📚 Journal
넥토리얼 코테 결과 : 6문제 중 4솔 (테케 기준)
ㄲㅂ~
아침부터 알고리즘만 겁나 푸는데
쉬운 문제들도 다 삑사리 나서 계속 gpt 찾고 난리도 아니었는데
그래도 실전은 그냥저냥 평타 쳐서 다행이다.
다음 번엔 좀 더 잘 준비하면 뭔가 각은 보이는듯.
📝 배운 것들
🏷️ 1 based indexing
1-based indexing이란 인덱스가 1부터 시작하는 방식입니다. 즉, 첫 번째 요소의 인덱스가 0이 아닌 1입니다.
파이썬이나 C/C++ 같은 언어에서는 인덱스가 0부터 시작하는 0-based indexing을 사용하지만, 1부터 시작하는 언어 또는 시스템(예: 일부 수학 공식, 데이터베이스 SQL, MATLAB 등)에서는 1-based indexing을 사용합니다.
🍚 코테 준비
📌 게임 맵 최단거리
# 0,0부터 시작해서 n,m까지 bfs한다
# 갈때마다 1로 만들어버린다
from collections import deque
def bfs(maps):
q=deque()
q.append((0,0))
limit_y=len(maps)
limit_x=len(maps[0])
di=[1,-1,0,0]
dj=[0,0,1,-1]
cnt=0
while q:
depth_len=len(q)
cnt+=1
for _ in range(depth_len):
i,j=q.popleft()
maps[i][j]=0
for n in range(4):
if 0<=i+di[n]<limit_y and 0<=j+dj[n]<limit_x:
if maps[i+di[n]][j+dj[n]]==1:
q.append((i+di[n],j+dj[n]))
if maps[-1][-1]==0: return cnt
else: return -1
def solution(maps):
return bfs(maps)뭐가 틀렸는지 모르겠어서 gpt
from collections import deque
def bfs(maps):
q = deque([(0, 0)])
limit_y = len(maps)
limit_x = len(maps[0])
di = [1, -1, 0, 0]
dj = [0, 0, 1, -1]
cnt = 0
while q:
depth_len = len(q)
cnt += 1
for _ in range(depth_len):
i, j = q.popleft()
# 목적지 도달 시 cnt 반환
if i == limit_y - 1 and j == limit_x - 1:
return cnt
# 상하좌우 이동
for n in range(4):
ni, nj = i + di[n], j + dj[n]
if 0 <= ni < limit_y and 0 <= nj < limit_x and maps[ni][nj] == 1:
maps[ni][nj] = 0 # 방문 체크만
q.append((ni, nj))
# 목적지에 도달하지 못한 경우
return -1
def solution(maps):
return bfs(maps)이걸로 제출하니까 맞긴 함
목적지에 도착하면 cnt를 종료해야되는데
목적지 도착하고도 다른 경로들 다 가보려고 해서 틀렸음
큰일났다 감다뒤
# 0,0부터 시작해서 n,m까지 bfs한다
# 갈때마다 1로 만들어버린다
from collections import deque
def bfs(maps):
q=deque()
q.append((0,0))
limit_y=len(maps)
limit_x=len(maps[0])
di=[1,-1,0,0]
dj=[0,0,1,-1]
cnt=0
while q:
depth_len=len(q)
cnt+=1
for _ in range(depth_len):
i,j=q.popleft()
maps[i][j]=0
if i==limit_y-1 and j==limit_x-1:
return cnt
for n in range(4):
if 0<=i+di[n]<limit_y and 0<=j+dj[n]<limit_x:
if maps[i+di[n]][j+dj[n]]==1:
q.append((i+di[n],j+dj[n]))
return -1
def solution(maps):
return bfs(maps)바꿨는데도 효율성 테스트 통과 못함
for n in range(4):
ni, nj = i + di[n], j + dj[n]
if 0<=ni<limit_y and 0<=nj<limit_x and maps[ni][nj]==1:
maps[ni][nj]=0
q.append((ni,nj))큐에 넣을 때 바로 방문체크 해버리지 않으면
중복되는 친구들 다같이 방문을 해버리는 경우가 생긴다
📌 단어 변환
# bfs로 다음 단어 후보 탐색 후에 cnt 올리기
# 큐에서 단어 꺼낼 때마다 words에서 단어 전부 검사하고 큐에 넣기
# 큐에 넣을 때 세트에 넣어서 방문 처리
# 다음 단어 조건 : 방문 안했었던, 지금 꺼낸 글자랑 한 글자만 다른 글자
# 한 글자만 다른거 검사 : 같은 인덱스 훑으면서 다른 거 2개 이상 찾으면 탈락
from collections import deque
def oneLetterDiff(origin,comp):
oneDiff=False
cnt=0
for i in range(len(origin)):
if origin[i] != comp[i]:
oneDiff=True
cnt+=1
if cnt==2:
oneDiff=False
break
return oneDiff
def bfs(begin,target,words):
visited=set([begin])
q=deque([begin])
res=-1
while q:
depth_len=len(q)
res+=1
for _ in range(depth_len):
origin=q.popleft()
if origin == target:
return res
for comp in words:
if comp not in visited and oneLetterDiff(origin,comp):
visited.add(comp)
q.append(comp)
return 0
def solution(begin, target, words):
return bfs(begin,target,words) 그나마 감각 돌아와서 이정도는 힌트 안 보고 품
📌 입국심사
# 기다린 시간을 7로 나눈 수와 10으로 나눈 수를 더하면 심사 받은 사람 명수
# 심사 받은 사람이 특정 인원 이상이 되는 최소 시간을 구해야 함
def solution(n, times):
start,end=0,10e10
while start<=end:
mid=(start+end)//2
passed=0
for time in times:
passed+=mid//time
if passed > n:
end = mid-1
elif passed < n:
start = mid+1
else:
break
return mid아 근데 이분탐색은 또 모르겠음 여기서 막혀서 gpt 씀
def solution(n, times):
start, end = 0, max(times) * n
answer = end
while start <= end:
mid = (start + end) // 2
passed = 0
for time in times:
passed += mid // time
if passed >= n:
answer = mid # 현재 시간을 후보로 저장
end = mid - 1 # 더 작은 시간을 탐색
else:
start = mid + 1 # 더 큰 시간을 탐색
return answer
mid는 마지막에 start와 같아지므로
조건을 만족하는 최소값이 아니라
조건을 만족하지 않는 최대값을 찾아내게 될 가능성 있음
그러므로 answer에 mid를 저장해놓는거
근데 이것보다
def solution(n, times):
start, end, mid = 1, times[-1] * n, 0
while start < end:
mid = (start + end) // 2
total = 0
for time in times:
total += mid // time
if total >= n:
end = mid
else:
start = mid + 1
return start다른 사람 풀이가 더 좋긴 한듯.
end = mid로 두고 종료 조건을 start < end로 둔 후에
start를 반환하면 된다.
내가 원래 외우고 있던 이분 탐색이랑 살짝 달라서 바로 체득은 안될듯.
실전에선 그냥 gpt 버전으로 가자.
📌 REST API : Total Goals by a Team
import requests
def getTotalGoals(team, year):
total_goals = 0
# Helper function to fetch and sum goals
def fetch_goals(team_param, team_name):
goals = 0
page = 1
while True:
url = f'https://jsonmock.hackerrank.com/api/football_matches?year={year}&{team_param}={team_name}&page={page}'
response = requests.get(url).json()
data = response['data']
if not data:
break
for match in data:
goals += int(match[f'{team_param}goals'])
if page >= response['total_pages']:
break
page += 1
return goals
# Sum goals when the team is team1
total_goals += fetch_goals('team1', team)
# Sum goals when the team is team2
total_goals += fetch_goals('team2', team)
return total_goals뭐가 뭔지 모르겠는데 시간 없어서 그냥 바로 답지 봄
url 요청을 보내기 위해서
갖고 있던 변수들을 url에 잘 포장해놓고
data를 requests.get(url).json()으로 받은 뒤에
거기에 있는 data를 본다.
data에는 경기 정보들이 들어있다. (returns data associated with matches in the year ...)
data가 없으면 우웩 하고 꺼버리고 (오류를 대비한듯)
data에 들어있는 정보들을 f'{변수}문자열' 사용해서 원하는 놈들 정보 확인한다
page가 total_page 보다 크면 우웩 하고 꺼버린다 (다 본 거니까)
이번 페이지 다 봤으면 page+=1 해서 다음 페이지 요청한다
fetch_goals('team1', team) 두 번 하는 이유는 홈일 때 어웨이일 때 데이터 합치기 위함
import requests
def getTotalGoals(team, year):
total_goals = 0
# Helper function to fetch and sum goals
def fetch_goals(team_param):
goals = 0
page = 1
while True:
url = f'https://jsonmock.hackerrank.com/api/football_matches?year={year}&{team_param}={team}&page={page}'
response = requests.get(url).json()
data = response['data']
if not data:
break
for match in data:
goals += int(match[f'{team_param}goals'])
if page >= response['total_pages']:
break
page += 1
return goals
# Sum goals when the team is team1
total_goals += fetch_goals('team1')
# Sum goals when the team is team2
total_goals += fetch_goals('team2')
return total_goals인자 줄여도 함수 내에서 쓰이는 거라 괜찮은듯
📌 REST API : Number of Drawn Matches
import requests
def getNumDraws(year):
draw_num=0
page=1
while True:
for i in range(11):
url = f'https://jsonmock.hackerrank.com/api/footbal_matches?year={year}&team1goals={i}&team2goals={i}&page={page}'
response = requests.get(url).json()
data = response['data']
if not data:
continue
for match in data:
draw_num+=1
if page >= response['total_pages']:
break
return draw_num어떻게든 해봤는데 자꾸 total_pages 없다고 오류 남.
import requests
def getNumDraws(year):
draw_num = 0
for i in range(0, 11):
page = 1
while True:
url = f'https://jsonmock.hackerrank.com/api/football_matches?year={year}&team1goals={i}&team2goals={i}&page={page}'
response = requests.get(url).json()
data = response['data']
draw_num += len(data)
if page >= response['total_pages']:
break
page += 1
return draw_numgpt가 고쳐줬다.
일단 for match in data 할 필요 없이 len(data) 하면 그게 match 수.
그리고 0대0 ~ 10대10일 때의 각 경우의 수가 기본이고
그 다음에 페이지들을 훑었다.
내 코드처럼 하면 n대n일 때는 데이터가 없는데도 훑으려고 시도함.
각 경우의 수에 대해 모든 페이지를 훑어야 종료 조건을 잘 설정할 수 있음.
📌 Lists
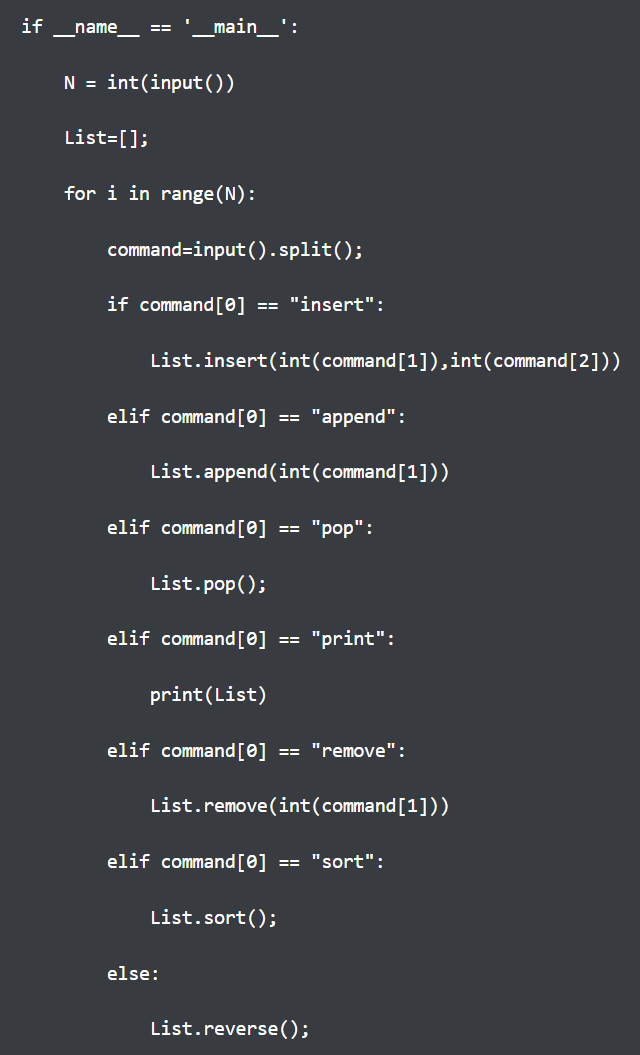
input().split()의 의미를 정확히 숙지하지 못하고 있었다
input().split()은 Python에서 표준 입력을 받아 문자열로 처리한 후, 공백을 기준으로 문자열을 나누어 리스트로 반환하는 구문입니다.
구체적인 의미
input(): 사용자가 입력한 값을 문자열로 읽어옵니다..split(): 공백을 기준으로 문자열을 나누어 리스트로 만듭니다.
예를 들어, 다음과 같은 입력이 있을 때:
# 입력 예시: "hello world 123"
data = input().split()
print(data)입력: hello world 123
출력:
['hello', 'world', '123']이렇게 input().split()은 입력을 공백을 기준으로 나눈 문자열 리스트를 생성하므로, 여러 값을 한 번에 받아 처리할 때 유용합니다.
📌 Flatland Space Station
def flatlandSpaceStations(n, c):
c.sort()
res=max(c[0]//2,(n-1-c[-1])//2)
for i in range(len(c)-1):
res=max((c[i+1]-c[i])//2,res)
return res nlogn으로 정렬 시켜주고 n만큼 순회하면 최종 시간 복잡도 nlogn
분명 계획은 완벽했는데
또 아무리 봐도 안 풀려서 물어봤더니
gpt가 고쳐준거 쓰니까 바로 풀리는 개꿀잼 몰카 또또 발생
def flatlandSpaceStations(n, c):
c.sort()
res = max(c[0], (n - 1 - c[-1]))
for i in range(len(c) - 1):
res = max((c[i + 1] - c[i]) // 2, res)
return res최대값이니까 초기값은 //2를 해줄 필요 없었다.
(그리고 처음엔 n-c[-1]//2로 했었는데 n-1-c[-1]가 맞았다. 문제 조건이 그럼.)
📌 4485 녹색 옷 입은 애가 젤다지?
# 특정 위치에서 시작해서 특정 위치까지 가는 가중치 최소 경로를 구해야 되니까 다익스트라
# 상하좌우 확인하는데 비용이 작아지면 우선순위 큐에 넣어라
import heapq
N=int(input())
cnt=0
while N!=0:
cnt+=1
cost_sum = [[float('inf')]*N for _ in range(N)]
thief = [list(map(int,input().split())) for _ in range(N)]
q = []
heapq.heappush(q, (thief[0][0],0,0))
cost_sum[0][0] = thief[0][0]
dy = [1,-1,0,0]
dx = [0,0,1,-1]
while q:
cost, y, x = heapq.heappop(q)
# 노드로 가는 비용이 더 비싸다면 패스
if cost_sum[y][x] < cost:
continue
# 연결된 모든 노드 탐색
for i in range(4):
ny, nx = y+dy[i], x+dx[i]
if 0<=ny<N and 0<=nx<N:
new_cost = cost + thief[ny][nx]
if new_cost < cost_sum[ny][nx]:
cost_sum[ny][nx] = new_cost
heapq.heappush(q,(new_cost,ny,nx))
print(f"Problem {cnt}: {cost_sum[-1][-1]}")
N=int(input())다익스트라 공부를 제대로 한 적이 없어서
일단 다익스트라 기본 코드 보면서 해봄
기본적으로 다익스트라는 bfs인데
큐가 그냥 큐가 아니고 힙큐고
큐에 넣는 조건이 경로 비용 갱신됐을 때인 bfs라고 보면 될듯
이 문제는 경로에 가중치가 부여된게 아니라 정점에 부여돼서 시작점을 thief[0][0]으로 초기화했어야 했는데 0으로 했던게 실수요인.
directions = [(1,0), (-1,0), (0,-1), (0,1)]
case_num = 1
def dijkstra(grid, n):
distance = [[INF] * n for _ in range(n)]
distance[0][0] = grid[0][0]
q = [(distance[0][0], 0, 0)]
while q:
dist, x, y = heapq.heappop(q)
if distance[x][y] < dist:
continue
for dx, dy in directions:남의 풀이. 방향 4개일 땐 이렇게 하는게 훨씬 깔끔한듯?
이 테크닉도 분명 언젠가 봤었을텐데 까먹음
