해야 할 것들
목~토에는 이론 공부를, 일~수에는 문제 풀기를 추천합니다!
단, 1주차의 ‘기초’ 문제는 푸는 것에 집중하기를 권장합니다.
라고 적혀 있었는데, 문제에 머리를 박아보니 왜 이렇게 말했는지 알 것 같다.
이론 모르고 냅다 풀면 의미가 없는듯?
오늘은 이론에 집중해봐야겠다.
To-do List
☑️ 사냥꾼 구현
☑️ 지금까지 썼던 TIL 옵시디언에 정리
☑️ 버블 정렬, 이분 탐색, 백트래킹 슈도 코드 변환
☑️ 백트래킹 구현
☑️ 시간 복잡도 어떻게 구하는지 알아내기
☑️ 백준 쉬운 문제 3개 정도 풀기
☑️ 정렬 알고리즘 구현해보기 : 퀵 정렬, 병합 정렬, 힙 정렬
✅ CSAPP 19p까지 읽기 -> 1.10까지 다 읽고 Part1 끝냄
✅ Do it! 뭐시기 읽기 -> 97p까지 읽음
애초에 늦게 와서 시간이 부족했다.
앞으로 이런 형식으로 할 것들 관리하면 될듯.
배운 내용
Do it! 자료 구조와 함께 배우는 알고리즘 입문 : 파이썬 편
01 알고리즘 기초
실행 구조
- 순차 구조 : 한 문장씩 순서대로 처리되는 구조
- 선택 구조 : 조건식으로 평가한 결과에 따라 실행 흐름이 변경됨
복합문
- 헤더 : if문이나 while문 등 복합문에서 콜론(:)으로 끝나는 부분까지
- 콜론의 의미 : '바로 뒤에 스위트가 이어집니다'
- 스위트(suite) : 헤더와 한 세트로 따라다니는 실행문. 복합문의 스위트는 반드시 행마다 같은 수준으로 들여쓰기를 해야 한다. PEP 8(파이썬의 코드 작성 규칙)에서는 공백 4개를 들여쓰기로 사용할 것을 권장한다.
알고리즘
어떠한 문제를 해결하기 위해 정해 놓은 일련의 절차
파이썬 스타일 가이드 PEP 8
클래스명은 카멜 케이스(camelCase), 함수명은 스네이크(snake_case) 형식 등...
조건 연산자 (if~else문)
파이썬의 유일한 삼항 연산자. 조건식 a if b else c 는 b를 평가한 값이 참이면 a를, 거짓이면 c를 출력한다.
반복문 건너뛰기와 여러 범위 스캔하기
for i in range(1, 13)
if i == 8:
continue
print(i, end=' ')건너뛰는 판단을 하려면 계속 if문 써야 하니까 비효율적
for i in list(range(1,8) + list(range(9,13)):리스트 써서 8 건너뛰면 더 효율적.
근데 생성한 리스트의 원소를 하나씩 꺼내 반복하므로
반복을 위한 연산 비용은 여전히 발생.
파이썬 변수
파이썬에선 데이터, 함수, 클래스, 모듈, 패키지 등을 모두 객체로 취급함. 객체는 자료형을 가지며 메모리(저장 공간)를 차지함. 파이썬의 이런 특징 때문에 파이썬의 변수는 값을 갖지 않는다는 특징이 있음.
예를 들어 x = 17은 x가 17이라는 값을 갖고 있다고 말할 수 없음. 보통 프로그래밍 언어에서 변수란 값을 저장하는 상자와 같다고 비유하는데 파이썬에서는 이 비유가 맞지 않음.
- 변수는 객체를 참조하는 객체에 연결된 이름에 불과함
- 모든 객체는 메모리를 차지하고, 자료형뿐만 아니라 식별 번호(identity)를 가짐
즉, n=17 을 쓰면 변수에 값을 저장하는게 아니라 int형 객체 17에 이름이 부여되는 것
변수 쓸 때 자료형 선언 안 해도 값 대입만 하면 바로 쓸 수 있는 이유가 이거 때문임.
라고 책에서 봤는데, 이거 알아서 코딩에는 어따 씀? 그냥 호기심 충족용 아님?
- 메모리 관리와 성능
파이썬의 객체 모델을 이해하면 메모리 관리와 성능 최적화에 도움이 됩니다. 객체가 어떻게 생성되고 소멸되는지, 메모리가 어떻게 할당되고 해제되는지를 알 수 있습니다.
import sys
a = 12345678901234567890
print(sys.getrefcount(a)) # 참조 카운트 확인sys.getrefcount를 사용하면 객체의 참조 카운트를 확인할 수 있습니다. 참조 카운트가 0이 되면 객체는 메모리에서 해제됩니다.
- 디버깅
변수와 객체의 관계를 이해하면 디버깅이 더 쉬워집니다. 예를 들어, 예기치 않은 객체 변경이 발생했을 때 원인을 쉽게 파악할 수 있습니다.
a = [1, 2, 3]
b = a
b.append(4)
print(a) # [1, 2, 3, 4]여기서 a와 b가 동일한 객체를 참조하기 때문에 발생한 문제를 쉽게 이해할 수 있습니다.
자료형
- 뮤터블 자료형 : 리스트, 딕셔너리, 집합 등이 있으며 값을 변경할 수 있음
- 이뮤터블 자료형 : 수, 문자열, 튜플 등이 있으며 값을 변경할 수 없음
파이썬의 대입
- 좌변에 변수 이름이 처음 나온 경우, 그 변수에 맞는 자료형으로 자동 선언
- 대입식은 값 자체가 아니라 참조하는 객체의 식별 번호를 대입
- 여러 변수에 여러 값을 한꺼번에 대입할 수 있음
- 파이썬에서 대입기호 =는 연산자가 아님. 식(expression)이 아니라 문(statement)이므로
x = 17의 자료형을 확인할 수 없음.
- 배열에 원소가 하나도 없는지 확인하고 싶다면 배열을 참조하는 변수를 조건식에 그대로 사용하면 됨. ex)
if x:- 배열의 대소 또는 등가 관계를 비교 연산자를 사용하여 판단할 수 있음. 맨 앞 원소부터 차례로 비교하면서 원소의 값이 같으면 다음 원소를 비교함. 원소 수가 다른 경우엔 원소 수가 많은 배열을 더 크다고 판단함
- 스캔 (주사, traverse) : 배열 원소를 하나씩 차례로 주목하여 살펴보는 방식
모듈
- 모듈 : 하나의 스크립트 프로그램. 확장자(.py)를 포함하지 않는 파일의 이름 자체를 모듈 이름으로 사용함.
- 스크립트 프로그램이 직접 실행될 때 변수
__name__은'__main__'- 스크립트 프로그램이 임포트될 때 변수
__name__은 원래의 모듈 이름- 파이썬은 모든 것을 객체로 다루므로 모듈도 당연히 객체
역순으로 정렬한 리스트 생성
-
reversed(x) : x의 원소를 역순으로 정렬하는 이터러블 객체. '역순으로 꺼낼 거에요~'라는 명령들일 뿐임. 이렇게는 역순으로 정렬 안됨.
-
list(reversed(x)) : 이렇게 해야 역순으로 정렬된 리스트 얻음
-
x.reversed() : 이렇게 하면 리스트가 역순으로 정렬됨
함수 사이에 주고받는 인수
파이썬에서는 매개변수에 실제 인수가 대입된다.
복사되는 것은 값이 아니라 참조하는 곳이므로 대입된 매개변수와 원래 변수가 참조하는 곳은 같다.
백준
8983 사냥꾼
내 코드가 틀렸던 이유
-
영역에 맞는 y좌표를 갖는 점을 찾은 후에 +1씩 인덱스를 올리거나 줄여가며 정답 영역에 들어있는 점들을 찾으려고 했는데, 이분 탐색의 의미가 없다. 탐색의 시작 말고는 정직하게 완전 탐색을 시도하기 때문이다. 탐색의 양이 조금은 줄어들 순 있겠지만, 완전 탐색에 가깝다.
-
코드 구현도 어렵다. 위나 아래로 탐색하며 정답 영역을 찾으려고 했는데, 알맞은 x좌표를 가진 영역의 점에서 시작할 때와 알맞지 않은 y좌표를 가진 영역에서 시작할 때의 코드가 서로 다르다. 때문에 상황 판단을 위한 변수도 너무 많았다.
-
조건 설정이 너무 길어졌다. 내 접근 방식의 근본적 문제였다. 사대와의 거리를 구하는 짤막한 식이 근본 조건인데 특정 y좌표에 해당하는지, x좌표 영역에 들어왔는지, 인덱스를 넘진 않았는지, 이렇게 3가지나 조건을 설정하는 코드가 되어버렸다.
CSAPP
1.5 캐시가 중요하다
이전의 내용이 의미하는 것은, 시스템은 정보를 한 곳에서 다른 곳으로 이동시키는 일에 많은 시간을 보낸다는 것이다. 그래서 시스템 설계자들의 주요 목적은 이러한 복사과정들을 가능한 한 빠르게 동작하도록 하는 것이다.
물리학의 법칙 때문에 더 큰 저장장치들은 보다 작은 저장장치들보다 느린 속도를 갖는다. 그리고 더 빠른 장치들은 더 느린 장치들보다 만드는 데 더 많은 비용이 든다.
일반적인 레지스터 파일은 수백 바이트의 정보를 저장하는 반면, 메인 메모리의 경우는 십억 개의 바이트를 저장한다. 그러나 프로세서는 레지스터 파일의 데이터를 읽는데 메로리의 경우보다 거의 100배 더 빨리 읽을 수 있다. 이 격차는 기술이 발달하며 매년 커지고 있다.
이에 대응하기 위해 캐시가 고안되었다. 캐시는 프로세서가 단기간에 필요로 할 가능성이 높은 정보를 임시로 저장할 목적으로 사용한다.
1.6 저장장치들은 계층구조를 이룬다
빠른 것도 있고 느린 것도 있다. L0, L1, L2 ... 이런식으로 부른다. 숫자가 클수록 느리고 저장용량 크다.
메모리 계층구조의 주요 아이디어는 한 레벨의 저장장치가 다음 하위레벨 저장장치의 캐시 역할을 한다는 것이다. L1과 L2의 캐시는 각각 L2와 L3의 캐시다. 로컬 디스크들은 원격 네트워크 서버에서 파일들을 가져와 보관한다.
1.7 운영체제는 하드웨어를 관리한다.
운영체제는 하드웨어와 소프트웨어 사이에 위치한 소프트웨어 계층으로 생각할 수 있다. 응용프로그램이 하드웨어를 제어하려면 언제나 운영체제를 통해서 해야 한다.
운영체제의 두 가지 주요 목적
1. 제멋대로 동작하는 응용프로그램들이 하드웨어를 잘못 사용하는 것을 막는다.
2. 응용 프로그램들이 단순한 매커니즘을 사용해 복잡하고 다양한 하드웨어를 조작할 수 있게 한다.
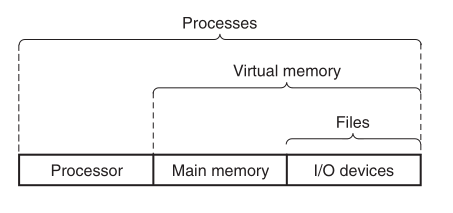
목적 달성을 위해서 3가지로 추상화를 한다
1. 파일 : 입출력장치의 추상화
2. 가상메모리 : 메인 메모리, 디스크 입출력 장치의 추상화
3. 프로세스 : 프로세서, 메인 메모리, 입출력장치 모두의 추상화
1.7.1 프로세스
프로세스 : 실행 중인 프로그램에 대한 운영체제의 추상화
다수의 프로세스들은 동일한 시스템에서 동시에 실행될 수 있으며, 각 프로세스는 하드웨어를 배타적으로 사용하는 것처럼 느낀다. 운영체제는 문맥 전환(context switching)이라는 방법을 사용해서 이러한 교차실행을 수행한다.
운영체제는 프로세스가 실행하는 데 필요한 모든 상태정보의 변화를 추적한다. 이 '컨텍스트'라고 부르는 PC, 레지스터 파일, 메인 메모리의 현재 값을 포함하고 있다. 운영체제는 현재 프로세스에서 다른 프로세스로 제어를 옮기려고 할 때 현재 프로세스의 컨텍스트를 저장하고 새 프로세스의 컨텍스트를 복원시키는 문맥 전환을 실행하여 제어권을 새 프로세스로 넘겨준다.
문맥 전환은 운영체제 커널(kernal)에 의해 관리된다. 커널은 운영체제 코드의 일부분으로 메모리에 상주한다. 응용프로그램이 운영체제에 의한 어떤 작업을 요청하면, 컴퓨터는 특정 파읽 읽기나 쓰기와 같은 특정 시스템 콜(system call)을 실행해서 커널에 제어를 넘겨준다. 그러면 커널은 요청된 작업을 수행하고 응용프로그램으로 리턴한다.
1.7.2 쓰레드(Thread)
프로세스는 쓰레드라고 하는 다수의 실행 유닛으로 구성되어 있다. 각각의 쓰레드는 해당 프로세스의 컨텍스트에서 실행되며 동일한 코드와 전역 데이터를 공유한다. 다중 쓰레딩은 다중 프로세서를 활용할 수 있다면 프로그램의 실행 속도를 빠르게 할 수 있다.
1.7.3 가상메모리
가상메모리 : 각 프로세스들이 메인 메모리 전체를 독점적으로 사용하고 있는 것처럼 만들어주는 추상화
각 프로세스는 가상주소 공간이라고 하는 균일한 메모리의 모습을 갖게 된다. 리눅스에서, 주소공간의 최상위 영역은 모든 프로세스들이 공통으로 사용하는 운영체제의 코드와 데이터를 위한 공간이다. 주소공간의 하위 영역은 사용자 프로세스의 코드와 데이터를 저장한다.
각 프로세스들에게 보여지는 가상주소공간들
-
프로그램 코드와 데이터 : 코드는 모든 프로세스들이 같은 고정 주소에서 시작하며, 다음에 C 전역변수에 대응되는 데이터 위치들이 따라온다. 코드와 데이터 영역은 실행가능 목적파일인 hello로부터 직접 초기화된다.
-
힙(Heap) : 코드와 데이터 영역 다음으로 런타임 힙이 따라온다. 힙은 프로세스가 실행되면서 C 표준함수인 malloc이나 free를 호출하면서 런타임에 동적으로 그 크기가 늘었다 줄었다 한다.
-
공유 라이브러리 : 주소공간의 중간 부근에 C 표준 라이브러리나 수학 라이브러리와 같은 공유 라이브러리의 코드와 데이터를 저장하는 영역.
-
스택(Stack) : 사용자 가상메모리 공간의 맨 위에 컴파일러가 함수 호출을 구현하기 위해 사용하는 사용자 스택이 위치한다. 힙과 마찬가지로 늘었다 줄었다 한다. 특히, 함수를 호출할 때마다 스택이 커지며, 함수에서 리턴될 때는 줄어든다.
-
커널 가상메모리 : 주소공간의 맨 윗부분은 커널을 위해 예약되어 있다. 응용프로그램들은 이 영역의 내용을 읽거나 쓰는 것이 금지되어 있으며, 마찬가지로 커널 코드 내에 정의된 함수를 직접 호출하는 것도 금지되어 있다.
가상메모리가 작동하기 위해서는 프로세서가 만들어내는 모든 주소를 하드웨어로 번역하는 등의 하드웨어와 운영체제 소프트웨어 간의 복잡한 상호작용이 필요하다. 기본적인 아이디어는 프로세스의 가상메모리의 내용을 디스크에 저장하고 메인 메모리를 디스크의 캐시로 사용하는 것이다.
1.7.4 파일
파일 : 연속된 바이트
1.8 시스템은 네트워크를 사용하여 다른 시스템과 통신한다
네트워크를 단지 또 다른 입출력 장치로도 볼 수 있다.
1.9 중요한 주제들
1.9.1 Amdahl의 법칙
일부 성능 개선 해도 총 속도 향상은 적다
1.9.2 동시성과 병렬성
쓰레드 수준 동시성
여러 스레드가 동시에 실행되면서 하나의 프로세스 내에서 작업을 병렬로 수행
멀티프로세서 시스템
어떤 시스템이 여러 개의 프로세서를 가지고 하나의 운영체제 커널의 제어 하에 동작
하이퍼쓰레딩(멀티쓰레딩)
하나의 CPU가 여러 개의 제어 흐름을 실행하는 기술
인스트럭션 수준 병렬성
프로세서가 여러 명령어를 동시에 실행하는 기술
파이프라이닝 : 하나의 인스트럭션을 실행하기 위해 요구되는 일들을 여러 단계로 나누고 프로세서 하드웨어가 일련의 단계로 구성되어 이들 단계를 하나씩 각각 수행한다.
슈퍼스케일러 : 사이클당 한 개 이상의 인스트럭션을 실행할 수 있는 프로세서
싱글 인스트럭션, 다중 데이터 병렬성(SIMD)
한 개의 인스트럭션이 병렬로 다수의 연산을 수행하는 기술
1.9.3 컴퓨터 시스템에서 추상화의 중요성
추상화의 사용은 전산학에서 가장 중요한 개념. 예를 들면, 좋은 프로그래밍 연습의 한 가지 측면은 함수들을 간단한 응용프로그램 인터페이스 API로 정형화하는 것으로, 프로그래머가 그 내부의 동작을 고려하지 않으면서 코드를 사용할 수 있도록 해준다.
운영체제 측면 세 가지 추상화를 소개했었다. 파일을 입출력 장치의 추상화로, 가상메모리는 프로그램 메모리의 추상화로, 프로세스는 실행 중인 프로그램의 추상화로. 여기에 한 가지를 더하면, 가상머신이 있다. 가상머신은 운영체제, 프로세서, 프로그램 모두를 포함하는 컴퓨터 전체의 추상화를 제공한다.
1.10 요약
컴퓨터 시스템은 응용프로그램을 실행하기 위해 함께 동작하는 하드웨어와 시스템 스포트웨어로 구성된다. 컴퓨터 내의 정보는 상황에 따라 다르게 해석되는 비트들의 그룹으로 표시된다.
프로그램은 ASCII 문자로 시작해서 컴파일러와 링커에 의해 바이너리 실행파일들로 번역되는 방식으로, 다른 프로그램들에 의해 다른 형태로 번역된다.
프로세서는 메인 메모리에 저장된 바이너리 인스트럭션을 읽고 해석한다.
계층구조 상부의 저장장치들은 하부의 장치들을 위한 캐시 역할을 수행한다.
운영체제 커널은 응용프로그램과 하드웨어 사이에서 중간자의 역할을 수행한다. 운영체제는 세 가지 근본적인 추상화 (파일, 가상메모리, 프로세스) 를 제공한다.
네트워크는 특정 시스템의 관점으로 볼 때, 단지 또 하나의 입출력장치다.
