
참고
자바의 정석
https://hhseong.tistory.com/125
https://velog.io/@suitepotato/00010
https://almost-native.tistory.com/337
논리형 - boolean
- 논리형에는 boolean 1가지 밖에 없다.
- boolean형 변수에는 true와 false 2가지가 존재하며, 기본 값은 false다.
- 대답 (yes / no), 스위치 (on / off)등의 논리구현에 주로 사용한다.
- 2가지 값만 표현하면 되서 1비트면 충분하지만, 자바에서 데이터를 다루는 최소단위가 byte이기 때문에, boolean 크기는 1byte다.
boolean power = true;
boolean checked = False; // 에러. 대소문자가 구분됨. true 또는 false만 가능- 자바에서는 데소문자가 구별되기 때문에 TRUE와 true는 다른 것으로 간주된다.
문자형 - char
- 문자형에는 char 1가지 자료형 밖에 없다.
- 단 하나의 문자만 저장이 가능하다.
- 사실 문자가 저장이 되는 것이 아니라, 해당되는 문자의 유니코드가 저장이 된다.
char ch = 'A'; // 문자 'A' (사실은 유니코드)를 char타입의 변수 ch에 저장.- 문자 대신에 유니코드가 저장이 되는 것은 컴퓨터는 숫자밖에 모르기 때문이다.
- 그래서, 문자의 유니코드를 직접 저장할 수 있다.
char ch = 'A'; // 문자 'A' (사실은 유니코드)를 char타입의 변수 ch에 저장.
char ch = 65; // 문자의 코드를 직접 변수 ch에 저장.- 혹시, 해당하는 문자의 유니코드를 알고 싶다면, 아래와 같이 정수형으로 형변환 하면 된다.
int code = (int) ch;특수문자 다루기
- 영문자 이외에 tab이나 backspace등의 특수문자를 저장하려면 아래와 같은 표처럼 작성하면 된다.
| 특수 문자 | 문자 리터럴 |
|---|---|
| tab | \t |
| backspace | \b |
| form feed | \f |
| new line | \n |
| carriage return | \r |
| 역슬래쉬 | \\ |
| 작은 따옴표 | \' |
| 큰 따옴표 | \" |
| 유니코드 (16진수) 문자 | \u유니코드 (ex. char a = '\u'0041) |
char타입의 표현형식
- 정수형과 다른 것은 부호가 없는 정수로만 표현이 된다는 것이다.
- 그래서, 표현할 수 있는 값의 범위가 다르다.
16비트로 표현할 수 있는 정수의 개수: 2^16 (65536개)
short타입의 표현범위: -2^15 ~ (2^15) -1 (-32768 ~ 32767)
char타입의 표현범위: 0 ~ (2^16)-1 (0~65535)
- 아래와 같이 'A'와 65를 저장하면 둘다 똑같은 2진수가 저장된다.
하지만 출력하면 결과가 다르게 나온다. ch는 'A'가 나올것이고 s는 65가 나올 것이다. - 왜냐하면 컴퓨터는 변수를 해석할 때 값만 보고 해석하는게 아니라 값의 타입까지 확인하고 출력을 하기 때문이다.
- 만약 값의 타입을 모르면 '1231'이라는 것을 일이삼일로 읽을지, 12시 31분으로 읽을 지 모르게 때문이다.
char ch = 'A';
short s = 65;인코딩과 디코딩 (encoding & decoding)
- 컴퓨터가 숫자밖에 모르기 때문에 문자가 숫자로 변환되는 것은 위에서도 언급을 하였다. 하지만 어떤 기준으로 변환을 할까? 그것은 바로 유니코드 표이다.
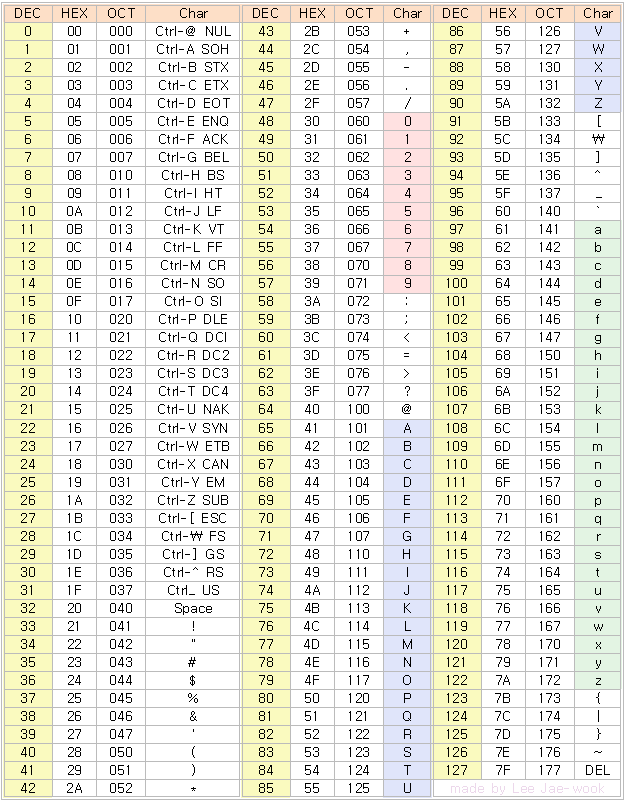
- 위의 표 처럼 문자를 코드로 변환하는 것을 문자 인코딩이라 하며, 코드를 문자로 변환하는 것을 문자 디코딩이라고 한다.
- 가끔 인터넷 검색을 하다보면, 페이지 전체가 알아볼수 없는 이상한 글자로 가득 찬 경험이 있을 것이다. 그때마다 버그인가? 해킹당했나?라고 생각하지 말고 해당 html 문서에서 인코딩에 사용된 코드표와 웹브라우저의 설정이 맞지 않아서이다.
아스키(ASCII)
- ASCII란, 정보교환을 위한 미국 표준 코드라는 뜻이며, 128개의 문자집합을 제공하는 7bit 부호이다.
- 처음 32개 문자는 제어문자로, 출력할수 없고 33번째 이후 문자들은 출력이
가능하며, 기호와 숫자, 영소대문자로 이루어져 있다. - 특징으로는 숫자 (0~9), 영문자 (A~Z, a~z)가 연속적으로 배치되었다는 것이 특징이며, 프로그래밍에서 유용하기 활용된다.
확장 아스키(Extended ASCII)와 한글
- 일반적으로 데이터는 1byte단위로 이루어 지는데, 아스키는 7bit이므로, 1bit가 남는다. 그 남는 1bit를 활용하여 문자를 추가 정의한 것이 확장 아스키이다.
- 확장 아스키중에 추가된 문자는 128개의 문자이다. 이 128개의 문자는 여러국가와 기업에서 서로의 필요에 따라 다르게 정의해서 사용한다.
- 그 중 대표적인 것이, ISO 8859-1이다. 주로 서유럽에서 일반적으로 사용하는 문자들을 포함한다.
- 확장 아스키로도 표현하기 힘든 언어가 한글이다. 그래서 생각해낸 방법이 두개의 문자코드로 한글을 표현하는 방법이다.
- 두개의 문자코드를 조합하여 만들어낸 것이 확장 완성형 (CP 949) 방식이다.
- 현재 윈도우 PC에서는 CP 949방식으로 인코딩되어서 저장되어 있다.
코드 페이지 (code page, cp)
- PC를 사용하는 지역이나 국가에 따라 여러 버전의 '확장 아스키'가 필요했다.
- 그래서, 여러 버전의 확장 아스키 모음집을 코드 페이지라고 불렀으며, CP xxx 형식으로 이름을 붙였다.
- 그래서, 한글 윈도우는 'CP-949', 영문 윈도우는 'CP-437'을 사용한다.
유니코드
- 인터넷의 발명으로 각 국에서 다른 언어를 사용하는 컴퓨터 간의 자료 교환이 활발해지기 시작하면서 서로 다른 문자 인코딩 사용으로 문서교환이 어려워졌다.
- 이에 어려움을 해소하고자, 전 세계의 모든 문자를 하나의 통일된 문자집합으로 표현하였고, 그것이 바로 유니코드이다.
- 처음에 유니코드는 2byte로 표현하기 시작하였으나, 새로운 언어들의 만들어지면서 21bit로 확장이 되었다.
- 새로 추가된 문자들을 보충문자라 불리며, 이 보충문자를 표현할려면 char 자료형이 아닌, int타입을 사용해야 한다.
- 유니코드는 먼저 유니코드에 포함시키고자 하는 문자들의 집합을 정의하였는데, 이것을 유티코드 문자 셋이라고 한다. 이 문자 셋에 번호를 붙인것이 유니코드 인코딩이다.
- 유티코드 인코딩에는 UTF-8, UTF-16, UTF-32등 여러가지가 있지만, 자바에서 사용하는 유니코드 인코딩은 UTF-16이다.
- 모든 문자의 크기가 동일한 UTF-16이 문자를 다루기 편리하지만, 1byte로도 충분히 표현이 가능한, 영문자나 숫자가 2byte가 되므로, 문서의 크기가 매우 커진다.
- UTF-8은 영문자나 숫자는 1byte, 한글은 3byte로 표현되어 문서의 크기가 작지만 가변적이다.
- UTF-8과 UTF-16 둘다 처음 128문자 아스키는 동일하다.
- 하지만, 인터넷 세상에서 문서의 크기가 작은 장점이 더 커서, 요즘은 UTF-8을 이용한다.
참고
코드포인트는 유니코드 문자 셋에 순서대로 붙인 일련번호이다.
이 문자들은 번호 (코드 포인트)로 다루는 것이 편리하다.
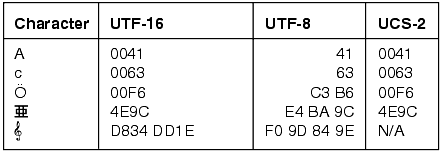
정수형
- 정수형은 byte부터 long까지 1byte부터 시작해서 2배씩 크기가 증가한다.
- 기본 자료형은 int이다.
정수형의 표현형식과 범위
- 어떤 진법의 리터럴을 변수에 저장해도 실제로는 2진수로 바뀌어 저장된다.

- 모든 정수형은 부호있는 정수이므로, 왼쪽의 첫번째 비트를 부호비트로 사용하고, 나머지는 값을 표현하는데 사용한다.
n비트로 표현할 수 있는 정수의 개수 : 2^n개 (2^(n-1)개 + 2^(n-1)개)
n비트로 표현할 수 있는 부호있는 정수의 범위 : -2^(n-1) ~ 2^(n-1) - 1
정수형의 선택기준
- 변수에 저장하려는 정수값의 범위에 따라 4개의 정수형 중에서 하나를 선택하면 되지만, byte나 short보다, int를 사용하도록 하자.
- byte나 short가 int보다 크기가 작아서 메모리를 조금 더 절약 할 수 있지만, 저장할 수 있는 값의 범위가 작은 편이라서 연산 시에 범위를 넘어서 잘못된 결과를 얻을 수 있다.
- 그리고 여담이지만, JVM 피연산자 스택이 피연산자를 4byte단위로 저장하기 때문에 byte나 short같은 4byte 아래의 자료형도 4byte로 변환되어 계산되기 때문에 오리혀 int가 효율적이다.
- 정수형 변수를 선언할 때는 int타입으로 하고, int의 범위를 넘어서는 수를 다룰 때는 long을 사용하면 된다.
- byte나 short는 성능보다 저장공간 절약하는것이 더 중요할 때 사용 권장.
참고
long타입의 범위를 벗어나는 값을 다룰 때는 실수형 타입이나 BigInteger 클래스를 사용하면 된다.
정수형의 오버플로우
- 4bit 2진수의 최댓값인 '1111'에서 1을 더하면 어떻게 될까? 에러 발생?
- 원래는 10000으로 되는것이 맞지만, 4bit밖에 허용이 안되면 0000으로 초기화가 된다.
- 이처럼, 타입이 표현할 수 있는 값의 범위를 넘어서는 것을 오버플로우라고 한다.
- 오버플로우가 발생하면, 예상하지 못한 결과 값이 나온다. 그래서, 오버플로우가 발생하지 않게, 충분한 크기의 타입을 선택해서 사용해야 한다.
- 쉽게 생각하면 자동차 주행표시기를 생각하면 쉽다.
요약정리
최대값 + 1 = 최소값
최소값 - 1 = 최대값
부호있는 정수의 오버플로우
- 부호 없는 정수와 부호 있는 정수는 표현범위 즉, 최댓값과 최솟값이 다르기 때문에 오버플로우가 발생하는 시점이 다르다.
- 부호없는 정수는 2진수로 '0000'이 될 때, 오버플로우가 발생하고,
부호있는 정수는 부호비트가 0에서 1로 될 때 오버플로우가 발생된다.
실수형
- 실수형은 말 그대로 실수를 저장하기 위한 자료형으로 float와 doble이 있다. 저장할 수 있는 범위는 아래와 같다.
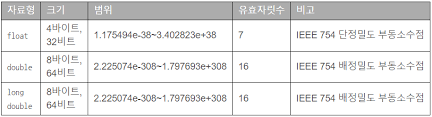
- 실수형은 소수점도 표현해야 하므로, 얼마나 큰 값을 표현할수 있는가 뿐만 아니라 얼마나 0에 가깝게 표현할 수 있는가도 중요하다.
Q. 실수형도 정수형처럼 오버플로우가 발생하는가?
A. 정수형과 달리, 실수형에서는 오버플로우가 발생하면 변수의 값은 무한대가 된다. 그리고 정수형에 없던 언더 플로우가 있는데, 언더플로우는 실수형으로도 표현할 수 없는 아주 작은 값, 즉, 양의 최소 값보다 작은 값이 되는 경우를 말한다.
- 같은 byte로 정수형보다 많은 범위를 낼수 있을까? int형과 float형은 똑같은 4byte이지만, float형이 훨씬 많은 범위를 표현할 수 있다.
- 그 이유는 값을 저장하는 형식이 다르기 때문이다. 정수형은 부호와 값 2가지로 이루어져 있지만, 실수형은 부후부, 지수부, 가수부로 나눠진다. 즉, 2의 제곱형태로 값을 저장하기 때문에 똑같은 byte로도 많은 범위를 표현할 수 있는것이다.
- 하지만, 이런 장점만 있으면, 우리 개발자들은 실수형만 썼을 것이다. 정말로 치명적인 단점이 존재한다. 바로, 오차가 발생할 수 있다는 단점이 있다. 그래서 실수형은 값의 범위보다도, 정밀도 또한 아주 중요한 요인으로 들어간다.
- float는 정밀도가 7자리이고, 그 이상은 double을 사용한다. 이것이 우리 개발자들이 실수형을 표현할 때 double형을 작성하는 이유이다.
- 저장하려는 값의 범위보다도, 보다 높은 정밀도가 필요해서이다.
- 그래서 메모리를 절약하는것이 더 중요한 프로그램에서는 float을 쓰고,
그 외에는 double을 사용한다.
실수형의 저장형식
- 실수형은 앞에서 이야기를 했듯이 정수형과 표현형식이 달라서, 실수형은 값을 부동소수점 형태로 저장한다.
- 부동소수점은 부호부, 지수부, 가수부로 이루어진다.
| 기호 | 의미 | 설명 |
|---|---|---|
| S | 부호 | 0이면 양수, 1이면 음수 |
| E | 지수 | 부호 있는정수, 지수의 범위는 -127 ~ 128 (float), -1023 ~ 1024 (double) |
| M | 가수 | 실재 값을 저장하는 부분. 10진수로 7자리 (float), 15자리 (double)의 정말도로 저장 가능 |
부호부
- 정수형과 달리 2의 보수법을 사용하지 않기 때문에, 양의 실수를 음의 실수로 바꾸려면, 그저 부호비트만 바꿔주면 된다.
지수부
- 지수부는 지수를 저장하는 부분으로 float의 경우는 8bit의 저장공간을 갖는다. 즉, -127 ~ 128의 범위가 저장된다.
- 하지만 NaN, 양의 무한대, 음의 무한대와 같이 특별한 값의 표현을 위해 예약되어 있으므로 실제로 사용가능한 지수의 범위는 -126 ~ 127이다.
가수부
- 가수부는 실제 값인 가수를 저장하는 부분으로 float의 경우는 2진수 23자리를 저장 가능하다. 즉, 10진수로 7자리를 저장할 수 있는데 이것이 정밀도다. double의 경우는 float의 정밀도의 2배이다.
부동 소수점의 오차
- 실수중에는 파이같은 무한소수가 존재하므로, 정수와 달리 실수를 저장할때는 오차가 발생할 수 있다.
- 게다가 10진수가 아닌 2진수로 저장하기 때문에, 10진수에서 유한소수더라도 2진수로는 무한소수가 될 수 있다. 2진소수로는 10진소수로 정확히 표현하기 힘들기 때문이다.
- 비록, 2진수가 유한소수라도, 가수를 저장할 수 있는 자리수가 한정되어 있으므로 저장되지 못하고 버려지는 값들이 있으면 오차가 발생한다.
- 2진수로 변환된 실수를 저장할때는 1.xxx X 2^n형태로 변환하는데 이 과정을 정규화라고 한다.
코드에서 float타입을 int타입으로 변환하는 함수가 존재하는데 아래와 같다.
Float.floatToIntBits();

모든 것을 즐길 줄 아는 개발자, 양성빈입니다.