
HashMap
파이썬에서 'dict'라고 불리는 내장 자료형을 사용하여 HashMap과 유사한 기능을 구현한다. 이때 HashMap은 키-값 쌍을 저장하고 관리하는 자료구조다.
개별 체이닝 해시맵
해시 충돌을 해결하기 위한 방법 중 하나로, 해시 테이블의 각 슬롯(버킷)에 연결 리스트(Linked List)나 다른 자료구조를 사용하여 동일한 해시 코드를 가진 키-값 쌍을 저장한다. 즉, 하나의 슬롯에 여러 개의 키-값 쌍을 연결 리스트나 다른 자료구조로 연결하여 관리하는 방식이다.
✅ HashMap 구현 코드
import collections
class ListNode:
# 파라미터가 안넘어오면 None으로 설정
def __init__(self, key=None, value=None):
self.key = key
self.value = value
self.next = None
class MyHashMap:
# 초기화
def __init__(self):
# 해시 테이블의 크기
self.size = 1000
# 실제 해시 맵을 나타내는 데이터 구조
self.table = collections.defaultdict(ListNode)
# 삽입
def put(self, key: int, value:int)->None:
index = key % self.size
# 인덱스에 노드가 없다면 삽입 후 종료
if self.table[index].value is None:
self.table[index] = ListNode(key,value)
return
# 인덱스에 노드가 존재하는 경우 연결 리스트 처리
p = self.table[index]
while p:
# key가 3이 넘어오고, 기존에 key 3의 값이 있으면
if p.key == key:
# 기존의 값 (10)에 새로 들어온 값(13)을 넣는다.
p.value = value
return
# 만약 다음 연결 리스트가 없으면 멈추고,
if p.next is None:
break
# 있으면 기존의 노드(2,10)를 다음 노드로 바꾸고
p = p.next
# 다음 노드를 새로 들어온 연결 리스트를 넣는다.
p.next = ListNode(key,value)
#조회
def get(self, key:int)->int:
index = key % self.size
if self.table[index].value is None:
return -1
#노드가 존재할 때 일치하는 키 탐색
p = self.table[index]
while p:
if p.key == key:
return p.value
p = p.next
return -1
#삭세
def remove(self, key: int)->None:
index = key % self.size
if self.table[index].value is None:
return
#인덱스 첫 번째 노드일 때 삭제 처리
p = self.table[index]
if p.key == key:
self.table[index] = ListNode() if p.next is None else p.next
return
#연결 리스트 노드 삭제
prev = p
while p:
if p.key == key:
prev.next = p.next
return
prev.p = p, p.next
단계별 설명
1. ListNode
class ListNode:
# 파라미터가 안넘어오면 None으로 설정
def __init__(self, key=None, value=None):
self.key = key
self.value = value
self.next = None- ListNode에는 key, value, next(다음 노드에 대한 값)이 필요하다.
2. HashMap 초기화
# 초기화
def __init__(self):
# 해시 테이블의 크기
self.size = 1000
# 실제 해시 맵을 나타내는 데이터 구조
self.table = collections.defaultdict(ListNode)- size는 임의로 정할 수 있고 우선 1000개정도로 잡는다. table은 각 해시 값과, 각 해시 값에 대한 Node를 key-value 값으로 가진다.
- defaultdict는 key 값이 없을 경우, ListNode의 기본값을 넣는다.
3. HashMap Put
# 삽입
def put(self, key: int, value:int)->None:
index = key % self.size
# 인덱스에 노드가 없다면 삽입 후 종료
if self.table[index].value is None:
self.table[index] = ListNode(key,value)
return
p = self.table[index]
while p:
if p.key == key:
p.value = value
return
if p.next is None:
break
p = p.next
p.next = ListNode(key,value)- index의 값은 key % self.size로 정의하고 있다. 이때 두가지 경우가 발생한다.
1. 해시 테이블의 해시 값은 통일하지만 키 값은 다른 경우
2. 해시 테이블의 해시 값이 동일하고 실제 키 값도 동일한 경우ex) key의 값이 2, 1002인 경우 index = key % self.size 의 결과 값은 둘 다 2로 해시 값은 동일하지만 key 값이 다르다
self.table[index]를 통해 해당 index(해시값)의 존재 여부를 확인한다. 없다면 해당 해시값에 ListNode를 추가하고 존재하는 경우 아래 조건문을 확인한다.- 만약
1. 해시 값과 key값이 동일한 경우데이터를 덮어쓰고 (실제 해당 key에 대한 값을 변경하기 위함이기 때문이다.)2. 해시 값과 key값이 다른 경우기존에 존재하면 Node의 next를 통해 충돌된 LinkNode를 연결 리스트를 통해 연결한다.
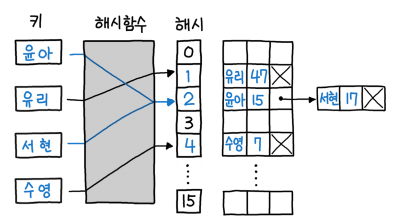
즉, 위 그림에서 해시 값이 2에 기존의 key=윤아, value=15가 있는데 key=윤아, value=34가 오게 되면 해당 key값이 동일하기 때문에 value를 덮어쓴다.
반면 해시 값이 2에 key=서현이 오게 되면 해시 값은 동일하지만 key값이 다르기 때문에 기존의 key=윤아 Node의 next에 key=서현 Node가 저장된다.
HashMap Get
#조회
def get(self, key:int)->int:
index = key % self.size
if self.table[index].value is None:
return -1
#노드가 존재할 때 일치하는 키 탐색
p = self.table[index]
while p:
if p.key == key:
return p.value
p = p.next
return -1- 해당 해시 값이 없는 경우 Node가 기본값이 주어지고 value 값이 없는 것이기 때문에 None을 반환한다.
- 해당 해시 값이 존재하는 경우 key가 일치하는지 판단하고 key가 일치하면 해당 Node의 value를 반환하고, 키가 다를 경우 next에 있는 Node로 변경하여 key 값 비교를 반복한다.
조회의 경우에도 마찬가지로 key=서현을 조회하게 되면 먼저 해시 값이 2를 조회하고 우선 key=윤아를 만나게 되는데 key값이 다르기 때문에 조회하는 Node를 next에 있는 key=서현 다음 Node로 변경하고 key 값을 비교한다.
HashMap Remove
#삭제
def remove(self, key: int)->None:
index = key % self.size
if self.table[index].value is None:
return
#인덱스 첫 번째 노드일 때 삭제 처리
p = self.table[index]
if p.key == key:
self.table[index] = ListNode() if p.next is None else p.next
return
#연결 리스트 노드 삭제
prev = p
while p:
if p.key == key:
prev.next = p.next
return
prev.p = p, p.next- 해시 값에 대해 value가 없으면 아무것도 수행하지 않는다.
- 해시 값에 대한 key 값을 비교하고 key값이 일치하는 경우 현재 Node를 next(다음 노드)로 변경한다. -> key가 일치하는 Node는 삭제되는 것이다.
- 만약 key 값이 일치하지 않는경우, 현재 노드를 prev 노드에 저장하고 p를 다음 노드로 변경하고 key 값을 비교하는 동작을 반복하며 key 값이 동일한 p가 나오면 prev의 next를 현재 비교중인 p의 next 값으로 변경한다.(현재 노드는 삭제되기 때문에 현재 비교중인 Node의 next를 이전 노드에 전달한다.)
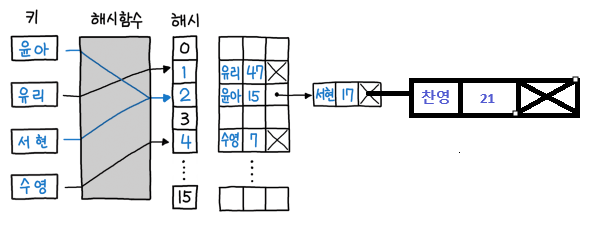
즉, 위의 그림에서 key=서현을 삭제한다고 하면 key=윤아는 키 값이 다르기 때문에 key=서현으로 이동하고 prev에 key=윤아 Node가 담기게 된다. key=서현은 원하는 key값이 맞기 때문에 prev.next(key=서현) Node를 p.next(key=찬영)으로 변경하게 된다.
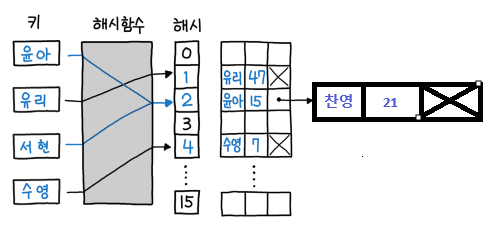
결국 위와 같이 LinkNode가 변경되게 된다.
✅ 참조
파이썬 알고리즘 인터뷰
