0 Intro
이 글은 1대 서버요정 minostauros - github profile이 만들어낸 연구실의 GPU Cluster를 유지보수하고 있는 2대 서버요정(a.k.a me)이 정리를 위해 쓰는 글이다.
고작 연구실 서버 관리가 무에 대수라고 블로그 글까지 쓰나...
위와 같은 생각이 드는 사람을 위해 우선 문제를 정의하고 가려고 한다.
인생사 새옹지마
2018년 인공지능 그랜드챌린지 우승과 다년간의 우수한 탑티어 컨퍼런스 논문 실적으로 이런저런 과제를 많이 받은 연구실은 서버의 수가 기하급수적으로 늘어나게 된다. 그와 함께 이를 관리해야할 필요성도 생기게 된다.
2020년 11월 23일 기준으로 조립 컴퓨터 36대, 랙서버 2대, DGX-1 1대를 보유하고 있다. 대부분의 조립컴, 랙서버에는 3~4개의 GPU가 들어가서 약 120개의 GPU를 보유하고 있는 셈이다.
여기서 이제 문제에 봉착하게 된다. 30명이 넘는 연구실 구성원이 120개의 GPU를 공간,시간 효율적으로 사용하기 위해서는 어떤 시스템과 정책을 갖춰야할까?
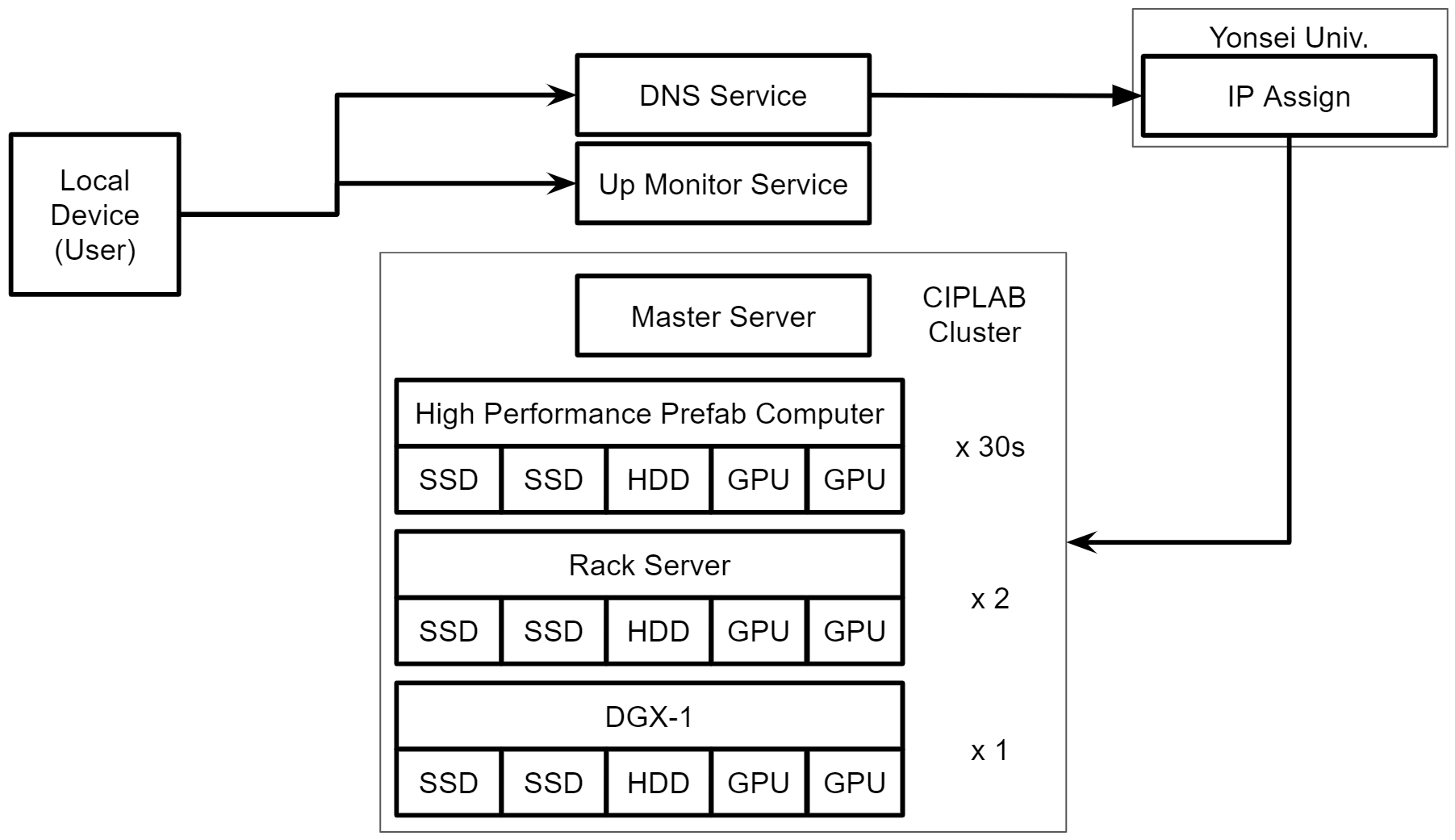
 |
|---|
| CIPLAB GPU Cluster Overview |
해결책의 방향성
- sol1. 개개인 혹은 팀에게 서버를 할당하고 알아서 관리 및 사용
- sol2. 클라우드 컴퓨팅 기반으로 모든 자원(CPU, GPU, Disk)을 가상화하고 사용 요청 시 사용자의 현재 사용량 및 현재 가용량을 고려해 할당
sol1은 가장 자동화되어 있지 않은 방식이고 sol2는 가장 자동화되어있다. 그로인해 아래와 같은 장단점이 발생하게 된다.
| sol1 | sol2 | |
|---|---|---|
| 장점 | 서버 관리의 불필요 | 모든 자원을 효율적으로 자원들을 활용 |
| 단점 | 효율적인 사용이 불가능 (e.g. 특정 개인이나 팀 유휴) | 클라우드 컴퓨팅 서비스 유지보수 필요 |
그래서 CIPLAB GPU Cluster는 가능한 두 해결책의 단점을 최소화 하는 방향으로 구성되었다. 현재 가용자원, 개별 사용자원을 모니터링하며 효율적인 사용이 가능하되 이러한 서비스의 유지보수 필요성을 가능한 낮추는 방향이다.
요구사항과 설계원칙
따라서 1대 서버요정은 아래와 같은 요구사항에 직면하게 되었다.
- 특정 서버가 개인에게 점유되지 않고 재사용 가능할 것
- 현재 서버를 누가 얼마나 사용하고 있는지 알 수 있을 것
- 어떤 서버가 사용 가능한지 알 수 있을 것
- 시스템 장애를 관리자나 유저가 알아챌 수 있을 것
- 가능한 유지보수가 필요없는 외부 서비스 및 프로그램을 사용할 것
이러한 요구사항을 아래와 같이 해결하게 된다.
- docker를 이용해 서버를 사용하는 유저의 프로세스를 모두 가상화
- container 이름 규약을 이용해 현재 이용량을 파악할 수 있도록 구현
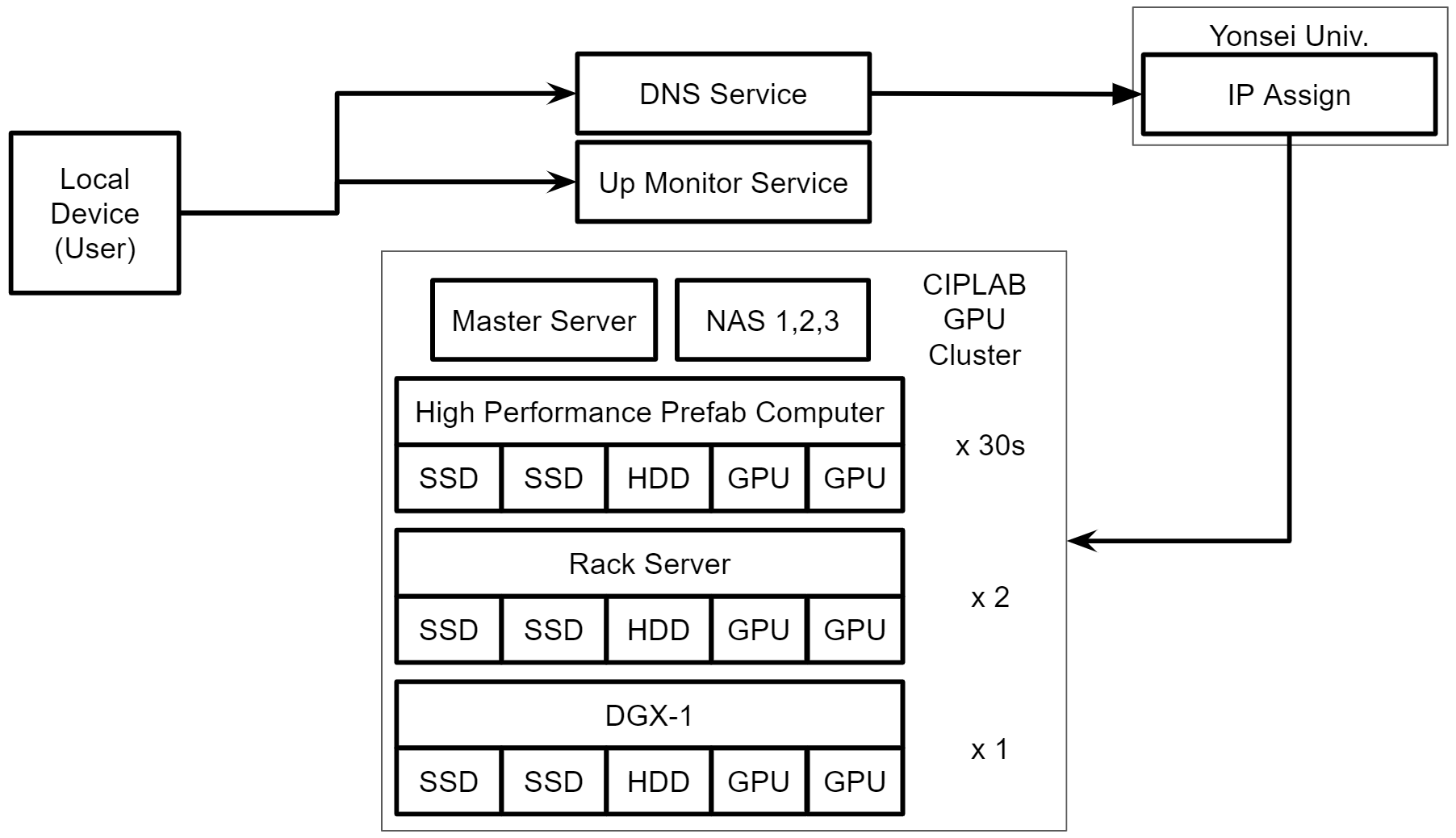
- CPU, GPU, Disk, Network 정보 등을 마스터 서버로 모아서 대시보드에서 표시(아래 그림 우측)
- 현재 서버가 살아있는지 ping을 통해 대시보드에서 표시(아래 그림 좌측)
- 이 과정에서 사용되는 프로그램들 대부분 유지보수를 하고 있는 Open Source거나 SaaS 서비스는 아래와 같다.
- Docker: 유저 프로세스 가상화, 처음에는 GPU 사용을 위해 Nvidia Docker를 필요로 했지만 이제 정식 버전에서도 지원
- UptimerRobot: ping을 날려서 특정 서버가 구동 중인지 확인 및 대시보드 생성
- cluster-smi:
nvidia-smi를 이용해서 이 정보를 한 곳으로 모으는 open source, 1대 서버요정이 수정한 버전에서 container name, 온도, 전력 사용량 등도 알 수 있음 - duc: disk 사용량을 알 수 있음
- netdata: 시스템에 대한 각종 데이터를 real-time으로 알려준다.
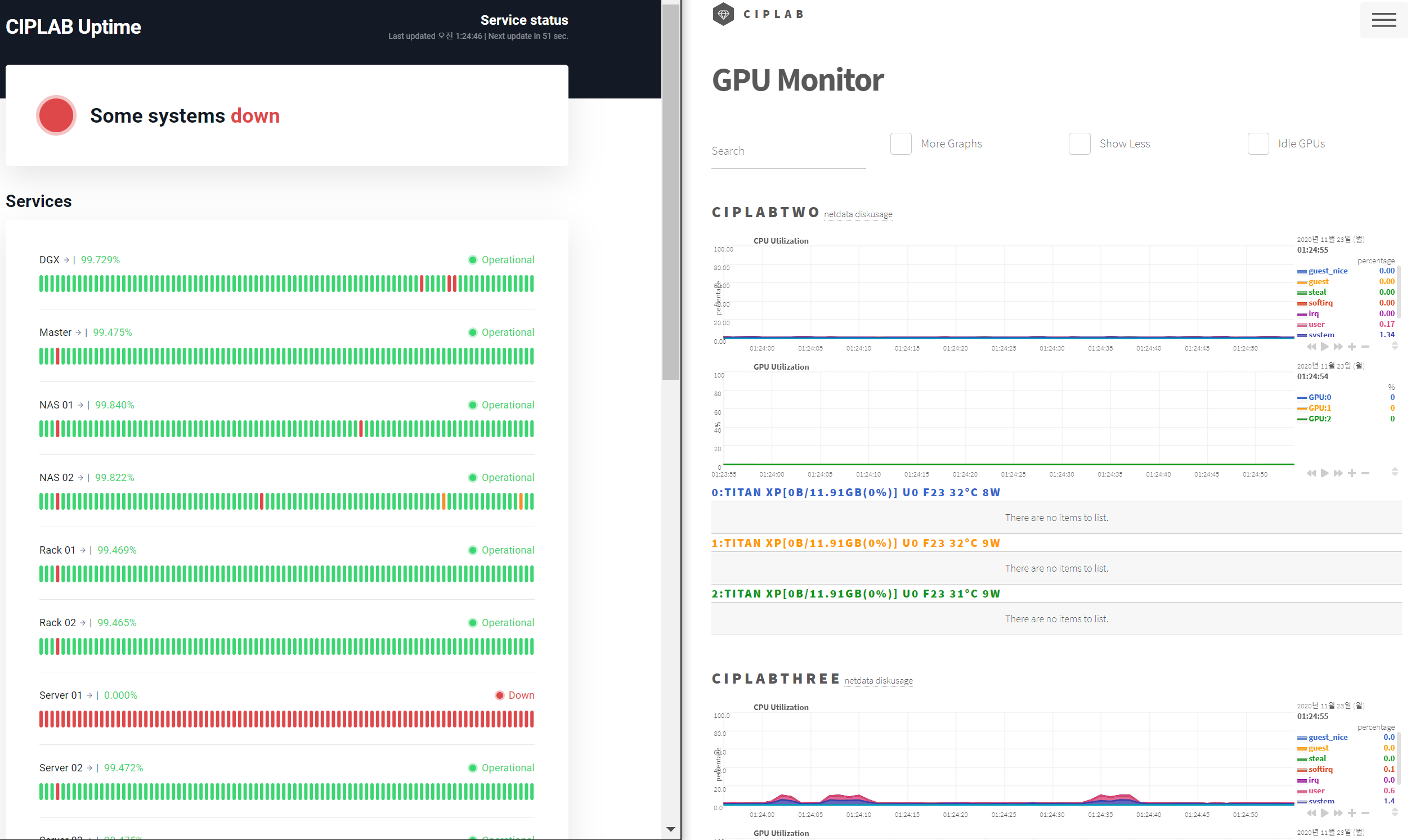 |
|---|
| Up 모니터링(좌측)과 각종 자원(CPU, GPU, Disk, Network) 모니터링(우측) |
다음 글이 있을까?
기본적으로 이 시리즈는 다음과 같은 목적을 가지고 진행될 예정이다.
- 나 스스로 현재 상태가 어떤지 파악하기
- 연구실 신입에게 설명하기 귀찮으니 던져줄 링크 만들기
- 이 글을 보고 혹시나 관심이 생길 3대 서버요정 후보 찾기
- 지금까지 시도했는데 안 되었던 Trouble & Shooting 정리하기
- 돈이 없어서 클라우드도 못 쓰고 시스템 엔지니어도 고용 못 하는 어정쩡한 규모의 서버실을 굴리는 책임자를 위한 팁
전부 애매한 목적이기 때문에 앞으로 관련 글을 더 안 쓸 수도 있다는 말씀!


저도 인공지능 연구실에서 서버관리를 하고 있는데 저희랑 동일한 방법을 하고 계셔서 너무 반갑네요!ㅋㅋㅋ
저희는 기본 도커구성(cuda, jupyter lab, opencv, ssh, xrdp)으로 운영하고
따로 웹 서비스를 만들어서 사용자가 직접 컨테이너 생성하도록 운영하고 있습니다.
모니터링 시스템이 없어서 아쉬워서 직접 만들까 고민중이었는데
Duc, netdata 를 조합하면 되겠군요
그런데 네트워크 구성은 어떻게 하셨는지 궁금합니다.
외부에서 원격으로 접속하는 일이 많을텐데, 퍼블릭 아이피를 여러개 할당받으셔서
NAT port mapping으로 하셨을까요?