🧭 To-do List
☑️ 백준 풀기 | 21606 아침 산책,
✅ 백준 풀기 | 1260 DFS와 BFS, 11724 연결 요소의 개수, 2606 바이러스, 11725 트리의 부모 찾기, 1707 이분 그래프, 14888 연산자 끼워넣기,
📝 배운 것들
🏷️ 음수 나눌 때 원하는 결과 나오게 하기
print(-9//4)
print(9//(-4))
아니 이거 왜 결과가 둘다 -3 나옴 -2 나와야되는거 아님? -2 나오게 하려면 어케함
파이썬에서 정수 나눗셈 연산(//)은 항상 나눗셈의 결과를 내림(floor)하여 정수를 반환합니다. 이 때문에 -9를 4로 나누거나 9를 -4로 나눌 때 둘 다 -3이 나옵니다. 이는 내림 연산의 특성 때문입니다.
예제
print(-9 // 4) # 결과: -3
print(9 // -4) # 결과: -3이는 수학적인 내림(floor) 연산이기 때문에 발생합니다. 예를 들어, -9를 4로 나누면 -2.25가 나오는데, 이 값을 내림(floor)하면 -3이 됩니다. 동일하게 9를 -4로 나누면 -2.25가 나오고, 이를 내림(floor)하면 -3이 됩니다.
해결 방법
- 정수 변환(
int()):
print(int(-9 / 4)) # 결과: -2
print(int(9 / -4)) # 결과: -2🏷️ set와 list의 속도 차이
set는 중간에 데이터 추가하거나 삭제해도 list처럼 연산량 많지는 않지?
네, set 자료형은 list와 비교했을 때 데이터 추가 및 삭제 연산에서 효율적입니다.
리스트(list)와 집합(set)의 차이점
-
리스트(
list):- 데이터 추가 (
append): 평균적으로 O(1) 시간이 걸리지만, 최악의 경우 (리스트 크기가 커져 메모리를 재할당해야 하는 경우) O(n) 시간이 걸릴 수 있습니다. - 데이터 삭제 (
remove,pop): 특정 요소를 찾는 데 O(n) 시간이 걸립니다. - 특정 요소의 존재 여부를 확인 (
in연산): O(n) 시간이 걸립니다.
- 데이터 추가 (
-
집합(
set):- 데이터 추가 (
add): 평균적으로 O(1) 시간이 걸립니다. - 데이터 삭제 (
remove,discard): 평균적으로 O(1) 시간이 걸립니다. - 특정 요소의 존재 여부를 확인 (
in연산): 평균적으로 O(1) 시간이 걸립니다.
- 데이터 추가 (
🏷️ set와 list의 자료구조
list는 무슨 자료구조로 구현되어 있고 set는 무슨 자료구조로 구현되어 있음?
파이썬의 list와 set은 서로 다른 자료구조를 기반으로 구현되어 있습니다.
리스트(list)
- 구현 자료구조: 동적 배열 (Dynamic Array)
- 특징:
- 인덱스 접근: 인덱스를 통한 요소 접근이 O(1) 시간 복잡도를 가집니다.
- 연속된 메모리: 연속된 메모리 공간에 저장됩니다.
- 크기 조정: 요소가 추가되면 필요에 따라 크기를 동적으로 조정합니다. 크기 조정 시에는 기존 배열의 요소를 새로운 배열로 복사하는 과정이 필요하여 O(n) 시간이 걸릴 수 있습니다.
- 빠른 탐색: 순차적으로 탐색할 때 효율적입니다.
집합(set)
- 구현 자료구조: 해시 테이블 (Hash Table)
- 특징:
- 빠른 연산: 추가, 삭제, 탐색 연산이 평균적으로 O(1) 시간 복잡도를 가집니다.
- 해시 함수: 요소는 해시 함수를 통해 저장 위치를 결정합니다.
- 순서 없음: 요소의 순서를 보장하지 않습니다.
- 중복 없음: 동일한 요소를 두 번 저장하지 않습니다.
- 메모리 사용: 해시 테이블은 동적 배열보다 메모리를 더 많이 사용할 수 있습니다.
구현 세부 사항
-
리스트 (
list):- 파이썬의
list는 동적 배열로 구현되어 있으며, 배열의 크기가 초과될 경우 크기를 두 배로 늘리고 기존 요소를 새 배열로 복사합니다. - 요소 추가(
append)는 평균적으로 O(1) 시간이 걸리지만, 배열 크기가 초과될 때는 O(n) 시간이 걸립니다. - 요소 삭제(
remove)는 요소를 찾는 시간이 O(n)이고, 삭제 후 요소를 이동하는 데 O(n) 시간이 걸립니다.
- 파이썬의
-
집합 (
set):- 파이썬의
set은 해시 테이블로 구현되어 있으며, 요소를 추가할 때 해시 함수를 사용하여 저장 위치를 결정합니다. - 요소 추가(
add)와 삭제(remove)는 평균적으로 O(1) 시간이 걸립니다. - 해시 충돌을 해결하기 위해 체이닝(chaining)이나 개방 주소법(open addressing)을 사용할 수 있습니다. 파이썬의
set은 체이닝 방식을 사용합니다.
- 파이썬의
🏷️ 연결 요소
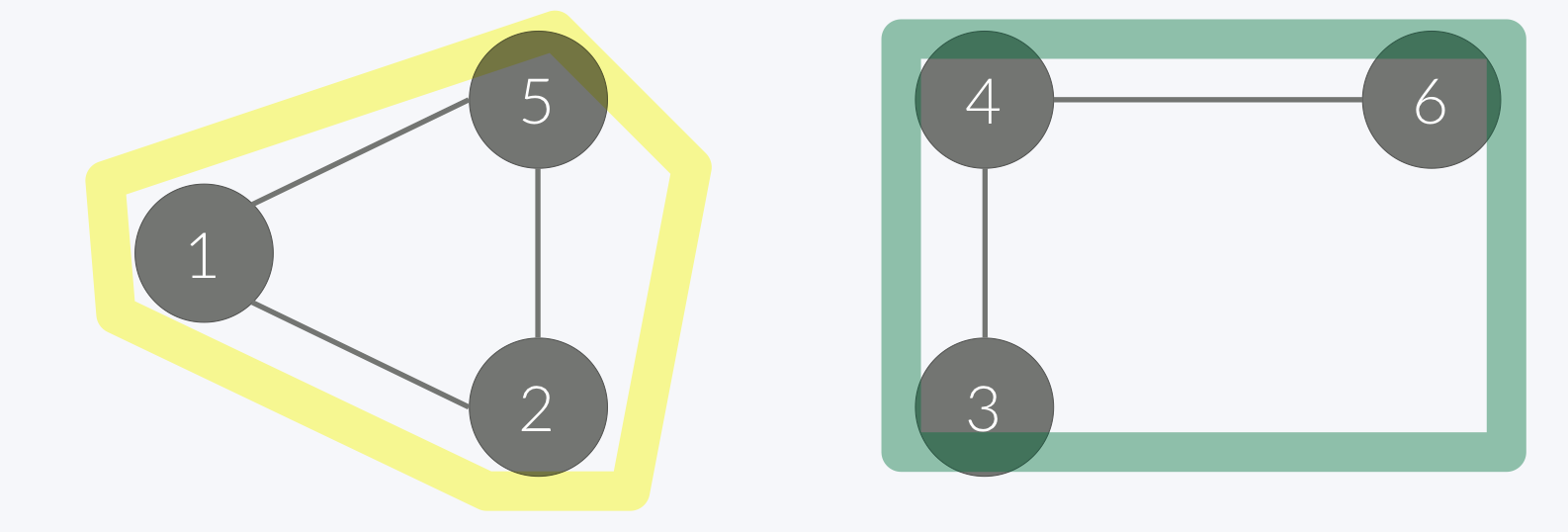
노란색 덩어리, 초록색 덩어리 각각이 연결 요소 하나
🏷️ 이분 그래프
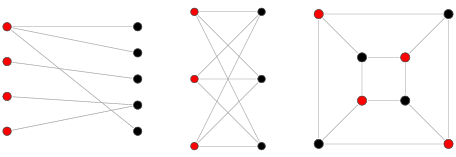
인접한 정점끼리 서로 다른 색으로 칠해서 모든 정점을 두 가지 색으로만 칠할 수 있는 그래프.
- BFS에서 인접한 정점을 탐색할 때 같은 색으로 다 칠해버린다
⚔️ 백준
📌 1260 DFS와 BFS
import sys
input = sys.stdin.readline
N, M, V = map(int, input().split())
# 그래프를 표현하는 인접 리스트
graph = [
[], # 0번 노드는 사용하지 않음 (노드 번호를 1부터 맞추기 위해)
[2, 3, 4], # 1번 노드와 연결된 노드들
[1], # 2번 노드와 연결된 노드들
[1, 5], # 3번 노드와 연결된 노드들
[1], # 4번 노드와 연결된 노드들
[3] # 5번 노드와 연결된 노드들
]
graph = [[] for _ in range(N+1)]
for _ in range(M):
a, b = map(int, input().split())
graph[a].append(b)
graph[b].append(a)
for node in graph:
node.sort()
# print(graph)
# 깊이 우선 탐색 DFS
# 1. 탐색 시작 노드를 스택에 삽입하고 방문 처리한다.
# 2. 스택의 최상단 노드에 방문하지 않은 인접 노드가 있으면
# 그 인접 노드를 스택에 넣고 방문 처리를 한다.
# 그리고 방문하지 않은 인접 노드가 없으면 최상단 노드를 꺼낸다
# 3. 두 번째 과정을 더 이상 수행할 수 없을 때까지 반복한다.
def dfs(node, visited):
visited.append(node)
print(node, end=' ')
if len(graph[node]) == 0:
return
for near in graph[node]:
if near not in visited:
dfs(near, visited)
visited = []
dfs(V,visited)
print('')
# print('dfs 완료')
# 너비 우선 탐색 BFS
# 1. 탐색 시작 노드를 큐에 삽입하고 방문 처리한다.
# 2. 큐에서 노드를 꺼내 해당 노드의 인접 노드 중에서
# 방문하지 않은 노드를 모두 큐에 삽입하고 방문 처리한다.
# 3. 두 번째 과정을 더 이상 수행할 수 없을 때까지 반복한다.
from collections import deque
def bfs(node, visited, waiting):
visited.append(node)
waiting.append(node)
while len(waiting) != 0:
node = waiting.popleft()
print(node, end=' ')
for near in graph[node]:
if near not in visited:
waiting.append(near)
visited.append(near)
return
visited = []
waiting = deque()
bfs(V,visited, waiting)
# print('bfs 완료')↑ 정답 코드
gpt한테 테스트 케이스 (맨 위의 graph 예시) 받아서 테스트해본 뒤에 나중에 백준 입력용 for문들 구현했다.
처음에 실수했던 부분들
- 무향 그래프라서 간선으로 연결된 두 정점 모두 graph를 업데이트 해줘야하는데 놓침
- sort 안 했더니 문제 조건대로 값이 작은 정점이 먼저가 아니라 먼저 등록된 간선을 먼저 감
- 백준이 요구하는 출력 방식이 아니라 정점 지날때마다 줄바꿈되게 해서 틀림
최적화해줘
def dfs(node, visited):
visited.add(node) # 리스트 대신 집합을 사용하여 O(1) 시간 복잡도로 방문 여부를 확인
print(node, end=' ')
for near in graph[node]:
if near not in visited:
dfs(near, visited)
# 그래프 예제
graph = {
1: [2, 3, 4],
2: [1],
3: [1, 5],
4: [1],
5: [3]
}
# 방문한 노드를 추적하기 위한 집합
visited = set()
# DFS 함수 호출
dfs(1, visited)주요 변경 사항
- visited 리스트를 집합으로 변경하여 방문 여부를 확인하는 시간을 O(1)로 줄임.
- 집합의 add 메서드를 사용하여 노드를 추가함.
bfs도 set로 바꿔주는거 말곤 없었음
📌 11724 연결 요소의 개수
import sys
input = sys.stdin.readline
N, M = map(int, input().split())
graph = [[] for _ in range(N+1)]
for _ in range(M):
a, b = map(int, input().split())
graph[a].append(b)
graph[b].append(a)
def dfs(node):
visited.add(node)
# print(node, end=' ')
for near in graph[node]:
if near not in visited:
dfs(near)
visited = set()
result = 0
for i in range(1,N+1):
if i not in visited:
dfs(i)
result += 1
print(result)↑ 정답 코드
dfs 갖다 쓰니 금방 풀림.
gpt한테 코칭받았던 set 사용해봤다.
📌 2606 바이러스
import sys
input = sys.stdin.readline
N = int(input())
M = int(input())
graph = [[] for _ in range(N+1)]
for _ in range(M):
a, b = map(int, input().split())
graph[a].append(b)
graph[b].append(a)
def dfs(node):
global result
visited.add(node)
# print(node, end=' ')
for near in graph[node]:
if near not in visited:
result += 1
dfs(near)
visited = set()
result = 0
dfs(1)
print(result)↑ 정답 코드
이것도 살짝만 변형하니 바로 풀림.
글로벌 변수 안 쓰는 버전으로 만들어달라고 요청해봤다.
def dfs(node, visited):
count = 0
visited.add(node)
for near in graph[node]:
if near not in visited:
count += 1
count += dfs(near, visited)
return count볼 때마다 직관적이지 않아서 마음에 안 드는데 필요한 순간이 있을테니 알아는 둬야할듯
📌 11725 트리의 부모 찾기
import sys
input = sys.stdin.readline
sys.setrecursionlimit(10**5)
N = int(input())
graph = [[] for _ in range(N+1)]
for _ in range(N-1):
a, b = map(int, input().split())
graph[a].append(b)
graph[b].append(a)
def dfs(node):
global result
visited.add(node)
# print(node, end=' ')
for near in graph[node]:
if near not in visited:
parents[near]=node
dfs(near)
visited = set()
parents = [i for i in range(N+1)]
result = 0
dfs(1)
for i in range(2,N+1):
print(parents[i])↑ 정답 코드
gpt한테 피드백 요청했더니
if near not in visited:이걸
if not visited[near]:이렇게 바꾸는 코드를 짰다.
난 원래 거가 마음에 드는듯.
전 문제에 썼던 result 지우는 거 말곤 별거 없었음.
import sys
from collections import deque
input = sys.stdin.readline
N = int(input())
vertices = [[0] for _ in range(N+1)]
parent = [0]*(N+1)
for _ in range(N-1):
a, b = map(int, input().split())
vertices[a].append(b)
vertices[b].append(a)
parent[1] = 0
q = deque()
q.append(1)
while q:
current = q.popleft()
for v in vertices[current]:
if parent[v] == 0:
parent[v] = current
q.append(v)
print('\n'.join(map(str, parent[2:])))큐로 구현하면 더 간단한듯?
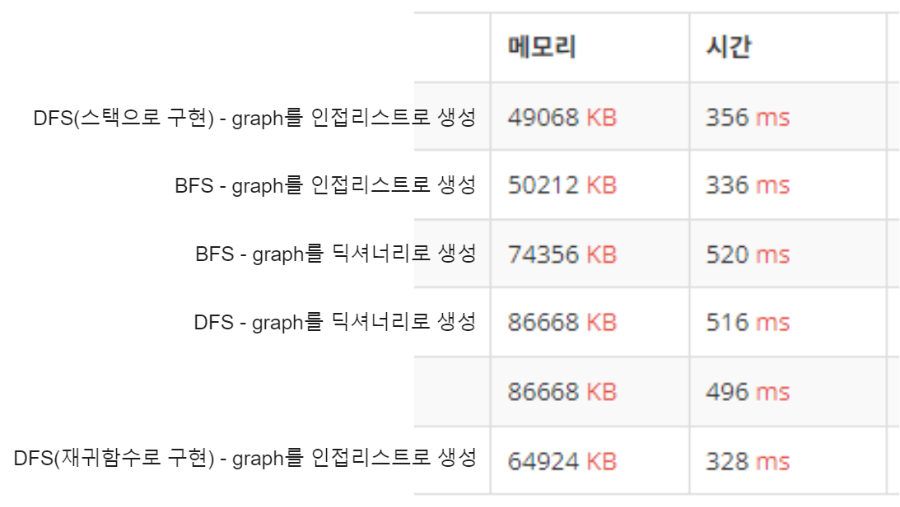
구현 방식에 따른 차이는 이렇게 난다고 한다.
📌 1707 이분 그래프
import sys
input = sys.stdin.readline
sys.setrecursionlimit(10**5)
from collections import deque
def bfs(node, visited, waiting):
visited.append(node)
waiting.append(node)
color[node] = 1
while len(waiting) != 0:
node = waiting.popleft()
for near in graph[node]:
if near not in visited:
waiting.append(near)
visited.append(near)
if color[near] is None:
color[near] = color[node] * -1
else:
if color[near] == color[node]:
return False
return True
K = int(input())
for _ in range(K):
V, E = map(int, input().split())
graph = [[] for _ in range(V+1)]
color = [None for _ in range(V+1)]
for _ in range(E):
a, b = map(int, input().split())
graph[a].append(b)
graph[b].append(a)
visited = []
waiting = deque()
bipartite = True
for i in range(1,V+1):
if i not in visited:
if not bfs(i,visited, waiting):
bipartite = False
break
if bipartite:
print('YES')
else:
print('NO') ↑ 정답 코드
아예 떨어진 그래프가 있다는 것도 고려를 해줘야 하는건가? 하고 해봤더니
그것 때문에 틀린거 맞았음. 성격 못됐다. 문제에라도 적어주지.
📌 21606 아침 산책
# 각 경로는 시작점과 끝점에 대해 유일하므로,
# 시작점과 끝점의 모든 조합을 확인해보면 됨
# 1. 시작점과 끝점은 실내로 제한됨
# 2. 경로 중간에 실내가 있으면 안됨
# 2.1. 부모들을 알아낸다
# 2.2. 겹치는 부모가 있으면 그 이상은 자른다
# 2.3. 부모들 중에 실내가 있는지 확인한다
#
# 2.1.1. 클래스로 선언했던 노드를 루트까지 따라 올라가며 부모들을 알아낸다
# 2.1.2. 만난 부모들은 리스트에 넣어놓는다
# 2.2.1. 겹치는 부모들이 있다면 마지막으로 겹치는 부모를 제외하고 모두 삭제
# 2.3.1. 두 집단의 부모를 훑으며 실내가 있는지 확인한다처음엔 이렇게 접근해봤는데, 생각해보니 루트가 어디인지도 안 알려주고
key가 뭐 어떤 조건으로 나열된다 이런 것도 없어서
실내인 키들을 순회하며 가능한 경로를 탐색하는게 맞을듯
result = 0
def dfs(node, visited):
global result
visited.append(node)
if len(graph[node]) == 0:
return
for near in graph[node]:
if near not in visited:
if A[near-1]=='1':
result += 1
else:
dfs(near, visited)
N = int(input())
A = input()
graph = [[] for _ in range(N+1)]
for _ in range(N-1):
a, b = map(int, input().split())
graph[a].append(b)
graph[b].append(a)
for i in range(1,N+1):
# 실내인 점을 찾았다면
if A[i-1] == '1':
dfs(int(i), [])
print(result)가볍게 dfs 했더니 98점만 맞음.
트리라는 조건을 사용 안 했으니까 당연한 결과.
한 번 갔던 경로는 시작과 끝을 뒤집기만 하면 +1하고 배제 가능하다는 점을 이용하면 될듯.
그러면 최소한 연산 반은 준다.
근데 어떻게?
이진 트리가 아니니까 루트 노드가 어디가 되든 상관이 없지 않나?
아무거나 (예를 들어 1) 루트 노드로 삼은 뒤에 거기까지 가는 부모 노드들을 얻고
처음 떠올렸던 아이디어 쓰면 되지않을까?
실외인 정점들은 다 합쳐버리고 실내인 점들만 잇는 것으로 생각하면 된다.
실외인 자식이 3명이라면 경우의 수는 4*3 = 12 가지.
실내 가지가 또 따로 나온다면 그 경우만 따로 센다.동기에게 대충 위에처럼 설명을 들었다. (훨씬 자세하고 친절하게 설명해줬음)
이해는 했는데 구현하기도 힘들고 어려워서 그냥 넘기고 나중에 답지 보기로 함.
굉장히 안 좋은 행동이라고는 생각하는데 머리가 (비유가 아니라 진짜로) 살짝 어지러워서 일단 패스.
도망치는 건 부끄럽지만 도움이 된다.
📌 14888 연산자 끼워넣기
def select_ope(idx,pre,next):
if idx == 0:
return pre + next
elif idx == 1:
return pre - next
elif idx == 2:
return pre * next
else:
return pre / next
def max_min(maxR,minR,R,remain):
if ope_list[0] != 0:
R += L[-remain]
remain -= 1
maxR = max(maxR, R)
minR = min(minR, R)
if remain != 0:
maxR, minR = max_min(maxR,minR,R,remain)
remain += 1
if ope_list[1] != 0:
R -= L[-remain]
remain -= 1
maxR = max(maxR, R)
minR = min(minR, R)
if remain != 0:
maxR, minR = max_min(maxR,minR,R,remain)
remain += 1
if ope_list[2] != 0:
R *= L[-remain]
remain -= 1
maxR = max(maxR, R)
minR = min(minR, R)
if remain != 0:
maxR, minR = max_min(maxR,minR,R,remain)
remain += 1
if ope_list[3] != 0:
R /= L[-remain]
remain -= 1
maxR = max(maxR, R)
minR = min(minR, R)
if remain != 0:
maxR, minR = max_min(maxR,minR,R,remain)
remain += 1
return maxR, minRdfs고 뭐고 그냥 브루트 포스로 재귀 쓰면 풀린다길래
쓰레기같은 방법으로 구현해봤는데 실패.
좀 더 세련되게 구현해봐야할 것 같다.
select_ope 만들어놓고 왜 안 쓴건지 모르겠고,
왜 똑같은 코드 안 묶고 계속 쓴건지 모르겠다.
아무 생각 없이 코드를 짜면 이런 디지털 쓰레기가 만들어지는구나.
N = int(input())
L = list(map(int, input().split()))
ope_list = list(map(int, input().split()))
res_list = set()
def brute(res,remain,a,b,c,d):
if remain != 0:
if a > 0:
brute(res+L[-remain],remain-1,a-1,b,c,d)
if b > 0:
brute(res-L[-remain],remain-1,a,b-1,c,d)
if c > 0:
brute(res*L[-remain],remain-1,a,b,c-1,d)
if d > 0:
brute(res//L[-remain],remain-1,a,b,c,d-1)
else:
res_list.add(res)
return
a = ope_list[0]
b = ope_list[1]
c = ope_list[2]
d = ope_list[3]
brute(L[0],N-1,a,b,c,d)
maxR = max(res_list)
minR = min(res_list)
print(maxR)
print(minR)그래도 좀 뭐 하려는지 정리하고 깔끔하게 만들어봤는데 틀렸다.
hm/연산자\ 끼워넣기.py
54
-24테스트 케이스를 출력 케이스로 잘못 넣어놓고서 답 나온줄 알고 제출해버렸다.
N = int(input())
L = list(map(int, input().split()))
ope_list = list(map(int, input().split()))
res_list = set()
def brute(res,remain,a,b,c,d):
if remain != 0:
if a > 0:
brute(res+L[-remain],remain-1,a-1,b,c,d)
if b > 0:
brute(res-L[-remain],remain-1,a,b-1,c,d)
if c > 0:
brute(res*L[-remain],remain-1,a,b,c-1,d)
if d > 0:
brute(int(res/L[-remain]),remain-1,a,b,c,d-1)
else:
res_list.add(res)
return
a = ope_list[0]
b = ope_list[1]
c = ope_list[2]
d = ope_list[3]
brute(L[0],N-1,a,b,c,d)
maxR = max(res_list)
minR = min(res_list)
print(maxR)
print(minR)↑ 정답 코드
음수 나누기 문제 때문에 잘못된 답 나왔었다.
//를 /로 바꾸고 int()로 묶어주니 해결.
📌 2573 빙산
# 1. 빙하 상황 받아오기
N, M = map(int, input().split())
Arctic = []
for _ in range(N):
scan = list(map(int,input().split()))
Arctic.append(scan)
# 2. 빙하 노드 배정하기
class Iceberg:
def __init__(self, height, location):
self.height = height
self.location = location
for i in range(N):
for j in range(M):
# print(Arctic[i][j])
height = Arctic[i][j]
if height != 0:
Arctic[i][j] = Iceberg(height, (i,j))빙하가 있는 부분만 노드 배정하려다가 뭔가 이상함을 느낌.
인접 그래프를 굳이 노드로 구현 안 하고
좌표 상하좌우 훑으면서 if != 0 이 조건만 넣으면 빙산 확인되는거 아닌가?
# 빙산이 녹음
# 덩어리를 셈
# 이중리스트로 행렬 구현
# 해당되는 좌표에 빙산 높이를 키, 상하좌우 빙산을 자식으로 넣음
# 상하좌우에 빙산(노드)이 있으면 녹을 때 1 덜 녹음
# 1. 빙하 상황 받아오기
N, M = map(int, input().split())
Arctic = []
Icebergs = set()
# 북극 상황 받아오기
for _ in range(N):
field = list(map(int,input().split()))
Arctic.append(field)
# 빙하가 어디에 있는지 스캔
for i in range(N):
for j in range(M):
height = Arctic[i][j]
if height != 0:
Icebergs.add((i,j))
from collections import deque
def iceberg_cnt(ice, visited, waiting):
cnt = 1
visited.append(ice)
waiting.append(ice)
while len(waiting) != 0:
ice = waiting.popleft()
# print(ice)
# print(waiting)
# print(visited)
i, j = ice[0], ice[1]
if i+1 < N:
if Arctic[i+1][j] > 0:
if (i+1,j) not in visited:
visited.append((i+1,j))
waiting.append((i+1,j))
cnt += 1
if 0 < i-1:
if Arctic[i-1][j] > 0:
if (i-1,j) not in visited:
visited.append((i-1,j))
waiting.append((i-1,j))
cnt += 1
if j+1 < M:
if Arctic[i][j+1] > 0:
if (i,j+1) not in visited:
visited.append((i,j+1))
waiting.append((i,j+1))
cnt += 1
if 0 < j-1:
if Arctic[i][j-1] > 0:
if (i,j-1) not in visited:
visited.append((i,j-1))
waiting.append((i,j-1))
cnt += 1
return cnt
# 빙하 목록에 들어있는 빙하 녹이기
def melting():
meltQueue = set()
# 이번 년도에 빙하가 얼마나 녹을지 계산
for iceberg in Icebergs:
i, j = iceberg[0], iceberg[1]
meltN = 4
if Arctic[i+1][j] != 0: meltN -= 1
if Arctic[i-1][j] != 0: meltN -= 1
if Arctic[i][j+1] != 0: meltN -= 1
if Arctic[i][j-1] != 0: meltN -= 1
if meltN > 0:
meltQueue.add((i,j,meltN))
# 계산해놨던 빙하 녹이는 사건 발생
for melt in meltQueue:
i, j, meltN = melt[0], melt[1], melt[2]
newHeight = Arctic[i][j] - meltN
if newHeight < 0: newHeight = 0
Arctic[i][j] = newHeight
if newHeight <= 0:
Icebergs.remove((i,j))
year = 0
ice = next(iter(Icebergs))
while len(Icebergs) == iceberg_cnt(ice, [], deque()):
melting()
year += 1
ice = next(iter(Icebergs))
print(year)어떻게든 하드코딩해서 풀고 제출했더니 시간초과 엔딩 났음.
내일 와서 다시 풀어야될듯.
(+ 너무 코드가 길어지고 이상해지면 무작정 쓰지 말고 접근 방법을 다시 생각해보자)
