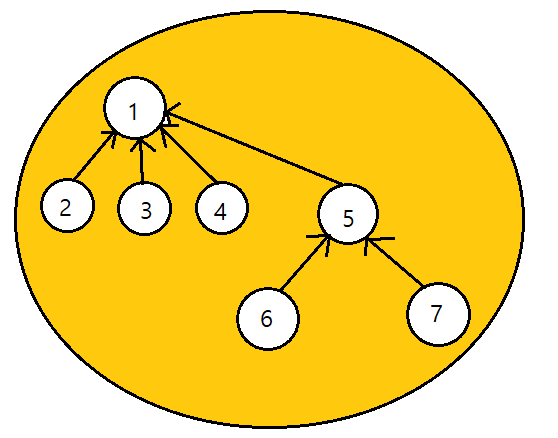
두 집합은 하나가 되었다.
void DS_UnionSet(DisjointSet* set1, DisjointSet* set2)
{
set2 = DS_FindSet(Set2);
Set2->Parent = Set1;
}집합 탐색(find) 연산은 집합에서 원소를 찾는 것이 아니라, 원소가 속해 있는 집합을 찾는 연산이다. 부모를 쭉 타고 가면 나올 것이다.
DisjointSet* DS_FindSet(DisjointSet* Set)
{
while (set->parent != nullptr)
set = set->parent;
return set;
}