🎯 To-do List
⌚ Time Tracking
- 10:40 - 11:00 : 기상, 공부 세팅
- 11:00 - 12:00 : CSAPP 읽기
- 12:00 - 13:15 : 점심
- 13:15 - 13:50 : CSAPP 읽기
- 13:50 - 16:40 : 낮잠
- 16:40 - 18:00 : 핸드폰, 휴식
- 18:00 - 19:10 : tiny 서버 구현
- 19:10 - 20:15 : 저녁
- 20:15 - 20:30 : tiny 서버 구현
- 20:30 - 20:45 : 라운지 이동
- 20:45 - 23:40 : tiny 서버 구현
- 23:40 - 00:35 : 2805 나무 자르기 풀기
- 00:35 - 01:25 : 복기 및 기록
- 01:25 - 01:45 : tiny 서버 구현
🔆 Today
- CSAPP 읽기 | 11.5 구현 챕터 전 까지 ✅
- tiny 웹 서버 만들기 ☑️
- 알고리즘 스터디 | 2805 나무 자르기 ✅
🍪 Plan
- tiny 웹서버를 만들고 → 숙제문제 11.6c, 7, 9, 10, 11 중 세문제 이상 풀기 → 프록시 과제 도전
- 퀴즈 봤던거 정리 (기술 면접 준비 +알파 느낌으로)
- CS:APP 읽기 | 6장
📚 Journal
방에서 공부하면 안됨
방에 세팅해놓은 공부 기자재들 다시 수거하는거 귀찮아서 점심 먹고 돌아와서도 방에서 공부를 했는데, 옆에 침대가 있으니 잠깐만 쉬었다 하려던게 그대로 낮잠이 되었다. 일요일이고, 피로가 쌓인 걸 푼 거니까 잠 잔거에 죄책감을 느낄 필요는 없겠지만, 방에서 공부하는 건 어려운 일이라는 걸 새삼 알게되었다. 진짜 애매한 상황 아니면 바로바로 라운지로 가야할듯.
+) 심지어 낮잠 자고 난 후(20:30 경)여서 졸리지도 않은데 순수하게 혼자 있기 때문에 집중이 안되는 것을 느낌. 라운지에서 공부할 땐 혼자여도 누가 올 수도 있다는 긴장감에 집중할 수 있었음.
코드 포매터 오류 고침
저번에도 말했지만, vscode에서 저장하면 지멋대로 코드 포맷을 바꿔버림.
그냥 그런갑다 하고 쓰고 있었는데,
sprintf(body, "%s<body bgcolor="
"ffffff"
">\r\n",
body);이번에는 선을 넘어버림.
코드 포매터와 관련되어 보이는 것들 죄다 지웠다가 vscode 재실행 해봤는데,
아무리 해도 코드 포매터의 저주가 풀리질 않았음.
이 현상 고치려고 했었나 그냥 설치해놓고 disable 시켜놨나 기억은 안 나는데,
일단 이걸 켜봤더니 드디어 고쳐짐.
저장해도 선 넘는 코드 스타일 적용 안 시켜줌.
📝 배운 것들
🏷️ sscanf
주어진 문자열에서 데이터를 읽을 때 sscanf 사용.
scanf는 표준 입력(키보드 등)을 받는다면,
sscanf는 문자열에서 필요한 데이터를 추출한다는게 차이점.
char str[] = "123 456";
int a, b;
sscanf(str, "%d %d", &a, &b);scanf랑 동작 방식은 비슷하다.
문자열 "123 456"을 읽어서, a에 123, b에 456을 저장한다.
🏷️ sprintf
char buffer[50];
int x = 10;
float y = 5.5;
sprintf(buffer, "x = %d, y = %.1f", x, y);데이터를 문자열로 변환해서 버퍼에 저장.
버퍼에 있던 기존 데이터는 무시하고 새로 덮어씌워버린다.
🏷️ strcasecmp
#include <strings.h>
int result = strcasecmp("Hello", "hello"); // result는 0이 됩니다.대소문자 구분 없이 두 문자열이 동일한지 비교함.
이 case에선 둘이 동일하다고 처리함.
엄밀히 말하면 C 표준 라이브러리는 아님.
POSIX 표준이라는 거에 포함돼있음.
대부분의 Unix 계열 시스템(Linux, macOS)에서는 사용 가능.
🏷️ strstr
char *str = "Hello, World!";
char *substr = strstr(str, "World");문자열에서 특정 부분 문자열을 찾아서 그 위치를 반환.
이 예시에서 substr는 "World!"를 가리키는 포인터가 됨.
🏷️ strcpy
char *strcpy(char *dest, const char *src);한 문자열을 다른 문자열에 복사함.
- dest: 복사된 문자열을 저장할 대상 버퍼
- src: 복사할 원본 문자열
dest에 있던 건 사라짐.
🏷️ strcat
char dest[20] = "Hello, ";
char *src = "World!";
strcat(dest, src);두 문자열을 연결함.
dest는 "Hello, World!"가 됨.
🏷️ '\0'의 의미
\0은 C 언어에서 문자열의 끝을 의미함.
아스키 코드로 0임.
널 문자라고 부르는데, NULL이랑 똑같은 건 아님.
🏷️ mmap()과 malloc()의 차이
malloc도 mmap도 메모리를 할당하는 함수임.
malloc은 사실 free를 한다고 해서 그 메모리가 시스템 자원에 귀속되진 않음.
그 메모리는 다음 malloc을 기다리고만 있음.
그래서 큰 메모리를 malloc으로 할당할 땐 mmap가 사용됨.
malloc 풀 내에서 메모리를 잡고 안 놔주면 다른 프로세스가 그거 못 써서 성능 저하 오기 때문.
mmap는 munmap으로 해제하면 바로 운영 체제에 반환됨.
그리고 mmap은 시스템 수준에 더 가까운 함수라서
매개변수들 조절하면 다양하게 조작 가능함 (매개변수 목록)
🌐 Web Server
🔷 Tiny Web Server
원본 repo에 있는 tiny.c에 책에 있는 코드 따라친 뒤 이해한 내용 주석 달기
📌 Annotating : main
/* 소켓 정보 가져오게 하고 할 일 하게하는 main 함수 */
int main(int argc, char **argv)
{
int listenfd, connfd; // 듣기 식별자, 연결 식별자 (서버 소켓과 클라이언트 소켓)
char hostname[MAXLINE], port[MAXLINE]; // 클라 호스트이름, 포트 (혹은 아이피 주소, 서비스 이름)
socklen_t clientlen; // 클라 주소 크기 (sockaddr 구조체 크기)
struct sockaddr_storage clientaddr; // 클라 주소 정보 구조체 (IPv4/IPv6 호환)
/* 인자 맞게 썼는지 확인 */
if (argc != 2)
{
fprintf(stderr, "usage: %s <port>\n", argv[0]);
exit(1);
}
listenfd = Open_listenfd(argv[1]); // 연결 대기 시작
while (1)
{
clientlen = sizeof(clientaddr);
connfd = Accept(listenfd, (SA *)&clientaddr, &clientlen); // line:netp:tiny:accept // 연결 수립
Getnameinfo((SA *)&clientaddr, clientlen, hostname, MAXLINE, port, MAXLINE, 0); // 소켓에서 클라 호스트 이름과 포트 번호 가져오기
printf("Accepted connection from (%s, %s)\n", hostname, port);
doit(connfd); // line:netp:tiny:doit // 연결 수립 후 서버에서 할 일
Close(connfd); // line:netp:tiny:close // 할 일 다 하면 연결 끝
}
}소켓 정보를 가져오게 하고 서버가 클라에 보낼 컨텐츠도 준비하도록 명령하는 함수
📌 Annotating : doit
/* 오류 있는지, 컨텐츠가 정적인지 동적인지 확인하고 읽기/실행 */
void doit(int fd)
{
int is_static;
struct stat sbuf;
char buf[MAXLINE], method[MAXLINE], uri[MAXLINE], version[MAXLINE];
char filename[MAXLINE], cgiargs[MAXLINE];
rio_t rio;
/* 요청 라인과 헤더 읽기 */
rio_readinitb(&rio, fd); // 읽기 함수에 쓰일 변수들 초기화
rio_readlineb(&rio, buf, MAXLINE); // 버퍼에 들어온 것들 읽기
printf("request headers:\n");
printf("%s", buf); // 요청 라인 출력
sscanf(buf, "%s %s %s", method, uri, version); // 버퍼에서 데이터 읽고 method, uri, version에 저장
if (strcasecmp(method, "GET")) // GET 요청인지 확인
{
clienterror(fd, method, "501", "Not Implemented", "Tiny does not implement this method"); // 아니면 꺼지라고 함
return;
}
read_requesthdrs(&rio);
/* URI에서 데이터 추출 */
is_static = parse_uri(uri, filename, cgiargs); // URI에서 데이터 추출
if (stat(filename, &sbuf) < 0) // 파일 읽어서 버퍼에 넣기
{
clienterror(fd, filename, "404", "Not found", "Tiny couldn't find this file"); // 오류 나면 끝내기
return;
}
if (is_static) // 정적 컨텐츠였다면
{
/* 일반 파일인지, 실행 권한이 있는지 확인 */
// S_ISREG : st_mode 값이 일반 파일(regular file)인지 확인하는 매크로
// sbuf에는 파일의 메타데이터가 들어가 있음. 파일의 권한, 파일 유형에 대한 정보를 비트 플래그로 저장함.
// S_IRUSR : 사용자가 파일을 읽을 수 있는 권한을 확인하기 위한 상수
if (!(S_ISREG(sbuf.st_mode)) || !(S_IRUSR & sbuf.st_mode))
{
clienterror(fd, filename, "403", "Forbidden", "Tiny couldn't read the file");
return;
}
serve_static(fd, filename, sbuf.st_size);
}
else // 동적 컨텐츠였다면
{
/* 일반 파일인지, 실행 권한이 있는지 확인 */
if (!(S_ISREG(sbuf.st_mode)) || !(S_IRUSR & sbuf.st_mode))
{
clienterror(fd, filename, "403", "Forbidden", "Tiny couldn't run the CGI program");
return;
}
serve_dynamic(fd, filename, cgiargs);
}
}오류가 있는지 점검하고, 컨텐츠가 정적인지 동적인지 확인한 뒤 읽기/실행하는 함수
📌 Annotating : clienterror
/* 에러 메시지 띄우는 함수 */
void clienterror(int fd, char *cause, char *errnum, char *shortmsg, char *longmsg)
{
char buf[MAXLINE], body[MAXBUF];
/* HTTP 응답 중 body 만들기 */
// body를 다시 추가해서 안 넣어주면 마지막 빼고 다 사라져버림.
// sprintf는 기존에 있던 데이터에 추가되는 방식이 아니라 덮어씌워버리기 때문.
// 응답을 문자열 하나로 만들어서 크기를 쉽게 알 수 있게 함.
sprintf(body, "<html><title>Tiny Error</title>");
sprintf(body, "%s<body bgcolor=""ffffff"">\r\n", body);
sprintf(body, "%s%s: %s\r\n", body, errnum, shortmsg);
sprintf(body, "%s<p>%s: %s\r\n", body, longmsg, cause);
sprintf(body, "%s<hr><em>The Tiny Web server</em>\r\n", body);
/* HTTP 응답 출력 */
// 응답 시작 라인, 응답 헤더 뿌려준 후에 응답 body 보내줌
sprintf(buf, "HTTP/1.0 %s %s\r\n", errnum, shortmsg);
rio_writen(fd, buf, strlen(buf));
sprintf(buf, "Content-type: text/html\r\n");
rio_writen(fd, buf, strlen(buf));
sprintf(buf, "Content-length: %d\r\n\r\n", (int)strlen(body));
rio_writen(fd, buf, strlen(buf));
rio_writen(fd, body, strlen(body));
}에러 메시지 띄우는 함수
📌 Annotating : read_requesthdrs
/* 요청 헤더를 읽는 함수 */
void read_requesthdrs(rio_t *rp)
{
// tiny 서버는 요청 헤더를 실제로 사용하진 않고, 그냥 읽기만 함.
// rp는 클라한테 받은 데이터들 들어있는 버퍼임.
char buf[MAXLINE];
rio_readlineb(rp, buf, MAXLINE); // rp에 있는걸 한 줄 읽어서 buf에 넣음
while(strcmp(buf, "\r\n")) // 버퍼에 빈줄이 나올 때까지 반복
{
rio_readlineb(rp, buf, MAXLINE); // rp를 한 줄 읽어서 buf에 넣음
printf("%s", buf);
}
return;
}요청 헤더를 읽는 함수
📌 Annotating : parse_uri
/* uri에 담긴 정보 추출 */
int parse_uri(char *uri, char *filename, char *cgiargs)
{
char *ptr;
if (!strstr(uri, "cgi-bin")) // 정적 컨텐츠를 요청했다면
{
strcpy(cgiargs, ""); // 초기화
strcpy(filename, "."); // .으로 초기화
strcat(filename, uri); // uri에서 요청하는 디렉토리로 감
if (uri[strlen(uri)-1] == '/') // uri 마지막 문자가 / 이면
strcat(filename, "home.html"); // home.html 꺼낸다
return 1;
}
else // 동적 컨텐츠를 요청했다면
{
ptr = index(uri, '?'); // ? 뒤에는 프로그램 매개변수들이 나옴
if (ptr) // 매개변수가 있으면
{
strcpy(cgiargs, ptr + 1); // cgi 매개변수 담는 곳에 넣어준다
*ptr = '\0'; // 넣어주고 난 후엔 매개변수 정보들 삭제함
}
else // 매개변수가 없으면
strcpy(cgiargs, ""); // 매개변수 없다고 초기화시키기
strcpy(filename, "."); // filename에 . 넣고
strcat(filename, uri); // .uri 만들기
return 0;
}
}uri에 담긴 정보를 추출하는 함수
1. Question : why checking "cgi-bin"?
꼭 그래야 하는 건 아니지만, CGI로 동적 컨텐츠를 처리할 땐 컨텐츠를 cgi-bin에 넣곤 함.
그니까 cgi-bin에 있는 걸 요청하면 동적 컨텐츠라는 뜻임.
책에서도 "가정한다"라는 식으로 말함.
2. Question : why use strcpy, not '='?
char s1[20]="abcdefg";
char *s2="012";이런거 잘만 되는데 왜 책에서는 굳이 strcpy를 쓴 건지 찾아봄.
int main(void) {
char s[4];
s = "abc"; //Fails
strcpy(s, "abc"); //Succeeds
return 0;
}https://stackoverflow.com/questions/6901090/c-why-is-strcpy-necessary
C에서 배열은 다른 배열에 직접 할당이 불가능함.
배열 초기화할 때 다른 배열을 그대로 사용할 수도 없음.
이런 특징은 B 언어와 BCPL 언어에서 물려받았음.
B나 BCPL에선 배열이 물리적인 포인터로 표현됐음.
C에선 배열이 포인터는 아니지만, 해석할 때 포인터로 변환됨.
그래서 C에서도 배열을 복사하는게 불가능함.
char c[] = "abc"처럼 문자열 리터럴로 초기화하거나,
구조체 안에 배열이 들어있어서 구조체 전체를 복사할 때는 예외적으로 가능함.
이런 예외 상황을 제외하면 memcpy같은 메모리 복사 함수 써야 됨.
strcpy는 문자열에 특화된 memcpy의 일종임.
그래서 쓰는거.
예시로 알아보기
int array1[5] = {1, 2, 3, 4, 5}; // 가능배열을 상수로 초기화하는 건 가능함.
int array2[5] = array1; // 불가능배열을 다른 배열로 초기화하는 건 안됨.
int array2[5];
memcpy(array2, array1, sizeof(array1)); // 가능배열을 선언한 뒤 memcpy로 초기화시켜주는 건 됨.
📌 Annotating : serve_static
/* 정적 컨텐츠 전송 */
void serve_static(int fd, char *filename, int filesize)
{
int srcfd; // 파일 식별자 저장
char *srcp, filetype[MAXLINE], buf[MAXBUF];
/* 응답 헤더를 클라에게 보낸다 */
get_filetype(filename, filetype);
sprintf(buf, "HTTP/1.0 200 OK\r\n");
sprintf(buf, "%sServer: Tiny Web Server\r\n", buf);
sprintf(buf, "%sConnection: close\r\n", buf);
sprintf(buf, "%sContent-length: %d\r\n", buf, filesize);
sprintf(buf, "%sContent-type: %s\r\n\r\n", buf, filetype);
rio_writen(fd, buf, strlen(buf)); // 헤더를 클라에게 전송
printf("%s", buf); // 디버깅을 위해 헤더 출력
/* 응답 body를 클라에 보낸다 */
srcfd = open(filename, O_RDONLY, 0); // 파일을 읽기 전용 ('O_RDONLY')로 연다
srcp = mmap(0, filesize, PROT_READ, MAP_PRIVATE, srcfd, 0);
// 파일 내용을 메모리에 매핑, srcp는 매핑된 메모리의 시작 주소
// PROT_READ: 매핑된 메모리 영역을 읽기 전용으로 설정
// MAP_PRIVATE: 메모리의 변경 사항이 파일에 반영되지 않고, 다른 프로세스와 공유되지 않음
close(srcfd); // 파일 식별자 닫기
rio_writen(fd, srcp, filesize); // 클라에게 파일 데이터 전송
munmap(srcp, filesize); // 할당했던 메모리 반환
}정적 컨텐츠를 클라이언트에게 보내는 함수
📌 Annotating : get_filetype
/* 해당 파일의 MIME 타입 반환 */
void get_filetype(char *filename, char *filetype)
{
if (strstr(filename, ".html"))
strcpy(filetype, "text/html");
else if (strstr(filename, ".gif"))
strcpy(filetype, "image/gif");
else if (strstr(filename, ".png"))
strcpy(filename, ".image/png");
else if (strstr(filename, ".jpg"))
strcpy(filetype, "image/jpeg");
else
strcpy(filetype, "text/plain");
}📌 Annotating : serve_dynamic
/* 동적 컨텐츠 전송 */
void serve_dynamic(int fd, char *filename, char *cgiargs)
{
char buf[MAXLINE], *emptylist[] = {NULL};
/* HTTP 응답의 첫 부분 클라에 전송 */
sprintf(buf, "HTTP/1.0 200 OK\r\n");
rio_writen(fd, buf, strlen(buf));
sprintf(buf, "Server: Tiny Web Server\r\n");
rio_writen(fd, buf, strlen(buf));
if (fork() == 0) // 자식 프로세스라면 0을 반환함
{
setenv("QUERY_STRING", cgiargs, 1); // URL에서 전송된 쿼리 문자열을 QUERY_STRING에 설정
dup2(fd, STDOUT_FILENO); // 자식이 출력하는거 전부 클라로 감 (클라 소켓 식별자를 표준 출력에 복사)
execve(filename, emptylist, environ); // CGI 프로그램 실행
}
wait(NULL); // 자식이 꺼질 때 까지 부모가 기다려줌
}동적 컨텐츠를 클라이언트에게 보내는 함수
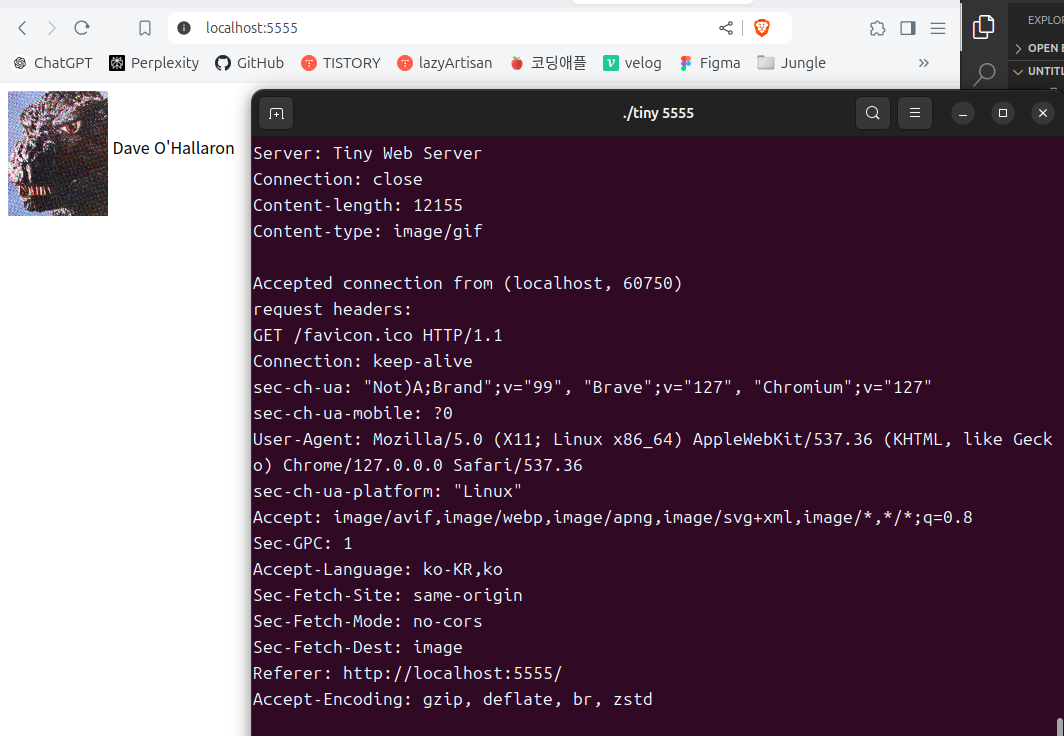
📌 Execution : Tiny Web Server
📖 CS:APP
📝 11.5 웹 서버
11.5.1 웹 기초
웹 클라리언트와 웹 서버는 HTTP(Hypertext Transfer Protocol)라는 프로토콜로 통신한다.
웹 클라(브라우저)가 서버에 연결하고 컨텐츠를 요청하면
서버는 컨텐츠를 주고 연결을 닫는다.
웹 서비스는 HTML(Hypertext Markup Language)로 작성된다.
11.5.2 웹 컨텐츠
웹 클라랑 서버에게, 웹 컨텐츠는 MIME(Multipurpose Internet Mail Extensions) 타입을 갖는 바이트 배열이다.
간단히 말해서 MIME은 컨텐츠 형식이다. HTTP 헤더에 담겨서 이게 무슨 종류의 컨텐츠인지 알려준다.
웹 서버가 클라한테 디스크에 담긴 파일 그대로 주면 정적 컨텐츠,
실행파일 돌리고 클라한테 보내면 동적 컨텐츠라고 한다.
웹 서버가 반환하는 모든 내용은 서버가 관리하는 파일과 연관된다.
이 파일들은 URL(Universal Resource Locator)라는 고유한 이름을 가진다.
URL 해석
http://www.google.com:80/index.htmlURL을 해석해보면,
- 포트 80에서 웹 서버가 듣고 있다
- 인터넷 호스트는 www.google.com이다
- index.html이라는 파일을 지정한다
http://bluefish.ics.cs.cmu.edu:8000/cgi-bin/adder?15000&213이 링크는 /cgi-bin/adder라는 실행파일을 두 개의 인자와 함께 호출한다.
? 문자는 파일 이름과 인자를 구분하고,
&는 각 인자를 구분할 수 있다.
서버의 URL 접미어 해석
- 서버가 URL의 컨텐츠가 정적인지 동적인지 결정하는 표준 규칙은 없다. 각자 정하는거.
- 접미어 앞 부분의
/는 루트 디렉토리 아니다. 홈 디렉토리다. - 최소한의 URL은
/이다. 기본으로/index.html같은 곳으로 연결해주곤 함. 빼먹어도 알아서/붙여줌.
11.5.3 HTTP 트랜잭션
HTTP 트랜잭션은 클라와 서버 간의 텍스트 기반 상호 작용이다.
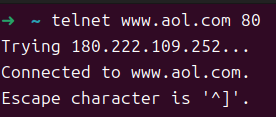
리눅스 telnet으로 인터넷 상의 모든 웹 서버랑 트랜잭션 해볼 수 있음.
연결하고 나서 텍스트 입력하면 carraige return이랑 feed 문자 (C로는 \r\n) 추가한 다음 서버로 보냄.
HTTP 요청
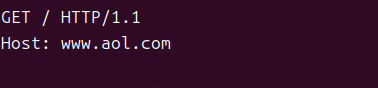
요청은 요청 라인과 요청 헤더로 이루어지고, 빈 줄 하나로 끝남.
method URI version이게 HTTP 요청 라인.
- method : GET, POST ...
- URI : URL에 파일 이름 + 인자 포함한 거
- version : 요청의 HTTP 버전 (최신은 1.1)
header-name: header-data이게 요청 헤더.
브라우저 이름이나 브라우적가 이해하는 MIMT 타입 같은 추가적인 정보 제공함.
일단 Host 헤더만 넣어도 됨.
Host 헤더는 HTTP/1.1 요청에서 쓰는 헤더임.
이 헤더는 프록시 캐시에서 사용되며, 브라우저와 서버 사이의 중간자 역할이 되기도 함.
HTTP 응답
응답도 비슷함. 응답 라인, 요청 헤더, 빈 줄, 응답 본체 이렇게 이루어짐.
version status-code status-message이게 응답 라인.
- version : 응답의 HTTP 버전
- status-code : 요청 특성 (3비트 양수)
- status-message : 에러 코드
응답 헤더는 응답에 대한 추가적인 정보 제공함. 예를 들어,
Content-Type은 컨텐츠의 MIME Type을 알려줌.
Content-Length는 컨텐츠 크기를 바이트로 알려줌.
11.5.4 동적 컨텐츠의 처리
서버가 동적 콘텐츠를 클라한테 제공할 때 CGI(Common Gateway Interface) 표준이라는 걸 쓸 수 있음.
CGI가 뭐냐면
- 클라가 서버로 프로그램의 인자를 전달하고,
- 서버가 인자를 받아서 자식 프로세스로 전달하고,
- 자식 프로세스가 생성한 출력을 클라에 보내는
방식에 대한 규칙임.
동적 컨텐츠 처리 과정
먼저 클라가 서버에 URI를 보냄.
GET /cgi-bin/adder?15000&213 HTTP/1.1이런 링크가 서버에 도착하면
fork 호출해서 cgi-bin에 있는 adder 프로그램 실행함.
adder는 CGI 환경변수에서 인자 가져옴.
동적 컨텐츠 만들어지면 CGI가 표준 출력 형태로 클라에 보냄.
(보내기 전에 출력을 클라 식별자에 연결해야됨)
프로세스는 Content-type과 Content-length 응답 헤더랑 헤더 종료하는 빈 줄까지 만들어야됨. 안 그러면 클라는 자기가 받은게 뭔지 모름.
⚔️ 백준
📌 2805 나무 자르기
import sys
input = sys.stdin.readline
N, M = map(int, input().split())
arr = list(map(int, input().split()))
pl, pr = 0, max(arr)
while(pl <= pr):
res=0
p = (pl+pr)//2
for h in arr:
if h-p > 0:
res+=(h-p)
if M > res:
pr = p-1
elif M < res:
pl = p+1
else:
break
if M > res:
print(p-1)
else:
print(p)
# 실수 1. 0이 아니라 min으로 잡음
# 실수 2. 자르는 높이가 높을수록 양이 많아질거라고 생각함
# 실수 3. '최소한' M 은 잘라가야 하는데 결과 중에 부족한 경우 생김저번에 한 번 풀어봤던 문제니까 빨리 풀고 서버나 만들러 가야지~ 생각했는데
뜻밖에 1시간 가까이 걸려버렸다.
너무 오만하게 문제 대충 읽고 생각도 안 하고 이분 탐색 조지면 알아서 풀릴 거라고 생각한게 패착이었음.
시험장에서 비슷한 문제 만났는데 이딴 식으로 시간 날리면 멘탈 붕괴할듯.
실수 1.
일단 시작 위치를 0이 아니라 나무 높이의 최솟값으로 잡은게 문제였음.
문제가 뭘 원하는지 생각조차 안 했다는게 드러남.
실수 2.
게다가 자르는 높이가 높을수록 양이 많아질거라고 생각해버림.
부등호 바꿨더니 예제는 잘 풀리긴 했는데 왜 결과가 그렇게 나오는지를 몰라서 헤맴.
왜 높으면 높다는 고정관념에 사로잡힌 건지 모르겠음.
실수 3.
'최소한' M을 잘라가야 하는데 그것보다 덜 잘라가는 경우를 반환했었음.
다른 사람 풀이 보니까 (심지어 내 예전 풀이도!) p를 바꿔주는 위치를 뒤쪽으로 보내서 풀었음.
import sys
input = sys.stdin.readline
N, M = map(int, input().split())
arr = list(map(int, input().split()))
pl, pr = 0, max(arr)
p = (pl+pr)//2
while(pl <= pr):
res=0
for h in arr:
if h-p > 0:
res+=(h-p)
if M > res:
pr = p-1
elif M < res:
pl = p+1
else:
break
p = (pl+pr)//2
print(p)(이런 느낌으로 수정이 가능하다. 더 깔끔.)
pl이랑 pr이 바뀌면 p의 위치도 바뀌어야 하는데, 그걸 놓쳤음.
나는 꾸역꾸역 정답 내긴 했는데, 미리 초기화 한 번 하고 p 갱신하는 곳은 뒤로 보내는게 깔끔한듯.
혹시 pl이나 pr의 위치로 답을 제출해도 되는지 확인해봤는데, 안됐음.
일단 맨 처음에 답을 찾아버리면 갱신이 안돼서 따로 조건 추가해야되는 것도 귀찮고,
마지막 결과에 따라 pl이랑 pr이 일관적으로 고정돼있지 않는게 불편함.
아마 또 조건문을 달아줘야 할 거임. 구현까지는 귀찮.
그냥 아직 이분 탐색을 마스터하지 못해서 그런 것 같음.
반 나누고 절반 간다는 개념은 완벽하게 아는데,
마지막 구간에서 pl과 pr이 어떻게 움직이는지를 머릿속에서 시각화를 못함.
오늘 아침에 누워서 아 이렇게 되는거구나 생각은 했었는데
막상 문제 풀려니까 머리에서 그리지를 못함.
