
GC(Garbage Collector, Garbage Collection)
GC라 하면 Garbage Collection 또는 Garbage Collector의 약자이다. 보통은 Garbage Collection을 의미하는 것 같다.
Garbage Collection은 사용되지 않는 메모리(Garbage)를 해제하는 동작을 의미하며, 이 동작을 수행하는 주체를 Garbage Collector라고 한다.
C/C++에서 malloc 등을 통해 동적으로 메모리를 관리할 수 있듯이 Java를 포함한 여러 프로그래밍 언어에서도 동적으로 메모리를 할당하여 사용할 수 있다. 다만 C/C++에서 free를 통해 할당한 메모리를 개발자가 직접 해제해 주어야 하는 것 과 달리, 몇 몇 언어에서는 메모리 관리의 책임을 개발자로부터 덜어내었고, 사용되지 않는 메모리를 제거해 프로그램의 메모리 누수를 방지하기 위해 Garbage Collection을 도입하였다.
GC Algorithm
Java외 다른 언어의 GC에 대해 알아보지는 않았지만, GC는 Java에서 만 사용되는 기술이 아니며, Java에서도 그 version에 따라 사용하는 GC가 다르기에, 우선 GC 알고리즘에 대해 먼저 알아보겠다.
Reference Counting(참조 카운팅)
이름 그대로 객체를 참조하는 횟수를 세는 방식이다. 하나 이상의 참조가 존재하는 객체는 살아남으며, 참조가 존재하지 않는(Unreachable) 객체는 GC의 대상이 된다.
객체에 대한 참조가 생성/제거 될 때 마다 참조 횟수를 증가/감소 하여, 별도의 GC 수집 작업 없이 즉각적으로 사용된 메모리를 회수할 수 있는 장점이 있다. 하지만, 이러한 횟수 증/감을 위한 overhead가 존재하며, 객체 간 순환 참조가 발생한 경우 GC의 대상이 되지 않는 치명적인 단점이 존재한다.
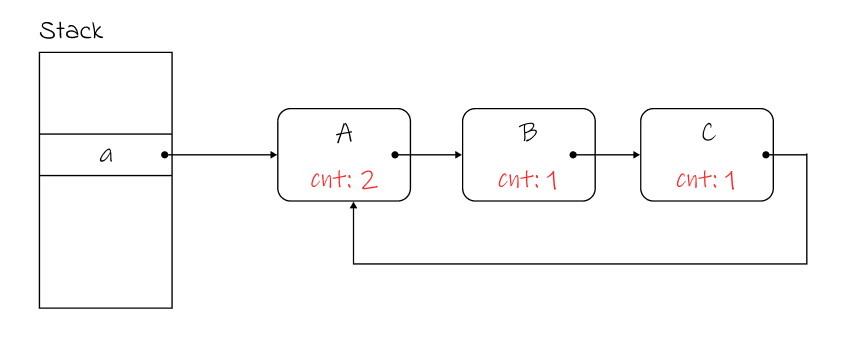
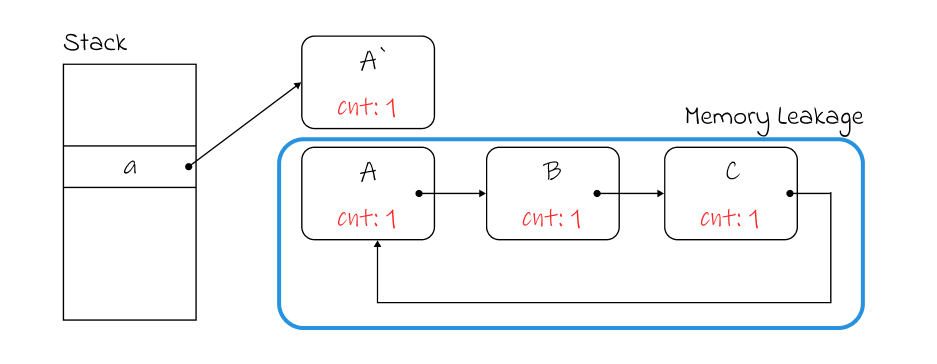
위와 같이 변수 a에 객체 A가 할당 되어있고, A→B→C→A의 순환 참조가 존재하는 경우, A의 reference count는 2가 되는데, 변수 a가 제거 되거나 참조가 변경되어 A에 대한 참조가 제거되는 경우, A, B, C 모두 count가 0이 되어 GC 대상이 되어야 하지만, A의 reference count가 0이 되지 않아 A, B, C 모두 GC의 대상이 되지 않아 메모리 누수가 발생한다.
Mark and Sweep
Mark and Sweep 알고리즘은 GC가 해야 할 두 가지 작업을 Mark와 Sweep으로 나누어 수행한다. 우선 Mark 단계에서는 참조되는 객체들을 찾아 마킹(marking)하며 GC의 대상이 될 객체인지 아닌지 판단하며, 다음 Sweep 단계에서 Mark 단계의 결과(mark bit, flag)를 통해 참조되지 않는(unreachable) 객체들을 제거한다.
이를 자세히 알아보면, 특정 root(들) 에서 시작하여 참조하고 있는 객체들을 찾으며 이때 참조되는(reachable) 객체들에 대해 reachable으로 마킹을 수행한다.
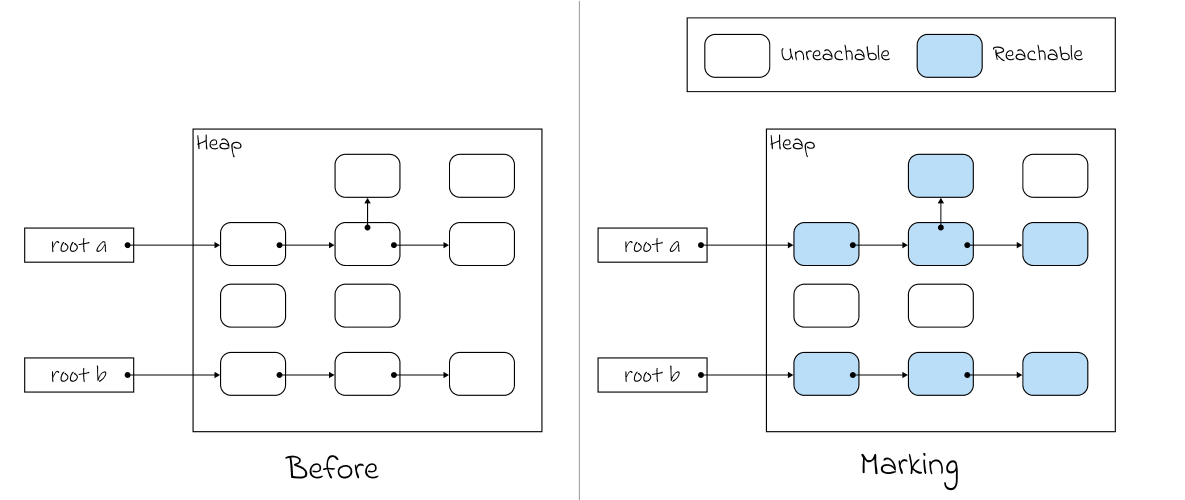
위와 같이 root들 에서 시작하여 참조하는 객체(메모리)에 대해 Reachable한 노드(객체)로 마킹을 수행하며, GC의 root가 될 수 있는 것은 stack, static 영역에 존재하는 변수 등 과 같은 heap 외의 영역에서 사용되는 변수들 정도로 생각하면 될 것 같다.
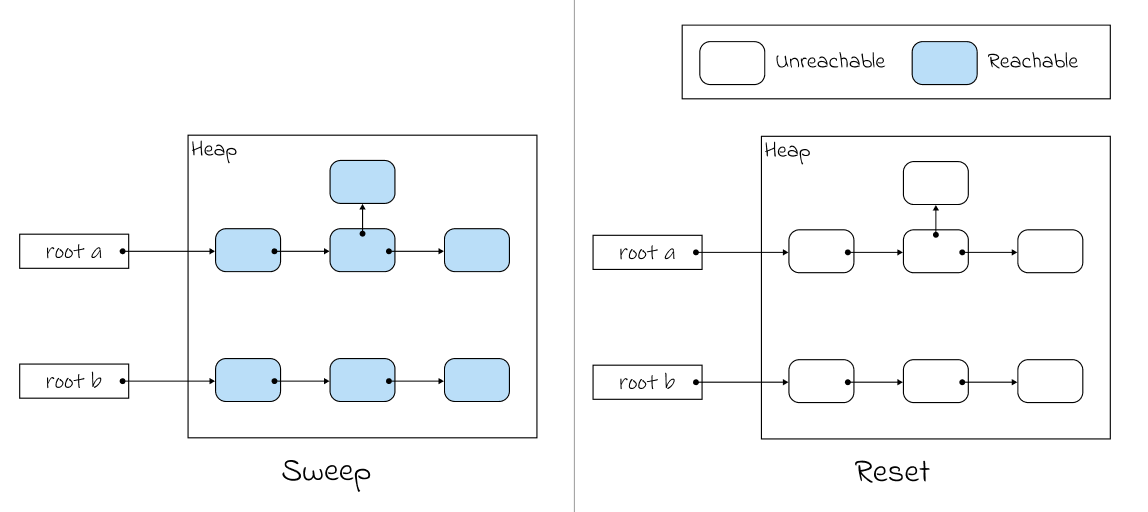
이후 Unreachable한 노드(객체)들의 메모리를 회수하는 Sweep 과정을 거치고, 마지막으로 마킹(marking)된 정보를 초기화 하는 것으로 Mark and Sweep 과정이 끝나게 된다.
Mark and Sweep 알고리즘은 Reference Counting 알고리즘과 달리, 객체에 대한 참조가 변하는 매 순간 실행되는 것이 아닌, GC를 수행하는 시점이 존재하여 특정 순간에 메모리 전체에 대한 Mark와 Sweep 과정을 거치게 된다. GC 작업을 수행하는 시점에 대한 최적화가 필요하며, Mark and Sweep 알고리즘은 Sweep 이후 메모리 단편화(Fragment)가 발생하는 문제점이 존재한다.
Mark-Sweep-Compact
Mark and Sweep에서 메모리 단편화 문제가 존재하기에, 이를 해결하기 위한 Compact 작업을 추가한 Mark-Sweep-Compact 알고리즘을 사용한다. 이는 Mark and Sweep 알고리즘과 유사하지만, 동작 이후 흩어진 메모리들을 compact 하여 한 곳에 모아 fragmentation을 해결하는 알고리즘이다.
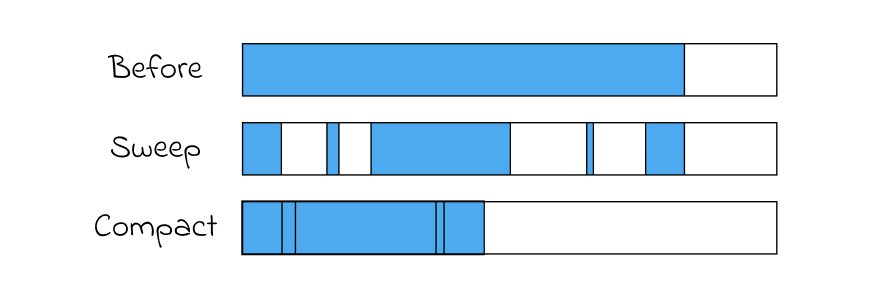
Memory fragment를 해결할 수 있으나, 새로 메모리를 할당함에 있어 작업 시간이 더 소요되어 GC 동작으로 인해 프로그램이 중단되는 시간(Stop The World)이 증가하게 된다. 이로 인해 이 compact 과정을 보다 효율적으로 수행할 수 있는 방식이 필요하며, 그 중 프로그램에서 객체들의 특성에 대한 가설을 바탕으로 이를 수행한다.
Stop The World
Java에서 GC가 수행되는 대상은 Heap 영역이다. Heap 영역은 thread-safe하지 않은 공유되는 영역으로, GC가 heap에서 작업을 정상적으로 수행하기 위해서는 다른 thread의 작업을 잠시 멈추게 되는데, 이를 Stop The World라고 부르며, 프로그램이 정상적으로 동작하지 않는 이 시간을 줄이기 위해 다양한 GC가 연구되고 GC 튜닝을 한다.
Weak generational hypothesis
많은 GC가 사용하는 알고리즘의 바탕이 되는 가설로, 프로그램 내 객체들의 특성에 대한 가설이다. 프로그램에서 대부분의 객체는 짧은 시간 동안 만 살아있다는 것을 통해 아래 두 가설을 세웠다.
- 대부분의 객체는 금방 Unreachable(참조를 잃은, 접근 불가능) 상태가 된다.
- 오래된 객체에서 젊은 객체로의 참조는 매우 적게 존재한다.
이를 바탕으로 Java는 메모리 구조(Heap 영역)를 Young, 그리고 Old Generation으로 나누었다.

Young Generation은 Eden과 Survivor(S0, S1)으로 구성되어 있고, Old Generation과 PermGen로 나눌 수 있다. Java 7까지 JVM의 Heap 영역에 Old 영역 외 Permanent 영역이 있었으나, Java 8 부터 JVM이 아닌 Native 영역으로 넘어가 OS에 의해 관리되게 되었다.
GC 동작 과정
GC의 동작은 크게 minor GC와 major GC로 나눌 수 있으며, minor GC의 대략적인 동작은 아래와 같은 과정을 거친다
- 새로운 객체가
Eden영역에 생성된다. - Eden 영역의 사용량이 일정 수치를 넘어가거나 특정 상황이 되면 GC가 trigger 된다.
- Eden 영역과 Survivor(S0 또는 S1 중 1개) 영역 내 참조되지 않는 객체를 제거한다 -
Scavenge - 위 과정에서 살아남은 객체를 Survivor(위 과정에서 scan 하지 않은) 영역으로 옮긴다. 이 과정에서 살아남은 객체들에 대해 나이(GC 동작에서 살아남은 횟수)를 기록한다.
- 이와 같은 과정 때문에 survivor 영역을 from / to 영역이라 부른다.
- Eden 영역과 3에서 scan한 survivor 영역을 비운다.
위 과정을 Copy & Scanvenge라고 부르며, 작은 메모리 영역을 관리함에 있어서 효율적인 방법이다. Old & Young generation의 비율은 -XX:NewRatio option을 통해 설정할 수 있는데, default 값은 2로, old에 비해 young generation의 비율이 작으며, young generation 내 eden과 suvivor의 비율은 -XX:SurvivorRatio option을 통해 설정할 수 있다.(default : 8)
다만 예외적으로, 새로운 객체가 생성될 때, 객체의 크기가 커 survivor 영역에 배치될 수 없을 경우 객체는 Eden 영역이 아닌 Old Generation에서 생성되며, Old Generation의 객체가 Young Generation의 객체를 참조하는 경우 scan 작업의 효율을 위해 이를 기록하는 Card Table이 존재한다.
위 과정을 수행하며 특정 나이가 지난 객체는 Old Generation으로 이동하게 되며, Old Generation에 수행되는 GC를 Major GC라 한다. Major GC에는 위에서 기술한 Mark and Sweep(Mark-Sweep-Compact)를 사용하며, minor GC에 비해 느리기에 프로그램의 성능에 큰 영향을 준다.
