📝 배운 것들
🏷️ User mode vs. Kernel mode
-
유저 모드:
- 유저 모드에서 실행되는 프로그램은 하드웨어나 시스템의 중요한 리소스에 직접 접근할 수 없으며, 운영체제의 보호 아래에서 동작함. 응용 프로그램이 파일을 읽거나 네트워크에 접속하는 등의 작업을 하려면 시스템 콜(System Call)을 통해 요청.
- 유저 모드의 가장 큰 장점은, 응용 프로그램이 망가져도 시스템 전체에 영향을 미치지 않고 해당 프로그램만 종료된다는 점임.
-
커널 모드:
- 커널 모드는 시스템 리소스(메모리, CPU, 하드웨어) 접근 권한을 가짐. 커널 모드에서 운영체제는 메모리 관리, 하드웨어 제어, 프로세스 관리 등의 중요한 작업을 수행함.
- 커널 모드에서 발생하는 오류는 전체 시스템에 심각한 영향을 줄 수 있기 때문에 매우 신중하게 관리해야 함.
유저 모드는 시스템 자원 권한 없고
커널 모드는 있다
나누면 안전하니까
🏷️ User stack vs. Kernel stack
유저 스택 (User Stack):
- 위치: 유저 모드에서만 사용됨. 프로세스가 유저 모드에서 실행될 때 데이터를 저장하는 데 사용됩니다.
- 특징
- 주로 함수 호출 시 함수의 매개변수, 리턴 주소, 지역 변수를 저장
- 유저 프로세스가 실행되는 동안 동적으로 크기를 변경할 수 있으며, 사용자가 직접 접근하고 관리할 수 있음
- 크기: 유저 스택은 상대적으로 큰 공간을 차지할 수 있으며, 시스템 설정에 따라 크기를 조절할 수 있음. 일반적으로 유저 스택의 크기는 제한 없이 확장할 수 있음.
커널 스택 (Kernel Stack):
- 위치: 커널 모드에서 사용되는 스택으로, 유저 스택과는 별도의 메모리 공간에 존재. 유저 프로세스가 커널 모드로 전환될 때(예: 시스템 콜을 할 때) 커널 스택을 사용.
- 특징
- 고정된 크기를 가짐.
- 일반적으로 각 프로세스 또는 스레드마다 하나씩 할당됨
- 커널이 함수 호출, 로컬 변수 저장 등을 처리할 때 사용됨
- 유저 모드에서 접근할 수 없으며, 보안을 위해 분리되어 있음
- 크기: 일반적으로 4KB ~ 16KB로 매우 작음. 크기는 시스템 아키텍처에 따라 고정됨.
🏷️ Kernel mode로 전환되는 상황
-
시스템 콜(System Call)
유저 모드에서 실행 중인 프로그램이 운영체제의 기능을 필요로 할 때, 시스템 콜을 통해 커널 모드로 전환됨. (ex. 파일 읽기, 쓰기, 네트워크 통신, 프로세스 제어 등)
-
인터럽트(Interrupts)
- 하드웨어 인터럽트: 하드웨어 장치(ex. 키보드, 마우스, 네트워크 카드 등)에서 인터럽트가 발생하면 CPU가 현재 작업을 일시 중단하고 커널 모드로 전환하여 인터럽트를 처리함
- 소프트웨어 인터럽트(트랩): 프로그램이 실행 중 오류(ex. 0으로 나누는 연산, 메모리 접근 오류)를 일으킬 때, 소프트웨어 인터럽트가 발생하여 커널 모드로 전환.
-
페이지 폴트(Page Fault)
프로그램이 현재 메모리에 없는 데이터를 접근하려 할 때 발생. 메모리에서 요청한 데이터가 없을 경우, 운영체제는 하드 디스크에서 데이터를 가져와 메모리에 로드해야 하며, 이 과정에서 커널 모드로 전환됨.
-
예외(Exception) 처리
CPU는 잘못된 명령어나 예외가 발생할 경우, 이를 처리하기 위해 커널 모드로 전환됨.
-
컨텍스트 스위칭(Context Switching)
운영체제가 여러 프로세스를 스케줄링하기 위해 현재 실행 중인 프로세스를 다른 프로세스로 전환할 때 커널 모드로 진입. 컨텍스트 스위칭은 프로세스의 실행 상태를 저장하고 새로운 프로세스의 상태를 복원하는 과정이 필요하기 때문.
🏷️ Trap, Exception
-
Trap
- 정의: 주로 소프트웨어에 의해 발생하는 동기적 이벤트. 이는 프로그램이 실행 중 오류(ex. 0으로 나누기, 잘못된 메모리 접근)가 발생했을 때 실행됨. 트랩이 실행되면, CPU는 커널 모드로 전환되어 트랩 핸들러라는 특정 코드를 실행함.
- 용도: 오류 처리뿐만 아니라 시스템 콜을 통해 프로세스가 운영체제에 특정 작업(ex. 파일 읽기, 메모리 할당)을 요청할 때도 사용됨.
- 특징: 트랩은 명령어 실행 중 발생하며, 해당 명령어를 완료한 후 다음 명령어로 제어를 넘김.
-
Exception
Exception은 trap을 포함하는 더 넓은 개념. 동기적으로 발생하며, 주로 소프트웨어의 실행 중에 발생하는 예상치 못한 사건.
- 종류
- 트랩: 정상적으로 명령을 완료한 후 발생. 주로 시스템 콜 처리나 디버깅 시 사용됨.
- 폴트(Fault): 명령어 실행 중에 발생. 문제가 해결되면 명령어가 다시 시도될 수 있음.
- 어보트(Abort): 심각한 오류로 인해 프로그램을 재시작하거나 복구할 수 없는 상황.
- 종류
🏷️ 동기적 발생, 비동기적 발생
동기적 발생은 프로그램이 0으로 나누기를 시도할 때, 해당 명령어를 실행하는 순간 즉시 트랩(예외)이 발생하여 CPU가 그 문제를 처리합니다. 즉, 명령어와 예외 발생이 직접적인 관계를 맺고 있습니다.
반면, 비동기적(asynchronous) 이벤트는 프로그램의 실행 흐름과 관계없이 발생하는 경우를 의미합니다. 예를 들어, 하드웨어 인터럽트는 CPU가 다른 작업을 하고 있을 때도 외부 장치(예: 키보드 입력)로 인해 언제든지 발생할 수 있습니다.
https://therefrom.tistory.com/44
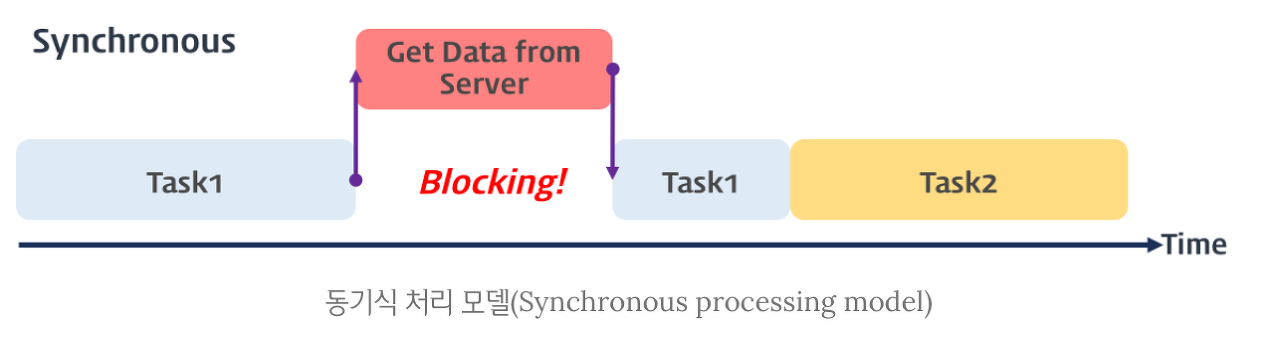
동기적인 방식은 요청과 결과가 순차적으로 일어남.
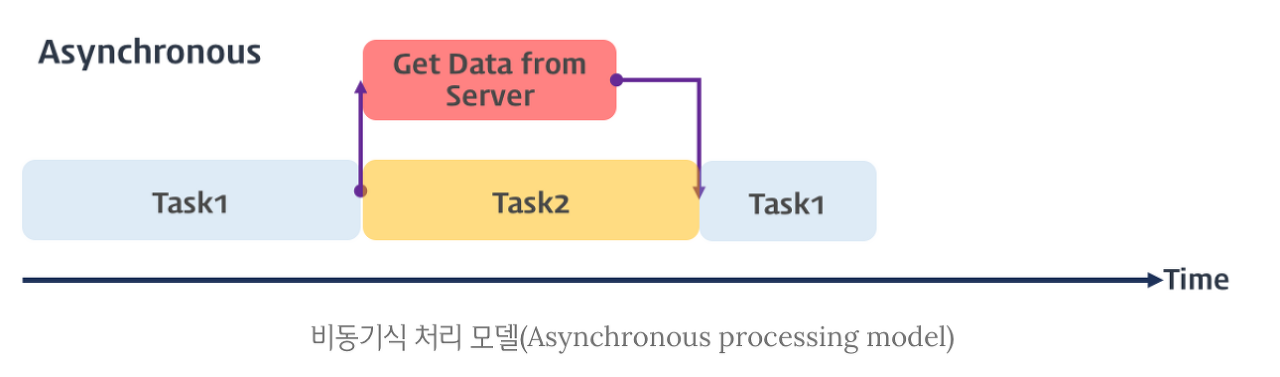
현재 작업 여부와 무관하게 다음 작업을 실행하고, 완료함.
🏷️ 인터럽트 (Interrupt)
인터럽트(Interrupt)는 하드웨어 또는 소프트웨어가 CPU에 즉각적인 주의를 요구하는 신호로, 현재 실행 중인 작업을 일시 중단하고 더 긴급한 작업을 처리하도록 하는 메커니즘입니다. 이 방식은 컴퓨터가 여러 작업을 동시에 처리할 수 있도록 돕는 중요한 역할을 합니다.
인터럽트의 종류
- 하드웨어 인터럽트: 하드웨어 장치(예: 키보드, 마우스, 네트워크 카드 등)가 발생시키는 인터럽트. 장치가 CPU의 주의를 끌어야 할 때 발생.
- 소프트웨어 인터럽트: 소프트웨어가 특정 작업을 요청할 때 발생하는 인터럽트. 주로 시스템 콜을 통해 운영체제에 특정 작업을 요청하거나, 잘못된 명령어 실행 등으로 인해 발생.
마스크 가능 인터럽트, 마스크 불가능 인터럽트
- 마스크 가능 인터럽트: CPU가 처리할 수 있는 다른 중요한 작업을 위해 일시적으로 무시할 수 있는 인터럽트.
- 마스크 불가능 인터럽트: CPU가 무시할 수 없는 중요한 인터럽트. 시스템 오류나 하드웨어 고장 같은 경우에 발생하며, 즉시 처리해야 함. (핀토스에선 안 다룬다고 함)
인터럽트 처리 과정
- 인터럽트 발생: 장치나 소프트웨어가 CPU에 인터럽트를 발생시킴.
- 현재 상태 저장: CPU는 현재 실행 중인 작업을 중단하고, 작업의 상태(레지스터 값, 프로그램 카운터 등)를 저장.
- 인터럽트 서비스 루틴(ISR) 실행: 각 인터럽트는 ISR(Interrupt Service Routine)이라는 특별한 처리 코드를 실행. ISR은 인터럽트의 원인을 분석하고, 그에 맞는 작업을 수행한 후 CPU의 제어권을 반환.
- 작업 복귀: ISR이 완료되면, CPU는 저장해둔 상태로 돌아가 중단된 작업을 다시 실행.
인터럽트와 폴링(Polling)의 차이
- 폴링은 CPU가 주기적으로 장치의 상태를 확인하는 방식. 반면, 인터럽트는 장치가 필요할 때 CPU에게 직접 신호를 보내는 방식. 폴링은 시스템 자원을 더 많이 소비하지만, 인터럽트는 CPU가 다른 작업을 할 수 있도록 하면서 필요한 경우에만 중단되기 때문에 더 효율적.
🏷️ Segmentation Fault
세그멘테이션 폴트(Segmentation Fault)는 프로그램이 접근 권한이 없는 메모리 주소를 읽거나 쓸 때 발생하는 오류입니다. 이 오류는 주로 시스템이 메모리 보호 기능을 통해 잘못된 메모리 접근을 감지하고, 이를 방지하기 위해 프로세스를 강제 종료할 때 발생합니다.
세그멘테이션 폴트가 발생하는 주요 원인
- 널 포인터 역참조: 널 포인터는 초기화되지 않은 포인터로, 메모리 상의 주소를 가리키지 않기 때문에 이를 접근하려 할 때 세그멘테이션 폴트가 발생합니다.
- 초기화되지 않은 포인터 사용: 초기화되지 않은 포인터(와일드 포인터)는 메모리 내 무작위 주소를 가리킬 수 있으며, 이로 인해 접근 권한이 없는 메모리 영역을 침범할 수 있습니다.
- 해제된 포인터 사용(댕글링 포인터): 동적 메모리 할당 후 이를 해제한 후에도 해당 메모리 주소에 접근하려 하면 문제가 발생할 수 있습니다. 메모리는 이미 반환되었으므로 해당 주소에 더 이상 접근할 수 없습니다.
- 읽기 전용 메모리 쓰기 시도: 읽기 전용으로 설정된 메모리 영역에 쓰기 작업을 시도하면 오류가 발생합니다. 예를 들어, 상수 문자열에 쓰기 작업을 시도하는 경우가 이에 해당합니다.
- 배열 범위 초과: 배열의 경계를 넘어서는 메모리에 접근하려 할 때도 세그멘테이션 폴트가 발생합니다. 예를 들어, 1000개의 요소를 가진 배열에서 1001번째 요소에 접근하려는 시도는 메모리 침범을 유발합니다.
운영체제의 역할
세그멘테이션 폴트가 발생하면, 하드웨어는 잘못된 메모리 접근을 감지하고 운영체제에 이를 알립니다. 운영체제는 이 신호를 받아서 해당 프로그램을 종료하고, 추가적인 시스템 손상을 방지합니다. 이때 코어 덤프(Core Dump)라는 파일이 생성될 수 있는데, 이 파일은 프로그램의 메모리 상태를 저장하여 개발자가 오류를 분석하는 데 도움을 줍니다.
세그멘테이션 폴트를 예방하는 방법
- 포인터 초기화: 포인터를 사용할 때 항상 유효한 메모리 주소를 할당받도록 해야 하며, 초기화되지 않은 포인터를 사용하지 않도록 주의해야 합니다.
- 메모리 할당 및 해제 관리: 동적 메모리를 할당한 후, 이를 적절히 해제해야 하며, 해제된 메모리를 다시 참조하는 오류를 방지해야 합니다.
- 배열 경계 검사: 배열을 사용할 때 경계를 초과하지 않도록 주의하며, 특히 반복문에서 배열 인덱스를 사용할 때 경계 조건을 철저히 확인해야 합니다.
- 안전한 함수 사용: 메모리를 다루는 함수(
malloc,free,scanf등)를 사용할 때 정확한 방식으로 호출해야 하며, 입력 검증을 통해 잘못된 메모리 접근을 방지해야 합니다.
이름의 유래
근데 왜 segmentation fault라는 이름이 붙었어? access fault가 더 어울리는 이름 같은데. 분할 폴트는 뭔가 이상하잖아
"Segmentation Fault"라는 이름은 메모리 관리 방식 중 하나인 세그멘테이션(Segmentation)에서 유래한 용어입니다. 이 개념을 이해하려면 먼저 메모리 구조와 운영체제가 메모리를 어떻게 관리하는지 살펴볼 필요가 있습니다.
세그멘테이션이란?
세그멘테이션은 프로그램이 사용하는 메모리를 여러 세그먼트(segment)로 나누어 관리하는 방식입니다. 일반적으로 메모리는 여러 개의 구역으로 나뉘어 있으며, 각 구역은 특정 용도로 사용됩니다. 주요 세그먼트는 다음과 같습니다:
- 텍스트 세그먼트: 프로그램의 실행 코드를 저장하는 영역입니다.
- 데이터 세그먼트: 전역 변수와 정적 변수를 저장하는 영역입니다.
- 스택 세그먼트: 함수 호출 시 지역 변수와 함수 호출 기록을 저장하는 영역입니다.
- 힙 세그먼트: 동적 메모리 할당(
malloc등)으로 사용되는 영역입니다.
왜 Segmentation Fault라고 부르나?
"Segmentation Fault"라는 이름은 프로그램이 자신이 할당받지 않은 세그먼트 또는 세그먼트 외부의 메모리를 잘못 참조했을 때 발생하는 오류에서 비롯되었습니다. 즉, 메모리 세그먼트 간의 경계를 침범하여 잘못된 주소에 접근하려고 할 때, 하드웨어와 운영체제가 이를 감지하고 프로그램의 접근을 차단하는 것입니다.
예를 들어:
- 프로그램이 스택 세그먼트의 한계를 넘어서 메모리에 접근하려 시도하거나,
- 힙 세그먼트에서 할당되지 않은 메모리에 접근하려 하면,
이러한 접근이 허용되지 않아 세그멘테이션 폴트가 발생합니다.
🏷️ Register vs. Memory
레지스터랑 메모리는 둘 다 기본적으론 데이터 저장하는 거.
-
레지스터(Register):
- 위치: CPU 내부
- 속도: 개빠름. CPU가 직접 접근. 보통 한 클록 사이클 내에 데이터를 처리.
- 크기: 개작음. 운영체제에 따라 32비트 또는 64비트의 데이터를 처리.
- 역할: 현재 CPU가 처리 중인 명령어와 데이터를 저장
-
메모리(Memory):
- 위치: CPU 외부. 주로 RAM(주기억장치)을 의미.
- 속도: 레지스터에 비해 훨씬 느림. CPU는 메모리에 직접 접근하지 않고, 메모리 버스를 통해 데이터를 가져옴.
- 크기: GB ~ TB 단위
- 역할: 실행 중인 프로그램의 데이터를 저장
🏷️ 레지스터 (Register)
https://plummmm.tistory.com/113
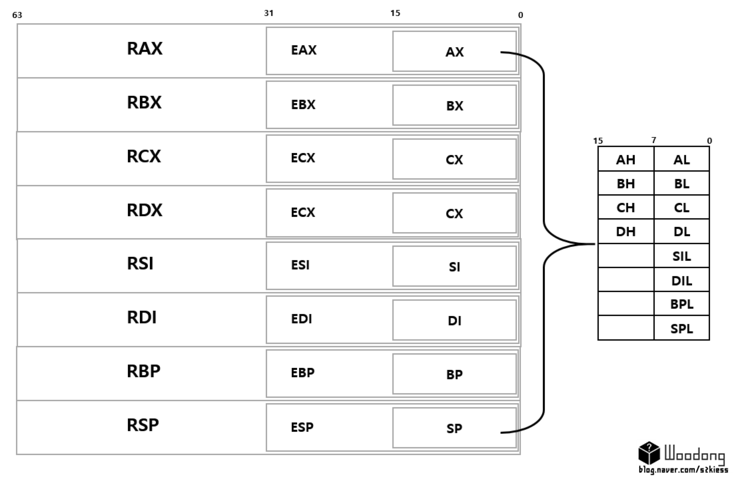
-
산술 연산 레지스터
AX : 산술 논리 연산에 사용된다. 그리고 함수의 리턴값이 여기 저장됨.
BX : 간접 번지 지정 시에 사용된다. 뭔말?? 배열의 인덱스 값을 저장하는거지.
CX : 반복문의 반복 횟수 지정 시에 사용된다. (counter) 그리고 문자열 처리에도 사용됨.
DX : AX의 보조적인 역할이다. AX와 합쳐져서 확장된 메모리로 사용하는 것. 그리고 I/O 어드레스를 지정할 때 사용됨. -
인덱스 레지스터
SI(Source index) : 복사나 비교를 할때 사용되는 소스 문자
DI(Destination index) : 역시나 복사나 비교를 할때 사용되는 목적지 문자. stos, movs를 사용할때 마다 1씩 증가한다.
- 포인터 레지스터
SP(Stack Pointer) : 스택의 가장 윗부분을 가르킨다. 스택에 값이 쌓이면 ESP도 증가한다.
BP(Base Pointer) : 스택의 제일 바닥 부분의 주소를 가르킨다. EBP밑에는 Return값이 있음.
위와 같은 용도로 쓰인다.
보면 접두사가 R 이 붙었는데.. 64비트일 때 R 접두사가 붙고 32비트 일때는 E 접두사가 붙는다.
리얼 모드 즉 16비트 모드에서는 접두사가 붙지 않는 레지스터를 사용한다고 생각하면 되고,
보호모드도 마찬가지로 E 접두사가 붙는 레지스터를 사용한다고 생각해면 무방하다.
🏷️ rax register
RAX 레지스터의 발전
- 8비트 아키텍처에서는 A라는 이름으로 불리던 "축적기(Accumulator)" 역할.
- 이후 16비트 아키텍처에서는 AX로 확장되었고, 이를 두 부분(AL과 AH)으로 나눠 사용할 수 있었음.
- 32비트 아키텍처에서는 EAX로 불리며 더 많은 데이터를 처리할 수 있었고, 64비트 환경으로 발전하면서 RAX가 됨.
RAX의 역할
- 리턴 값 저장: 함수가 완료되면 결과 값이 RAX에 저장됨.
- 시스템 콜: RAX는 시스템 콜에서 중요한 역할을 하며, 커널과의 상호작용을 위한 시스템 호출 번호를 담음. 이를 통해 프로세스는 운영체제에 특정한 작업을 요청할 수 있음.
- 연산 수행: RAX는 여러 산술 연산에서 피연산자나 결과를 저장하는 데 사용됨. 또한 이 레지스터는 곱셈, 나눗셈과 같은 명령에서 중요한 역할을 함.
하위 레지스터
RAX는 하위 버전인 EAX(32비트), AX(16비트), AL(8비트)로 나눠 사용할 수 있다. 예를 들어, 64비트 RAX의 하위 32비트에 접근할 때는 EAX를 사용하며, 하위 8비트를 참조할 때는 AL을 사용할 수 있다. 이러한 하위 레지스터는 하위 호환성을 유지하면서 특정 데이터 부분만 접근하거나 수정할 때 유용하다.
🏷️ 시스템 콜
프로그램은 시스템 콜을 통해 운영체제에서 제공하는 서비스를 요청할 수 있다.
프로그램이 시스템 자원 직접 못 건드리게 해서 보안과 안정성 유지.
시스템 콜의 동작 방식
- 유저 모드에서 커널 모드로 전환: 유저 모드에서 실행 중인 프로그램이 시스템 자원(예: 파일, 네트워크, 하드웨어)에 접근해야 할 때 시스템 콜을 통해 커널에 요청을 보냄. 이때 CPU는 유저 모드에서 커널 모드로 전환됨.
- 커널의 작업 처리: 커널은 해당 요청을 처리한 후, 요청한 프로그램에 결과를 반환함. 이 작업이 끝나면 다시 유저 모드로 돌아감.
시스템 콜의 주요 예
- 프로세스 제어:
fork(),exec(),wait()와 같은 함수로 프로세스를 생성, 실행, 대기하는 작업을 수행. - 파일 관리:
open(),read(),write(),close()와 같은 함수로 파일을 열고, 데이터를 읽고 쓰며, 파일을 닫음. - 디바이스 관리: 하드웨어 장치와 상호작용하기 위해
ioctl()같은 시스템 콜이 사용됨. - 통신: 네트워크 연결을 관리하거나 메시지를 주고받는 데 사용되는 시스템 콜도 있음.
🏷️ 파일 디스크립터
파일 디스크립터는 파일을 읽거나 쓰기 위해 read(), write()와 같은 시스템 콜을 통해 사용됨
운영 체제는 프로세스가 파일을 열 때마다 식별자를 하나 만들고,
무슨 파일을 가리키고 있는지 등의 정보와 함께 테이블에 기록한다.
각 프로세스들도 파일을 열면 식별자를 만들고 자신의 파일 식별자 테이블에 기록한다.
기본적으로 파일 식별자 테이블의 0,1,2는 이미 할당되어 있다.
각각 표준 입력, 표준 출력, 표준 오류이다.
실제로 함수에서 사용하고 싶을 땐
기호 상수 STDIN_FILENO, STDOUT_FILENO, STDERR_FILENO을 사용하는 것이 가독성을 위해 좋다.
🏷️ 캐시 (Cache)
자주 사용되는 데이터를 빠르게 접근할 수 있도록 임시로 저장하는 메모리. 데이터 접근 속도를 향상시키기 위해 사용. CPU나 웹 브라우저와 같은 여러 컴퓨팅 시스템 요소가 캐시를 사용하여 성능을 극대화.
캐시는 작고 빠른 메모리로, 메인 메모리(RAM)나 저장 장치보다 훨씬 더 빠르게 데이터를 읽고 쓸 수 있음. 프로그램이 데이터를 요청할 때, 먼저 캐시에 데이터가 있는지 확인함.
만약 데이터가 캐시에 존재한다면(캐시 히트), 바로 데이터를 반환.
캐시에 데이터가 없을 경우(캐시 미스), 더 느린 메모리나 저장 장치에서 데이터를 가져와 캐시에 저장한 후 데이터를 반환.
🏷️ 원자적 연산 (Atomic operation)
원자적 연산(Atomic Operation)은 실행되는 동안 다른 작업에 의해 방해받지 않는 연산. 다중 스레드 환경에서 데이터 일관성이 보장됨. 예를 들어, 여러 스레드가 동시에 변수에 접근하여 값을 변경할 때, 원자적 연산을 사용하면 다른 스레드가 그 변수를 사용하는 도중에 값이 변경되지 않도록 보호됨.
대부분의 현대 하드웨어와 프로세서, 운영체제는 이러한 원자적 연산을 위한 특별한 명령어(예: compare-and-swap, fetch-and-add)를 지원.
주로 하드웨어 기반으로 구현해서 단일 명령어가 완료될 때까지 다른 스레드나 프로세스가 해당 메모리 영역에 접근하지 못하게 함.
🏷️ 32bit OS vs. 64bit OS
https://www.geeksforgeeks.org/32-bit-vs-64-bit-operating-systems/
In computing, there are two types of processors existing, i.e., 32-bit and 64-bit processors. These types of processors tell us how much memory a processor can access from a CPU register. For instance,
A 32-bit system can access 232 different memory addresses, i.e. 4 GB of RAM or physical memory ideally, it can access more than 4 GB of RAM also.
A 64-bit system can access 264 different memory addresses, i.e. actually 18-quintillion bytes of RAM. In short, any amount of memory greater than 4 GB can be easily handled by it.
🏷️ 프로세스 (Process)
프로세스는 운영체제에서 실행 중인 프로그램의 인스턴스임.
프로세스는 CPU에서 실행되기 위해 필요한 데이터와 코드를 포함하는 여러 자원(예: 메모리, 파일 핸들, 실행 중인 코드 등)을 가지고 있으며, 각각 독립된 주소 공간을 할당받음.
운영체제는 각 프로세스를 관리하기 위해 프로세스 제어 블록(PCB)이라는 구조체를 유지하며, 여기에는 프로세스의 상태, 메모리 관리 정보, CPU 사용 시간 등의 정보가 저장됨.
⚔️ 백준
📌 1005 ACM Craft
from collections import deque
T = int(input())
for _ in range(T):
N, K = map(int,input().split())
time = 0
time_table = list(map(int,input().split()))
prev_table = [[] for _ in range(N+1)] # 짓기 전에 지어야 할 건물
next_table = [[] for _ in range(N+1)] # 지은 후에 지어야 할 건물
for _ in range(K):
a, b = map(int,input().split())
prev_table[b].append(a)
next_table[a].append(b)
win = int(input())
cnt = 0
q = deque()
q.append(win)
while q:
b = q.popleft()
for other_b in q:
time_table[other_b] -= time_table[b-1]
cnt += time_table[b-1]
time_table[b-1] = 0
# 최소 건설 시간을 갖고 있는 놈들만 빼내오도록
if b == win:
break
for next_b in next_table[b]: # 다음 건물 탐색
can_build = True
for prev_b in prev_table[next_b]:
if time_table[prev_b] != 0:
can_build = False
break
if can_build:
q.append(next_b)
print(time)
# 건설 시간 제일 큰 놈이 있으면 그 친구 끝날때까지 다른 쪽에선 쭉쭉 진행 가능
# 큐에서 건설 시간 제일 작은 놈 꺼내서 큐에 있는 건물들 전부 해당 건물 시간만큼 뺀 다음에 (cnt도 더해줌)
# 큐에 다음으로 연결된 건물을 넣는데, 이전 건물 테이블을 순회하며 타임 테이블이 전부 0인지 확인
# 0이 아니면 못 넣음
# 만약 최종 건물 만들었으면 끝최소 건설 시간 작은 놈을 꺼내는 것의 연산 비용이 너무 높아보이고,
거꾸로 시작하는게 아니라 정방향으로 시작하면
처음 시작 건물이 여러개일 가능성 있음
더 생각해봐야할듯. 일단 핀토스 할 것.
📌 10026 적록색약
N=int(input())
L = [list(input()) for _ in range(N)] # 이거 받는 법 또 까먹었었음
L2 = [[0]*N for _ in range(N)]
for i in range(N):
for j in range(N):
if L[i][j] == 'R' or L[i][j] == 'G':
L2[i][j] = 'R'
else:
L2[i][j] = 'B'
# 정상인
cnt = 0
dx, dy = [1,-1,0,0], [0,0,1,-1]
for i in range(N):
for j in range(N):
if L[i][j] != -1:
a = L[i][j]
stack=[(i,j)]
cnt += 1
while stack:
x, y = stack.pop()
# a = L[x][y] 여기에 넣었더니 -1이 무한반복. 이미 -1로 변한 놈이 스택에서 나올 수 있음.
L[x][y] = -1
for k in range(4):
if (0<= x+dx[k] < N) and (0<= y+dy[k] < N):
if L[x+dx[k]][y+dy[k]] == a:
stack.append((x+dx[k],y+dy[k]))
# 적록색약
cnt2 = 0
for i in range(N):
for j in range(N):
if L2[i][j] != -1:
a = L2[i][j]
stack=[(i,j)]
cnt2 += 1
while stack:
x, y = stack.pop()
L2[x][y] = -1
for k in range(4):
if (0<= x+dx[k] < N) and (0<= y+dy[k] < N):
if L2[x+dx[k]][y+dy[k]] == a: # 여기 L2로 안 바꿔줌
stack.append((x+dx[k],y+dy[k]))
print(cnt, cnt2)
# 어려움 : 적록 색약인 놈이 보는 것도 추가해야 함
# visited 배열 추가했으면 L2 새로 만들 필요 없었음- 문자열 여러개 2차원 배열로 만들 때 list(input())
- 이미 -1로 변한 놈이 스택에서 나올 수 있다는 거 인지.
- 문제 제대로 읽었는데 적록색약도 세야 되는거 까먹음
- visited 배열 선언하면 따로 L2 받을 이유 없음.
- 복붙할거면 인자 바꿔주는거 놓치지 말기
from collections import deque
def BFS(x,y):
q.append((x,y))
dx = [-1,0,1,0]
dy = [0,1,0,-1]
visited[x][y] = 1
while q:
x, y = q.popleft()
for d in range(4):
nx = x + dx[d]
ny = y + dy[d]
# 인덱스 범위 안에 있으면서, 같은 색이면서, 방문 안한 경우
if 0<=nx<N and 0<=ny<N and a[nx][ny] == a[x][y] and not visited[nx][ny]:
visited[nx][ny] = 1 # 방문체크 후 큐에 넣음
q.append((nx,ny))
N = int(input())
a = [list(input()) for _ in range(N)]
q = deque()
# 적록색약 아닌 경우
visited = [[0] * N for _ in range(N)]
cnt1 = 0
for i in range(N):
for j in range(N):
if not visited[i][j]: # 아직 방문 안한 경우만 체킹
BFS(i,j)
cnt1 += 1
# 적록색약인 경우
for i in range(N):
for j in range(N):
if a[i][j] == 'G':
a[i][j] = 'R'
visited = [[0] * N for _ in range(N)]
cnt2 = 0
for i in range(N):
for j in range(N):
if not visited[i][j]:
BFS(i,j)
cnt2 += 1
print(cnt1, cnt2)이 사람 코드 좀 잘 짠듯.
