🎯 To-do List
✅ 알고리즘 공부 | B트리, Trie, KMP 알고리즘, 보이어-무어 알고리즘 공부
✅ 백준 | 2869 달팽이는 올라가고 싶다, 2628 종이자르기, 1074 Z
☑️ CS:APP | 3장 안 읽은 부분 마저 읽기, CSAPP 저자 직강 유튜브 보기
📝 배운 것들
🏷️ B-tree
https://www.youtube.com/watch?v=bqkcoSm_rCs&list=PLcXyemr8ZeoREWGhhZi5FZs6cvymjIBVe&index=26
B tree 기본
각 노드의 최대 자녀 노드 수 : M
각 노드의 최대 key 수 : M-1
각 노드의 최소 자녀 노드 수 : (M/2) <- 반올림
각 노드의 최소 key 수 : (M/2)-1 <- (M/2)는 반올림
B tree 추가
맨 끝에 추가하는데 넘치면 쪼개고 가운데는 승진.
- 추가는 항상 leaf 노드에 한다
- 노드가 넘치면 가운데 key를 기준으로 좌우 key들은 분할하고 가운데 key는 승진한다
B tree 데이터 삭제
뭔가 이상해지면(키 수, 자식 수 부족해짐) 부모한테서 가져오거나 형제한테서 가져온 뒤에 합친다
- 삭제는 항상 leaf 노드에서 발생한다
- 삭제 후 최소 key 수보다 적어졌다면 재조정한다
1. key 수가 여유있는 형제의 지원을 받는다
2. 형제의 지원이 불가능하면 부모의 지원을 받고 형제와 합친다
2.1 동생이 있으면 동생과 나 사이의 key를 부모로부터 받는다
- 그 key와 나의 key를 차례대로 동생에게 홥친다
- 나의 노드를 삭제한다
2.2 동생이 여유가 없거나 애초에 없으면 형과 나 사이의 key를 부모로부터 받는다
- 그 key와 형의 key를 차례대로 나에게 합친다
- 형의 노드를 삭제한다
3. 2번 후 부모에 문제가 있다면 상황에 맞게 대응한다
3.1 부모가 root 노드가 아니라면
- 그 위치에서부터 다시 1번부터 재조정을 시작한다
3.2 부모가 root 노드고 비어있다면
- 부모 노드를 삭제한다
- 직전에 합쳐진 노드가 root 노드가 된다
internal 노드 데이터 삭제
- leaf 노드에서 삭제하고 필요하면 재조정
- internal 노드에 있는 데이터를 삭제하려면 leaf 노드에 있는 데이터와 위치를 바꾼 후 삭제한다
- leaf 노드에 있는 데이터 중에 어떤 데이터와 위치를 바꿔줄 것인가?
- 삭제할 데이터의 선임자나 후임자와 위치를 바꿔준다
- 선임자(predecessor) : 나보다 작은 데이터들 중 가장 큰 데이터
- 후임자(successor) : 나보다 큰 데이터들 중 가장 작은 데이터
B tree 시간 복잡도
왜 DB index로 B tree 계열이 사용되는가?
avg case, worst case에 대해 조회, 삽입, 삭제 모두 시간 복잡도가 O(log N)이기 때문이다.
BST는 잘못 넣으면 균형이 깨지기 때문에 스스로 균형을 맞추는 트리들이 만들어짐
AVL tree, Red-Black tree. 이것들도 시간 복잡도가 O(log N)이다.
근데 DB index에는 왜 BST 계열 말고 B tree 계열을 사용하는가?
Computer System
CPU : 프로그램 코드가 실제로 실행되는 곳
Main memory : 실행 중인 프로그램들의 코드들과 코드 실행에 필요한 혹은 그 결과로 나온 데이터들이 상주하는 곳
Secondary storage : 프로그램과 데이터가 영구적으로 저장되는 곳, 실행 중인 프로그램의 데이터 일부가 임시 저장되는 곳 (DB도 여기에)
secondary storage의 특징
- 데이터를 처리하는 속도가 가장 느리다
- 데이터를 저장하는 용량이 가장 크다
- block 단위로 데이터를 읽고 쓴다
- block
- file system이 데이터를 읽고 쓰는 논리적인 단위
- block의 크기는 2의 승수로 표현되며 대표적인 block size는 4KB, 8KB, 16KB 등이 있다.
- 불필요한 데이터까지 읽어올 가능성이 있음
B tree가 DB index로 쓰이는 이유
- DB는 secondary storage에 저장된다
- DB에서 데이터를 조회할 때 secondary storage에 최대한 적게 접근하는 것이 성능 면에서 좋다
- 트리랑 데이터 모두 secondary storage에 있다고 할 때, AVL tree는 같은거 찾을 때 여러 번 트리 왔다갔다 해야되는데 B tree는 그 횟수 줄일 수 있다.
- secondary storage가 block 단위로 가져오므로 BST 계열은 필요없는거 더 많이 가져옴. B tree 노드는 block 단위의 저장 공간을 알차게 사용할 수 있음.
self-balancing BST의 노드들도 block 안에 최대한 담는다면?
: 그게 결국 B tree 동작 방식. BST 다른 노드들 억지로 담은 다음에 그거 해석하는거 구현할 바에야 그냥 B tree 쓰는게 나음.
hash index를 쓰는 건?
: hash index는 삽입/삭제/조회의 시간 복잡도가 O(1)이지만 equaility(=) 조회만 가능하고 범위 기반 검색이나 정렬에는 사용될 수 없다는 단점이 있다.
🏷️ Trie

문자열에 있는 각 요소를 노드로 보고 쭉 이어주고,
여러 개 저장할 때 중복되는 요소는 생략하면
검색을 빠르게 할 수 있다.
🏷️ KMP 알고리즘
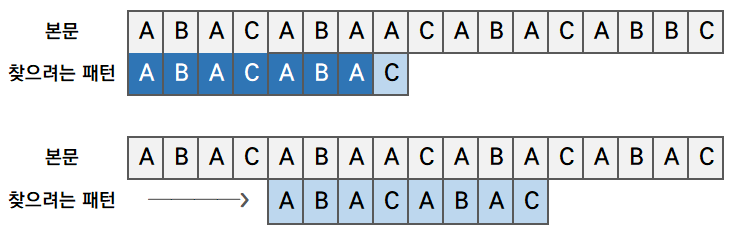
이해 시켜준 글 : https://chanhuiseok.github.io/posts/algo-14/
패턴과 겹치는지 하나씩 확인하다가 패턴 아닌거 찾거나
그동안 앞에 얼마나 겹쳤는지 확인하고 그만큼만 앞으로 돌아감
하나도 안 겹쳤으면 그동안 찾았던 만큼 다 스킵
🏷️ 보이어-무어 알고리즘
이 블로그 설명을 그냥 잘함 : https://chanhuiseok.github.io/posts/algo-15/
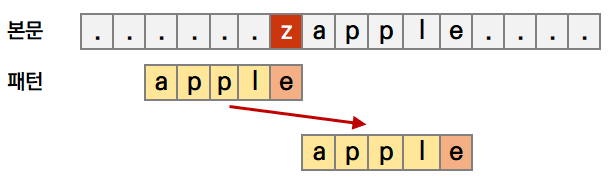
패턴에 안 들어있는건 패스
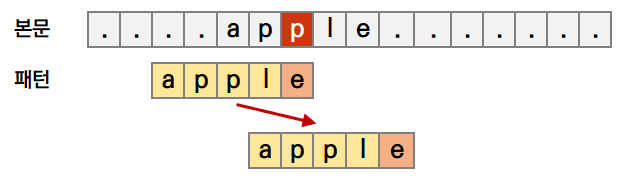
패턴에 들어있으면 뒷부분에 있는 것부터 센다.
기본적으로 KMP는 패턴에 대한 정보만 기억한다면
보이어-무어는 알파벳들에 대한 정보를 기억한다.
⚔️ 백준
📌 1065 한수
n = int(input())
hansu = 0
for i in range(1, n+1):
if i < 100:
hansu += 1
if i >= 100:
temp1 = int(str(i)[0]) - int(str(i)[1])
temp2 = int(str(i)[1]) - int(str(i)[2])
if temp1 == temp2:
hansu+=1
print(hansu)간단하게 파이썬으로 짜면 이정도.
근데 너무 마음에 안 든다.
나는 뭔가 수학적으로 필요한 것만 확인하는 로직이 있을 줄 알았는데
다들 brute force로 풀었다.
저번에도 생각했던 거지만
내가 너무 최적화된 로직 아니면 마음에 안 들고 바로 떠올리지도 않는다.
문제가 여유 주면 여유만큼 풀자.
#include <iostream>
using namespace std;
int arithmetic_sequence(int num) {
int cnt = 0; // 한수 카운팅
if (num < 100) {
return num;
} else {
cnt = 99;
for (int i = 100; i <= num; i++) {
int hun = i / 100; // 백의 자릿수
int ten = (i / 10) % 10; // 십의 자릿수
int one = i % 10;
if ((hun - ten) == (ten - one)) { // 각 자릿수가 수열을 이루면
cnt++;
}
}
}
return cnt;
}
int main(int argc, char const *argv[]) {
int N;
cin >> N;
int result = arithmetic_sequence(N);
cout << result;
return 0;
}조금 더 최적화하면 이정도긴 한데 이것도 마음에 안 듦.
print(sum([((i // 100) - (i % 100 // 10))
== ((i % 100 // 10) - (i % 10))
or i <= 99
for i in range(1, int(input())+1)]))이 사람 좀 잘 푼듯
📌 2628 종이자르기
W, H = map(int, input().split())
N = int(input())
arr_W, arr_H = [0], [0]
for i in range(N):
WorH, line = map(int, input().split())
if WorH == 1:
arr_W.append(line)
else:
arr_H.append(line)
arr_W.append(W)
arr_H.append(H)
arr_W.sort()
arr_H.sort()
W_max, H_max = 0, 0
for i in range(len(arr_W)-1):
W_max = max(W_max,arr_W[i+1]-arr_W[i])
for i in range(len(arr_H)-1):
H_max = max(H_max,arr_H[i+1]-arr_H[i])
print(W_max * H_max)잘 푼듯
📌 10989 정렬하기 3
import sys
input = sys.stdin.readline
N = int(input())
arr = [0]*10001
for _ in range(N):
n = int(input())
arr[n]+=1
for i in range(10001):
if arr[i] != 0:
for _ in range(arr[i]):
print(i)나쁘지 않게 푼듯. 옆 동기가 딕셔너리로 풀어본다길래 아이디어 얻음.
📌 1074 Z
# 사분면으로 쪼개기
N, r, c = map(int,input().split())
x, y, size = 0, 0, 2**N
cnt=0
def visitOrder(x,y,size):
global cnt
if(size == 1):
print(int(cnt))
return
half = size/2
if x+half > c:
if y+half > r:
return visitOrder(x,y,half)
else:
cnt+=size*size*(2/4)
return visitOrder(x,y+half,half)
else:
if y+half > r:
cnt+=size*size*(1/4)
return visitOrder(x+half,y,half)
else:
cnt+=size*size*(3/4)
return visitOrder(x+half,y+half,half)
visitOrder(x,y,size)옆 동기 풀이를 많이 참고함.
