데이터 둘러보기
- Pandas 불러오기
import pandas as pd- csv파일 읽어오기, 객체에 파일 넣어주기
pd.read_csv(파일위치)
df = pd.read_csv(파일위치)- 구글 마운트로 드라이브에서 파일 불러올수 있음
- colum이름을 확인하거나 몇개인지 확인
df.columns
len(df.columns)
- 데이터 info check
df.info()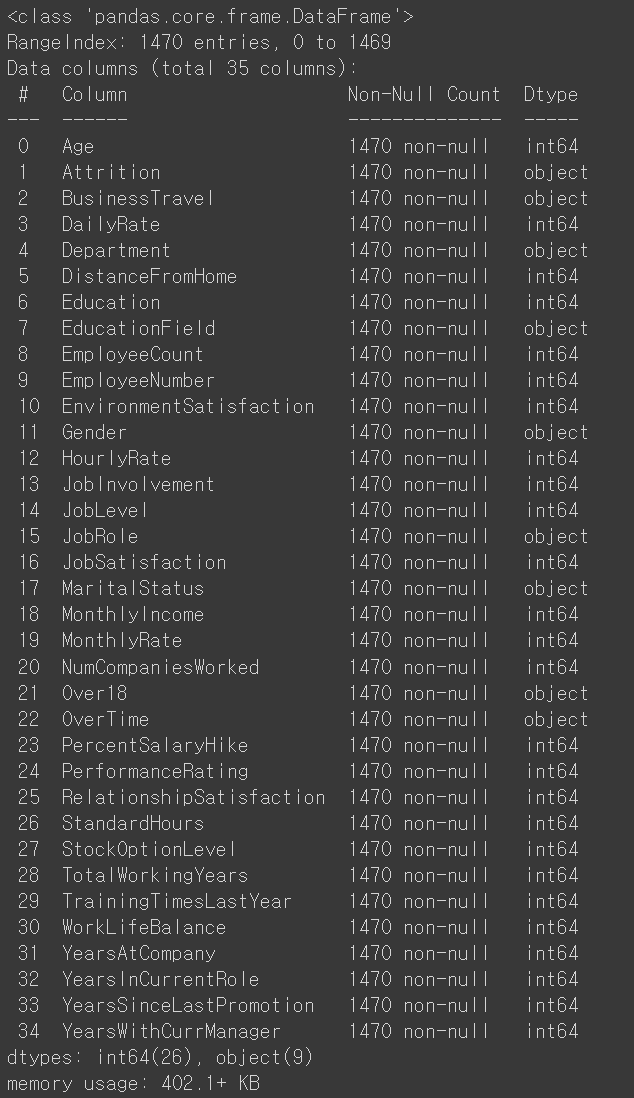 - 행, 열 갯수,컬럼이름, null값 유무, 데이터타입까지 한번에 확인 가능
- 행, 열 갯수,컬럼이름, null값 유무, 데이터타입까지 한번에 확인 가능
- 중복값 여부 확인하기
print(len(df))
print(len(df.drop_duplicates()))- 두개의 숫자가 같으면 중복값 X
- Outlier(이상치) 확인하기
df.describe().round(0).T- .T 는 column과 row를 바꿔줌 (row가 많을 때 보기 편하게)
- 표준편차가 큰 값 확인하기
- percentile default 는 .25,.5,.75
- include, exclude 도 옵션, 숫자가 아닌 값도 가져올 수 있음
- mean(평균값)은 이상치에 크게 영향 받고 median(중앙값)은 크게 영향 받지 X
- 유일값 확인하기
df.nunique- 유일값이 하나인 경우들은 분석에 필요없을 확률이 높음
- 필요없는 Column들 제거하기
df.drop(['컬럼1','컬럼2',...],axis=1,inplace=True)axis = 0은 행,axis = 1은 열inplace=True는 객체에 바로 적용시켜줌
- 문자열, 숫자열 데이터 확인하기
df.select_dtypes(include=object)
df.select_dtypes(include = 'int64')Groupby() / Pivot_table()
tmp0 = df[['Department', 'EducationField','JobRole','JobLevel', 'Attrition']].copy()
tmp0.groupby('Department').size()
#tmp0.groupby('Department')['Department'].count()도 동일한 결과
- copy해주는 이유는 데이터를 이리저리 다뤄보면서 원래 데이터에 영향이 갈 수 있기 때문
- size()는 호출된 객체의 크기 또는 길이를 반환 (Null 포함)
- count()는 집계함수 (Null 제외)
tmp0.groupby(['Department','JobRole']).size().sort_values(ascending=False)
- 여러기준으로 그룹핑 가능
sort_value를 통해 정렬 가능reset_index사용하지 않으면 시리즈 형태로 출력됨
tmp0.groupby(['Department','JobRole','JobLevel','EducationField']).size().sort_values(ascending=False).reset_index(name='Emp Count')- 괄호안에 이름을 size로 세어준 값의 컬럼이름을 정해줄 수 있음
- 이렇게 하면 데이터프레임 형태로 반환
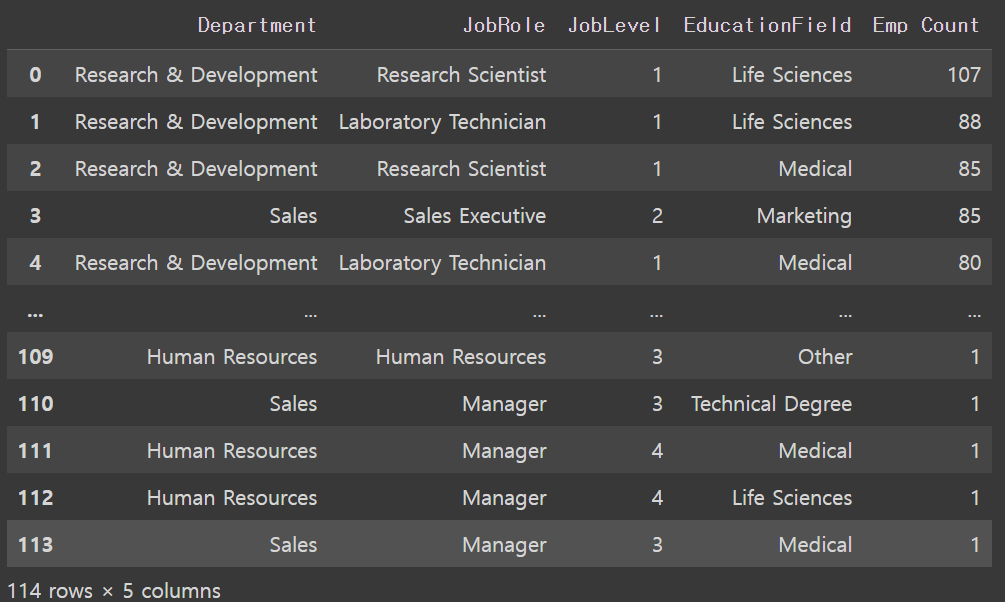
tmp1 = df[['Department','JobRole','JobLevel','Age', 'Attrition']].copy()
tmp1.groupby(['Department','JobRole'])['Age'].agg(['count','max','min'])agg를 통해 여러계산을 한번에도 가능
pt2 = pd.pivot_table(tmp1,
index=['Attrition','Department','JobRole'],
columns='JobLevel',
values='Age',
aggfunc='count',
fill_value=''
)
pt2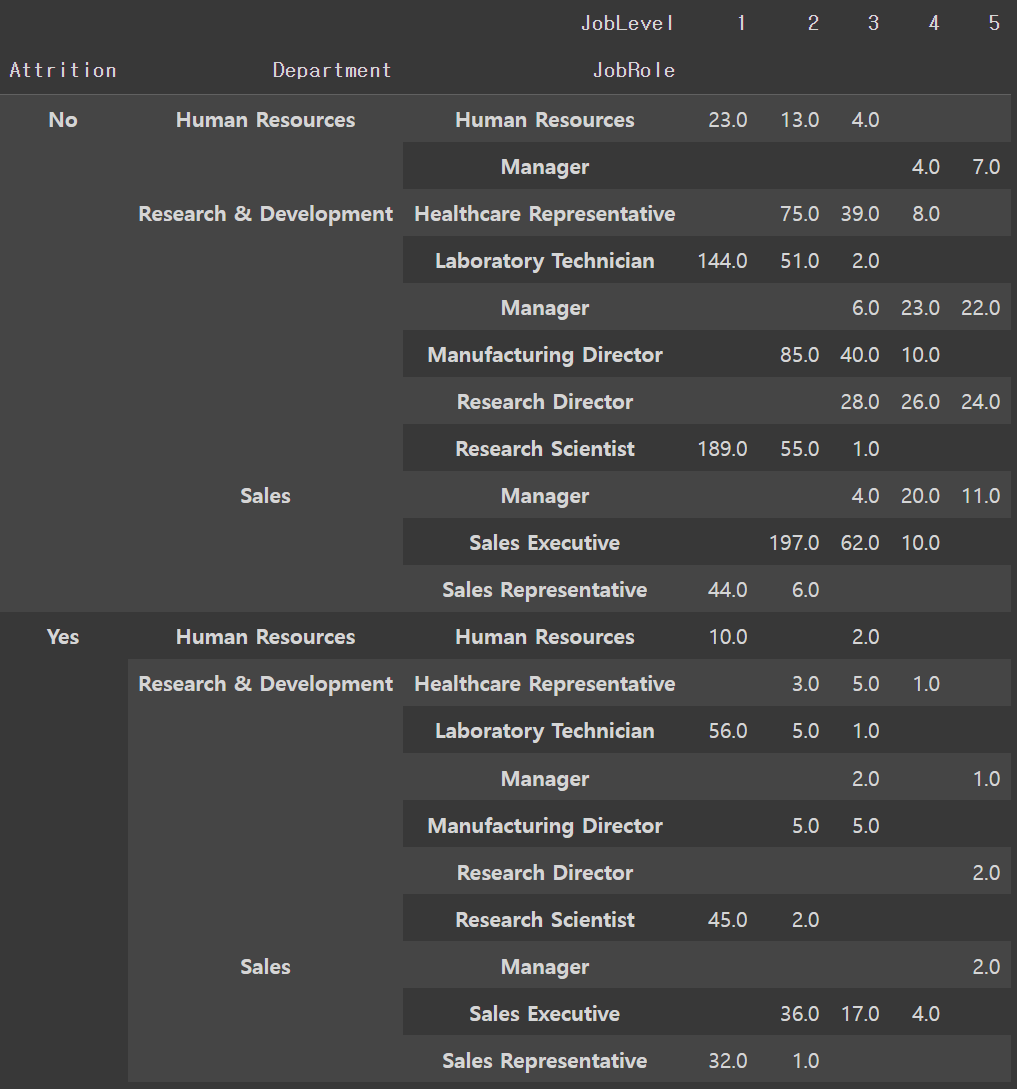
fill_value는 null 값을 채워줄 형태를 정할 수 있음
pt2.index
pt2.index.names- 인텍스를 확인해줄수 있고 위에 pt2피벗테이블은 멀티 인덱스
- 현재 인덱스는 3개 'Attrition', 'Department', 'JobRole'
- 0 : 'Attrition', 1 : 'Department', 2 : 'JobRole' 이러한 순서
- -1은 맨뒤 차례의 인덱스 임으로 'JobRole'임
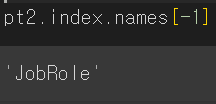
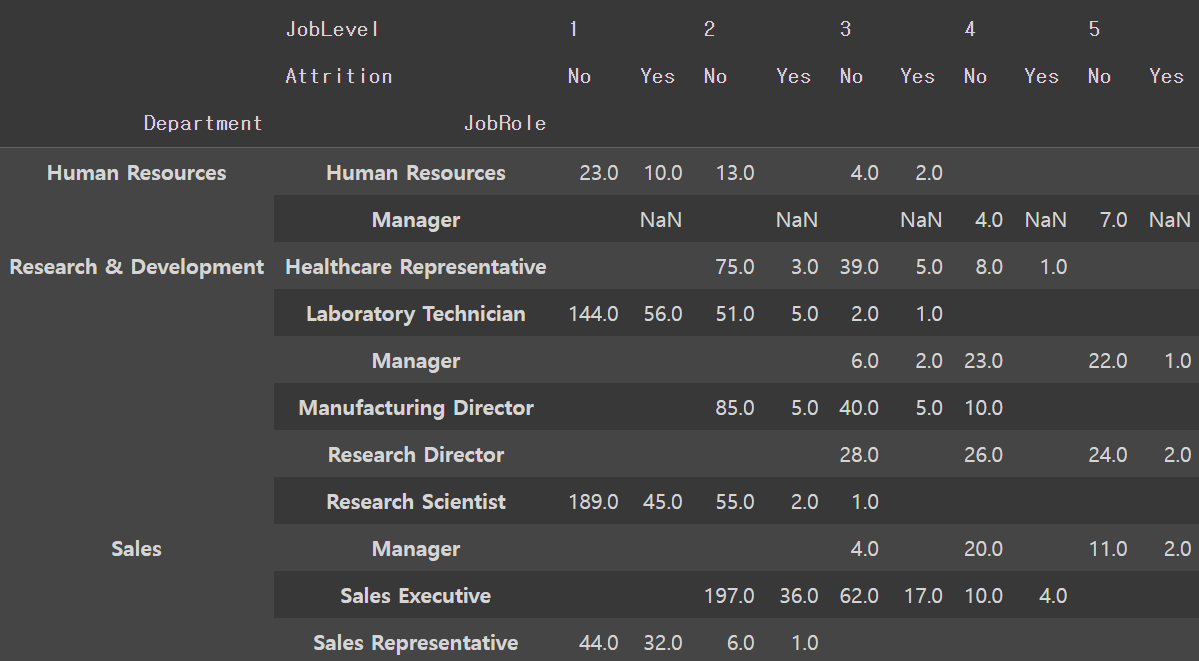
pt2.unstack(level=0)- unstack,stack은 멀티인덱스를 가지고 있는 프레임의 형태를 변형할 때 유용하다
- 위 코드의 의미는 level=0 즉 인덱스 'Attrition'을 열의 위치로 옮기겠다는 의미
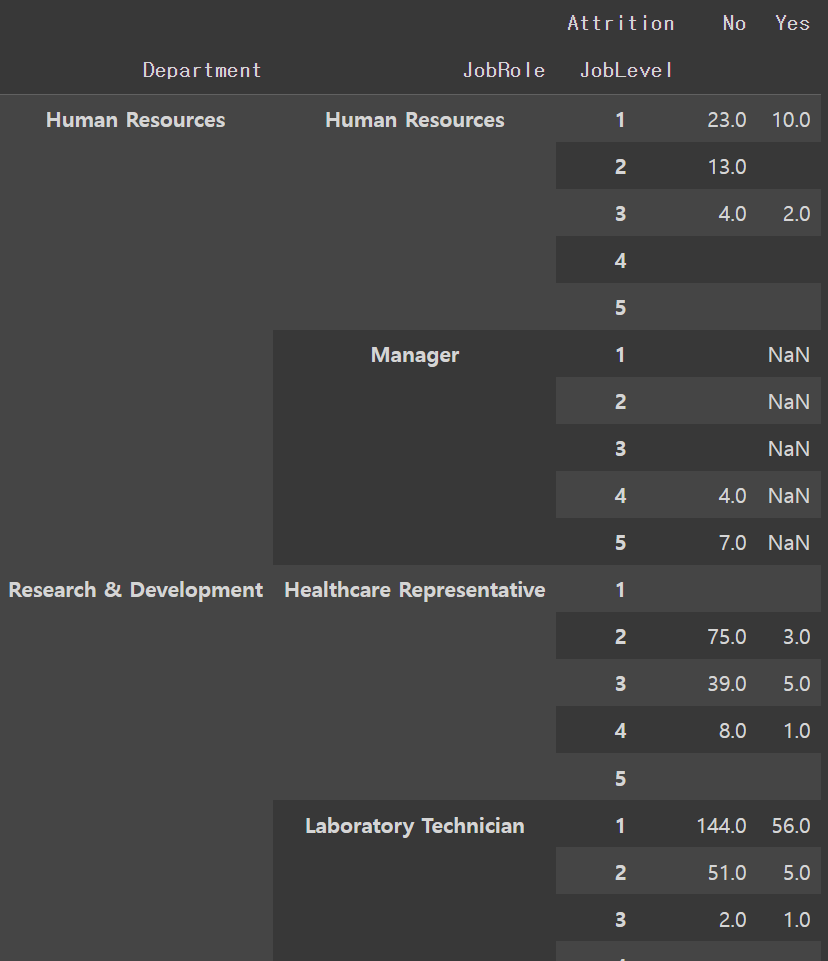
pt2.unstack(level=0).stack(level=0)stack은 반대로 열에 있는 걸 행으로 바꿔줌- 그럼 위 코드의 의미는 'JobLevel'을 행으로 옮기겠다는 의미

볼로그