
이전 블로그에서 2020.01.25에 작성된 글입니다.
들어가며
근래에 NAS(Neural Architecture Search)로 주제를 바꾸며 pytorch를 더 자유자재로 구현할 필요성이 생겼다.
그런데 공부를 하다가 autograd 관련 예제의 결과를 예측하는데 실패한 것들이 있어서 정리할겸 이 글을 쓴다.
우선 Autograd의 동작을 이해하고 싶다면 아래의 동영상을 추천한다.
이를 이해하고 나면 몇 개의 예제를 살펴보자.예제1 - scalar value와 backward
x = torch.ones(1, requires_grad=True)
print(x)
y = x + 2
print(y)
print("===== Run backward =====")
y.backward()
print(y)
# Output
"""
tensor([1.], requires_grad=True)
tensor([3.], grad_fn=<AddBackward0>)
===== Run backward =====
tensor([3.], grad_fn=<AddBackward0>)
"""위의 예제는 심플하다.
예제2 - chain rule + scalar backward
import torch
x = torch.ones(2, 2, requires_grad=True)
print(x)
"""
tensor([[1., 1.],
[1., 1.]], requires_grad=True)
"""
y = x + 2
print(y)
"""
tensor([[3., 3.],
[3., 3.]], grad_fn=<AddBackward0>)
"""
z = y * y * 3
out = z.mean()
print(z, out)
"""
tensor([[27., 27.],
[27., 27.]], grad_fn=<MulBackward0>) tensor(27., grad_fn=<MeanBackward0>)
"""
out.backward()
print(x.grad)
"""
tensor([[4.5000, 4.5000],
[4.5000, 4.5000]])
"""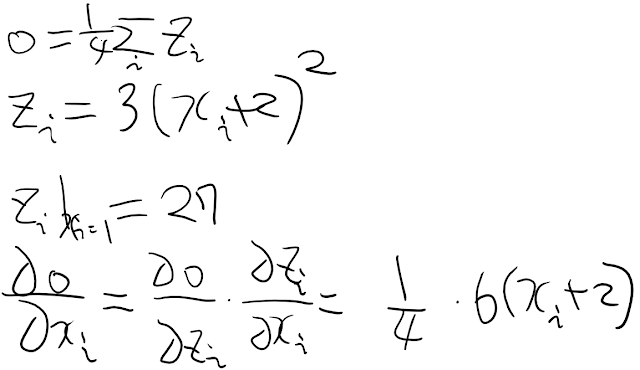
예제3 - vector backward
개인적으로 잘 이해가 되지 않았던 부분은 이 부분이다.
x = torch.randn(3, requires_grad=True)
y = x * 2
while y.data.norm() < 1000:
y = y * 2
print(y) # tensor([-195.7258, 698.0129, -715.0337], grad_fn=<MulBackward0>)
gradients = torch.tensor([0.1, 1.0, 0.0001], dtype=torch.float)
y.backward(gradients)
print(x.grad) # tensor([1.0240e+02, 1.0240e+03, 1.0240e-01])backward에 넣어주는 gradients가 무엇을 의미하는지, 그리고 x.grad의 결과값은 왜 저렇게 나오는지 이해하기가 어려웠다.
그래서 torch.autograd.backward - pytorch docs
.PNG) 를 참조해보았더니 아래와 같이 설명이 나왔다.
를 참조해보았더니 아래와 같이 설명이 나왔다.
Autograd and Jacobian Matrix
Jacobian Matrix는 m 차원에서 n 차원으로 가는 함수 f가 있다고 할 때 각각의 차원에 대해 모든 편미분 값을 모아놓은 matrix이다.
그리고 grad_tensors는 이 Jacobian Matrix에 곱해주는 어떤 값이라고 할 수 있다. 이는 여러 방향으로 응용될 수 있다.
learning_rate, chain rule 등등에 사용가능하기 때문이다.
결론
사실 블로그 글은 항상 시작할 때는 잘 써야지 하다가 마지막에 가면 그냥 대충 쓰게되는 것 같다.
이 요약 글을 보고 잘 이해가 안 되면 맨 처음의 동영상이나 참고자료를 잘 보면 될 것 같다.
참고자료

블로그가 이전되었습니다. (2024.09.12) 홈페이지 참조 (https://yangspace.co.kr/)