!!개인 공부용이기 때문에 틀린 내용이 있을 수도 있습니다!! 잘못된 내용이 있으면 언제든지 지적해 주세요.
trie 알고리즘은 문자열을 다루는 알고리즘의 일종으로, 빠른 탐색이 가능하기 때문에 문자열을 다루는 문제에서 자주 사용된다.
기본 구조는 간단하다. 현재 문자에서 다음 문자로 갈 수 있는 노드가 이미 생성되어있다면 다음 문자로 바로 넘어가고, 없다면 노드를 추가해주면 된다.
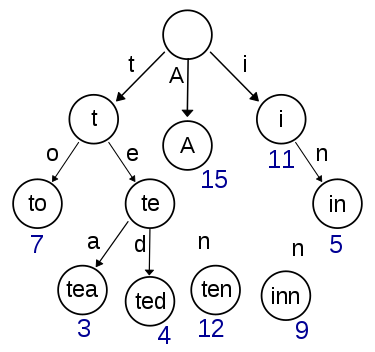
출처: 위키백과
위의 그림을 예시로 설명해보면, 아무것도 없는 루트노드에서 시작하여 to라는 문자열을 추가하려고 한다고 생각해보자. 먼저 첫 글자인 t를 루트 노드에 연결해준다. 그 후 t->o 로 갈 수 있도록 o 노드를 추가해준다. 문자열의 끝에는 해당 문자열이 끝났다는 표시를 해 주어야 한다. 이제 to 문자열이 trie에 추가되었다. 그 다음으로 tea라는 문자열을 추가해보자. 루트에서 t로 가는 노드는 이미 있으므로 첫 글자 t는 추가해주지 않아도 된다. 다음으로 e, a는 노드가 없으므로 추가해준다. 이와 같은 과정을 계속 반복하여 만들어지는 구조가 바로 trie이다.
문자열을 탐색할때는 루트노드에서 찾고자 하는 문자열의 첫 글자를 찾고, 첫 글자가 있는 노드에서 다음 글자로 넘어갈 수 있는 노드가 존재하는지 찾고 ... 이 과정을 반복한다. 만약 중간에 노드가 없으면 해당 문자열은 trie에 삽입되지 않은 문자열이라는 뜻이므로 탐색을 종료한다.
struct Trie {
bool finish; // 끝나는 지점을 표시해줌
Trie* next[26]; // 26가지 알파벳에 대한 트라이
// 생성자
Trie() : finish(false) {
memset(next, 0, sizeof(next));
}
// 소멸자
~Trie() {
for (int i = 0; i < 26; i++)
if (next[i])
delete next[i];
}
// 삽입
void insert(const char* key) {
if (*key == '\0') finish = true; // 문자열이 끝나는 지점일 경우 표시
else {
int curr = *key - 'A';
if (next[curr] == NULL)
next[curr] = new Trie(); // 탐색이 처음되는 지점일 경우 동적할당
next[curr]->insert(key + 1); // 다음 문자 삽입
}
}
// 탐색
Trie* find(const char* key) {
if (*key == '\0') return this; // 문자열이 끝나는 위치를 반환
int curr = *key - 'A';
if (next[curr] == NULL) return NULL; // 찾는 값이 존재하지 않음
return next[curr]->find(key + 1); // 다음 문자를 탐색
}
};