🎯 To-do List
⏳ Routine
✅ 알고리즘 스터디 | 1655 가운데를 말해요
☑️ 기술 면접 준비 |
🍪 Plan
☑️ c++ 공부하기
☑️ 기술 면접 준비 | (1) 경쟁 조건, 데드락, (2) 뮤텍스, 세마포어, 조건 변수, (3) 멀티프로세스와 멀티쓰레드의 차이
☑️ malloc 구현 후 | CS:APP 6장 읽기, 복습을 위해 이거 보기
📚 Journal
내일부터는 룸메형한테 좀 더 적극적으로 깨워달라고 했다.
새 삶을 살아야 한다.
야행성 생활은 건강에 안 좋다.
뭘 해야될지 갈팡질팡해서
컨텍스트 스위칭에 의한 오버헤드가 자꾸 발생하는 것 같다.
명확하게 오늘 언제 뭐 할지 목표를 적어놓자. (집에서 리걸패드 가져오면 좋을듯)
📦 Malloc
고친 함수도 너무 많고 고칠 곳도 많다.
그리고 남은 구현해야할 것들도 너무 많다. (next fit, best fit, seglist 등)
디버깅을 통해 내가 짠 코드가 어디서 틀렸는지 확인하는 것도 귀중한 경험이겠지만
일단 답지 보면서 어디서 틀렸는지, 로직이 맞았는지 확인하고 다음 걸로 확인하는게 더 나을듯.
답지 : https://yskisking.tistory.com/223
1 : 매크로
/* bp에 대해 pred와 succ가 적힌 곳의 주소를 구한다 */
#define PREP(bp) ((char *)(bp)) // 이거 그냥 그대로라 필요 없긴 한데 의미 드러나게 선언
#define NXTP(bp) ((char *)(bp) + WSIZE)내가 한 건 이건데
#define PRED_FREEP(bp) (*(void **)(bp))
#define SUCC_FREEP(bp) (*(void **)(bp + WSIZE))답지에는 이렇게 돼있었음.
동기에게 물어보니 컴파일러에 따라서 *(void **)(bp) 이렇게 하면
char *로 바꿔주는 것들도 있다고 함.
근데 gpt에게 물어보니 애초에 두개는 다르다고 함.
일단 내 걸로 가보고 안되면 답지 걸 쓰는게?
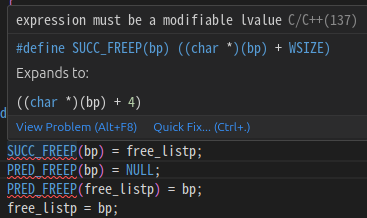
내걸로 해보니까 오류 뜸.
이중 포인터 써야 됨.
다시 생각해보니까 완전히 다른거 맞음.
내건 그냥 주소를 가져오는 거였고,
답지는 주소에 들어있는 값을 가져오는 거임.
2 : mm_init
내 코드
PUT(heap_listp, 0); // 정렬 패딩
PUT(heap_listp + (1 * WSIZE), PACK(DSIZE, 1)); // 프롤로그 헤더
PUT(heap_listp + (2 * WSIZE), PACK(DSIZE, 1)); // 프롤로그 푸터
PUT(heap_listp + (3 * WSIZE), PACK(0, 1)); // 에필로그 헤더
heap_listp += (2 * WSIZE);답지
PUT(heap_listp, 0); // 정렬 패딩
PUT(heap_listp + (1 * WSIZE), PACK(DSIZE, 1)); // 프롤로그 헤더
PUT(heap_listp + (2 * WSIZE), NULL); // 프롤로그 PRED 포인터 NULL로 초기화
PUT(heap_listp + (3 * WSIZE), NULL); // 프롤로그 SUCC 포인터 NULL로 초기화
PUT(heap_listp + (4 * WSIZE), PACK(16, 1)); // 프롤로그 풋터 16/1
PUT(heap_listp + (5 * WSIZE), PACK(0, 1)); // 에필로그 헤더 0/1
free_listp = heap_listp + DSIZE; // free_listp는 프롤로그 PRED 포인터를 가리키고 있다프롤로그 블록을 가용리스트에 꼭 추가해야 하는 건가? 일단 로직을 좀 더 보자.
// @@@ explicit @@@ 수정함 4 -> 6, PRED, SUCC 추가했기 때문
if((heap_listp = mem_sbrk(24)) == (void *)-1) {
return -1;
}후에 답지 다시 따라쳐보다가 이것도 해줘야 하는거 확인.
3 : extend_heap
내 코드
/* 가용 블록 헤더/푸터, 에필로그 푸터를 초기화 */
/* sbrk에서 반환된 포인터 bp는 이전의 에필로그 블록을 가리키고 있음.
sbrk로 heap의 크기가 늘어났으므로, 이전의 에필로그 블록을 가용 블록으로 변환해야 함.
이를 위해 새로운 가용 블록의 헤더와 푸터를 설정하고, 새로운 에필로그 블록을 생성하는 과정. */
/* 가장 최근에 생긴 가용 블록이므로 다음 가용 블록 포인터는 NULL */
PUT(HDRP(bp), PACK(size, 0)); // 가용 블록 헤더
PUT(HDRP(bp) + WSIZE, recent_free); // 이전 가용 블록 포인터 : recent_free
PUT(HDRP(bp) + 2 * WSIZE, 0); // 다음 가용 블록 포인터
PUT(FTRP(bp), PACK(size, 0)); // 가용 블록 푸터
PUT(HDRP(NEXT_BLKP(bp)), PACK(0, 1)); // 새 에필로그 헤더
recent_free = bp;답지
// 헤더, 풋터, 에필로그 헤더 설정
// 새로 가용된 블록들은 분할되어 있지 않다
PUT(HDRP(bp), PACK(size, 0)); // 기존 에필로그 블록을 새로운 가용 블록의 헤더로 설정한다
PUT(FTRP(bp), PACK(size, 0)); // 새로운 가용 블록의 풋터를 설정한다
PUT(HDRP(NEXT_BLKP(bp)), PACK(0, 1)); // 새로운 에필로그 헤더 설정왜 새로 생긴 가용 블록인데 가용 리스트에 추가를 안 하는거지? 생각했는데
동기한테 물어봤더니 병합할 때 추가된다고 함. 일단 이것도 그런갑다 하고 패스.
4 : mm_malloc
내 코드
// 넣을 데이터의 사이즈가 더블워드보다 작으면
// 할당할 블록의 크기를 강제로 키워준다
if (size <= DSIZE)
asize = 3 * DSIZE;
// 아니라면 8바이트 정렬만 맞춰준다
else
asize = DSIZE * ((size + 3 * DSIZE - 1) / DSIZE);답지
// size가 8 이하면 16으로 설정 ( 8단위로 정렬되니까. 8바이트만 있으면 헤더풋터 넣으면 끝임 )
if(size <= DSIZE) {
asize = 2*DSIZE;
}
// size가 9이상이면
else {
asize = DSIZE * ((size + (DSIZE) + (DSIZE - 1)) / DSIZE); // 헤더풋터(더블워드) 추가한 후 8의 배수로 올림
}이건 최소 크기를 늘려주지도 않음. 묵시적이랑 코드 똑같음. 왜???
5 : find_fit
내 코드
static void *find_fit(size_t asize)
{
void *bp = recent_free;
// recent_free가 가리키는 블록부터 시작해서 0 될 때까지 탐색
while (bp != 0)
{
// 헤더를 봤더니 할당되어 있지 않고, 충분히 크다면
if (!GET_ALLOC(HDRP(bp)) && (asize <= GET_SIZE(HDRP(bp))))
return bp; // 할당
bp = PREV_FREE(bp); // 이전 블록 계속 탐색
}
return NULL; // 맞는 블록이 없으면 NULL 반환
}답지
// 적절한 가용 블록 찾기 ( first fit )
static void *find_fit(size_t asize) {
void *bp;
// @@@ explicit @@@
// 가용블록의 후임자를 지목하며 순회한다. 마지막 후임자는 PRED 블록이다.
// PRED블록의 헤더는 프롤로그 헤더이다. 해당 블록을 만나면 가용리스트를 다 쓴 것이므로 종료
// PRED와 SUCC중 SUCC은 일반 가용 블록과의 비교조건(필드)를 동일시 하기 위해서와,
// 8바이트 정렬조건을 만족시키기 위해 존재한다.
for(bp = free_listp; GET_ALLOC(HDRP(bp)) != 1; bp = SUCC_FREEP(bp)) {
// 가용블록 사이즈가 적절하면 해당 가용블록 포인터 리턴
if(GET_SIZE(HDRP(bp)) >= asize) {
return bp;
}
}
// 맞는 블록이 없으면 NULL리턴
return NULL;
}(!GET_ALLOC(HDRP(bp)) 이 부분 지워줘야 했던거 말곤 다른거 없는듯
6 : place
내 코드
static void place(void *bp, size_t asize)
{
size_t osize = GET_SIZE(HDRP(bp));
if ((osize - asize) >= (3 * DSIZE))
{
// payload 담은 블록 헤더 푸터 설정
PUT(HDRP(bp), PACK(asize, 1));
PUT(FTRP(bp), PACK(asize, 1));
bp = NEXT_BLKP(bp);
// 가용 블록 헤더 푸터 가용리스트 설정
PUT(HDRP(bp), PACK(osize - asize, 0));
PUT(FTRP(bp), PACK(osize - asize, 0));
PUT(PREP(bp), recent_free);
PUT(NXTP(bp), 0);
recent_free = bp;
// 이전 가용 블록으로 찾아가서
// 현재 가용 블록을 다음 가용 블록으로 만들어야 함
PUT(NXTP(PREV_FREE(bp)), bp);
}
else
{
PUT(HDRP(bp), PACK(GET_SIZE(HDRP(bp)), 1));
PUT(FTRP(bp), PACK(GET_SIZE(HDRP(bp)), 1));
// 이전 가용 블록으로 찾아가서
// 현재 블록의 다음 가용 블록과 이어줘야 함
connect_free_list(bp);
}
}답지
// @@@ explicit @@@
// asize만큼 할당하고 남은 가용 블록이, 최소블록 기준보다 같거나 큰 경우에만 분할해야 한다(남은 블록이 16byte 이상)
static void place(void *bp, size_t asize) {
// 후보 가용 블록의 사이즈
size_t csize = GET_SIZE(HDRP(bp));
// @@@ explicit @@@
// 할당할 것이니 freeList에서 지워주기
removeBlock(bp);
// 필요한 만큼 할당한 후 남은 가용 블록이, 최소블록 기준(16)보다 같거나 큰 경우 분할
if((csize - asize) >= (2*DSIZE)) {
// 할당할 가용 블록의 헤더/풋터 설정
PUT(HDRP(bp), PACK(asize, 1));
PUT(FTRP(bp), PACK(asize, 1)); // 헤드 크기를 보고 풋터를 찾아간다
// 할당하고 남은 블록의 헤더/풋터 설정
bp = NEXT_BLKP(bp);
PUT(HDRP(bp), PACK(csize-asize, 0));
PUT(FTRP(bp), PACK(csize-asize, 0));
// @@@ explicit @@@
// 할당하고 남은 가용 블록 freeList 에 넣어주기
putFreeBlock(bp);
}
// 남을 가용 블록이 16보다 작을 경우, 남은 걸 통째로 할당해 버린다
else {
PUT(HDRP(bp), PACK(csize, 1));
PUT(FTRP(bp), PACK(csize, 1));
}
}대충 보긴 했는데 내가 적은 걸 함수로 묶어준 차이밖에 없는듯.
나는 이 함수 만든 후에 구현한 이후에 removeBlock와 putFreeBlock를 하나로 묶은
connect_free_list라는 함수를 만들었다.
7 : mm_free
내 코드
void mm_free(void *bp)
{
size_t size = GET_SIZE(HDRP(bp));
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
PUT(PREP(bp), recent_free);
PUT(NXTP(bp), 0);
recent_free = bp;
coalesce(bp);
}답지
void mm_free(void *bp)
{
size_t size = GET_SIZE(HDRP(bp));
// allocated를 0으로 설정
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
// 해제했으니 연결하러 간다
coalesce(bp);
}나는 당연히 직관적으로 free되고 나면 바로
리스트에서 제거해줘야 하는거 아닌가? 생각했는데
답지는 coalesce(병합) 함수에서 리스트 제거를 담당했다.
다시 생각해보니 병합이 가능하면 지워줄 일도 없을 뿐더러,
병합해줘야 하는데 리스트에서 이미 지워져 있으면 리스트에 재추가하는 로직이 곤란해질듯.
더 열심히 해서 시간만 더 확보했어도 여기까지 제대로 생각이 도달했을텐데.
8 : coalesce
내 코드
static void *coalesce(void *bp)
{
size_t prev_alloc = GET_ALLOC(FTRP(PREV_BLKP(bp)));
size_t next_alloc = GET_ALLOC(HDRP(NEXT_BLKP(bp)));
size_t size = GET_SIZE(HDRP(bp));
// case 1 : 이전과 다음 블록이 모두 할당되어 있다. 병합 불가
if (prev_alloc && next_alloc)
{
return bp;
}
// case 2 : 다음 블록만 가용 블록. 다음 블록과 병합.
else if (prev_alloc && !next_alloc)
{
connect_free_list(bp);
bp = NEXT_BLKP(bp);
connect_free_list(bp);
bp = PREV_BLKP(bp);
size += GET_SIZE(HDRP(NEXT_BLKP(bp)));
PUT(HDRP(bp), PACK(size, 0)); // 헤더에 기록된 size를 바꾼다
PUT(FTRP(bp), PACK(size, 0)); // 헤더에 기록된 size가 바뀌었으니 FTRP(bp)의 반환값도 size만큼 커진다
}
// case 3 : 이전 블록만 가용 블록. 이전 블록과 병합.
else if (!prev_alloc && next_alloc)
{
connect_free_list(bp);
bp = PREV_BLKP(bp);
connect_free_list(bp);
bp = NEXT_BLKP(bp);
size += GET_SIZE(HDRP(PREV_BLKP(bp)));
PUT(FTRP(bp), PACK(size, 0)); // 푸터에 기록된 size를 바꾼다
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0)); // 이전 가용 블록의 헤더에 기록된 size를 바꾼다
bp = PREV_BLKP(bp);
}
// case 4 : 이전 블록과 다음 블록 모두 가용 블록. 모두 병합.
else
{
connect_free_list(bp);
bp = NEXT_BLKP(bp);
connect_free_list(bp);
bp = PREV_BLKP(bp);
bp = PREV_BLKP(bp);
connect_free_list(bp);
bp = NEXT_BLKP(bp);
size += GET_SIZE(HDRP(PREV_BLKP(bp))) + GET_SIZE(FTRP(NEXT_BLKP(bp)));
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0)); // 이전 가용 블록의 헤더에 기록된 size를 바꾼다
PUT(FTRP(NEXT_BLKP(bp)), PACK(size, 0)); // (bp에 적힌 size는 아직 바뀌지 않았으니 NEXT_BLKP가 원하는대로 작동)
bp = PREV_BLKP(bp);
}
return bp;
}답지
static void *coalesce(void *bp) {
// 이전, 다음 블록의 allocated 여부 확인
size_t prev_alloc = GET_ALLOC(FTRP(PREV_BLKP(bp)));
size_t next_alloc = GET_ALLOC(HDRP(NEXT_BLKP(bp)));
// 현재 블록의 size 확인
size_t size = GET_SIZE(HDRP(bp));
/*
size와 새로운 헤더/풋터를 설정하면,
기존 헤더/풋터는 가비지 값처럼 인식되어 무의미해 진다. 일반 블록처럼 쓸 수 있다.
*/
// @@@ explicit @@@
// 연결한 후에 freeList에 따로 추가해준다
// removeBlock은 freeList에서 끊어주는 것이다
// case 1 : 앞뒤 모두 할당 상태일 땐 밑에서 freeList에 바로 넣어준다
// case 2 : 뒤만 미할당 상태일 때
if(prev_alloc && !next_alloc) {
// 뒤가 미할당이니 뒤를 합쳐야 한다.
// 현재 블록과 합치기 위해 뒤 블록의 freeList연결을 해제하고 헤더/풋터를 설정해 준다
removeBlock(NEXT_BLKP(bp));
// 뒤 블록 사이즈를 더한다
size += GET_SIZE(HDRP(NEXT_BLKP(bp)));
// 더해진 사이즈와 allocated를 현재블록 헤더/뒷블록 풋터에 할당한다
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
}
// case 3 : 앞만 미할당 상태일 때
else if(!prev_alloc && next_alloc) {
// freeList에서 이전 블록 연결을 끊어준다
removeBlock(PREV_BLKP(bp));
// 앞 블록 사이즈를 더한다
size += GET_SIZE(HDRP(PREV_BLKP(bp)));
// 블록 포인터를 앞 블록으로 옮겨준다
bp = PREV_BLKP(bp);
// 더해진 사이즈와 allocated를 앞블록 헤더/현재블록 풋터에 할당한다
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
}
// case 4 : 앞/뒤 모두 미할당 상태일 때
else if(!prev_alloc && !next_alloc) {
// freeList에서 앞/뒤 블록 연결을 모두 끊어준다
removeBlock(PREV_BLKP(bp));
removeBlock(NEXT_BLKP(bp));
// 앞/뒤 블록 사이즈를 더한다
size += GET_SIZE(HDRP(PREV_BLKP(bp))) + GET_SIZE(FTRP(NEXT_BLKP(bp)));
// 더해진 사이즈와 allocated를 앞블록 헤더/뒷블록 풋터에 할당한다
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0));
PUT(FTRP(NEXT_BLKP(bp)), PACK(size, 0));
// 앞/뒤와 합쳤으니, 블록 포인터를 앞쪽으로 옮겨준다.
bp = PREV_BLKP(bp);
}
// 연결된 블록을 freeList의 앞쪽에 추가한다
putFreeBlock(bp);
return bp;
}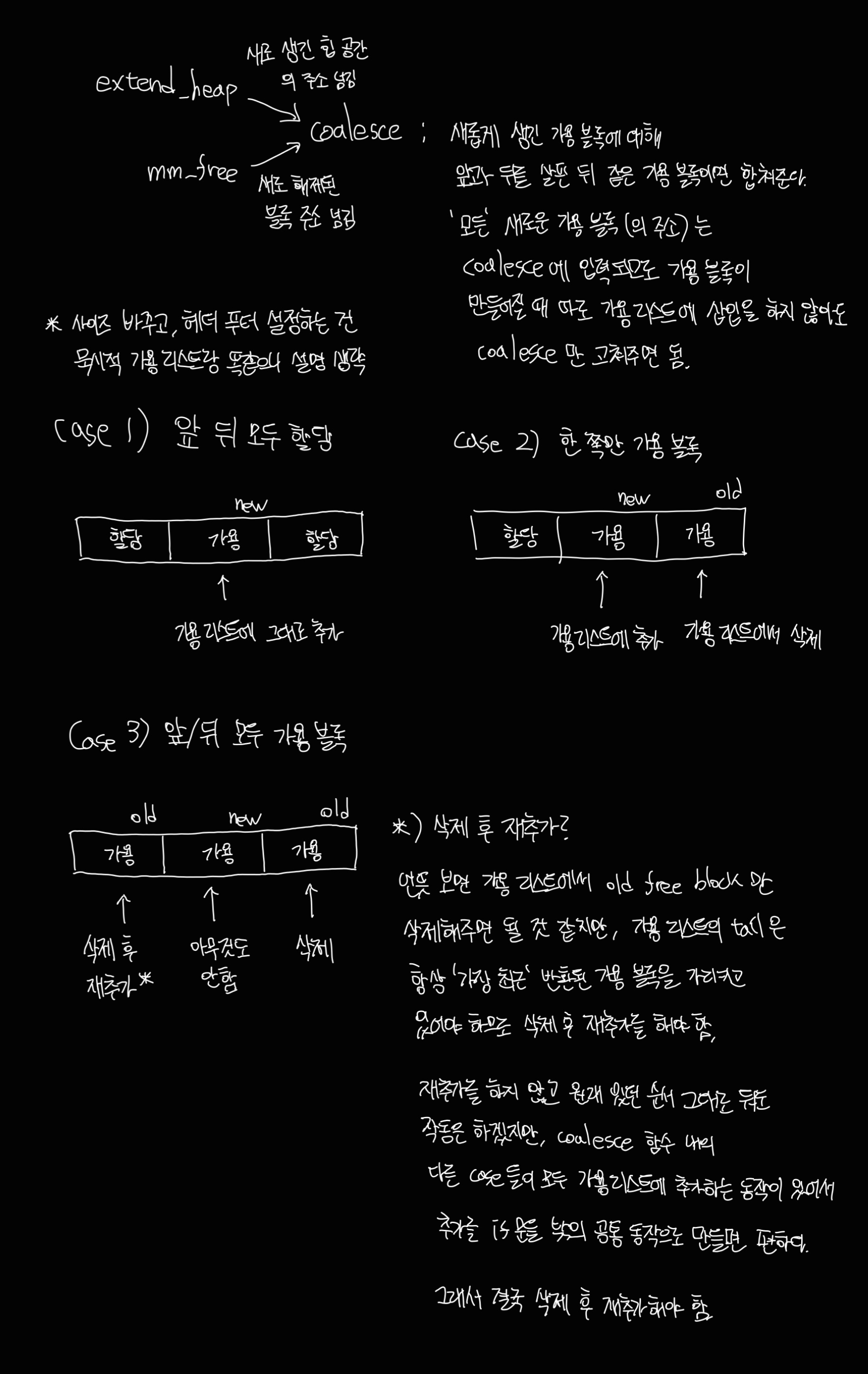
로직은 일단 이해하긴 했다.
connect_free_list(bp);
bp = NEXT_BLKP(bp);
connect_free_list(bp);
bp = PREV_BLKP(bp);
bp = PREV_BLKP(bp);
connect_free_list(bp);
bp = NEXT_BLKP(bp);내 코드에서 이 부분 좀 바보같았던 것 같음.
그냥 connect_free_list(NEXT_BLKP(bp)) 해버리면 그만인데.
bp를 일일이 옮겨다닐 필요 없었음.
9 : connect_free_list (removeBlock, putFreeBlock)
내 코드
// 가용 리스트에서 사라지는 노드의 양 옆 노드를 이어줌
void connect_free_list(char *bp)
{
if (PREV_FREE(bp) != 0)
PUT(NXTP(PREV_FREE(bp)), NEXT_FREE(bp));
if (NEXT_FREE(bp) != 0)
PUT(PREP(NEXT_FREE(bp)), PREV_FREE(bp));
}답지
// @@@ explicit @@@
// 반환/생성된 새로운 free 블록을 freeList 맨 앞에 추가한다
void putFreeBlock(void *bp) {
// 기존 맨앞에 있던애를 이제 넣을애 후임자로
SUCC_FREEP(bp) = free_listp;
// 맨앞이니까 앞에껀 없고
PRED_FREEP(bp) = NULL;
// 기존 맨앞에 있던애의 전임자를 이제 넣을애로
PRED_FREEP(free_listp) = bp;
// freeList 포인터를 이제 넣을애로
free_listp = bp;
}
// @@@ explicit @@@
// free 리스트에서 블록 지우기
void removeBlock(void *bp) {
// 첫 번째 블록을 없앨 때
if(bp == free_listp) {
// 뒤 free 블록의 PRED 포인터를 없앤다
PRED_FREEP(SUCC_FREEP(bp)) = NULL;
// freeList의 첫 번째 포인터를 뒤 free 블록으로 한다
free_listp = SUCC_FREEP(bp);
}
else {
// 가운데인 내가 빠지니 앞과 뒤를 이어준다
SUCC_FREEP(PRED_FREEP(bp)) = SUCC_FREEP(bp);
PRED_FREEP(SUCC_FREEP(bp)) = PRED_FREEP(bp);
}
}함수에 다 넣어도 되는 것들을 나는 다 밖에다가 따로따로 넣어버려서 다소 초라한듯.
10 : 결국
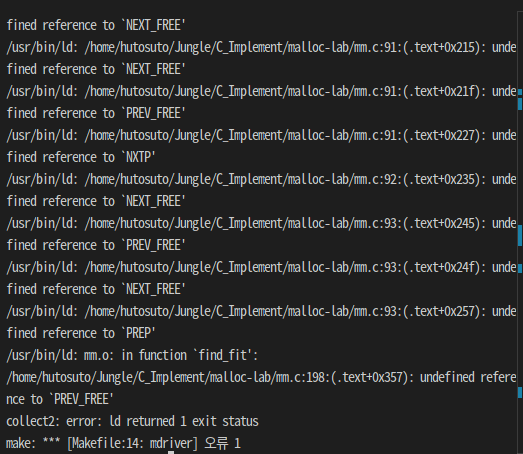
답지 보면서 클론 코딩해봤는데 다른 변수명이 워낙 많아서 놓친 게 너무 많았음.
로직 열심히 공부했으니 일단 만족해야할듯...
묵시적 + next fit 구현이나 해보자.
⚔️ 백준
📌 2504 괄호의 값
import sys
input = sys.stdin.readline
brackets = list(input().strip())
stack=[]
# 유효한 괄호열인지 확인
for brkt in brackets:
if stack:
if stack[-1] == '(' and brkt == ')':
stack.pop()
continue
elif stack[-1] == '[' and brkt == ']':
stack.pop()
continue
stack.append(brkt)
if stack:
print(0)
else:
for brkt in brackets:
if brkt == ')':
if stack[-1] == '(':
stack.pop()
stack.append(2)
else:
piece = 0
while(stack[-1] != '('):
piece += stack.pop()
stack.pop()
stack.append(2 * piece)
elif brkt == ']':
if stack[-1] == '[':
stack.pop()
stack.append(3)
else:
piece = 0
while(stack[-1] != '['):
piece += stack.pop()
stack.pop()
stack.append(3 * piece)
else:
stack.append(brkt)
print(sum(stack))어제 기숙사로 돌아와서 폰으로 코드 짜고 제출해봤더니
아무리 해도 계속 런타임 오류가 뜸.
로직은 분명히 맞는데 뭐지? 이러다가
오늘 교육장으로 돌아와서 노트북 VSCode로 돌려보니 디버깅 단계에서 바로 오류가 뜸.
현재 piece 자리에 sum을 넣어서였음.
이미 선언돼있는걸 쓰고 있어서 그랬던 거였는듯.
그거 고치니까 바로 됨.
📌 1655 가운데를 말해요
import heapq
N = int(input())
heap = []
for i in range(1,N+1):
heapq.heappush(heap,int(input()))
if i%2==0: print(heap[i//2-1])
else: print(heap[i//2])heap에 넣으면 알아서 정렬되는거 아닌가?
그거 가운데 인덱스 가져오면 되는거 아님?
라고 생각하긴 했음. 근데 아니었음.
[1, 2, 3, 8, 4, 9, 5, 10, 7, 6]
1
/ \
2 3
/ \ / \
8 4 9 5
/ \ /
10 7 6이런 느낌이었음.
import heapq
N = int(input())
heap = []
for i in range(1,N+1):
heapq.heappush(heap,int(input()))
middle = heapq.nsmallest(i//2+1, heap)
if i%2 != 0: print(middle[-1])
else: print(middle[-2])힙 모듈로 만들어본 날먹 코드.
테케는 통과하는데 시간초과 뜬다.
# 이분 탐색 : 인덱스 반 쪼개보고 같으면 넣기,
jump = i//4
while(1):
if(arr[idx]>n):
idx += jump
elif(arr[idx]<n):
idx -= jump
elif(arr[idx]==n):
arr.insert(idx+1,n)
break
if jump == 0:
arr.insert(idx+1,n)
break
jump //= 2
if i%2==0: print(arr[(i+1)//2+1])
else: print(arr[(i+1)//2])이분탐색 구현해보려고 했는데 실패.
변수를 2개만 써도 되는 cool한 방법이라고 생각은 되는데
일단 빨리 풀고 집에 가고 싶기 때문에 책에 있는 이분 탐색 코드를 다시 봄.
N = int(input())
arr = [int(input())]
print(arr[0])
for i in range(1,N):
n = int(input())
pl = 0
pr = i-1
while True:
pc = (pl + pr) // 2
if arr[pc] == n:
arr.insert(pc,n)
break
elif arr[pc] < n:
pl = pc + 1
else:
pr = pc - 1
if pl > pr:
if arr[pc] > n:
arr.insert(pc+1,n)
else:
arr.insert(pc,n)
break
if i%2!=0: print(arr[i//2])
else: print(arr[i//2+1])책 보고 짰는데도 계속 틀림. 최후의 수단으로 gpt를 씀.
N = int(input())
arr = [int(input())]
print(arr[0])
for i in range(1, N):
n = int(input())
pl = 0
pr = i - 1
while pl <= pr:
pc = (pl + pr) // 2
if arr[pc] == n:
arr.insert(pc, n)
break
elif arr[pc] < n:
pl = pc + 1
else:
pr = pc - 1
else:
arr.insert(pl, n)
if (i + 1) % 2 != 0:
print(arr[(i + 1) // 2])
else:
print(arr[(i + 1) // 2 - 1])이제 정상적으로 돌아가긴 했음.
근데 시간 초과 뜸.
import heapq
import sys
input = sys.stdin.readline
N = int(input())
mid = 0
max_h = []
min_h = []
for i in range(N):
n = int(input())
if i==0:
mid = n
print(mid)
else:
if n <= mid:
heapq.heappush(max_h,-n)
heapq.heappush(min_h,mid)
mid = -heapq.heappop(max_h)
else:
heapq.heappush(min_h,n)
heapq.heappush(max_h,-mid)
mid = heapq.heappop(min_h)
if (i+1)%2 == 0: print((-1)*heapq.nsmallest(1,max_h))
else: print(mid)질문 게시판에서
1. 답 코드 살짝 구조만 봄
2. 힙 2개를 사용해야 한다는 힌트 봄
이 2개로 여기까지 만들어봤는데 안됨.
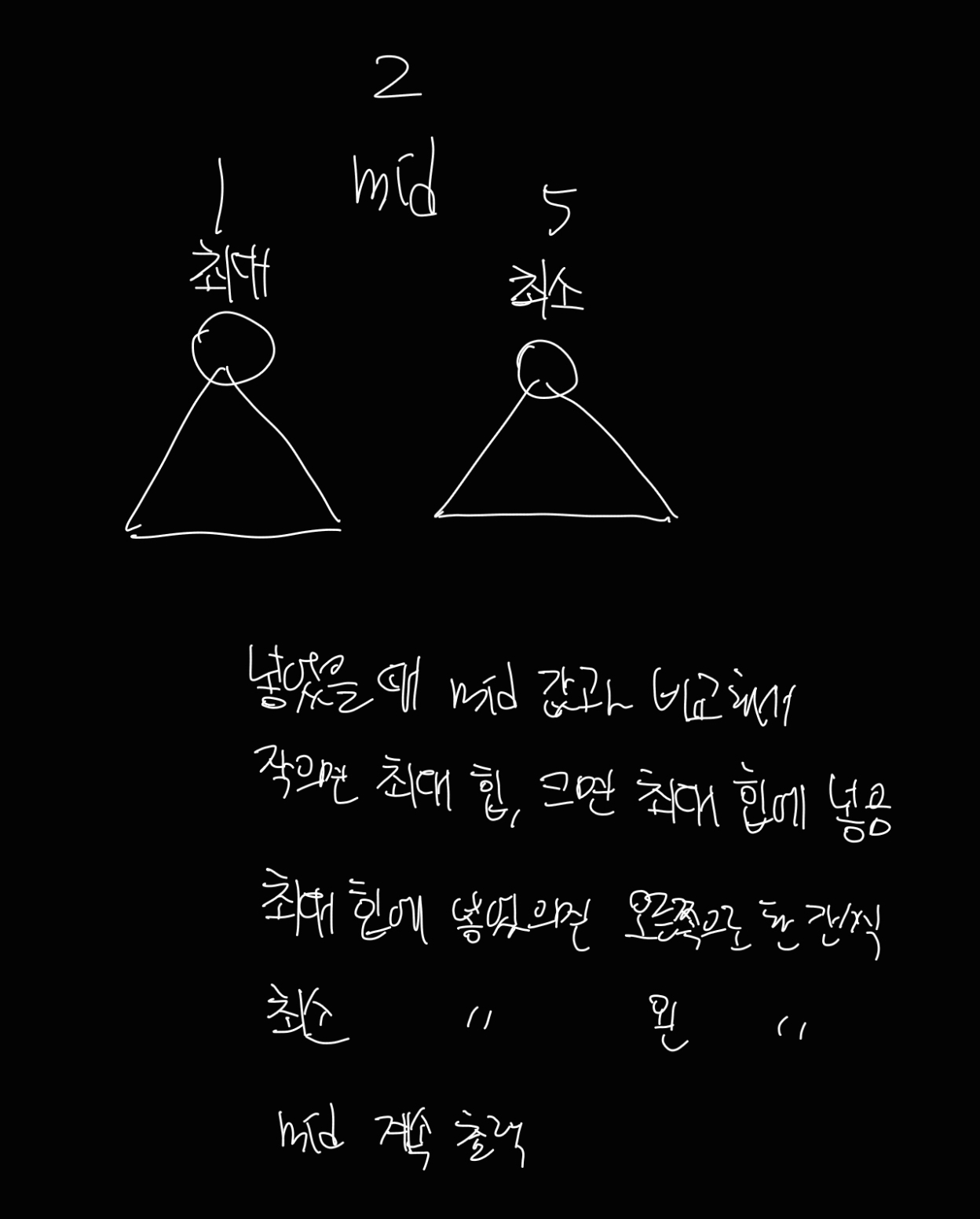
로직은 이랬음.
슬슬 힘들어서 gpt한테 고쳐달라고 함.
import heapq
import sys
input = sys.stdin.readline
N = int(input())
max_h = [] # 최대 힙 (파이썬 힙은 최소 힙이므로, 음수 값을 넣어 최대 힙처럼 사용)
min_h = [] # 최소 힙
for i in range(N):
n = int(input())
if len(max_h) == len(min_h):
heapq.heappush(max_h, -n)
else:
heapq.heappush(min_h, n)
if min_h and -max_h[0] > min_h[0]:
max_val = -heapq.heappop(max_h)
min_val = heapq.heappop(min_h)
heapq.heappush(max_h, -min_val)
heapq.heappush(min_h, max_val)
print(-max_h[0])
그랬더니 완전히 뜯어고쳐버림.
백준 제출했더니 맞았습니다 뜨긴 함.
이런 테크닉을 얻어서 의미가 있다고 해야할지
사실상 힌트와 gpt에 의존해서 의미가 없다고 해야할지...
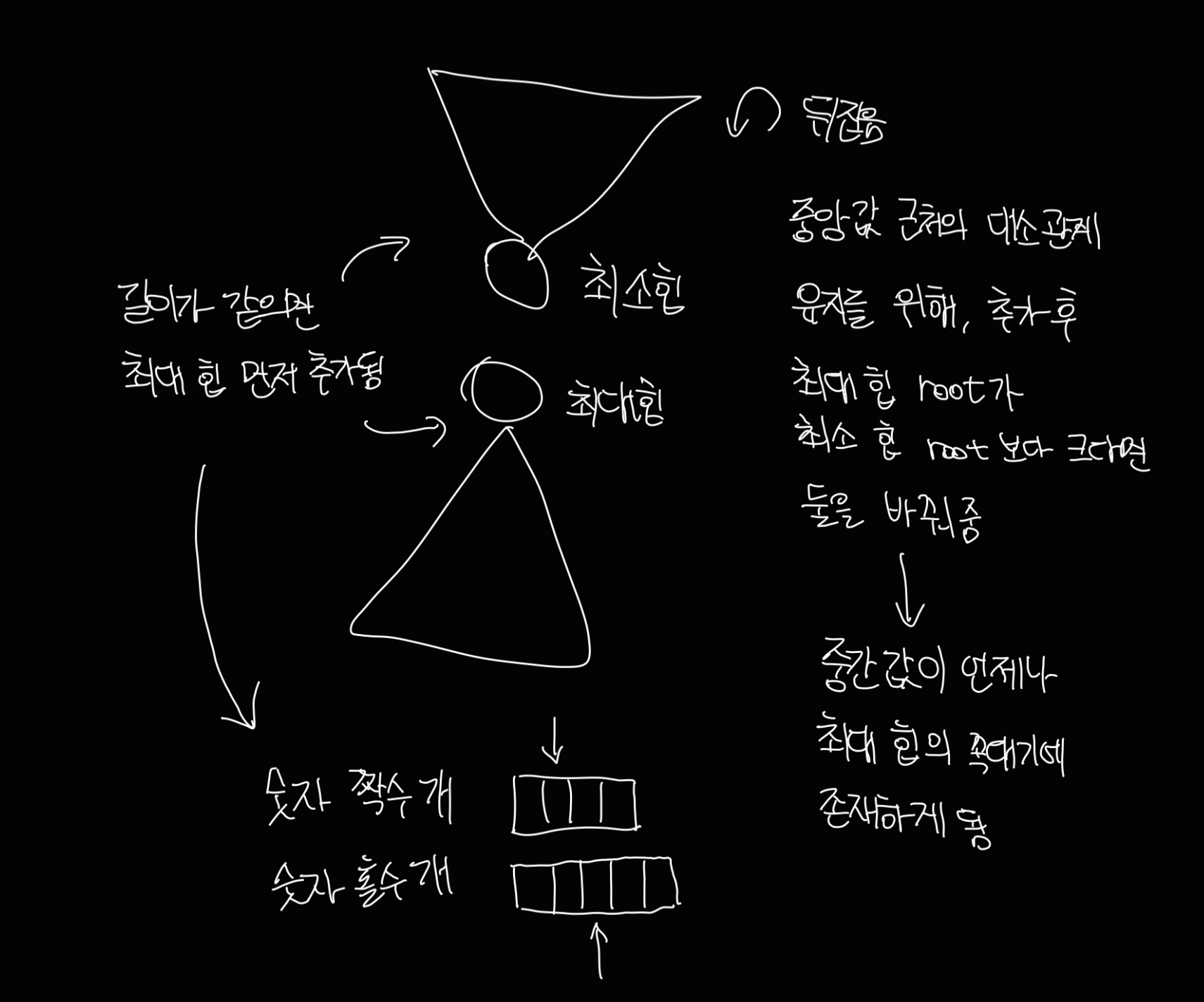
↑ 로직 이해한 노트
from heapq import heappop, heappush
N = int(input())
leftHeap =[]
rightHeap = []
L = []
for i in range(N):L.append(int(input()))
mid = L[0]
answer=[mid]
for i in range(1,N):
num = L[i]
if mid <=num :
heappush(rightHeap,num)
else:
heappush(leftHeap,-1*num)
if (i+1)%2==0 :
if len(leftHeap) > len(rightHeap) :
heappush(rightHeap, mid)
mid = -1*heappop(leftHeap)
else:
if len(leftHeap)+2==len(rightHeap) :
heappush(leftHeap, -1*mid)
mid = heappop(rightHeap)
answer.append(mid)
for a in answer:
print(a)https://frog-in-well.tistory.com/65
이 사람 코드처럼 mid 쓰는게 직관적으로 이해는 더 편할듯.
나도 시간을 조금(사실 많이) 더 줬으면 여기까지 갈 수 있었을듯?
