SYNACKTIV 분석 보고서
https://www.synacktiv.com/publications/php-filters-chain-what-is-it-and-how-to-use-it
PHP Wrapper
PHP Manual
https://www.php.net/manual/en/wrappers.php
<?php
$file = $_GET['file_name'];
include('file_name'+'.php');
?>위와 같은 코드에서 사용자의 입력 값을 필터링 없이 include() 함수의 인자로 보내는 경우 LFI 공격에 취약함을 안다.
ㅡ
www.victim.com/index.php?file=../../../../../../etc/passwd기본적인 LFI 공격의 경우 Path Traversal 공격과 함께 사용되는 경우가 많아, 위 file 파라미터와 같이 공격이 이루어지곤 한다.
그러나, 위 include 함수를 확인해 보면 자동으로 .php 확장자를 추가하여 include 하고 있어 위 file 파라미터와 같이 공격할 경우 /etc/passwd을 읽어올 수 없게 된다.
ㅡ
www.victim.com/index.php?file=../../../../../../etc/passwd/(NULL Byte)보통 이런 경우 /etc/passwd뒤에 NULL Byte를 추가하여 확장자를 떼내는 우회를 시도하곤 했는데, 이는 PHP 버전이 상승하면서 NULL 바이트가 확인될 경우 더 이상 읽어오지 않게 되면서 NULL Byte를 통한 우회법이 통하지 않게 되었다.
ㅡ
<?php
var_dump(stream_get_wrappers());
?>
array(10) {
[0]=>
string(5) "https"
[1]=>
string(4) "ftps"
[2]=>
string(13) "compress.zlib"
[3]=>
string(3) "php"
[4]=>
string(4) "file"
[5]=>
string(4) "glob"
[6]=>
string(4) "data"
[7]=>
string(4) "http"
[8]=>
string(3) "ftp"
[9]=>
string(4) "phar"
}이를 해결하기 위해 PHP Wrapper를 사용한다. 본래, PHP Wrapper는 PHP 기본 내장 기능으로, 파일 시스템 함수와 함께 개발자의 편의를 위해 사용하는 URL 스타일 프로토콜이다. 보통 많이 보는 http://, https://도 웹 통신을 위한 wrapper라고 볼 수 있다. 이 중 php:// wrapper에 집중할 예정이다.
ㅡ
php://filter/convert.base64-encode/resource=/etc/passwdphp:// wrapper는 filter와 encode/decode옵션을 함께 사용할 수 있는데, 이를 통해 LFI 공격 시 다양한 필터링을 우회할 수 있다.
ㅡ
include('file_name'+'.php');다음과 같은 코드에 file_name 파라미터 값을 wrapper에 encode 옵션과 함께 사용해주면, .php가 붙은 파일을 직접적으로 실행하지 않고, 파일의 데이터를 encode하여 가져와 .php 확장자를 우회하여 원하는 파일의 내부 데이터를 읽어올 수 있다.
php://convert.iconv
세상에 많은 언어와 이모티콘 등 다양한 문자를 컴퓨터에서 지원하기 위해, 다양한 인코딩이 만들어져 있다.
$ iconv -l
The following list contains all the coded character sets known. This does
not necessarily mean that all combinations of these names can be used for
the FROM and TO command line parameters. One coded character set can be
listed with several different names (aliases).
437, 500, 500V1, 850, 851, 852, 855, 856, 857, 858, 860, 861, 862, 863, 864,
865, 866, 866NAV, 869, 874, 904, 1026, 1046, 1047, 8859_1, 8859_2, 8859_3,
8859_4, 8859_5, 8859_6, 8859_7, 8859_8, 8859_9, 10646-1:1993,
10646-1:1993/UCS4, ANSI_X3.4-1968, ANSI_X3.4-1986, ANSI_X3.4,
ANSI_X3.110-1983, ANSI_X3.110, ARABIC, ARABIC7, ARMSCII-8, ARMSCII8, ASCII,
ASMO-708, ASMO_449, BALTIC, BIG-5, BIG-FIVE, BIG5-HKSCS, BIG5, BIG5HKSCS,
BIGFIVE, BRF, BS_4730, CA, CN-BIG5, CN-GB, CN, CP-AR, CP-GR, CP-HU, CP037,
CP038, CP273, CP274, CP275, CP278, CP280, CP281, CP282, CP284, CP285, CP290,
CP297, CP367, CP420, CP423, CP424, CP437, CP500, CP737, CP770, CP771, CP772,
CP773, CP774, CP775, CP803, CP813, CP819, CP850, CP851, CP852, CP855, CP856,
CP857, CP858, CP860, CP861, CP862, CP863, CP864, CP865, CP866, CP866NAV,
CP868, CP869, CP870, CP871, CP874, CP875, CP880, CP891, CP901, CP902, CP903,
CP904, CP905, CP912, CP915, CP916, CP918, CP920, CP921, CP922, CP930, CP932리눅스에서는 iconv 명령어의 -l 옵션을 통해 리눅스에서 지원하는 다양한 인코딩 테이블의 목록을 확인할 수 있다.
ㅡ
convert.iconv.<input-encoding>.<output-encoding>
convert.iconv.<input-encoding>/<output-encoding>변환 테이블의 인코딩 방식은 php에서 iconv가 활성화 되어 있는 경우, php://convert.iconv.*.* wrapper로 접근 가능하다. 기본적으로 위와 같이 입력 인코딩과 출력 인코딩 방식을 같이 적어주는 방식으로 사용된다.
ㅡ
$file = file_get_contents('php://convert.iconv.UTF-8/ISO-8859-1/resource=file.txt');예시로, file.txt 파일을 UTF-8에서 ISO-8859-1 인코딩 방식으로 변환하여 file 변수에 저장하도록 할 수 있다.
base64decode
디코딩 과정에서 쓰레기 값이 발생하는 경우 php에서 base64의 디코딩은 흥미롭게 작동한다.
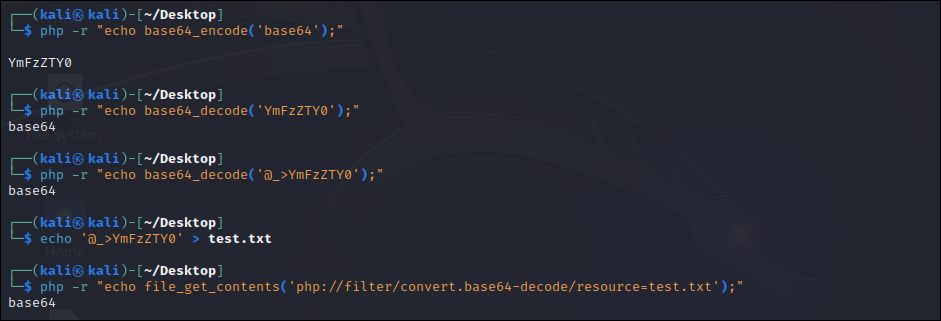
사진을 확인해 보면, base64 디코딩 과정에서 값에 @_>를 추가하더라도, 오류가 발생하지 않고 존재하지 않는 것처럼 추가하지 않은 값과 동일한 결과를 보인다는 점이다.
또한, php의 base64-decode 필터와 유사한 기능을 하는 base64_decode 함수는 =(등호)를 다루는 점에서 필터와 다르게 동작한다.
ㅡ
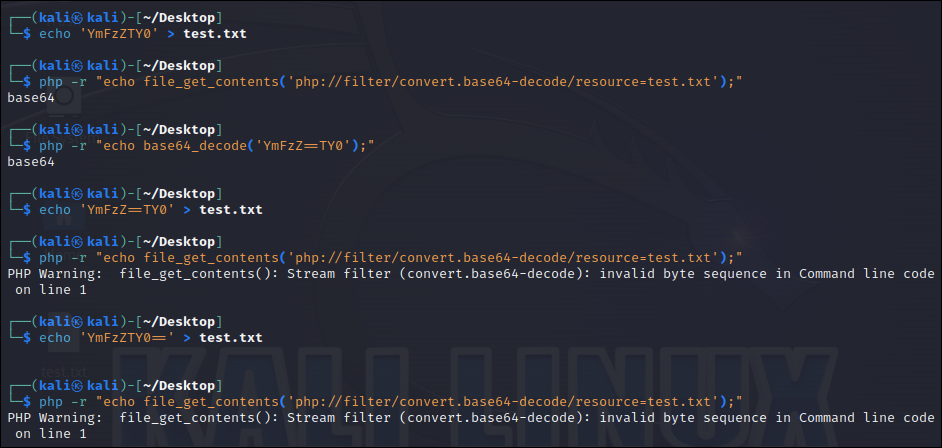
위 사진에서 볼 수 있는 것처럼, base64-decode 필터는 =에 대해 올바른 패딩으로 인식하지 못 하고 잘못 처리하는 것을 볼 수 있다.
ㅡ

즉, base64-decode 필터를 올바르게 사용하기 위해서는 =를 제거하는 과정이 필요한데, 이를 UTF-7 인코딩을 통해 해결할 수 있다.
다음과 같이 UTF-7 인코딩은 =를 다른 문자로 변환하여 base64 디코딩 시 영향을 미치지 않도록 한다.
Unicode BOM
@_>를 추가해도, 동일하게 decode되는 것을 이해하기 위해선 인코딩 RFC를 살펴봐야 한다.
The Unicode Standard and ISO 10646 define the character "ZERO WIDTH
NON-BREAKING SPACE" (0xFEFF), which is also known informally as "BYTE
ORDER MARK" (abbreviated "BOM").This usage, suggested by Unicode
and ISO 10646 Annex F (informative), is to prepend a 0xFEFF character
to a stream of Unicode characters as a "signature"; a receiver of such
a serialized stream may then use the initial character both as a hint
that the stream consists of Unicode characters and as a way to recognize
the serialization order.
In serialized UTF-16 prepended with such a signature, the order is
big-endian if the first two octets are 0xFE followed by 0xFF; if they
are 0xFF followed by 0xFE, the order is little-endian. Note that
0xFFFE is not a Unicode character, precisely to preserve the
usefulness of 0xFEFF as a byte-order mark.몇 인코딩에서는 인코딩 시 결과 값 앞에 바이트의 순서를 시스템에서 지정하기 위해 BOM(Byte of Mark)이라는 것을 추가한다. 예를 들어 위 RFC-2781을 참고해 보면, UTF-16에서 특정한 signature를 추가하는데, 이를 통해 big-endian 순서인지 little-endian 순서인지를 판단한다. 여기서 중요한 점은 디코딩 시에 BOM은 무시된다는 점이다.
ㅡ
$ php -r "echo base64_decode('@_>YmFzZTY0');"
base64그래서, @_>를 추가하여도 base64-decode 필터는 이를 BOM으로 인식하여 무시하고 디코딩한다는 것을 알 수 있다.
Korean Character encoding for Internet Messages
It is assumed that the starting code of the message is ASCII. ASCII
and Korean characters can be distinguished by use of the shift
function. For example, the code SO will alert us that the upcoming
bytes will be a Korean character as defined in KSC 5601. To return
to ASCII the SI code is used.
Therefore, the escape sequence, shift function and character set used
in a message are as follows:
SO KSC 5601
SI ASCII
ESC $ ) C Appears once in the beginning of a line
before any appearance of SO characters.인터넷 메세지에서 한국어를 처리하기 위해 한글 문자 인코딩 (ISO-2022-KR)이 탄생했으며 이는, RFC-1557에 자세히 명시되어 있다. 또한, RFC-1557에 따르면, ISO-2022-KR 인코딩은 ESC $ ) C로 시작해야 한다.
ㅡ
<?php
$iso_2022_7bits_encodings = array('ISO-2022-CN', 'ISO-2022-CN-EXT', 'ISO-2022-JP', 'ISO-2022-JP', 'ISO-2022-JP-2', 'ISO-2022-KR');
foreach ($iso_2022_7bits_encodings as $elem){
echo "[$elem] : hex [";
echo bin2hex(iconv('UTF8',$elem, 'START'))."]\n";
}
이건 좀 신기했는데, ISO-2022에 중국어, 일본어 등 다양한 인코딩들이 속해 있지만, iconv에서 사용 가능한 유일한 인코딩은 한국어 뿐이며, ISO-2022-KR에서만 BOM이 붙는 것을 확인할 수 있다.
TRANSFORM THEM AND GET WHAT YOU WANT
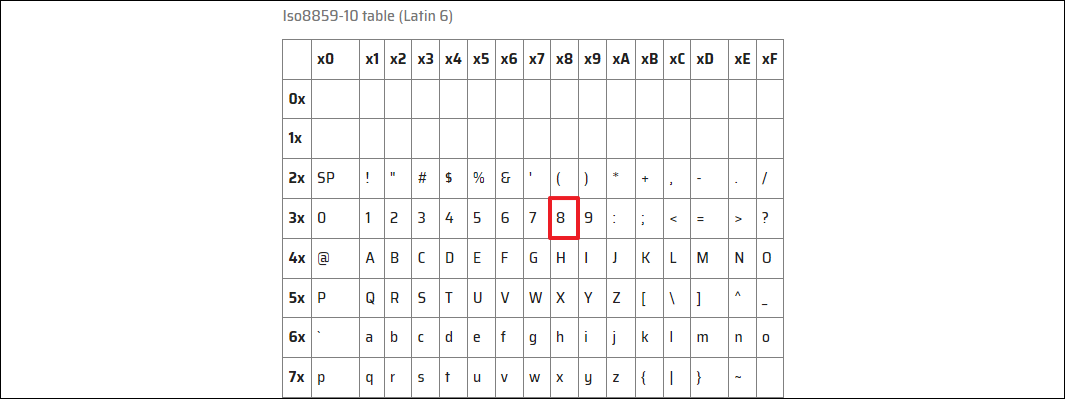
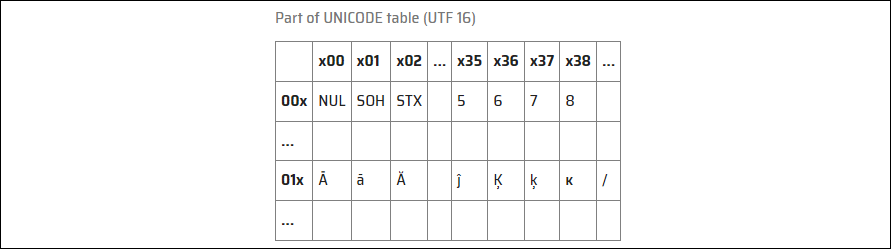 앞서 설명한 BOM과 인코딩을 통해 우리가 원하는 문자를 삽입할 수 있다. 원하는 문자 중 8을 만든다고 가정해 보자. 이때, 8을 얻기 위해선 ISO8859-10(Latin 6) 테이블과 Unicode 테이블을 필요로 한다.
앞서 설명한 BOM과 인코딩을 통해 우리가 원하는 문자를 삽입할 수 있다. 원하는 문자 중 8을 만든다고 가정해 보자. 이때, 8을 얻기 위해선 ISO8859-10(Latin 6) 테이블과 Unicode 테이블을 필요로 한다.
ㅡ
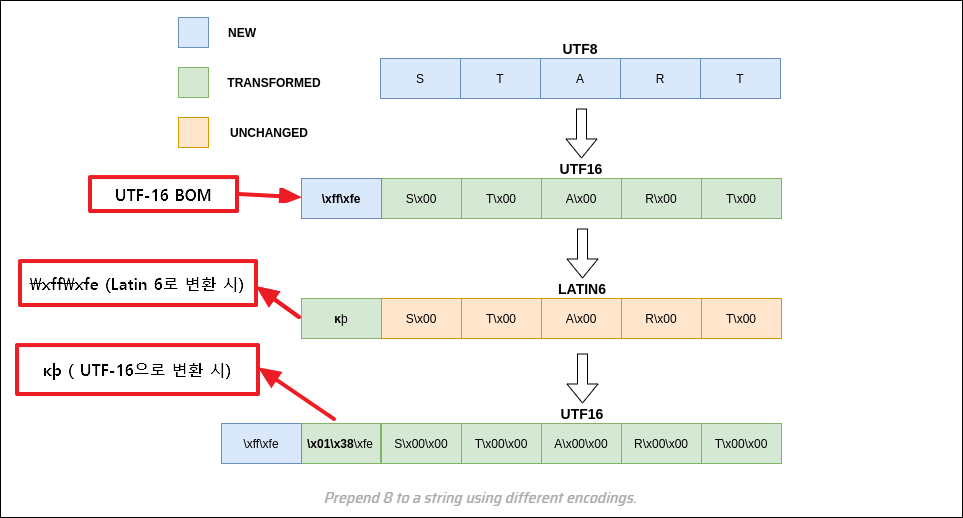
가장 처음 UTF-8로 인코딩 된 START란 글자가 UTF-16으로 인코딩 되는 과정에서 \xff\xfe란 UTF-16 BOM이 붙는다.
ㅡ
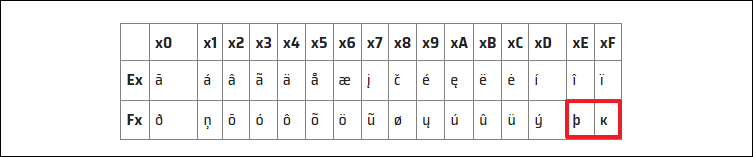
이때 다시 Latin 6으로 변환하면, UTF-16의 BOM인 \xff\xfe가 ĸþ란 문자로 바뀌게 된다.
ㅡ
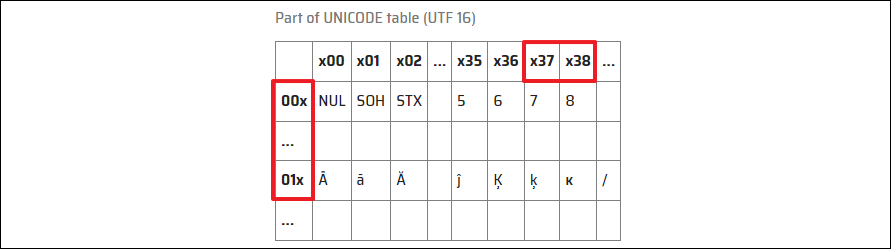
다시 UTF-16으로 변환하게 되면, 맨 앞에 BOM이 다시 붙고 ĸþ 문자는 각각 \x01\x38, \x00\xfe로 변환되고, 출력하는 과정에서 \x01\x38\x00\xFE는 UTF-8로 변환되게 된다.
이때, \x38이 우리가 원하는 8이란 글자로 변환된다.
ㅡ
<?php
$return = iconv( 'UTF8', 'UTF16', "START");
echo(bin2hex($return)."\n");
echo($return."\n");
$return2 = iconv( 'LATIN6', 'UTF16', $return);
echo(bin2hex($return2)."\n");
echo($return2."\n");
확인한 과정을 PHP 코드로 생성하여 확인 시 8과 기존 단어인 START를 이쁘게 확인할 수 있다.