내일부터 팀 숙제
9시에서 10시까지 준비, 10시부터 코드 리뷰, 각자 강의 준비
숙제 1, 코드 리뷰 받고 싶은 코드 1개 링크
숙제 2. 책 읽고 설명 준비 (내일은 1.4까지)
내일 할 거
- 수 정렬하기 2 - 2751 : 내장함수로 날먹했던거 정성 들여서 정렬 구현해보기
- 쉬운 문제들 다 풀어보기 : 안 풀리는 건 답지 보고 이해하고 넘기기
- 넘겼던 문제들 이해하기 : 백지에서 내가 풀 수 있을 정도로
- CSAP 1장 끝까지 읽고 정리
배운 것들
정렬
- 버블 정렬 : 배열을 순회하며 인접한 두 숫자를 비교하여 위치를 바꾸는 작업을 반복
- 선택 정렬 : 수열에서 최솟값을 찾아서 가장 왼쪽으로 넣는 작업을 반복
- 삽입 정렬 : 오른쪽의 미탐색 영역에서 숫자를 하나씩 꺼내서 정렬이 끝난 왼쪽 영역의 적절한 위치에 삽입하는 작업을 반복
- 힙 정렬 : 힙이라는 데이터 구조를 사용한다 (빠른데 구현이 더 어려움)
- 병합 정렬 : 모든 숫자를 각각 그룹으로 나눈 후에 합치며 정렬한다
- 퀵 정렬 : 피봇을 하나 정한 뒤에 작은 건 왼쪽에 정렬, 큰 건 오른쪽에 정렬한 뒤 그 정렬된 그룹도 또 피봇 하나 정해서 왼쪽 오른쪽 정렬
def bubble_sort(a: MutableSequence) -> None:
- a: MutableSequence: 매개변수 a는 MutableSequence 타입이어야 합니다.
- -> None: 이 함수는 반환값이 없습니다.
동적 계획법
조금 장난스럽게 말해서 답을 재활용하는 거다. 앞에서 구했던 답을 뒤에서도 이용하고, 옆에서도 이용하고...엄밀히 말해 동적 계획법은 구체적인 알고리즘이라기보다는 문제해결 패러다임에 가깝다. 동적 계획법은 "어떤 문제를 풀기 위해 그 문제를 더 작은 문제의 연장선으로 생각하고, 과거에 구한 해를 활용하는" 방식의 알고리즘을 총칭한다.
공백으로 구분된 문자열 세트로 저장하는 법
S_find = {input().split()}
이렇게 하면 세트로 저장되는거 맞지?
{input().split()} 표현은 예상한 대로 동작하지 않습니다. 이는 세트가 아닌 중첩된 리스트를 포함하는 세트를 생성합니다.
예를 들어, 입력이 1 2 3이라면, input().split()은 ['1', '2', '3']을 반환하고, {['1', '2', '3']}는 중첩된 리스트를 포함하는 세트를 생성하게 됩니다.
S_find = set(input().split())위와 같이 set() 생성자를 사용하여 입력된 문자열을 공백으로 분할한 후 각 요소를 세트에 추가할 수 있습니다.
이 코드는 입력된 문자열을 공백으로 분할한 후 각 단어를 세트의 요소로 추가합니다. 예를 들어, 입력이 1 2 3이면, S_find는 {'1', '2', '3'}이 됩니다.
백준
9663 N-Queen
# 하노이탑처럼 문제를 정성적으로 이해해야 하는줄 알고
# 가로세로, 대각선의 의미를 생각해보았는데, 전혀 풀리지 않아
# 검색해서 백트래킹으로 풀어야 한다는 힌트를 봄
# 단순히 경우의 수를 세야 하는 문제들도 있는듯
# 슈도 코드
# 체스판을 1/4로 나눔, 1/4 판떼기에서 한 칸씩 놓기 시작
# 배열 1 : 체스판 배열, 퀸이 놓인 칸은 1, 없는 칸은 0
# 배열 2 : 백트래킹 전부 해본 체스 좌표, (N/4,N/4) 크기
# 재귀 함수 선언
# '배열 1'에 '배열 2'를 삽입한다
# 1/4 판떼기에 퀸을 하나 놓는다
# 전체 체스판에서 지금 놓인 퀸이 공격 가능한 영역에 1을 삽입
# 남아있는 체스가 있다면 '배열 1'과 '배열 2'를 제외한 공간에 체스를 하나 놓는다
# 남아있는 체스가 1개인데 놓을 자리가 없다면 return None
# 남아있는 체스가 0개라면 return count++
# 슈도 코드 (최적화 시도 x)
# (N,N)의 행렬로 만든 체스판에 퀸을 하나 놓는다.
# 놓은 위치와 공격 가능한 위치를 1로 표시한다.
# 0이 있는 위치에 다음 퀸을 놓고 퀸 개수 -1
# 안되면 return None
# 퀸 개수가 0이면 return count++
# 남은 퀸 개수와 행렬을 함수에 넣는다.처음 짰던 슈도 코드
def Nqueen(Qn, matrix):
# 0을 찾아서 퀸을 하나 표시한다
i, q = 0, 0
for i in range(N):
if 0 in matrix[i]:
q = matrix[i].index(0)
elif i == N-1:
return None
matrix[i][q] = 1
# 가로세로 공격 가능한 위치를 표시한다
for row in range(N):
matrix[row][q] = 1
for col in range(N):
matrix[i][col] = 1
# 대각선 공격 가능한 위치를 표시한다
ru = 1
while i+ru < N and 0 <= q-ru:
matrix[i+ru][q-ru] = 1
ru += 1
rd = 1
while i+rd < N and q+rd < N:
matrix[i+rd][q-rd] = 1
rd += 1
ld = 1
while 0 <= i-ld and q+ld < N:
matrix[i-ld][q-ld] = 1
ld += 1
lu = 1
while i+lu < N and 0 <= q-lu:
matrix[i+lu][q-lu] = 1
lu += 1
# 퀸 개수를 하나 줄인다
Qn -= 1
if Qn == 0:
count += 1
return None
else:
matrix[i][q] = 0
Nqueen(Qn, matrix)
N = int(input())
matrix = [[0] * N for _ in range(N)]
count = 0
Nqueen(N, matrix)
print(count)시도했던 코드 1. 공격 가능한 위치를 회수하지 않아 백트래킹 안됨.
함수 처리하고 0 요청과 1 요청을 구분하면 재활용할 수도 있을 것 같긴 한데,
일단 정답 (행렬에는 퀸 위치만 업데이트, 공격 가능한 위치 탐색) 방향으로 다시 짜봄
def isSafe(location, matrix):
# 가로세로 공격 가능한 위치를 검사한다
i = location[0]
j = location[1]
for row in range(N):
if matrix[row][j] == 1 :
return False
for col in range(N):
if matrix[i][col] == 1 :
return False
# 대각선 공격 가능한 위치를 검사한다
for k in range(1, N):
if i + k < N and j + k < N and matrix[i + k][j + k] == 1:
return False
if i + k < N and j - k >= 0 and matrix[i + k][j - k] == 1:
return False
if i - k >= 0 and j + k < N and matrix[i - k][j + k] == 1:
return False
if i - k >= 0 and j - k >= 0 and matrix[i - k][j - k] == 1:
return False
# 아무 퀸도 공격 못하면 True
return True
# 해당 체스판에 queen이 들어갈 경우의 수 구하는 함수
def Nqueen(Qn, matrix):
global count
# 남은 퀸이 없다면 경우의수 +1
if Qn == 0:
count += 1
return
# 퀸이 들어갈 수 있는 위치를 순회한다
for i in range(N):
for j in range(N):
if matrix[i][j] == 0:
if isSafe([i,j],matrix):
matrix[i][j] = 1
Nqueen(Qn-1, matrix)
matrix[i][j] = 0
N = int(input())
matrix = [[0] * N for _ in range(N)]
count = 0
Nqueen(N, matrix)
print(count)정답 슬쩍슬쩍 보면서 기존 코드 재활용하면서 코드 짜봤는데 작동 제대로 안 함.
일단 보류하고 기초적인 문제들 먼저 풀어보기로 함.
이렇게 막혀서 지능 딸리는거 절감할 땐 공부를 어떻게 해야할지 막막하다.
1181 단어 정렬
import sys
from collections import defaultdict
N = int(sys.stdin.readline().strip())
S = {sys.stdin.readline().strip() for _ in range(N)}
D = defaultdict(list)
L = sorted(S)
L.sort()
N = len(L)
for i, string in enumerate(L):
D[len(string)].append(string)
for key in sorted(D.keys()):
for string in D[key]:
print(string)for key in sorted(D.keys())
- D.keys()는 D의 모든 키를 반환합니다.
- sorted(D.keys())는 키를 정렬하여 반환합니다.
- 정렬된 키를 순서대로 순회합니다.
for string in D[key]
- 각 키에 대해 해당 키의 값(문자열 리스트)을 순회합니다.
- 예를 들어, key가 5일 때 D[key]는 ["apple"]입니다.
쓰레기같이 풀기도 하고 gpt 힘도 빌렸어서 다른 사람 코드를 좀 봄.
원래 생각했던 정공법인 정렬을 이용했길래 정렬로 다시 풀어보기로 함.
for i in range(N-1):
for j in range(N-1, i, -1):
if len(S[j]) < len(S[j-1]):
S[j], S[j-1] = S[j-1], S[j]
elif len(S[j]) == len(S[j-1]):
if S[j] < S[j-1]:
S[j], S[j-1] = S[j-1], S[j]기본 버블 정렬 썼더니 시간 초과 뜸
import sys
N = int(sys.stdin.readline().strip())
S = [sys.stdin.readline().strip() for _ in range(N)]
for i in range(N-1):
for j in range(N-1, i, -1):
if len(S[j]) < len(S[j-1]):
S[j], S[j-1] = S[j-1], S[j]
elif len(S[j]) == len(S[j-1]):
if S[j] < S[j-1]:
S[j], S[j-1] = S[j-1], S[j]
print(S[0])
for i in range(1,N):
if S[i] != S[i-1]:
print(S[i])정렬 다 끝나면 굳이 더 안 돌리게 최적화해서 통과는 했는데
기존 날먹 방법 대비 시간이 너무 오래 걸림.
날먹은 212ms 걸렸고 이건 4064ms걸림.
import sys
N = int(sys.stdin.readline().strip())
S = [sys.stdin.readline().strip() for _ in range(N)]
for i in range(N-1):
k = 0
while k < n-1:
last = n-1
for j in range(N-1, k, -1):
if len(S[j]) < len(S[j-1]):
S[j], S[j-1] = S[j-1], S[j]
last = j
elif len(S[j]) == len(S[j-1]):
if S[j] < S[j-1]:
S[j], S[j-1] = S[j-1], S[j]
last = j
k = last
for i in range(N):
if S[i] != S[i-1]:
print(S[i])아니 근데 왜 이건 시간 초과 뜨는건지 모르겠음
단어 사전순 정렬 때문에 생각보다 효율적이지 않은 건 알겠는데 시간 초과가 뜨면 안되지 않나?
셰이커 정렬 써보려고 했는데 문제 조건까지 적용시키기 조금 복잡해서 일단 넘어감
10971 외판원 순회 2
https://sangju.tistory.com/13
에서 정답 코드를 찾았는데 흐름을 보면서 따라가고 이해할 수는 있어도
도저히 이걸 혼자서 코드 짤 자신이 없음
N = int(input())
S = [list(map(int, input().split())) for _ in range(n)]
def dfs(depth, x):
if depth == n-1:
# 최대 깊이일 때 해야할 것
# 출발했던 도시로 돌아온다
# 만약 다 더한게 최소값이면 합계를 최소값으로 바꾼다
# 합계를 다시 되돌린다
return
for i in range(1, n): # 출발 도시는 상관 없으니 도시 1~n-1을 검토한다
if visited[i] == 0 and costs[x][i]: # 방문 안 한 도시이고 방문 가능하다면
# 배열에 방문했다고 표시한다
# 방문 비용을 합친다
# 다음 도시로 이동한다 (재귀함수)
# 이동했던 합계, 배열 취소한다
dfs(0,0)
print(sum_cost)일단 슈도 코드 짜봤는데 이래도 아직 모르겠음 일단 다음 걸로 넘어가봐야할듯
근데 다음 문제 2468 안전영역은 더 어려움 ㅅㅂ
1920 수 찾기
날먹으로 풀면 터무니 없이 쉬울 것 같아서
다루는 주제 : 이분 탐색이라길래 일단 이분 탐색을 시도해보기로 함.
N = int(input())
S = input().split()
M = int(input())
S_find = input().split()
def BSA(start, idx_half, end, compare):
# 배열 S의 현재 영역의 절반에 있는 인덱스에 있는 값을 compare와 비교함
# compare가 S[idx_half]보다 작으면 idx_half => end, (start + idx_half)/2 => idx_half
# compare가 S[idx_half]보다 크면 idx_half => start, (idx_half + end)/2 => idx_half
print(start, idx_half, end, compare)
if start == end:
if compare == S[idx_half]:
return 1
else:
return 0
if compare < S[idx_half]:
BSA(start, (start + idx_half)//2, idx_half, compare)
else:
BSA(idx_half, (idx_half + end)//2, end, compare)
for i in range(M):
print(BSA(0, len(S)//2, len(S), S_find[i]))처음 짠 코드는 예제 입력을 넣어봤더니 1 1 2 1이 무한히 반복됨.
쓰레기 코드.
굳이 재귀를 쓸 이유가 있나 생각이 들어서 반복문으로 하기로 함.

뭔가 익숙한 궁금증이어서 정리했던 거 찾아봤더니 어제 짤막 강의에 나왔던 내용.
문제가 정렬 후에 탐색하는 문제라서 정렬을 먼저 시켜줘야 한다
gpt한테 무슨 알고리즘 고를지 물어봤더니
- 퀵 정렬(Quick Sort)
- 병합 정렬(Merge Sort)
- 힙 정렬(Heap Sort)
대충 이 3가지가 O(n log n) 알고리즘이라 일반적인 상황에서 효율적이라고는 하는데
세가지 다 구현 안 해봤고 뭘 해야될지도 모르겠고
결정적으로 이분 탐색을 해보라고 준 문제일테니 일단 정렬은 내장 함수로 날먹하고 이분 탐색 구현에 집중했다
N = int(input()) # 사막 크기
S = input().split() # 사막
M = int(input()) # 바늘 개수
S_find = input().split() # 찾아야 하는 바늘들
S.sort()
for i in range(M):
isIn = 0
need = S_find[i]
start = 0
idx_half = N//2
end = N
# 이분 탐색
while (start != end):
# 배열(혹은 현재 범위) 중앙에 있는 값을 확인
# 찾는 숫자와 중앙의 값을 비교
# 필요하지 않은 숫자들 제외
# 반복
if S[idx_half] == need:
isIn = 1
# print('same')
break
elif S[idx_half] < need:
start = idx_half + 1
idx_half = (start+end)//2
# print('smaller')
else: # S[idx_half] > need:
end = idx_half -1
idx_half = (start+end)//2
# print('bigger')
print(isIn)근데 시간 초과 떴음. gpt한테 물어보니까 이것도 무한 반복 되는 경우 있다고 함.
쓰레기 코드.
gpt가 정답을 주긴 했는데 내 코드 좀만 다듬으면 될 것 같아서 주석을 정리하고 다시 확인해보기로 함.
while (start != end):이걸
while (start <= end):이걸로 바꿨더니 인덱스 오류 남.
그것도 특수 케이스가 아니라 예제 케이스에서 바로.
배열에 없는 값인 7을 찾을 때
!= 조건을 걸어주면 올라가다가 인덱스 5에서 멈추는데
<= 조건을 걸면 한 번 더 올라가서 인덱스 오류 일으킴.
< 조건으로 바꿔줬더니 오류 없어졌다.
물론 백준에 제출하면 출력 초과라는 오류는 여전히 뜸. < 로그 찍은거 때문이었음
근데 < 로 하면 그냥 '틀렸습니다' 뜸.
생각해보니 로직상으론 <=이 맞는데?
하고 보니까 end가 N-1이 아니라 N이었음.
수정 후 <=로도 바꾸고 다시 해봄.
됐다.
N = int(input()) # 사막 크기
S = input().split() # 사막
M = int(input()) # 바늘 개수
S_find = input().split() # 찾아야 하는 바늘들
S.sort()
for i in range(M):
isIn = 0
need = S_find[i]
start = 0
idx_half = N//2
end = N-1
# 이분 탐색
while (start <= end):
print(idx_half)
if S[idx_half] == need:
isIn = 1
break
elif S[idx_half] < need:
start = idx_half + 1
idx_half = (start+end)//2
else:
end = idx_half -1
idx_half = (start+end)//2
print('찾았는지 : ',isIn)정답 맞춘 코드
CSAPP
hello world 출력하는 간단한 프로그램조차도 실행되고 종료되기 위해서 시스템 주요 부분들이 조화롭게 동작해야 함. 이게 어떤 과정으로 일어나는지 알아보는 것이 이 책의 목적.
1.2 프로그램은 다른 프로그램에 의해 다른 형태로 번역된다
linux> gcc -o hello hello.c
이거 유닉스 시스템에서 입력하면 hello.c를 읽어서 실행파일인 hello로 번역한다.
번역은 전처리기, 컴파일러, 어셈블러, 링커 이 4가지의 컴파일 시스템을 거친다.
- 전처리 단계 : 전처리기(cpp)는 C 프로그램을 #문자로 시작하는 디렉티브에 따라 수정한다.
#include<stdio.h><< 이거 프로그램 문장에 삽입한다는 뜻. .i로 끝나는 새로운 C 프로그램이 생성됨. - 컴파일 단계 : 컴파일러(ccl)는 텍스트파일 hello.i를 텍스트 파일인 hello.s로 번역하며, 이 파일에는 어셈블리어 프로그램이 저장됨.
- 어셈블리 단계 : 어셈블러(as)가 hello.s를 기계어 인스트럭션으로 번역해서 재배치가능 목적프로그램 의 형태로 묶어 hello.o라는 목적파일에 그 결과를 저장. (이제 열어보면 해석불가)
- 링크 단계 : 링커 프로그램(ld)이 표준 C 라이브러리인 printf.o에 들어있는 printf 함수를 hello.o 파일과 결합시킴. 그 결과인 hello 파일은 실행파일로 메모리에 적재되어 시스템에 의해 실행됨
1.3 컴파일 시스템이 어떻게 동작하는지 이해하는 것은 중요하다
hello.c처럼 간단한 프로그램은 컴파일 시스템이 알아서 잘 해주겠지만...
프로그램 성능 최적화하기
: c 프로그램 작성 시 올바른 판단을 하기 위해서는 기계어 수준 코드에 대한 기본적인 이해를 할 필요가 있음
- switch 문은 if-else 문을 연속해서 사용하는 것보다 언제나 더 효율적일까?
- 함수 호출 시 발생하는 오버헤드는 얼마나 되는가? (오버헤드 : 프로그램의 실행흐름 도중에 동떨어진 위치의 코드를 실행시켜야 할 때 , 추가적으로 시간, 메모리, 자원이 사용되는 현상)
- while 루프는 for 루프보다 더 효율적일까?
- 포인터 참조가 배열 인덱스보다 더 효율적인가?
- 합계를 지역변수에 저장하면 참조형태로 넘겨받은 인자를 사용하는 것보다 왜 루프가 더 빨리 실행되는가?
- 수식 연산시 괄호를 단순히 재배치하기만 해도 함수가 더 빨리 실행되는 이유는 무엇인가?
프로그램 성능 최적화하기 : GPT 답변
1. switch 문은 if-else 문을 연속해서 사용하는 것보다 언제나 더 효율적일까?
switch 문은 컴파일러가 효율적으로 최적화할 수 있는 경우가 많습니다. 특히, switch 문이 많은 case를 가지며 이들이 정수형 상수일 경우, 컴파일러는 이를 "jump table"로 최적화할 수 있습니다. 이렇게 하면 상수 값에 따라 직접적인 점프가 가능하여 효율적입니다.
if-else 문은 연속적으로 조건을 평가합니다. 각 조건이 평가되어야 하므로, 많은 조건이 있는 경우 시간이 더 많이 소요될 수 있습니다.
하지만, switch 문이 항상 if-else 문보다 효율적인 것은 아닙니다. 조건이 복잡하거나 비정수형 데이터인 경우, if-else 문이 더 적합할 수 있습니다.
결론적으로, switch 문이 정수형 상수 값을 비교하는 경우에는 일반적으로 더 효율적입니다.
2. 함수 호출 시 발생하는 오버헤드는 얼마나 되는가?
함수 호출 시 발생하는 오버헤드는 다음과 같은 요소들로 구성됩니다:
스택 프레임 생성: 함수 호출 시 스택에 새로운 프레임이 생성되어야 합니다.
인자 전달: 함수 인자들이 스택에 push되거나 레지스터를 통해 전달되어야 합니다.
리턴 주소 저장: 호출된 함수가 끝난 후 돌아갈 주소를 스택에 저장해야 합니다.
함수 호출 및 리턴: 함수 진입 및 반환을 위한 명령어가 실행됩니다.
이 오버헤드는 함수의 인자 수, 인자 전달 방식(레지스터 vs 스택), 함수의 호출 빈도 등에 따라 달라집니다.
일반적으로 함수 호출 오버헤드는 몇 개의 명령어 사이클을 추가로 소비합니다. 하지만, 인라인 함수로 최적화할 수 있는 경우, 이 오버헤드를 줄일 수 있습니다.
3. while 루프는 for 루프보다 더 효율적일까?
while 루프와 for 루프는 거의 동일한 방식으로 동작합니다. 컴파일러는 두 루프를 거의 같은 기계어 코드로 변환합니다.
for 루프는 초기화, 조건 검사, 증감 부분을 한 곳에서 선언할 수 있어 코드가 더 깔끔하고 가독성이 좋습니다.
while 루프는 조건만 검사하며, 초기화와 증감 부분은 루프 외부에 명시해야 합니다.
따라서, 성능 측면에서 while 루프와 for 루프의 차이는 거의 없으며, 주로 가독성과 코드 스타일에 따라 선택됩니다.
4. 포인터 참조가 배열 인덱스보다 더 효율적인가?
포인터 참조는 배열 인덱스 연산과 동일한 기계어 명령어로 컴파일될 수 있습니다. 즉, 배열 인덱스는 포인터 연산으로 변환됩니다.
예를 들어, array[i]는 내부적으로 *(array + i)로 변환됩니다.
그러나, 포인터를 직접 사용하는 경우, 인덱스 연산을 명시적으로 하지 않으므로 코드가 더 직관적일 수 있습니다.
특정 경우, 포인터 연산이 더 효율적일 수 있지만, 현대의 최적화 컴파일러는 배열 인덱스와 포인터 참조 간의 성능 차이를 거의 없앱니다.
5. 합계를 지역변수에 저장하면 참조형태로 넘겨받은 인자를 사용하는 것보다 왜 루프가 더 빨리 실행되는가?
지역 변수는 스택에 저장되며, 접근이 매우 빠릅니다.
반면, **참조 형태(포인터)**로 넘겨받은 인자는 메모리의 다른 위치(힙 또는 다른 스택 프레임)에 위치할 수 있으며, 접근 시 메모리 지연이 발생할 수 있습니다.
캐시 효율성도 큰 차이를 만듭니다. 지역 변수는 일반적으로 캐시에 잘 들어맞지만, 참조된 데이터는 그렇지 않을 수 있습니다.
따라서, 루프 내에서 빈번히 접근하는 데이터는 지역 변수에 저장하는 것이 더 효율적입니다.
6. 수식 연산시 괄호를 단순히 재배치하기만 해도 함수가 더 빨리 실행되는 이유는 무엇인가?
수식 연산에서 괄호를 재배치하면 연산 순서가 변경됩니다. 이는 연산의 중간 결과를 저장하고 재사용할 수 있도록 하여 효율성을 높일 수 있습니다.
예를 들어, (a + b) + c와 a + (b + c)는 중간 결과를 달리 생성합니다.
(a + b) + c는 먼저 a + b를 계산한 후 그 결과에 c를 더합니다.
a + (b + c)는 먼저 b + c를 계산한 후 그 결과에 a를 더합니다.
연산 순서를 바꾸면 CPU 레지스터와 캐시 사용이 최적화될 수 있습니다.
특히, 컴파일러는 상수 식을 미리 계산하거나, 공통 부분을 미리 계산하여 반복적으로 사용되는 값을 줄임으로써 성능을 최적화할 수 있습니다.링크 에러 이해하기
: 가장 당혹스러운 프로그래밍 에러는 링커의 동작과 관련되어 있으며, 큰 규모 소프트웨어 빌드할 때 더욱 그럼.
- 링커가 어떤 참조를 풀어낼 수 없다고 할 때는 무엇을 의미하는가?
- 정적변수와 전역변수의 차이는 무엇인가?
- 만일 각기 다른 파일에 동일한 이름의 두 개의 전역변수를 정의한다면 무슨 일이 일어나는가?
- 정적 라이브러리와 동적 라이브러리의 차이는 무엇인가?
- 컴파일 명령을 쉘에서 입력할 때 명령어 라인의 라이브러리들의 순서는 무슨 의미가 있는가?
- 왜 링커와 관련된 에러들은 실행하기 전까지는 나타나지 않는 걸까?
링크 에러 이해하기 : GPT 답변
1. 링커가 어떤 참조를 풀어낼 수 없다고 할 때는 무엇을 의미하는가?
링커가 참조를 풀어낼 수 없다고 하는 것은 프로그램에서 사용된 심볼(변수, 함수 등)의 정의를 찾을 수 없음을 의미합니다. 이는 여러 가지 이유로 발생할 수 있습니다:
함수나 변수가 선언만 되고 정의되지 않았을 때.
링킹 시 필요한 라이브러리가 누락되었을 때.
오타나 잘못된 이름 사용으로 인해 참조가 실패할 때.
필요한 객체 파일이나 라이브러리가 컴파일 또는 링크 과정에서 포함되지 않았을 때.
2. 정적변수와 전역변수의 차이는 무엇인가?
정적 변수 (static variable):
파일 내 정적 변수: 함수 외부에서 선언되었지만 static 키워드가 붙어있는 변수입니다. 해당 파일 내에서만 접근 가능하며, 다른 파일에서는 접근할 수 없습니다.
함수 내 정적 변수: 함수 내부에서 선언된 static 변수로, 함수가 호출될 때마다 초기화되지 않고, 프로그램이 종료될 때까지 값을 유지합니다.
전역 변수 (global variable):
파일 내 어디서나 접근할 수 있는 변수입니다.
static 키워드가 붙지 않은 변수로, 다른 파일에서 extern 키워드를 사용하여 참조할 수 있습니다.
3. 만일 각기 다른 파일에 동일한 이름의 두 개의 전역변수를 정의한다면 무슨 일이 일어나는가?
동일한 이름의 전역 변수를 각기 다른 파일에서 정의하면 링킹 과정에서 충돌이 발생합니다. 링커는 두 개의 변수를 구분할 수 없으므로 multiple definition 에러가 발생합니다.
이러한 충돌을 피하기 위해 헤더 파일에는 전역 변수를 extern 키워드로 선언하고, 하나의 소스 파일에서만 해당 변수를 정의하는 것이 좋습니다.
4. 정적 라이브러리와 동적 라이브러리의 차이는 무엇인가?
정적 라이브러리 (Static Library):
.a 또는 .lib 확장자를 가집니다.
컴파일 시에 라이브러리의 코드가 프로그램의 실행 파일에 포함됩니다.
실행 파일이 더 커지지만, 배포 시 별도의 라이브러리가 필요하지 않습니다.
동적 라이브러리 (Dynamic Library):
.so (Shared Object) 또는 .dll (Dynamic Link Library) 확장자를 가집니다.
실행 파일이 실행될 때 라이브러리가 동적으로 로드됩니다.
실행 파일 크기가 작아지지만, 실행 시 라이브러리가 필요합니다.
5. 컴파일 명령을 쉘에서 입력할 때 명령어 라인의 라이브러리들의 순서는 무슨 의미가 있는가?
컴파일 시 명령어 라인에서 라이브러리의 순서는 중요합니다.
링커는 왼쪽에서 오른쪽으로 참조를 해결합니다. 즉, 어떤 라이브러리가 다른 라이브러리를 필요로 하는 경우, 참조되는 라이브러리가 참조하는 라이브러리보다 앞에 와야 합니다.
잘못된 순서로 인해 참조가 해결되지 않아 링킹 오류가 발생할 수 있습니다.
예를 들어, gcc main.o -lmylib1 -lmylib2에서 mylib1이 mylib2를 참조한다면 순서가 맞지만, 반대의 경우 참조를 해결할 수 없어 오류가 발생합니다.
6. 왜 링커와 관련된 에러들은 실행하기 전까지는 나타나지 않는 걸까?
링커는 컴파일된 객체 파일들을 결합하여 실행 파일을 생성하는 역할을 합니다.
컴파일러는 각 소스 파일을 독립적으로 컴파일하여 객체 파일을 생성합니다. 이 과정에서 변수나 함수의 선언은 확인하지만, 정의는 확인하지 않습니다.
링커는 이 객체 파일들을 결합하면서 참조된 모든 심볼의 정의를 찾아야 합니다. 만약 정의를 찾을 수 없으면 링킹 에러가 발생합니다.
따라서, 링커와 관련된 에러는 컴파일 시점이 아니라 링킹 시점에 나타납니다.
동적 라이브러리의 경우, 런타임에 로드될 때 참조를 해결하므로, 이 때 에러가 발생할 수도 있습니다.보안 약점 피하기
: 오랫동안 버퍼 오버플로우 취약성이 인터넷과 네트워크 상의 보안 약점의 주요 원인으로 설명되었다. 이 취약성은 프로그래머들이 신뢰할 수 없는 곳에서 획득한 데이터의 양과 형태를 주의 깊게 제한해야 할 필요를 거의 인식하지 못하기 때문에 생겨난다.
3장에서는 스택체제, 버퍼 오버플로우 취약성, 공격의 위협을 줄이기 위한 프로그래머, 컴파일러, 운영체제에서 사용할 수 있는 방법들을 학습함.
보안 약점 피하기 : GPT 답변
버퍼 오버플로우의 원리
버퍼 오버플로우는 프로그램이 버퍼(메모리 블록)에 예상보다 더 많은 데이터를 쓰려고 할 때 발생합니다. 일반적으로, 버퍼는 고정된 크기를 가지며, 이 크기를 초과하는 데이터를 저장하려고 하면 메모리의 다른 영역을 덮어쓰게 됩니다. 이는 메모리 손상을 초래하며, 악의적인 공격자는 이를 이용해 코드를 주입하거나 프로그램의 흐름을 조작할 수 있습니다.
버퍼 오버플로우를 방지하는 방법
입력 데이터 검증 및 제한:
모든 입력 데이터를 검증하고, 버퍼 크기를 초과하지 않도록 제한해야 합니다.
예를 들어, strncpy 함수는 복사할 데이터의 최대 크기를 지정할 수 있습니다.
strncpy(buffer, input, sizeof(buffer) - 1);
buffer[sizeof(buffer) - 1] = '\0'; // null-terminate the buffer안전한 라이브러리 함수 사용:
gets 함수 대신 fgets와 같은 안전한 입력 함수를 사용합니다.
fgets(input, sizeof(input), stdin);컴파일러 보호 기능 사용:
현대 컴파일러는 버퍼 오버플로우를 방지하는 다양한 보호 기능을 제공합니다.
예를 들어, 스택 보호(stack protection), 주소 공간 배치 랜덤화(Address Space Layout Randomization, ASLR) 등을 사용합니다.
정적 분석 도구 사용:
정적 분석 도구를 사용해 코드의 잠재적 버퍼 오버플로우 취약성을 사전에 발견하고 수정할 수 있습니다.
메모리 안전 언어 사용:
C와 같은 메모리 관리가 어려운 언어 대신, 메모리 안전성이 높은 언어(예: Java, Python, Rust)를 사용합니다.
1.4 프로세서는 메모리에 저장된 인스트럭션을 읽고 해석한다
hello.c 소스 프로그램을 컴파일 시스템이 번역하면 실행파일이 생기고,
이것을 유닉스 시스템에서 실행하기 위해 쉘이라는 응용 프로그램에 그 이름을 입력한다.
linux> ./hello
hello, world
linux>쉘 : 커맨드라인 인터프리터, 프롬프트 출력하고 명령어 입력받아서 실행한다. 명령어가 내장 쉘 명령어가 아니면 실행파일 이름으로 판단하고 그 파일을 로딩해서 실행해줌.
1.4.1 시스템의 하드웨어 조직
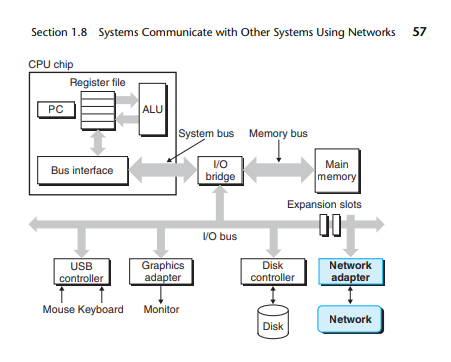
버스(Buses)
- 버스(bus) : 시스템 내를 관통하는 전기적 배선군. 워드(word)라는 고정 크기의 바이트 단위로 데이터를 전송하도록 설계됨.
- 한 개의 워드를 구성하는 바이트 수는 시스템마다 보유하는 기본 시스템 변수
- 오늘날 대부분의 컴퓨터들은 4바이트(32비트) 또는 8바이트(64비트) 워드 크기를 갖는다
입출력 장치
- 각 입출력 장치는 입축력 버스와 컨트롤러 나 어댑터 를 통해 연결됨
- 컨트롤러와 어댑터의 차이는 패키징에 있음
- 컨트롤러 : 디바이스 자체가 칩셋이거나 시스템의 인쇄기판 (마더보드)에 장착된다
- 어댑터 : 마더보드의 슬롯에 장착되는 카드
메인 메모리
- 메인 메모리 : 프로세서가 프로그램을 실행하는 동안 데이터와 프로그램을 모두 저장하는 임시 저장장치
- 물리적으로 메인 메모리는 DRAM (Dynamic Random Access Memory) 칩들로 구성되어 있음
- 논리적으로 메모리는 연속적인 바이트들의 배열로, 각각 0부터 시작해서 고유의 주소(배열의 인덱스)를 가지고 있다.
프로세서
- 주처리장치(CPU) (=프로세서) : 메인 메모리에 저장된 인스트럭션들을 해독(실행)하는 엔진
- 프로세서의 중심에는 워드 크기의 저장장치(또는 레지스터)인 프로그램 카운터(PC)가 있다.
- 전원 공급부터 끊어질 때까지 프로세서는 프로그램 카운터가 가리키는 곳의 인스트럭션을 반복적으로 실행하고 PC값이 다음 인스트럭션의 위치를 가리키도록 업데이트함.
인스트럭션의 요청에 의해 CPU가 실행하는 단순한 작업의 예
- 적재(Load): 메인 메모리에서 레지스터에 한 바이트 또는 워드를 이전 값에 덮어쓰는 방식으로 복사한다.
- 저장(Store): 레지스터에서 메인 메모리로 한 바이트 또는 워드를 이전 값을 덮어쓰는 방식으로 복사한다.
- 작업(Operate): 두 레지스터의 값을 ALU로 복사하고 두 개의 워드로 수식연산을 수행한 뒤, 결과를 덮어쓰기 방식으로 레지스터에 저장한다.
- 점프(Jump): 인스트럭션 자신으로부터 한 개의 워드를 추출하고, 이것을 PC에 덮어쓰기 방식을 복사한다.
적재와 저장의 차이(GPT답변)
적재 (Load):
- 적재는 메모리에서 데이터를 읽어와서 레지스터에 저장하는 작업입니다.
- 예를 들어, RAM에 저장된 값을 CPU의 레지스터로 가져오는 작업입니다.
- 이는 메모리에서 레지스터로 데이터를 "적재"하는 것이라고 할 수 있습니다.
저장 (Store):
- 저장은 레지스터에 있는 데이터를 메모리에 기록하는 작업입니다.
- 예를 들어, CPU의 레지스터에 있는 값을 RAM에 저장하는 작업입니다.
- 이는 레지스터에서 메모리로 데이터를 "저장"하는 것이라고 할 수 있습니다.
간단히 말하면:
- 적재 (Load): 메모리 → 레지스터### ALU (산술 논리 장치)
- 저장 (Store): 레지스터 → 메모리
ALU (산술 논리 장치)
- ALU는 컴퓨터 프로세서의 핵심 구성 요소 중 하나로, 산술 및 논리 연산을 수행합니다.
- 산술 연산에는 덧셈, 뺄셈, 곱셈, 나눗셈이 포함됩니다.
- 논리 연산에는 AND, OR, NOT, XOR와 같은 비트 수준의 연산이 포함됩니다.
- ALU는 데이터를 처리하고 결과를 레지스터에 저장합니다.
레지스터 (Register)
- 레지스터는 CPU 내부에 있는 고속 메모리 저장소입니다.
- 레지스터는 매우 빠른 속도로 데이터를 읽고 쓸 수 있으며, 주로 연산 중간 결과를 저장하거나, 데이터를 임시로 저장하는 데 사용됩니다.
- 레지스터는 메모리보다 용량이 작지만 훨씬 빠릅니다.
