자료 구조(Data Structure)
데이터 값의 모임, 각 원소들이 논리적으로 정의된 규칙에 의해 나열되며 자료에 대한 처리를 효율적으로 수행할 수 있도록 자료를 구분하여 표현한 것
- 큰 프로젝트를 만드는 경우 최종 결과물의 성능이나 구현의 어려움 등이 자료구조에 크게 의존한다.
- 데이터 처리속도를 향상하고, 처리과정 또한 단순화 할 수 있다.
- 자료 구조에서는 메모리 공간의 효율 뿐만 아니라, 실행 시간의 효율성도 따진다.
자료 구조와 알고리즘의 관계
- 알고리즘은 어떤 문제를 해결하기 위해 정해진 일련의 절차나 방법을 공식화한 형태로 표현한 것
- 같은 지식수준을 가진 사람이라면, 그 알고리즘을 보고 누구나 같은 결과를 낼 수 있어야 한다.
- 자료 구조의 선택 => 효율적인 알고리즘의 선택
자료형에 따른 분류
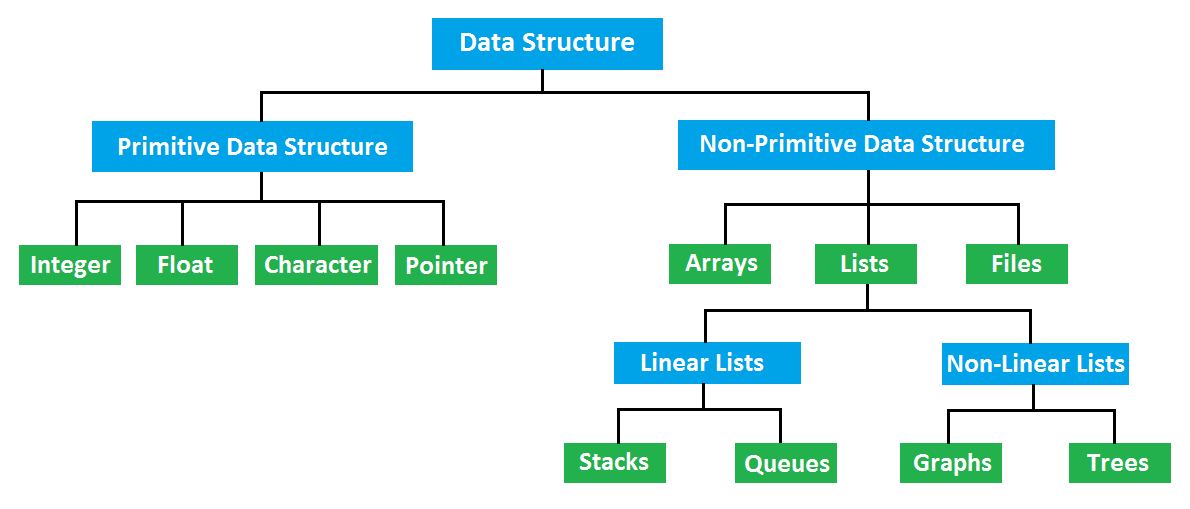
Primitive Data structure(원시 자료형)
자료를 구성하는 가장 기본적인 단위.
Integer (정수형)
수학의 int에 해당하는 단위
단, 수학에서 다루는 ‘정수’ 범위와 달리, 유한한 범위를 갖습니다.
유한한 범위는 프로그래밍 언어에 따라 약간씩 다릅니다.
Float (실수)
수학의 ‘실수’에 해당하는 단위.
실수 범위에는 유리수(rational number)와 무리수(irrational number)
단, 정수형과 마찬가지로 컴퓨터에서는 표현 범위가 한정적이므로,
정확한 소수점 아래 값을 나타낼 수 없습니다.
따라서, 소수점 몇 번째 자리까지 정확히 나타낼 수 있는지가
실수형의 범위.
Character (문자)
문자는 말 그대로 하나의 문자를 뜻합니다. 이 때 문자는 a, T, ^ 와 같이 보이는 문자 뿐만 아니라
띄어쓰기, tab, enter와 같은 공백문자(white space)도 포함.
Pointer (포인터)
포인터는 Integer나 Float, Character 처럼
그 자체로 정수, 실수, 문자처럼 의미있는 값을 갖지 않습니다.
대신에 자료형이 컴퓨터 메모리 내에서 저장된 곳,
즉, 메모리 내의 주소를 통해 자료형의 실제 값을 불러낼 수 있다.
NonPrimitive Data Structure(비원시 자료형)
Array
동일한 타입의 데이터들을 저장하며, 고정된 크기를 가지고 있다.
인덱싱이 되어 있어 인덱스 번호로 데이터에 접근할 수 있다.
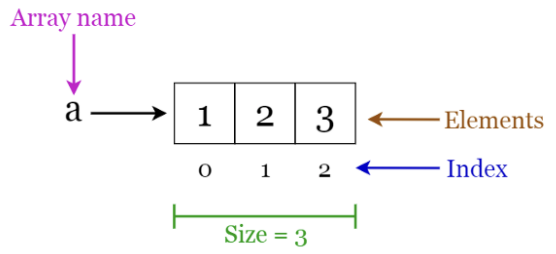
- 배열 목록, 힙, 해시 테이블, 벡터 및 행렬과 같은 기타 데이터 구조를 구축하기 위한 빌딩 블록으로 사용
- 삽입 정렬, 빠른 정렬, 버블 정렬 및 병합 정렬과 같은 다양한 정렬 알고리즘에 사용
Linked List
각 데이터 시퀀스가 순서를 가지고 연결된 순차적 구조
동적인 데이터 추가/삭제에 유리하다.

- 각 요소는 Node
- 각 Node에는 key와 다음 노드를 가리키는 포인터인 next가 포함
- 첫 번째 요소는 Head
- 마지막 요소는 Tail→ Alt + Tab을 사용하여 프로그램 간 전환
→ 갤러리
사실 위 배열과 연결 리스트는 아래의 자료 구조들을 구현하는 데 사용되는 기본 자료 구조들이다.
Linear lists
Stack(스택)
순서가 보존되는 선형 데이터 구조
가장 마지막 요소(가장 최근 요소)부터 처리하는 LIFO (Last In First Out)
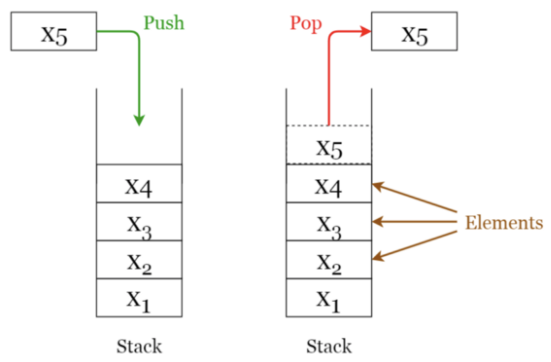
→ 실행 취소
→ 수학적 표현식을 구문 분석하고 평가
→ 재귀 프로그래밍에서 함수 호출을 구현
Queue(큐)
가장 먼저 입력된 요소를 처리하는 FIFO (First In First Out)
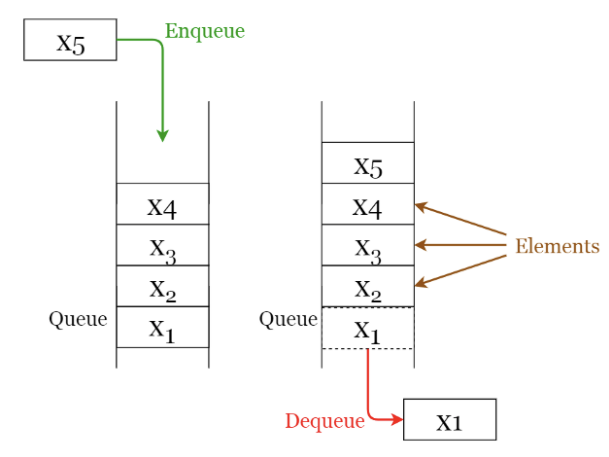
→ 멀티스레딩에서 스레드를 관리
→ 대기열 시스템
Non-Linear List
Graph(그래프)
- nodes/vertices(노드) 사이에 edge(엣지)가 있는 collection
- directed(방향) 그래프는 일방통행
- undirected(무방향) 그래프는 양방향
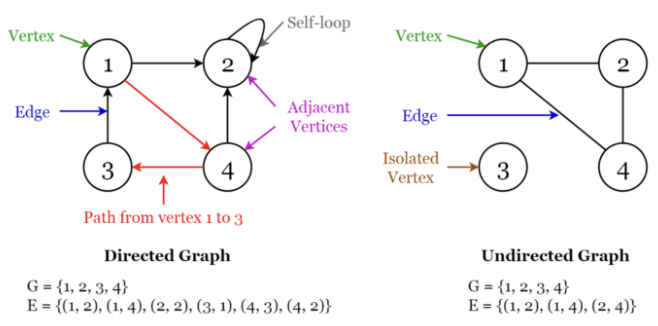
→ 소셜 미디어 네트워크를 나타내는 데 사용
→ 검색 엔진에 의해 웹 페이지 및 링크를 나타내는 데 사용
→ GPS에서 위치와 경로를 나타내는 데 사용
Tree(트리)
- 그래프가 계층적 구조를 가진 형태
- 최상위 노드(루트)를 가지고 있음
- 상위 노드를 부모(parent) 노드, 하위 노드를 자식(child) 노드라 한다.
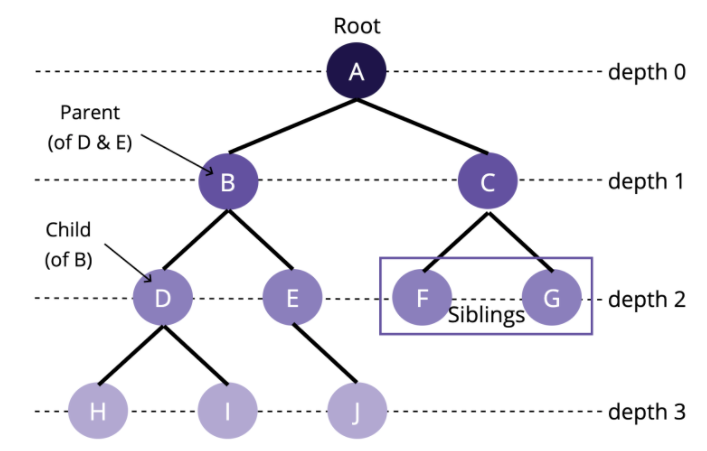
→ Binary Trees(이진트리)
→ Binary Search Tree(이진 검색 트리)
→ Heap(힙)
추가
Hash table(해시 테이블)
- 해시함수를 사용하여 변환한 값을 색인(index)으로 삼아 키(key)와 데이터(value)를 저장하는 자료구조
- 데이터의 크기에 관계없이 삽입 및 검색에 매우 효율적
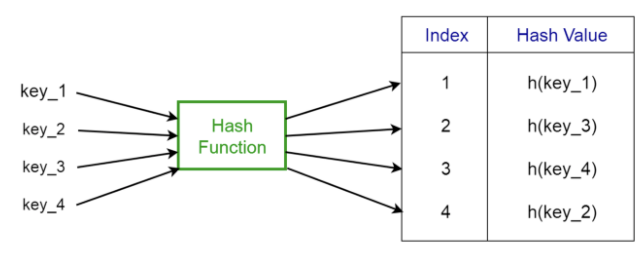
→ 데이터베이스 인덱스 구현
→ 사용자 로그인 인증
→ "set" 데이터 구조 구현
보통 테이블 내에 더 작은 서브그룹인 버킷(bucket)에 키/값(key/value) 쌍(pair)을 저장한다.
단, 충돌이 자주 일어날 수 있으며 이를 위해 다양한 방법으로 해시 함수를 개선하거나 해시 테이블의 구조 개선(chaining, open addressing 등)의 방법이 사용된다.
Heap(힙)
Binary Tree(이진트리)
최소 힙 : 부모의 키 값이 자식의 키 값보다 작거나 같다.
=> 루트 노드의 키 값이 트리의 최솟값
최대 힙: 부모의 키 값이 자식의 키 값보다 크거나 같다.
=> 루트 노드의 키 값이 트리의 최댓값
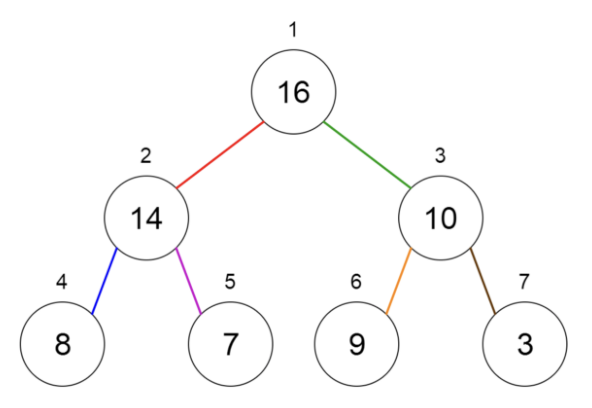
→ 힙 정렬 알고리즘
→ 우선순위 큐
References
