
배경
이번 포스트는 지연 로딩 문제를 해결하기 위해 Fetch Join을 사용하면서 겪은 단점과 개선하려는 시도를 기록한다. 🏃♀️ 🏃
구현 중인 프로젝트의 내용(흐름)을 설명하기 때문에 글이 약간 길다.
꼭 읽어야만 이해되지는 않지만 읽으면 왜 이렇게 결정했는지가 더 와닿지 않을까? 🙃
발단
Colla 프로젝트에서 성능을 위해 거의 모든 엔티티가 지연 로딩 전략으로 조회되게끔 구현하고 있었다.
이로 인해 단순하게 Spring에서 기본 제공하는 findAll()과 같은 JPA 메서드를 사용하면 지연 로딩으로 인한 문제가 발생했다.
(LazyInitializationException 또는 N+1 문제!)
자주 마주할 문제이므로 이번 기회에 지연 로딩 문제를 해결하기 위한 방식들을 정리하자는 생각에 자료를 꽤 찾아봤다.
굉장히 많은 자료가 나왔는데 대략적으로 정리하자면 다음과 같다.
-
hibernate.enable_lazy_load_no_trans
설정시 연관된 lazy하게 load되는 엔티티를 각각 별개의 세션(트랜잭션)으로 처리- LazyInitializationException는 발생하지 않지만 결국 N+1 문제 발생 → Anti pattern
-
Global Fetch 전략 수정
지연 로딩에서 즉시 로딩으로 패치 전략을 변경한다. (LAZY → EAGER)- 사용하지 않는 엔티티까지 로딩된다.
- N+1 문제가 발생한다.
-
Fetch Join (Entity Graph)
엔티티 조회시 연관된 엔티티까지 함께 가져오게 된다. N+1 문제를 해결할 수 있다.- 필요한 조건마다 레포지토리 함수(쿼리)를 작성해야한다.
- 프론트에서 데이터 조건이 달라지면 쿼리가 일일히 수정되어야한다.
-
Proxy intialization 프록시 초기화
영속성 컨텍스트가 살아있을 때 필요한 엔티티의 프록시를 강제로 초기화한다.- 영속성 컨텍스트가 살아있을 때 초기화해야하므로 프레젠테이션 계층이 서비스 계층을 침범할 수 있다.
- 많이 사용하게 될 시 영속성에 많은 엔티티들이 올라와있게 되어 부담이 갈 수 있다.
각각의 장단점이 비교적 명확했고, 원하는 것은 Lazy 전략을 유지하면서 쿼리가 일일히 나가지 않도록 하는 것이었으므로 Fetch Join을 사용해서 쿼리가 한번만 실행되도록하는 방식을 선택하게 되었다.
전개
하지만 동일한 방식으로 계속해서 개발을 진행하다보니 단점이 명확해졌다.
앞 단에서 필요한 데이터의 조건이 달라지면 레포지토리 함수의 쿼리를 재작성해야했다.
즉 프레젠테이션 계층의 변화가 직접적으로 데이터 접근 계층에 영향을 미쳤다.
이는 한 쿼리에서 사용하는 엔티티가 늘어날 수록 더 넓은 범위에서 영향을 받게되었고,
따라서 레포지토리 함수가 최대한 좁은 범위를 유지할 수 있도록 개선이 필요해졌다.
결말
그래서 해결책은?
위에 미리 정리했던 방식 중 하나이자, 프로젝트를 같이 진행하는 팀원이 제시한 방식이었다.
프록시 초기화, 즉 Hibernate.intialize(Entity) 를 이용해서 이미 가지고 있는 엔티티와 연관된 Lazy Fetch해야할 엔티티들를 미리 영속성 컨텍스트에 올려놓는 방식이었다.
우리의 프로젝트에서의 데이터는 크게 다음과 같다.
- 꼭 필요하지만 적게 생성되고 자주 변화하지 않는 것
프로젝트의 멤버, 프로젝트의 테스크들의 상태값, 프로젝트의 스토리 - 꼭 필요하고 많이 생성되고 자주 변화하는 것
프로젝트의 테스크 - 필수적으로 필요하지는 않지만 자주 변화되는 것
프로젝트의 테스크들의 태그(라벨)
이때 자주 변화한다면 영속성 컨텍스트 단에 초기화를 해놓는다해도 금방 변경되므로 다시 초기화가 필요할 수 있다.
또한 데이터량이 많다면 메모리에 지나치게 많은 데이터가 올라가므로 바람직하지 않다.
그러니 첫번재 유형과 같은 엔티티가 영속성에 컨텍스트에 올려놓기 가장 적절했다.
메모리를 지나치게 많이 차지하지 않고, 자주 변경되지 않으므로 영속성을 통해 사용하기 쉽다.
따라서 Fetch Join시에 첫번째 유형의 엔티티는 같이 쿼리에 작성하지 않고,
Hibernate의 프록시 초기화를 통해 미리 가져오도록 하는 방식을 사용했다.
개선
이번 포스트의 주제는 여기서부터다.
프록시 초기화는 Hibernate.initialize(Entity)를 통해 이루어졌다.
목적이 프로젝트의 기본 정보(멤버, 테스크 상태값 등)를 미리 프록시에 올려놓는 것이었으므로
projectService.initializeProjectInfo(projectId)
와 같이 함수의 분리해놓고, 필요한 서비스인 TaskService에서 불러 사용하고 있었다.
하지만 이런식으로 사용하게 되니 TaskService에서 다른 서비스를 의존하게 되고 심지어 그 로직은 필수적인 비즈니스 로직조차 아니였다.
즉 성능 개선을 위한 코드로 인해 상위 계층 -> 하위 계층이 아닌 동등 계층에서의 의존성이 증가하고 있었다.
이런 성능에 관련된 코드는 이후 상황에 따라 자유롭게 추가 / 삭제 / 변경될 수 있어야한다고 생각했다. (데이터나 비즈니스의 특성은 언제나 달라질 수 있으므로)
따라서 프록시 초기화 관련 코드를 분리하기로 했다.
그렇다면 어떻게 분리해야할까?
사전 지식 조사와 결정에서 생각보다 오랜 시간이 걸렸다.
공통적인 기능 (프록시 초기화)를 해주는 공통 모듈을 깔끔하게 만들어낼 수 있었으면 해서 초기에는 디자인 패턴을 적용할 생각이었다.
아래는 대략적으로 조사했던 디자인 패턴들이다.
- Facade Pattern
기존 코드를 편리하게 사용할 수 있는 Wrapper 제공
기능을 정의하는 단순화된 상위 수준의 인터페이스 정의 - Adaptor Pattern
원래 코드를 다른 코드와 작동할 수 있게 하는 Wrapper 제공
한 클래스의 인터페이스를 사용하고자 하는 클래스의 인터페이스로 변환 - Proxy Pattern
실제 객체 대신 대리자 객체를 투입
주로 서브 시스템 간의 결합도를 낮출 수 있는 패턴을 조사했다.
초기에는 Facade Pattern을 사용해서 공통으로 사용할 수 있는 프록시 초기화 역할의 클래스를 만들 예정이었다.
하지만 학습할 수록 Facade에서는 하위 서브시스템을 엮어 사용할 수 있도록 하는 인터페이스의 역할이었기 때문에 서브 시스템에서 공통으로 사용할 수 있도록 하는 목적과는 오히려 정반대라고 판단해 제외했다..
가장 목적에 적합한 것은 Proxy Pattern이었지만, 프록시 초기화를 적용해야하는 클래스마다 Wrapper를 작성해야한다는 점은 큰 단점이었다.
최종적으로 눈에 들어온 것은 Spring AOP였다.
기본적으로 Proxy Pattern과 유사한 역할을 하지만, Dinamic Proxy를 적용해
구현해야할 양을 줄이고 효과적으로 분리할 수 있다는 장점에 선택하게 되었다.
그래서 적용
개념
Spring AOP
공통 기능을 분리해 핵심 로직에 영향을 미치지 않으면서 소스 코드의 중복을 감소시킬 수 있는 방법.
(여러 곳에서 사용하는 공통 코드 = Aspect 를 분리하고 핵심적인 작업만 가지도록 한다.)
Spring의 AOP는 동적 프록시를 기반으로 구현되었기 때문에 런타임에만 부가 기능을 적용할 수 있다.
비교적 간단하게 사용할 수 있지만 기능의 한계가 있고, AspectJ를 사용하면 더욱 다양한 AOP를 사용할 수 있는 것 같다.
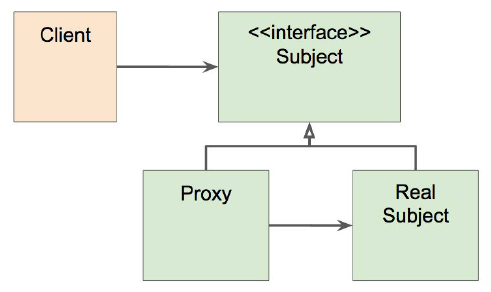
프록시 패턴 사용시 기존 기능을 변경하지 않고 기능을 추가할 수 있다.
Spring AOP는 대상인 클래스의 빈을 생성할 때 프록시를 자동으로 만들고 원본 클래스 대신 프록시를 빈으로 등록한다. (따라서 Spring 빈에만 AOP를 적용할 수 있다.)
관련 개념 정리
Aspect
AOP의 기본 모듈. 싱글톤 형태로 존재한다.
하나의 모듈로 Advice와 PointCut을 포함한다.
Target
Aspect의 Advice가 적용되는 대상 (클래스 또는 메서드)
Advice
해야할 일에 대한 정보 (부가 기능의 구현체)
Aspect가 무엇을 언제 적용할지를 정의한다.
Join point
부가 기능을 실행할 시점 (Advice의 적용 위치이자 끼어들 지점)
메서드 진입시, 생성자 호출시, 필드에서 값 가져올시 등 다양한 시점이 가능하다.
Pointcut의 후보
Pointcut
Join point의 상세 스펙을 정의한다.
Advice는 Pointcut에 의해 매칭되는 Join point에 실행되게 된다.
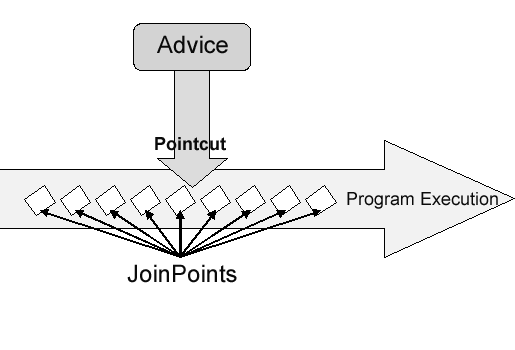
Pointcut과 Join point, Advice에 대한 이해는 여전히 어려운 것 같다.
말로만 해서는 잘 이해가 되지 않으므로 간단하게 먼저 작성해보자!
간단 적용
@RequiredArgsConstructor
@Transactional
@Service
public class TaskService {
private final UserService userService;
private final StoryService storyService;
private final ProjectService projectService;
private final TaskTagService taskTagService;
private final TaskStatusService taskStatusService;
private final TaskStatusLogService taskStatusLogService;
private final TaskRepository taskRepository;
public void testProxy() {
// 정상 실행
// System.out.println("testProxy() run!");
// 비정상 실행
System.out.println("testProxy() throw!");
throw new Error();
}
}@Aspect
@Component
@RequiredArgsConstructor
public class ProxyInitializer {
private final ProjectService projectService;
@Before("execution(public void kr.kro.colla.task.task.service.TaskService.testProxy())")
public void initializeProxyBefore() {
System.out.println("Aspect : Before");
}
@After("execution(public void kr.kro.colla.task.task.service.TaskService.testProxy())")
public void initializeProxyAfter() {
System.out.println("Aspect : After");
}
@AfterReturning("execution(public void kr.kro.colla.task.task.service.TaskService.testProxy())")
public void initializeProxyAfterReturning() {
System.out.println("Aspect : AfterReturning");
}
@AfterThrowing("execution(public void kr.kro.colla.task.task.service.TaskService.testProxy())")
public void initializeProxyAfterThrowing() {
System.out.println("Aspect : AfterThrowing");
}
}@SpringBootTest
public class AspectTest {
@Autowired
private TaskService taskService;
@Test
void checkJoinPoint() {
taskService.testProxy();
}
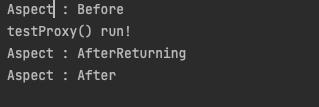
}정상 실행시 결과
비정상 실행시 결과
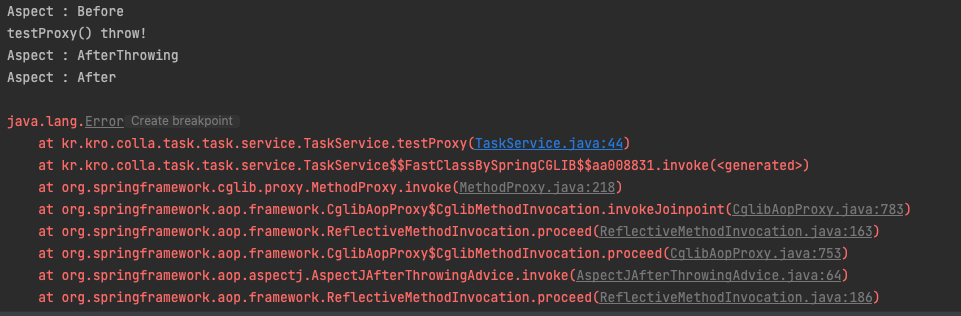
즉 메서드 실행 이전 @Before >
메서드의 정상 실행 이후인 @AfterReturning = 메서드의 비정상 실행 이후인 @AfterThrowing > 실행 이후인 @After으로 실행된다.
실제 적용
포인트컷을 통해 Advice의 적용 범위를 특정 클래스나 패키지 하위와 같이도 적용 가능하지만,
프록시 초기화의 경우 어떤 클래스의 어떤 메서드에서 사용할지 정해져있지 않으므로 커스텀 어노테이션을 작성해서 실행 시점을 지정하자.
@Retention(value = RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface ProxyInitialized {
String target() default "nothing";
}@Retention 해당 어노테이션의 정보 유지 범위 지정 (RUNTIME 런타임시)
@Target 해당 어노테이션의 사용 가능 대상을 지정 (METHOD 메서드 대상)
이때 어노테이션에서 target 문자열을 통해 프록시 초기화 대상을 명시한다.
@Aspect
@Component
@RequiredArgsConstructor
public class ProxyInitializer {
private final ProjectService projectService;
@Before("@annotation(proxyInitialized) && args(id,..)")
public void initializeProxy(ProxyInitialized proxyInitialized, Long id) throws Throwable {
String target = proxyInitialized.target();
initializeProjectProxy(id, target);
}
public void initializeProjectProxy(Long id, String type) {
Project project = projectService.findProjectById(id);
switch (type) {
case "ProjectInfo":
Hibernate.initialize(project.getStories());
case "ProjectMemberAndTaskStatus":
Hibernate.initialize(project.getTaskStatuses());
case "ProjectMember":
Hibernate.initialize(project.getMembers());
default:
break;
}
}
}@annotation(Advice 파라미터명)를 통해 커스텀 어노테이션 객체를 인자로 받는다
또한 프록시를 초기화해야할 대상과 연결된 객체의 id가 필요한 것은 공통적이기때문에 (ex) 프로젝트 멤버의 프록시 초기화면 해당 프로젝트의 id) args(id, ..)을 통해서 가장 첫번째 파라미터가 Long 타입인 메서드만 매칭되도록 제한했다.
같은 표현으로 args(Long,..)도 가능하지만 advice 내에서 파라미터로 id를 사용하기위해 위 표현으로 작성했다. (Long 이후 파라미터는 상관 X)
이때 Aspect에서 조회한 Project 객체를 이후의 TaskService로도 넘겨줄수 있지만
- 어차피 한 번 조회하고 나면 영속성 컨텍스트에 올라와있기 때문에 다시 조회하는데 소요 시간이 적다는 점
- Aspect로 인해서 Service 로직 (받는 파라미터라던가)의 변경이 일어나게되면 Aspect를 사용하는 서비스 함수 / 아닌 서비스 함수 간 차이가 발생하기 때문에 추후에 프록시를 자유롭게 적용하고 빼기 어려워질 수 있다는 점
으로 인해 넘겨주지 않고 서비스단에서 다시 조회하도록 했다.
결과적으로 다음과 같이 사용할 수 있다.
@RequiredArgsConstructor
@Transactional
@Service
public class TaskService {
//..
@ProxyInitialized(target ="ProjectMember")
public List<RoadmapTaskResponse> getStoryTasks(Long projectId, Long storyId) {
Story story = storyService.findStoryById(storyId);
List<Task> taskList = taskRepository.findStoryTasks(story);
return taskList.stream()
.map(task -> {
User manager = task.getManagerId() != null
? userService.findUserById(task.getManagerId())
: null;
return TaskResponseConverter.convertToRoadmapTaskResponse(task, manager);
}).collect(Collectors.toList());
}
}
@ProxyInitialized(target = "ProjectInfo")
public List<ProjectStoryTaskResponse> getTasksGroupByStory(Long projectId) {
Project project = projectService.findProjectById(projectId);
//..
}너무 복잡한 내부 로직은 생략했다. 위의 함수를 보면 주된 taskRepository.findStoryTasks(story)의 로직 외에도 userService.findUserById(task.getManagerId()) 와 같이 쿼리가 발생할 수 있는 조회 로직을 포함하고 있는 것을 확인할 수 있다.
결과
이제 결과를 확인해보자.
getTasksGroupByStory() 함수는 테스크를 스토리로 그룹화한 결과를 반환하는 함수지만, 테스크 엔티티는 물론이고 프로젝트의 스토리, 테스크의 현재 진행 상태, 테스크를 담당한 담당자 등 조회해야하는 엔티티 범위가 넓다.
따라서 @ProxyInitialized(target = "ProjectInfo")를 통해 프로젝트의 테스크 진행 상태, 멤버, 스토리를 프록시를 통해 미리 가져오도록 했다.
현재 데이터베이스에는 테스크 종류 6개, 사용자 2명, 테스크 30개로 상대적으로 적은 데이터량으로 결과를 뽑아봤다.
프록시 초기화 관련 코드 없을 경우
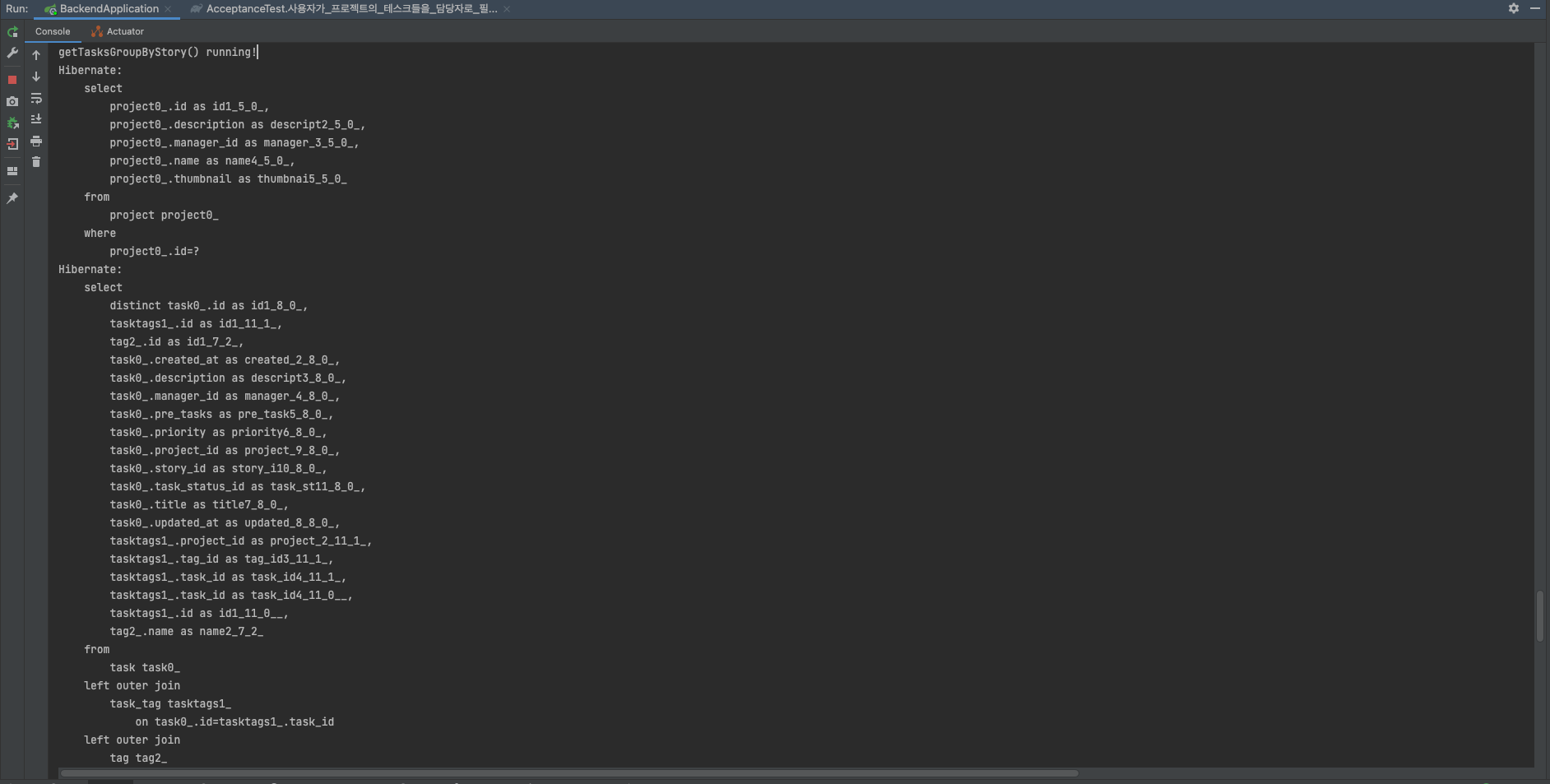
getTasksGroupByStory() running!
Hibernate:
select
project0_.id as id1_5_0_,
project0_.description as descript2_5_0_,
project0_.manager_id as manager_3_5_0_,
project0_.name as name4_5_0_,
project0_.thumbnail as thumbnai5_5_0_
from
project project0_
where
project0_.id=?
Hibernate:
select
distinct task0_.id as id1_8_0_,
tasktags1_.id as id1_11_1_,
tag2_.id as id1_7_2_,
task0_.created_at as created_2_8_0_,
task0_.description as descript3_8_0_,
task0_.manager_id as manager_4_8_0_,
task0_.pre_tasks as pre_task5_8_0_,
task0_.priority as priority6_8_0_,
task0_.project_id as project_9_8_0_,
task0_.story_id as story_i10_8_0_,
task0_.task_status_id as task_st11_8_0_,
task0_.title as title7_8_0_,
task0_.updated_at as updated_8_8_0_,
tasktags1_.project_id as project_2_11_1_,
tasktags1_.tag_id as tag_id3_11_1_,
tasktags1_.task_id as task_id4_11_1_,
tasktags1_.task_id as task_id4_11_0__,
tasktags1_.id as id1_11_0__,
tag2_.name as name2_7_2_
from
task task0_
left outer join
task_tag tasktags1_
on task0_.id=tasktags1_.task_id
left outer join
tag tag2_
on tasktags1_.tag_id=tag2_.id
where
task0_.project_id=?
order by
task0_.created_at desc
Hibernate:
select
taskstatus0_.id as id1_9_0_,
taskstatus0_.name as name2_9_0_
from
task_status taskstatus0_
where
taskstatus0_.id=?
Hibernate:
select
taskstatus0_.id as id1_9_0_,
taskstatus0_.name as name2_9_0_
from
task_status taskstatus0_
where
taskstatus0_.id=?
Hibernate:
select
taskstatus0_.id as id1_9_0_,
taskstatus0_.name as name2_9_0_
from
task_status taskstatus0_
where
taskstatus0_.id=?
Hibernate:
select
taskstatus0_.id as id1_9_0_,
taskstatus0_.name as name2_9_0_
from
task_status taskstatus0_
where
taskstatus0_.id=?
Hibernate:
select
taskstatus0_.id as id1_9_0_,
taskstatus0_.name as name2_9_0_
from
task_status taskstatus0_
where
taskstatus0_.id=?
Hibernate:
select
taskstatus0_.id as id1_9_0_,
taskstatus0_.name as name2_9_0_
from
task_status taskstatus0_
where
taskstatus0_.id=?
Hibernate:
select
stories0_.project_id as project_6_6_0_,
stories0_.id as id1_6_0_,
stories0_.id as id1_6_1_,
stories0_.end_at as end_at2_6_1_,
stories0_.pre_stories as pre_stor3_6_1_,
stories0_.project_id as project_6_6_1_,
stories0_.start_at as start_at4_6_1_,
stories0_.title as title5_6_1_
from
story stories0_
where
stories0_.project_id=?
Hibernate:
select
user0_.id as id1_12_0_,
user0_.avatar as avatar2_12_0_,
user0_.github_id as github_i3_12_0_,
user0_.name as name4_12_0_
from
user user0_
where
user0_.id=?
Hibernate:
select
user0_.id as id1_12_0_,
user0_.avatar as avatar2_12_0_,
user0_.github_id as github_i3_12_0_,
user0_.name as name4_12_0_
from
user user0_
where
user0_.id=?AOP를 통해 프록시 초기화를 적용할 경우
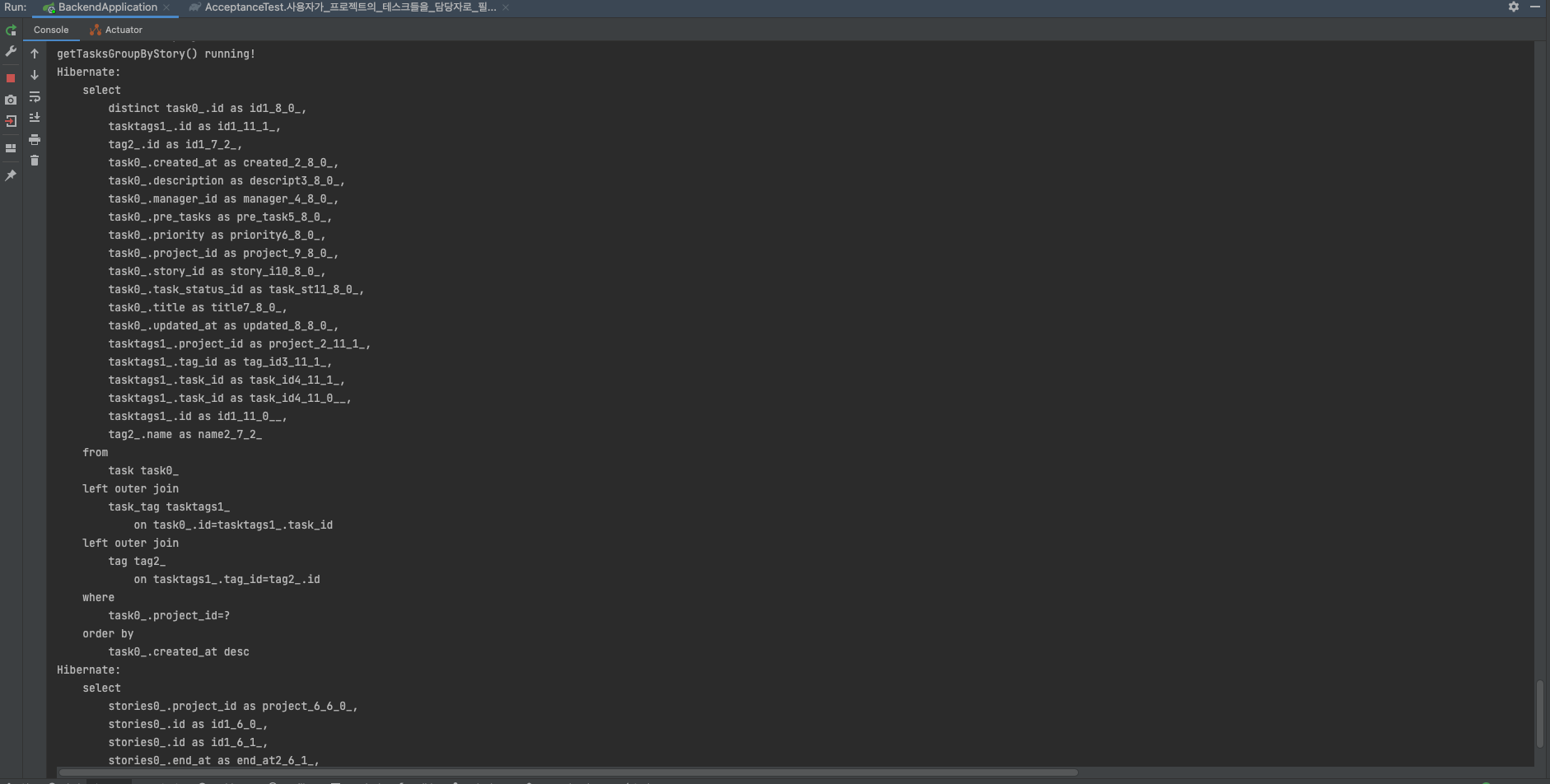
(오른쪽의 맨 하단까지 남은 스크롤바의 차이로 쿼리 정도를 알 수 있다 🤣)
getTasksGroupByStory() running!
Hibernate:
select
distinct task0_.id as id1_8_0_,
tasktags1_.id as id1_11_1_,
tag2_.id as id1_7_2_,
task0_.created_at as created_2_8_0_,
task0_.description as descript3_8_0_,
task0_.manager_id as manager_4_8_0_,
task0_.pre_tasks as pre_task5_8_0_,
task0_.priority as priority6_8_0_,
task0_.project_id as project_9_8_0_,
task0_.story_id as story_i10_8_0_,
task0_.task_status_id as task_st11_8_0_,
task0_.title as title7_8_0_,
task0_.updated_at as updated_8_8_0_,
tasktags1_.project_id as project_2_11_1_,
tasktags1_.tag_id as tag_id3_11_1_,
tasktags1_.task_id as task_id4_11_1_,
tasktags1_.task_id as task_id4_11_0__,
tasktags1_.id as id1_11_0__,
tag2_.name as name2_7_2_
from
task task0_
left outer join
task_tag tasktags1_
on task0_.id=tasktags1_.task_id
left outer join
tag tag2_
on tasktags1_.tag_id=tag2_.id
where
task0_.project_id=?
order by
task0_.created_at desc
Hibernate:
select
stories0_.project_id as project_6_6_0_,
stories0_.id as id1_6_0_,
stories0_.id as id1_6_1_,
stories0_.end_at as end_at2_6_1_,
stories0_.pre_stories as pre_stor3_6_1_,
stories0_.project_id as project_6_6_1_,
stories0_.start_at as start_at4_6_1_,
stories0_.title as title5_6_1_
from
story stories0_
where
stories0_.project_id=?프로젝트의 스토리와 테스크를 뽑는 쿼리는 패치 조인 쿼리로 같은 쿼리를 실행하지만, 존재하는 사용자(user)와 테스크 종류(task_status)에 따라 일일히 쿼리를 날리는 아래 부분을 통해 프록시 초기화의 차이를 파악할 수 있다.
따라서 Aspect로 분리하고 나서도 프록시 초기화가 제대로 적용되고 있는 것을 확인할 수 있다. 그럼 여기서 포스팅 끝! ⭐️
