데이터베이스 정규화 (Database Normalization)
- 데이터베이스 정규화는 데이터베이스의 설계와 연관 있다. 그 이유는 데이터베이스 설계가 결론적으로 데이터가 어떻게 저장될 지 구조를 정해주기 때문이다.
이를 위해서 아래의 내용들이 중요하다 :
- Data redundancy
- Data integrity
- Anomaly
Data Redundancy
데이터 중복 (data redundancy) 은 실제 데이터의 동일한 복사본이나 부분적인 복사본을 뜻한다. 이러한 중복성으로 데이터를 복구할 때에 더 수월할 수도 있겠지만 데이터베이스 내에서는 몇가지 문제점들을 대체로 지닌다 :
- 일관된 자료 처리의 어려움
- 저장 공간 낭비
- 데이터 효율성 감소
Data Integrity
데이터 정규화는 이러한 데이터 무결성을 강화하기 위한 목적도 지닌다.
데이터 무결성 (data integrity) 은 데이터의 수명 주기 동안 정확성과 일관성을 유지하는 것을 뜻한다. 즉, 입력된 데이터가 오염되지 않고 입력된 그대로 데이터를 사용할 수 있다는 뜻이기도 하다.
Anomaly
데이터 이상 현상 (anomaly) 과 같은 경우에는 데이터에서 기대한 것과 다른 이상 현상을 가리킨다.
다음과 같은 3가지 현상이 있다:
- 갱신 이상 (update anomaly)
- 삽입 이상 (insertion anomaly)
- 삭제 이상 (deletion anomaly)
Update Anomaly
갱신 이상 (update anomaly) 은 동일한 데이터가 여러 행 (레코드) 에 걸쳐 있을 때에 어느 데이터를 갱신해야 하는지에 대한 논리적 일관성이 없어 발생하게 된다.
다음과 같은 테이블이 존재하고 두 개의 레코드가 동일한 사람일 때에 (519번) 갱신을 하게 되는 경우 어떤 데이터를 해야 하는지에 대한 문제가 발생한다.

Insertion Anomaly
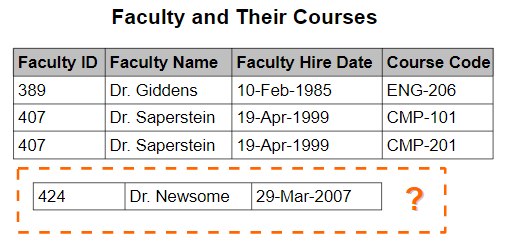
삽입 이상 (insertion anomaly) 은 데이터 삽입을 못하는 경우를 가리킨다.
다음과 같은 경우 새로운 직원이 들어왔을 때에 (Dr. Newsome) 아직 가르칠 수업이 정해지지 않은 경우에는 데이터에 추가되지 못하게 된다. 수업을 NULL 과 같은 값으로 지정해야 하지 않은 이상 담당 수업이 있어야 추가될 수 있는 이상 현상이 발생하는 것이다.
Deletion Anomaly
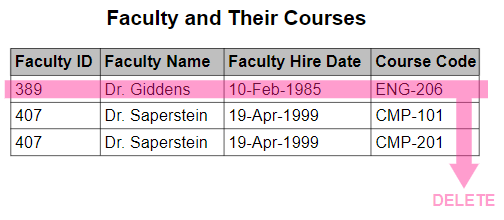
삭제 이상 (deletion anomaly) 과 같은 경우에는 데이터의 특정 부분을 지울 때에 의도치 않게 다른 부분들도 함께 지워지는 이상 현상이다.
다음과 같은 경우에는 한 직원이 담당하는 수업이 사라지는 것을 적용할 때 발생하는 모습을 보여준다. 즉, 한 직원 데이터의 수업 관련 데이터를 지우기 위해서는 레코드 전체가 사라져 결국에는 의도치 않게 다른 직원의 데이터들도 같이 삭제되는 현상이 발생하게 된다.