인덱스란?
- 색인 = 쉽게 찾아볼 수 있도록 일정한 순서에 따라 놓은 목록
- 원하는 값을 빠르게 찾는다.
- where 등을 통해 적용
특징
- 항상 최신의 정렬상태 유지
- 하나의 데이터베이스 객체
- 데이터베이스 크기의 약 10% 저장공간 필요
인덱스 알고리즘
<용어 설명>
페이지 : 데이터가 저장되는 단위
full table scan : 순차적으로 접근 → 접근 비용 감소
언제 사용되는가?
- 적용 가능한 인덱스가 없는 경우
- 인덱스 처리 범위가 넓은 경우
- 크기가 작은 테이블에 엑세스하는 경우
BST(이진 탐색 트리) : 이진탐색 + 연결리스트

B-Tree
- 이진탐색트리의 단점을 극복
- 데이터베이스 인덱스에 적용
- 트리 높이가 같음
- 자식 노드를 2개 이상 가질 수 있음

select
- 인덱스를 통해 성능 향상
Insert
- 새로운 데이터가 들어오는데 리프 페이지가 가득차면, 루트 페이지는 비어있는 페이지를 확보하고 문제가 있는 페이지의 데이터를 공평하게 나누어 저장한다. → 페이지 분할 → DB가 느려지고 성능에 영향을 준다.
Delete
- 인덱스의 데이터를 실제로 지우지 않고 사용안함 표시를 한다.
- where절 사용 시 조회 성능은 향상되나 사용하지 않는 인덱스가 적용되었다면 불필요한 처리량이 증가한다.
- 사용 안함 표시로 페이지 낭비 및 인덱스 조각화가 심해진다.
Update
- Delete(기존 값 사용안함 표시) + Insert(변경된 값 삽입)
- where절 사용 시 조회 성능은 향상되나 사용하지 않는 인덱스가 적용되었다면 불필요한 처리량이 증가한다.
- 사용 안함 표시로 페이지 낭비 및 인덱스 조각화가 심해진다.
한줄요약 : select는 성능 향상, insert & delete & update는 성능 저하
인덱스 종류
- 클러스터링 인덱스

1. 실제 데이터와 같은 무리의 인덱스
2. Primary Key or Not Null & Unique 만족 시 자동 생성
3. 실제 데이터 자체가 정렬
4. 테이블당 1개만 존재 가능
5. 리프 페이지가 데이터 페이지- 논-클러스터링 인덱스(보조 인덱스)

1. 실제 데이터와 다른 무리의 별도의 인덱스
2. Unique Key or Unique index 직접 생성 or index 생성
3. 실제 데이터 페이지는 그대로
4. 별도의 인덱스 페이지 생성 → 추가 공간 필요
5. 테이블 당 여러 개 존재
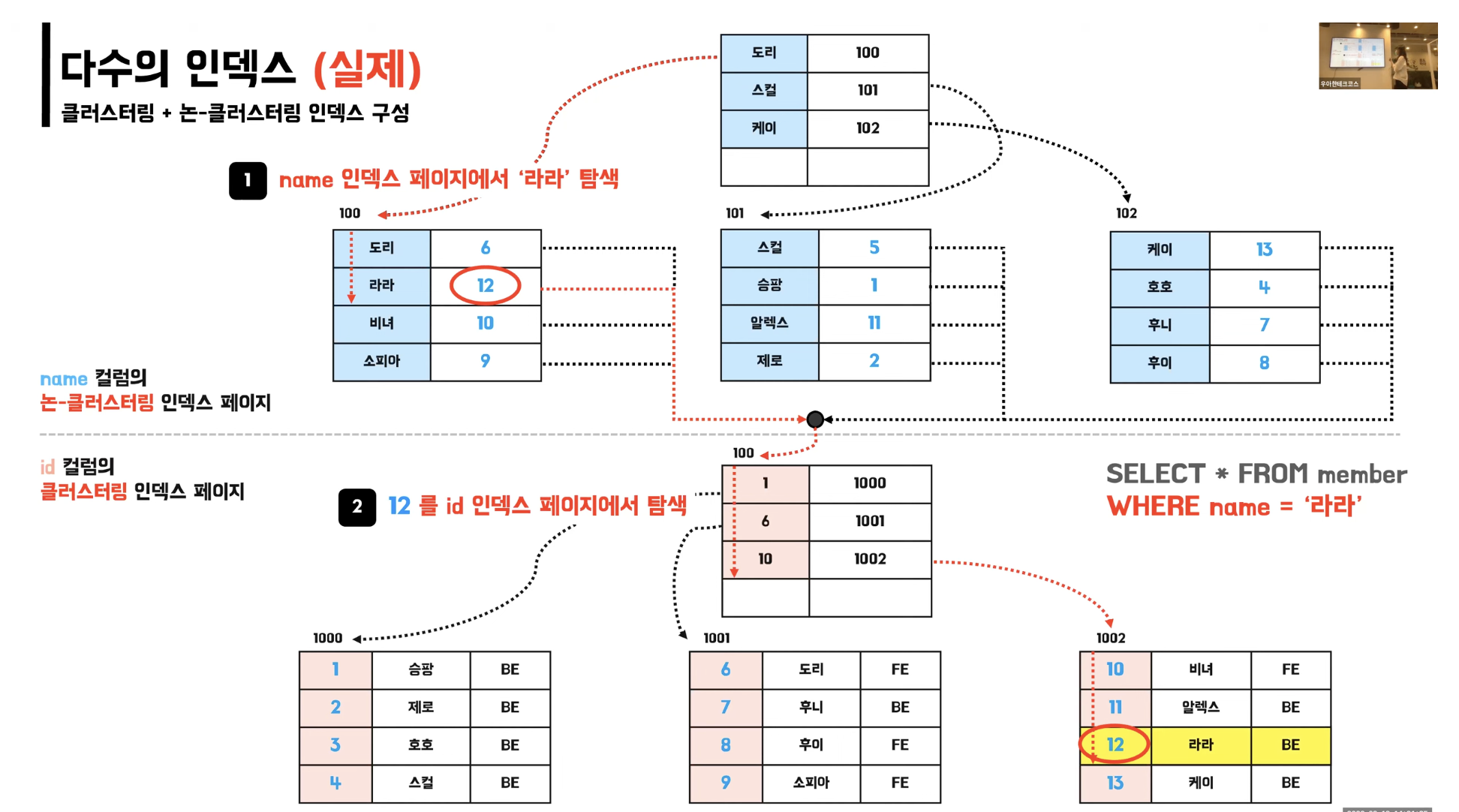
6. 리프 페이지에 실제 데이터 페이지 주소를 담고 있다.클러스터링 인덱스와 논-클러스터링 인덱스를 함께 적용한다면?

- 논-클러스터링 인덱스 페이지에서 데이터 탐색 후 찾은 데이터를 기반으로 클러스터링 인덱스 페이지에서 최종 결과 탐색
- 논 클러스터링 인덱스에서 리프 페이지에 실제 데이터 페이지 주소가 아닌 클러스터링 인덱스가 적용된 컬럼의 실제 값이 저장
어떤 칼럼에 인덱스를 적용해야할까?
- 카디널리티가 높은 것에 적용 (중복 수치가 낮은 것)
- where, join, order by 절에 자주 사용되는 컬럼 → 조건절이 있어야 인덱스가 사용
- insert, update, delete가 자주 발생하지 않는 컬럼
- 규모가 작지 않은 테이블
인덱스 사용 시 주의사항
-
잘 활용되지 않는 인덱스는 과감히 제거
-
데이터 중복도가 높은 칼럼은 인덱스 효과가 적다
-
자주 사용되더라도 insert, update, delete가 자주 일어나는지 고려
→ 조금 느린 쓰기를 감수하고 빠른 읽기를 선택하는 것도 하나의 방법
참고

시도하고 More Do하는 백엔드 개발자입니다.