Java의 TreeSet은 TreeMap을 통해 구현되어 있다.
어쩌다 보니 TreeSet의 요소를 모두 조회하는 시간복잡도가 궁금해 졌다.
조회는 O(N)이 아닌가 생각했지만, 정말 O(N)이 맞는지 고민해 보았다. Heap 자료구조에서 모든 요소를 정렬된 상태로 조회할 때 시간 복잡도는 O(N logN)이 아닌가? 또 Java의 HashMap 구조를 생각해 보았을 때, 전체 요소를 조회하기 위해서는 bucket을 모두 조회 해야 하고, bucket 내부 요소들을 또 조회해야 한다. 배열로 구현된 bucket의 크기(Capacity)는 요소의 수 size에 따라 달라지며, bucket 내부 요소들 또한 내부 요소 수에 따라 LinkedList 또는 Tree 구조로 존재한다. 이들을 전부 조회하는 시간복잡도를 정확히 알 수 있을까?
라는 고민에서 시작된 TreeSet 구조 알아보기이다.
Java Set
Java는 Set이라는 자료 구조를 지원한다. Set 자료구조는 List, Map과 함께 대표적인 자료구조 중 하나로, 순서가 없으며 데이터의 중복을 허용하지 않는 특징이 있다.
각 자료구조의 특징은 아래와 같다
| 순서 | 중복 허용 | |
|---|---|---|
| List | O | O |
| Set | X | X |
| Map | X | Key: X / Value : O |
Java에서 Set 구조를 구현한 구현체는 HashSet, LinkedHashSet, TreeSet 등이 있으며 LinkedHashSet은 입력 순서를, TreeSet은 정렬된 순서를 보장하도록 구현되어 있다. 그 중 TreeSet에 대해서 조금 더 알아보도록 하겠다.
Java TreeSet
TreeSet은 이름부터 Tree를 기반으로 구현된 것으로 보인다.
Java의 TreeSet class를 보면 아래와 같이 설명하고 있다.
“A NavigableSet implementation based on TreeMap. The elements are ordered using their natural ordering, or by a Comparator provided at set creation time, depending on which constructor is used.
This implementation provides guaranteed log(n) time cost for the basic operations (add, remove and contains).”
또한, TreeSet class의 선언부는 아래와 같다.

가장 중요한 부분은 “NavigableSet implementation based on TreeMap” 이다.
TreeMap을 기반으로 한 NavigableSet의 구현 class란 뜻인데, 그럼 TreeMap과 NavigableSet에 대해서 더 알아보겠다.
NavigableSet
NavigableSet은 SortedSet을 extends한 interface로, 탐색을 위한 몇 가지 method를 추가한 interface라고 생각하면 될 것 같다. 아래는 Java의 설명이다.
“A SortedSet extended with navigation methods reporting closest matches for given search targets. Methods lower, floor, ceiling, and higher return elements repectively less than, … “
Collection Framework의 NavigableSet의 상속 구조는 아래와 같다.
Iterable > Collection > Set > SortedSet > NavigableSet
SortedSet은 first(), last() method를 제공하고, NavigableSet은 lower(), floor(), ceiling() 등 탐색을 위한 method를 제공한다.
NavigableSet은 보다 편하게 자료구조를 탐색할 수 있도록 한 interface라고 생각하면 될 것 같다. 다음으로는 TreeMap에 대해서 알아보겠다.
TreeMap
NavigableSet에 대해서 알아보았는데, TreeSet의 설명에 따르면, TreeSet은 TreeMap을 기반으로 구현한 NavigableSet이다. 분명 Set 자료구조를 알아보고 있었는데, Map이 등장했다.
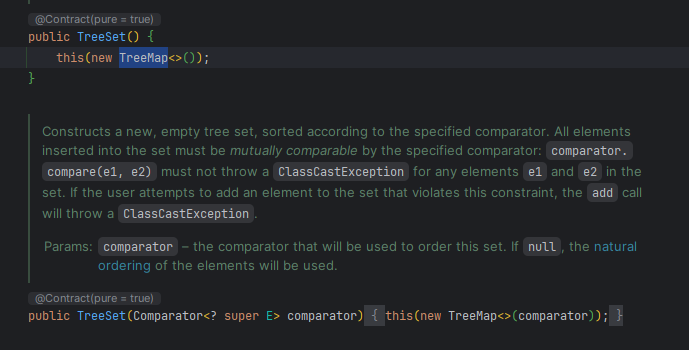
우선, TreeSet의 코드를 살펴보면, 여러 Constructor가 존재하는데, 모든 Constructor는 결국 하나의 Constructor로 이어지며 이는 아래와 같다.
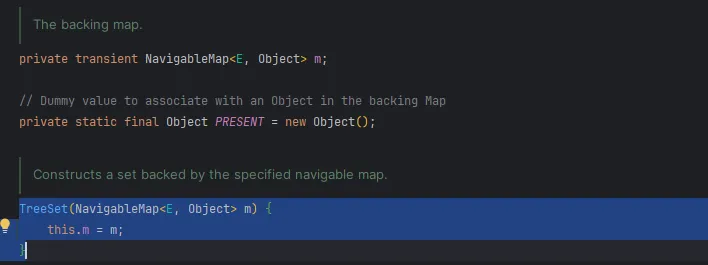
NavigableMap을 기본으로 사용함을 알 수 있으며, 해당 Constructor를 호출하는 Constructor 들을 살펴보면, 아래와 같이 TreeMap을 Argument로 전달함을 확인할 수 있다.

NavigableMap
TreeSet이 TreeMap을 통해서 구현된 것을 확인할 수 있었다. TreeMap을 알아보기 전에 TreeSet의 backing map에 사용된 NavigableMap interface 부터 알아보자.
Java에 따르면
“A SortedMap extended with navigation methods returning closest matches for given search targets. Methods lowerEntry, floorEntry, and higherEntry retuun Map. … “
앞서 살펴본 NavigableSet과 유사한 탐색 기능을 추가한 interface임을 알 수 있다.
따라서, TreeMap은 정렬된 상태를 유지하는 SortedMap과 탐색을 위한 NavigableMap을 구현한 class임을 알 수 있다.
TreeMap 내부 구조
처음 의문의 시작인 TreeSet의 모든 요소를 조회하는 시간 복잡도에서 시작해서, TreeSet이 TreeMap을 통해 구현된 것 까지 알 수 있게 되었다. 이제, TreeMap의 내부 구조를 살펴보도록 하겠다.
우선 Java에 따르면,
“A Red-Black tree based NavigableMap implementation. This map is sorted according to the natural ordering of its keys, or by a Comparator provided at map creation time, depending on which constructor is used.”
TreeMap은 RB tree를 기반으로 구현되었다고 설명하고 있다.
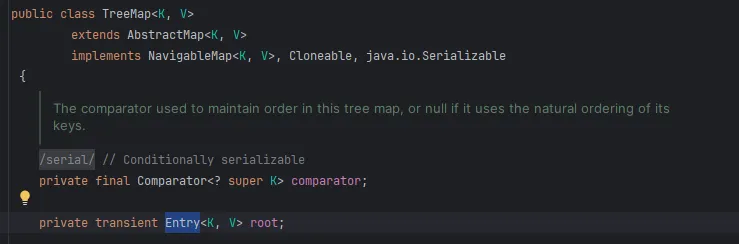
TreeMap의 내부에는 Entry 라는 Class의 root가 있음을 확인할 수 있다. 해당 Entry는 Map.Entry를 구현한 것으로 TreeMap class에서 확인할 수 있으며, Key-Value 구조의 Map의 요소를 관리하기 위한 것 이라고 생각하면 될 것 같다.
또한, TreeMap class에서 rotateLeft(), rotateRight(), fixAfterInsertion(), setColor() 등 이름만 보아도 RB Tree를 관리하기 위한 여러 method를 정의해 둔 것을 확인할 수 있어 TreeMap은 RB Tree를 통해 구현되어 있음을 확인할 수 있다.
결국 TreeSet의 전체 요소를 조회하는 것은 Tree의 요소를 조회하는 것이므로, 시간 복잡도는 O(N)임을 알게 되었다.
정확한 조회를 위한 과정은 iterator와 관련이 있는 것 같아 추후에 더 알아보도록 하겠다. Collection이 Iterable을 상속한 구조임은 처음 알았다.

Backing Map 사용 이유
TreeSet이 TreeMap 기반으로 구현 된 것을 확인하였고, TreeMap의 내부 구조까지 살펴보았다. 하지만, Java는 왜 TreeSet 자료구조를 구현하기 위해 Backing Map을 선택하였을지 의문이 들었다. TreeMap에서 RB tree를 구현해 두었기에 이를 재활용하는 것은 이해가 되지만, Key-Value 형태의 Map을 사용함으로 인해 낭비되는 메모리 용량이 있지 않나? 라는 생각이 들었다.
이를 확인하기 위해 TreeSet의 add() method를 확인해 보았다.

Backing map의 m.put(key, value) method에 Key는 추가 하려는 요소이지만, Value에 PRESENT 라는 수상한 이름을 확인할 수 있다.
이는 TreeSet 내부에서 정의된 값으로, 아래와 같이 확인할 수 있다

Map에 활용하기 위한 Dummy 값임을 명시하고 있는데, 아마 Key-Value 구조로 인해 메모리가 낭비되지만, 동일한 Dummy 값을 Value에 활용하여 추가적인 메모리 사용을 최소화하고자 하지 않았을 까 싶다.
결론은, 재사용과 최적화
