VPC Peering
1. 도입 배경
사내 XX BI 구축 프로젝트에서 아키텍처와 함께 데이터 파이프 라인 구축업무를 맡게 되었다.
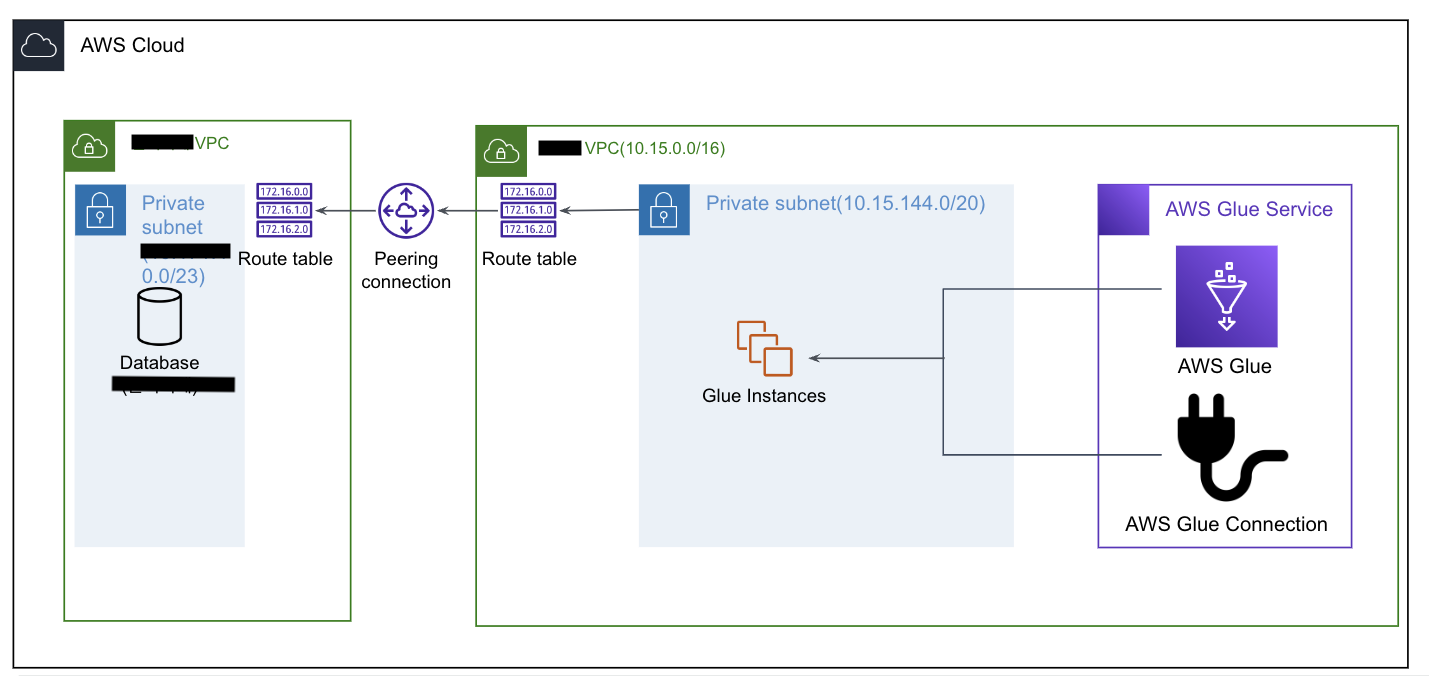
타 AWS 계정에 있는 Source DB에서 현재 AWS 계정에서 Glue를 이용하여 데이터를 ETL 작업을 수행이 필요하여 VPC Peering을 사용하여 연결하고자 했음.
2. VPC Peering
AWS 상의 가상 네트워크인 VPC(Virtual Private Cloud)는 같은 AWS Cloud이지만 논리적으로 분리되어있는 구조이다.
VPC Peering 은 논리적으로 분리되어있는 복수개의 VPC 간에 트래픽을 라우팅할 수 있도록 네트워크를 연결해주는 기능이다.
같은 계정 내 VPC는 물론, 타 계정에 있는 VPC끼리도 연결이 가능하다.
동일 AZ내 Networking은 무료로 구성이 가능하나, 다른 가용영역 및 리전에서는 비용이 발생하므로 해당 비용은 AWS 요금에서 찾아보길 바란다.
3. 실습
3.1 구성
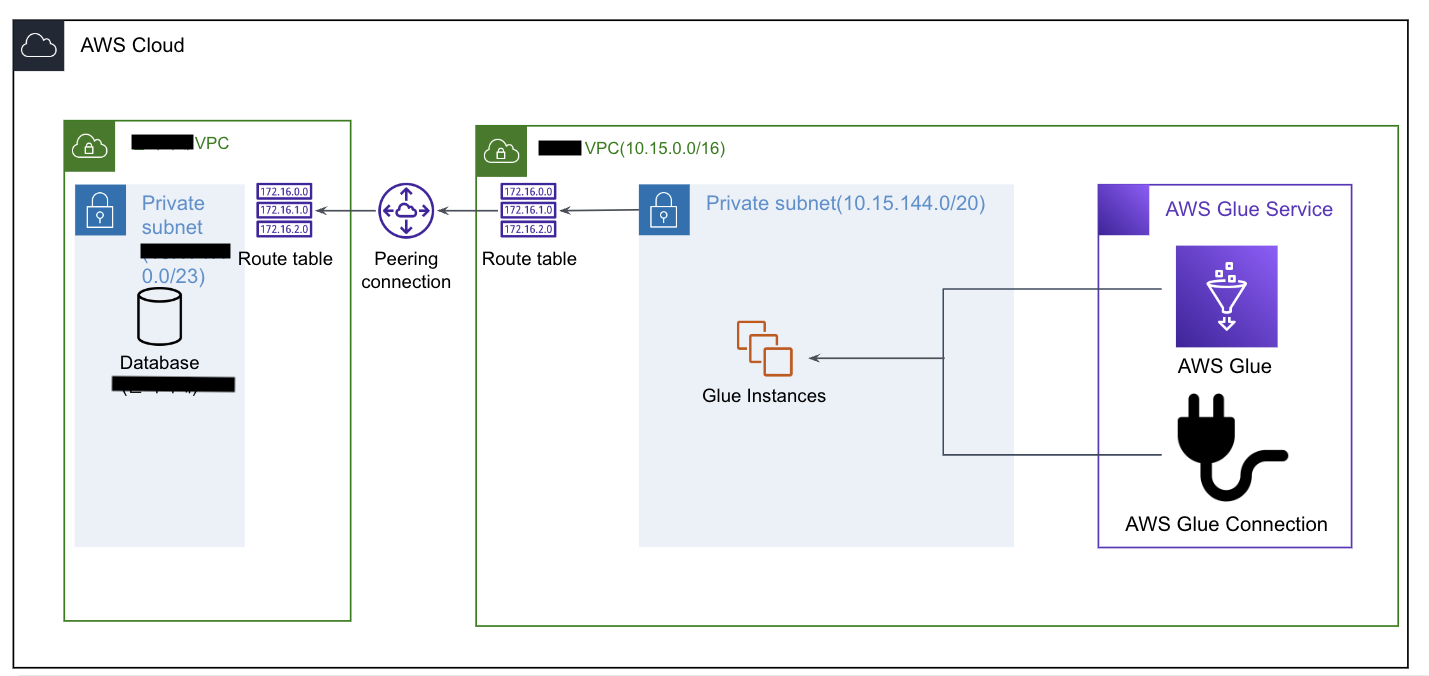
- 요청자가 수신자에게 연결 요청
- 요청자
- 수신자
- 수신자가 연결 요청 수락 → 활성화
- Private IP를 이용하여 통신하는 경우 라우팅 테이블에 경로 추가(DB가 Private Subnet에 있다)
- SG에 의해 트래픽이 제한되어있을 경우 필요시 수정.
- 요청자 IP 대역대 Open
주의 사항: 요청 및 수락하는 VPC의 IP대역다가 같은 대역으로 되어있을 경우 IP충돌으로 인해 VPC Peering을 구성할 수 없다.- 즉, 요청자도 10.0.0.0/16, 수신자도 10.0.0.0/16 이라면 Peering을 구성할 수 없다.
- 타계정, 같은 계정 구성의 차이는 크게 없다.
3.2 환경
3.3.1 요청자 Account(Glue)
- Account ID : xxxxxxx
- VPC ID : xxxxxxxx
- VPC IPv4 CIDR
- 10.12.0.0/16
3.3.2 수신자 Account(DB)
- Account ID : xxxxxx
- VPC ID : xxxxxx
- VPC IPv4 CIDR
- 10.15.0.0/16
3.3.3 연결
- 요청자(Glue를 연결할 계정 내 VPC) VPC Peering 요청
3.3 연결 요청
3.3.1 Requester(요청자)
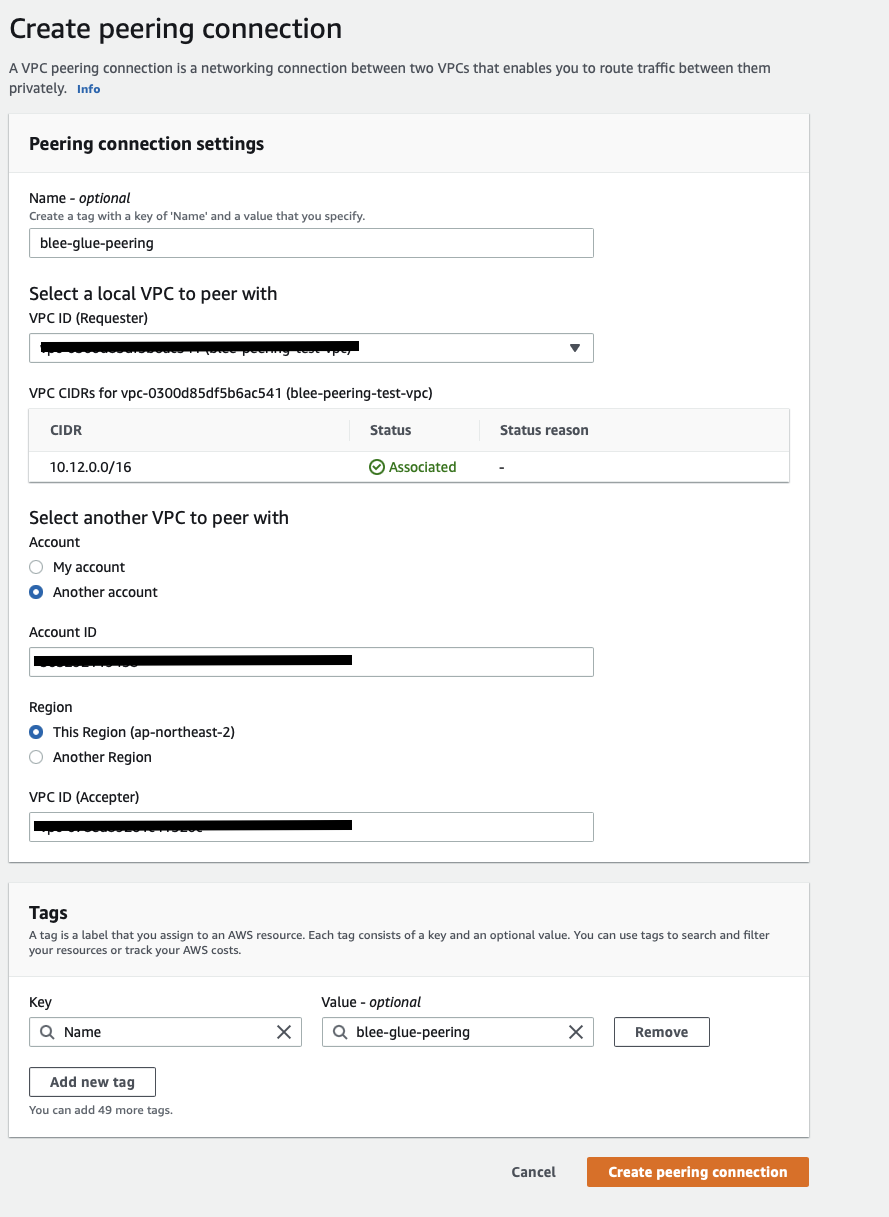
3.3.2 Accepter(수신자)
해당 요청에 대해서 수신자는 Action -> 승인 -> 활성화

3.4 라우트 테이블 설정
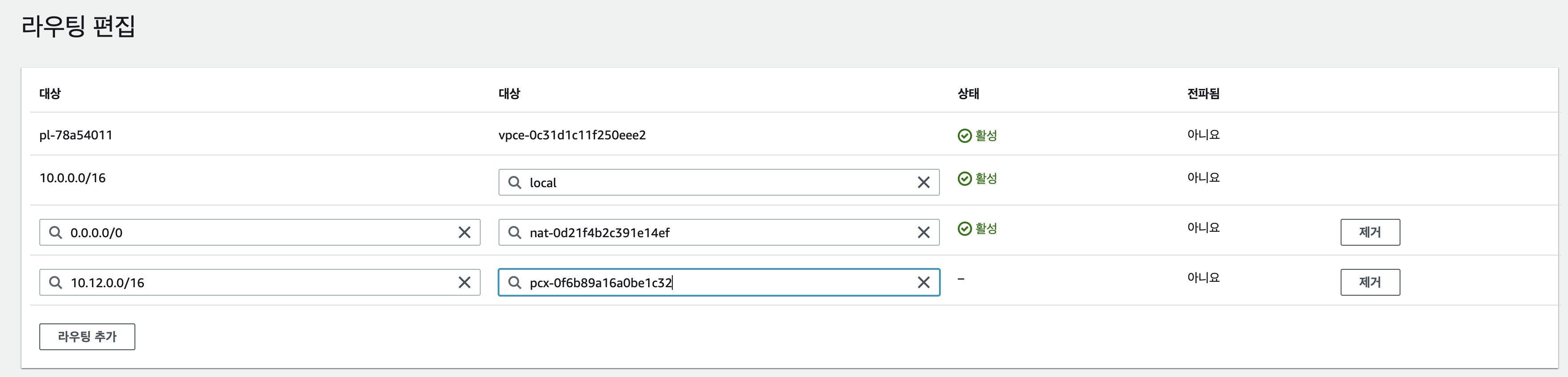
3.4.1 요청자 Private RouteTable
- 요청자는 Glue Connection을 이용하여 수신자 내 Private DB에 연결하고자 한다.
- 요청자의 Glue Connection을 생성하고자하는 VPC - Private Subnet의 RouteTable에 수신자의
VPC IPv4 CIDR (10.15.0.0/16)의 경우 VPC Peering으로 갈 수 있도록 설정 - 아래 사진에 IP는 여러번의 실습으로 인한 캡처 사진.
3.4.2 수신자 Private RouteTable
수신자의 DB가 설치되어있는 Private Subnet에 연결된 RouteTable 또한 요청자의 IPv4대역대를 VPC Peering으로 향할 수 있도록 설정

3.5 보안그룹 설정
3.5.1 수신자 DB 보안그룹
- 수신자의 DB 보안그룹에서 요청자의 IPv4 대역을 수용할 수 있도록 Open 추가
- 5432(PostgreSQL), 10.12.0.0/16 추가
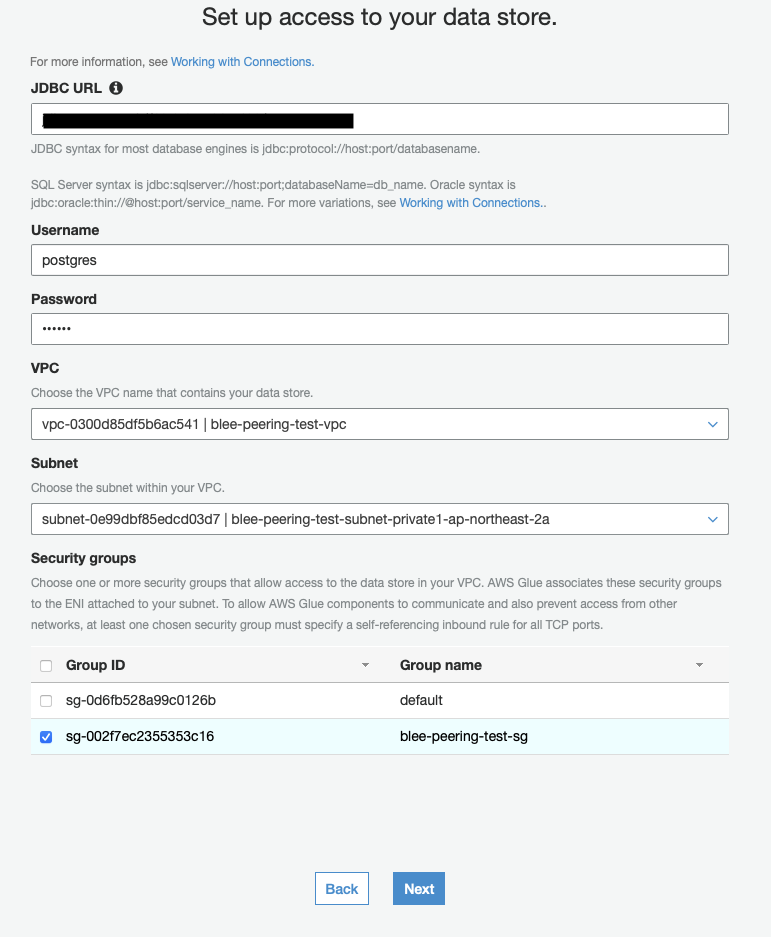
3.6 Glue Connection
3.6.1 생성
- VPC 선택 : 요청자 내 VPC Peering이 요청된 VPC
- Subnet 선택 : 위 VPC 내 라우트 테이블을 수정한 Private Subnet 으로 선택
- 해당 서브넷에서 생성되어야 VPC Peering을 활용할 수 있으므로
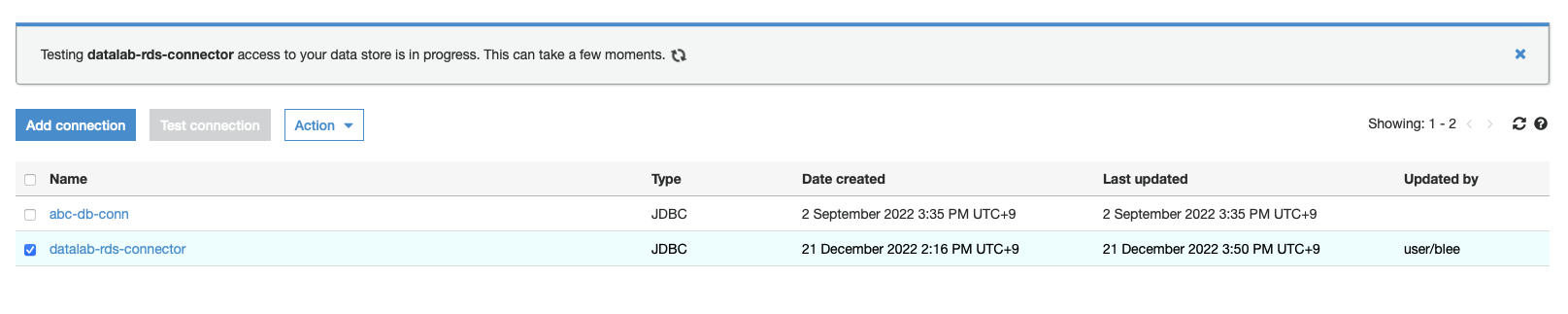
3.6.2 테스트
- 연결시도

- 성공
3.7 Glue Job 테스트
- 위에서 생성한 Glue Connection 만 잘 선택하고 나머지는 크게 설정한 것 없이 수행
import sys
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.dynamicframe import DynamicFrame
from awsglue.job import Job
import boto3
from pyspark.sql import functions as F
import json
# --------------------------------------------
# -- SparkContext 생성
# --------------------------------------------
glueContext = GlueContext(SparkContext.getOrCreate())
spark = glueContext.spark_session
spark.sparkContext.setLogLevel("ERROR")
# --------------------------------------------
# -- Overwrite setting
# --------------------------------------------
spark.conf.set("spark.sql.sources.partitionOverwriteMode","dynamic") # 없으면 전체 Partition이 overwrite 된다
hadoop_conf = glueContext._jsc.hadoopConfiguration()
hadoop_conf.set("mapreduce.fileoutputcommitter.marksuccessfuljobs", "false") # SUCCESS 폴더 생성 방지
#hadoop_conf.set("fs.s3.impl", "org.apache.hadoop.fs.s3a.S3AFileSystem") # $folder$ 폴더 생성 방지
# --------------------------------------------
# -- @params: [JOB_NAME]
# --------------------------------------------
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
bucket_name = 'bucket-name'
outputPath = f's3a://{bucket_name}/peering_test/products'
db_username = 'postgres'
db_password = 'password'
db_url = 'jdbc:postgresql://10.0.15.12:5432/postgres'
pushdownquery = "SELECT * FROM \"RETAIL\".\"products\""
df = spark.read.format("jdbc") \
.option("url",db_url) \
.option("dbtable", "\"RETAIL\".\"products\"") \
.option("user",db_username) \
.option("password",db_password) \
.option("driver","org.postgresql.Driver").load()
if df.count() > 0:
# S3로 적재
#df.show(10)
df.write.mode('overwrite').parquet(outputPath)4. 맺은말
프로젝트를 수행하기 전 테스트 겸 정리했었던 내용을 공유하고자 글을 작성하였습니다.
해당 내용이 틀렸을 수도 있고 중복되거나, 다른분들께서 작성하신 내용과 동일한 내용이 있을 수 도있지만 참고하셨으면 하는 바람에 작성을 하였습니다.
참조

Becoming the Data Engineer