
2장_자바 데이터 타입, 변수 그리고 배열
목표
자바의 데이터 타입, 변수 그리고 배열을 사용하는 방법을 익힙니다.
목차
- 프리미티브 타입과 레퍼런스 타입
- 프리미티브 타입별 특징
- 리터럴
- 변수와 변수 선언 및 초기화
- 표현식, 문장, 블록
- 변수의 스코프와 라이프타임
- 프리미티브 타입 변환 및 프로모션
- 래퍼 클래스와 박싱
- 업다운 캐스팅과 다형성
- 배열과 배열 생성
- 타입 추론과 var
1. 프리미티브 타입과 레퍼런스 타입
프리미티브 타입
Primitive Type, 원시 타입, 기본 타입, 기본 유형
자바는 정적 타입을 사용하는 언어이기 때문에, 변수를 사용하기 전에 먼저 타입을 선언해야 한다.
int gear = 1; // int가 프리미티브 타입초기화할 때 new 연산자를 쓰지 않는다.
언어에 내장된 특수 데이터이며, 클래스에서 생성된 객체가 아니다.
byte / short
signed int / unsigned int
signed long / unsigned long
float / double / boolean / char
레퍼런스 타입
Reference type, 레퍼런스 유형, 참조 타입, 참조 유형
레퍼런스 소유자, 객체 접근 수단
레퍼런스 타입은 객체에 대한 레퍼런스를 보유한, 객체에 접근할 수있는 수단이다. 메모리 위치 자체는 개발자와 관련이 없다. 모든 참조 유형은 java.lang.Object 타입의 서브 클래스이다.
레퍼런스 타입의 종류는 아래와 같다.
| 레퍼런스 타입 | 설명 |
|---|---|
| Annotation | 메타 데이터(데이터에 대한 데이터)를 프로그램 요소와 연결한다. |
| Array | 동일 유형의 데이터 요소를 고정 크기로 저장하는 데이터 구조이다. |
| Class | 실제 세계에서 무언가를 모델링하며, 필드와 메소드로 구성된다. 상속, 다형성 및 캡슐화를 위해 고안되었다. |
| Enumeration | 선택 항목의 집합을 나타내는 개체에 대한 참조다. |
| Interface | 퍼블릭 API를 제공하며 클래스에 의해 구현된다. |
타입 간 비교
| 레퍼런스 타입 | 프리미티브 타입 |
|---|---|
| 개수 무제한 | 개수 8가지만 |
| 데이터에 대한 레퍼런스를 저장한다 | 프리미티브 타입이 보유한 실제 데이터를 저장한다 |
| 레퍼런스 타입이 다른 레퍼런스 타입에 할당되면 둘 다 동일한 객체를 가리킨다 | 프리미티브의 값이 동일한 유형의 다른 변수에 할당되면 복사본이 만들어진다 |
| 객체가 메소드에 전달되면 호출된 메소드는 전달된 객체의 내용을 변경할 수 있지만 객체의 주소는 변경할 수 없다 | 프리미티브가 메소드에 전달되면 프리미티브의 복사본만 전달된다. 호출된 메소드는 원래 기존 값에 접근할 수 없으므로 오리지널 값은 변경할 수 없다. 대신 복사된 값을 변경할 수 있다. |
타입별 할당 및 복사 예시
public class AssignmentExample {
public static void main(String[] args) {
// 프리미티브 타입 예시
int num1 = 52;
int num2 = num1;
num2 = 10;
// 프리미티브 타입의 할당은 복사본을 만들기 때문에,
// 할당 이후 num2를 다른 값으로 할당하면 서로 다른 값이 출력된다
System.out.println(num1); // 52가 출력됨
System.out.println(num2); // 10이 출력됨
// 레퍼런스 타입 예시
int[] arr1 = { 1, 2, 3 };
int[] arr2 = arr1;
// 레퍼런스 타입의 할당은 동일한 객체 주소를 가리키므로,
// 할당 이후 주소를 출력해보면 같은 주소값이 나온다.
System.out.println(arr1); // [I@5aaa6d82
System.out.println(arr2); // [I@5aaa6d82
// 또한, 동일한 객체를 가리키므로
// 인덱스 0의 값을 바꾸면 arr1와 arr2 인덱스 0의 값이 모두 바뀐다.
arr2[0] = -9;
System.out.println(arr1[0]); // -9가 출력됨
System.out.println(arr2[0]); // -9가 출력됨
}
}Refs:
2. 프리미티브 타입별 특징
타입 테이블
자바는 8개의 원시 타입을 갖고 있다. (자바 8 이전까지)
| 자료형 | 크기 (bytes) | 값 범위 | 디폴트 값 | 비고 |
|---|---|---|---|---|
| byte | 1 byte | -128 ~ 127 | 0 | |
| short | 2 | -32,768 ~ 32,767 | 0 | |
| signed int | 4 | -2^31 ~ 2^31 - 1 | 0 | -2,147,483,648 ~ 2,147,483,647 |
| unsigned int | 4 | 0 ~ 2^32 - 1 | 0 | 자바 8부터 사용 가능 |
| signed long | 8 | -2^63 ~ 2^63 - 1 | 0L | -9,223,372,036,854,775,808 ~ 9,223,372,036,854,775,807 |
| unsigned long | 8 | 0 ~ 2^64 - 1 | 0L | 자바 8부터 사용 가능 |
| float | 4 | single-precision 32-bit IEEE 754 부동 소수점 | 0.0f | 6-7자리 십진수를 저장 |
| double | 8 | double-precision 64-bit IEEE 754 부동 소수점 | 0.0d | 15자리 십진수를 저장 |
| boolean | 1 bit | false, true | false | |
| char | 2 | '\u0000' ~ '\uffff' (or 0 ~ 65,535) | '\u0000' | 단일 문자 / 문자 또는 ASCII 값을 저장 |
String
자바는 특별히 java.lang.String 클래스를 통해 문자열을 지원해준다. 문자열을 큰 따옴표로 묶으면 자동으로 새 String 객체가 생성된다.
String s = "this is a string";
중요한 사실은, 문자열 객체는 변경이 불가능하다. 즉, 일단 생성되면 해당 값을 변경할 수 없다. String의 경우 디폴트 값은 null 이다.
디폴트 값
선언되었지만 초기화되지 않은 필드(예, 인스턴스 필드)는 컴파일러에 의해 적절한 기본값으로 설정된다. 일반적으로 기본값은 데이터 유형에 따라 0 또는 null 이다. 그러므로 필드를 선언할 때 항상 값을 할당할 필요는 없다. 그러나 이러한 기본값에 의존하는 것은 좋지 않은 프로그래밍 스타일이다.
참고로,
null은 아무것도 참조하지 않는다.만약
null인 참조 변수에 대한 메소드를 호출하거나 객체에 점(.) 연산자를 사용하면java.lang.NullPointerException이 발생한다.private static int MAX_LENGTH = 20; ... String theme = null; // theme의 값이 null인데 점 연산자를 사용했기 때문에, NPE(NullPointerException)이 발생한다. if (theme.length() > MAX_LENGTH) { ... }
지역 변수는 약간 다르다. 컴파일러는 초기화되지 않은 지역 변수에 기본값을 할당하지 않는다. 선언된 지역 변수를 초기화 할 수 없는 경우, 사용하기 전에 값을 할당해야 한다. 초기화되지 않은 지역 변수에 접근하면 컴파일 에러가 발생한다.
Refs :
3. 리터럴
식에 의해 계산된 결과 값이 아니라, 직접(directly) 표현된 값을 의미한다.
literals are represented directly in your code without requiring computation
( Oracle Java Docs )
비슷한 표현으로, 소스코드에 하드코딩된 값(직접 적어준 값) 을 의미하며, 변수 초기화에 많이 사용된다.
bool b = true; // 리터럴: true
int num1 = 100; // 리터럴: 100
int num2 = 0x11; // 리터럴: 0x11
int num3 = null; // 리터럴: null
float num4 = 1.2f; // 리터럴: 1.2f
double num5 = 0.1111; // 리터럴: 0.1111
string str = "HelloJava"; // 리터럴: "HelloJava"이때, 리터럴로 초기화한 변수가 가리키는 값은 변할 수 있지만, 프로그램이 시작하고 끝날 때까지, =의 오른쪽 값은 변하지 않는다. 그리고 이는 리터럴의 본래 의미인, 소스 코드의 고정 값의 표현이라는 의미에 부합한다.
잠깐, 변수가 가리키는 값이 변경될 수 있다고 했다. 이는 변수라는 용어가 말그대로 값이 "변하는 수"를 가리키기 때문에 어색하지 않다.
하지만, 한 번 초기화해놓으면, 변수가 가리키는 값이 절대 변하지 않는 경우가 있다. 그리고 이렇게 대입한 변수의 값이 절대 변하지 않는 것을 가리켜 상수라고 한다. (상수는 리터럴과 다른 개념이니 주의하자!)
다시 리터럴로 돌아와서, null도, true도, 100도 모두 리터럴이 될 수 있다.
정수 리터럴
Integer Literals
정수 유형 byte, short, int 및 long의 값은 int 리터럴에서 만들 수 있고, int 범위를 초과하는 long 유형의 값은 long 리터럴에서 만들 수 있다.(long 리터럴 = int 리터럴 + L)
- 10진수(Decimal, Base 10): 숫자 0에서 9까지의 숫자로 구성된다.
- 16진수(Hexadecimal, Base 16): 숫자 0에서 9까지의 숫자와 A에서 F까지의 문자로 구성된다.
- 2진수(Binary, Base 2): 숫자 0과 1로 구성된다. (Java SE 7 이후로 바이너리 리터럴을 작성할 수 있다.)
// 숫자 26을 표현하는 3가지 리터럴 방식
int decVal = 26; // 10진수
int hexVal = 0x1a; // 16진수
int binVal = 0b11010; // 2진수부동 소수점 리터럴
Floating-Point Literals
부동 소수점 리터럴은 F 또는 f로 끝난다. 그렇지 않으면 double이고, double은 마지막에 D 또는 d를 작성할 수 있다.
다시 말하면, 부동 소수점 유형 (float 및 double)은 E 또는 e (과학적 표기법의 경우), F 또는 f (32 비트 부동 리터럴) 및 D 또는 d (64 비트 이중 리터럴)를 사용하여 표현할 수 있다.
float f1 = 123.4f;
double d1 = 123.4;
double d2 = 1.234e2; // d1과 동일하나, 과학적 표기법으로 작성한 경우다.문자 및 문자열 리터럴
Character and String Literals
char 및 String 유형의 리터럴에는 모든 유니 코드 (UTF-16) 문자가 포함될 수 있다. 편집기 및 파일 시스템에서 허용하는 경우 이러한 문자를 코드에서 직접 사용할 수 있다.
문자 리터럴에는 항상 '작은 따옴표' 를 사용하고, 문자열 리터럴에는 "큰 따옴표" 를 사용해야 한다.
자바는 이들 리터럴에 대한 몇 가지 특수 이스케이프 시퀀스를 지원한다.
\b (백 스페이스)
\t (탭)
\n (줄 바꿈)
\f (양식 피드)
\r (캐리지 리턴)
\"(큰 따옴표)
\'(작은 따옴표)
\\ (백 슬래시)
null 리터럴은 모든 레퍼런스 타입에서 사용할 수 있다. 프로그램에서 null은 일부 객체를 사용할 수 없음을 나타내는 마커로 자주 사용된다.
그리고 추가적으로 클래스 리터럴(Class Literal)도 있으니 참고하자.
Refs :
4. 변수와 변수 선언 및 초기화
필드와 변수, 멤버
자바에서는 필드와 변수 두 가지 용어를 모두 사용(혼용..)하기 때문에 문서를 참조할 때면 매우 혼란스럽다. 자바 공식 문서에서 얘기하는 필드와 변수에 대해 살펴보자.
필드와 변수를 논의 할 때 다음과 같은 일반 지침을 사용한다.
일반적인 필드(지역 변수 및 매개 변수 제외)에 대해 이야기하는 경우, 간단히 필드라고 말할 수 있다.이야기가 모든 것에 해당하는 경우, 이 경우에는 변수라고 할 수 있다.
문맥이 구별을 요구하는 경우 특정 용어 (정적 필드, 지역 변수 등)를 적절하게 사용한다.때때로 멤버라는 용어도 사용한다.
이는 집단과 구성원의 관점으로 이해해야 한다.
클래스를 하나의 집단이라 할 때, 필드 또는 메소드는 이 집단에 속한 구성원이다.
이 구성원들을 각각 멤버라고 부를 수 있다.
자바는 다음의 변수들을 정의하고 있다. (여기에서는 설명이 모든 경우에 해당하므로 필드가 아닌 변수를 사용하였다.)
인스턴스 변수
Instance Variable, Non-Static Fields, 비정적 필드, 객체 필드
객체는 static 키워드 없이 선언된 필드에 개별 상태를 저장한다. 비정적 필드는 해당 값이 클래스의 각 인스턴스(객체)에 고유하기 때문에 인스턴스 변수라고 한다. 한 자전거의 currentSpeed는 다른 자전거의 currentSpeed와 독립적이다.
클래스 변수
Class Variables, Static Fields, 정적 필드
static 한정자로 선언된 모든 필드다. 클래스의 인스턴스가 몇 개가 있든지 상관없이 컴파일러는 이 변수의 복사본을 단 하나만 알고 있다. 예를 들어 A 종류 자전거의 기어 개수(필드)는 모든 인스턴스에 동일하게 적용되기 때문에 static으로 표시할 수 있다.
static int numGears = 6;또한 키워드 final 을 추가하여 기어 수가 변경되지 않도록 나타낼 수 있다.
지역 변수
Local Variables, 로컬 변수
객체가 필드에 상태를 저장하는 방법과 유사하게, 메소드는 종종 지역 변수에 임시 상태를 저장한다. 지역 변수 선언 문은 필드 선언과 유사한데, 지역 변수라고 지정하는 특별한 키워드가 없기 때문이다.
int count = 0;지역 변수인지의 여부는 오로지 변수가 선언된 위치, 변수가 메소드의 중괄호 내부({ }) 에 위치해 있는지에 달려 있다.
따라서, 지역 변수는 선언된 메소드 내부에서만 볼 수 있다. 클래스의 다른 곳에서는 이 변수에 접근할 수 없다.
매개변수
Parameter, 파라미터
무조건 마주하게 되는 main 메소드의 시그니처로 매개변수를 살펴보자.
public static void main (String [] args) // args가 매개변수 args 변수는 이 메소드에 대한 매개 변수다. 중요한 점은, 매개 변수가 항상 필드가 아닌 변수 로 분류된다는 점이다.
변수 선언 및 초기화
아래 예시는 변수 선언과 변수 초기화하는 방법을 간단하지만 구체적으로 보여주고 있다.
class Ref {
public int r;
}
class Main {
public static void main(String[] args) {
// 프리미티브 타입 변수 선언 및 변수 초기화
int value = 10;
// 레퍼런스 타입 변수 선언 및 변수 초기화
Ref r = new Ref();
}
}Refs:
5. 표현식, 문장, 블록
연산자
Operators
여기에서는 자세히 다루지 않는다. 여기에서는 그냥 연산자는 + 나 = 등이 있고, 익스프레션 작성시 사용되는 것 정도로 알고 넘어가자. 자세한 내용을 배우고 싶다면 여기, 종류별 연산자를 삐르게 확인하고 싶다면 여기를 참조하자.
표현식
Expressions, 익스프레션, 식
변수(a, b, ..), 연산자(=, ..) 또는 메소드 호출로 구성된다. 문장(Statements)을 이루는 핵심 구성 요소다. 아래 예시를 살펴보자.
// 주석에 적혀있는 것이 각 줄의 표현식이다.
int cadence = 0; // cadence = 0
anArray[0] = 100; // anArray[0] = 100
System.out.println("Element 1 at index 0: " + anArray[0]);
// "Element 1 at index 0: " + anArray[0]
int result = 1 + 2; // result = 1 + 2
if (value1 == value2) // value1 == value2
System.out.println("value1 == value2"); // "value1 == value2"문장
Statements, 문
문장은 완전한 실행 단위를 형성한다. 다음 유형의 표현식은 세미콜론(;) 으로 표현식을 종료하여 명령문으로 만들 수 있다. 블록으로 그룹화되는 특징이 있다.
- 할당 익스프레션 (Assignment expressions)
- ++ 또는-사용 (Any use of
++or--) - 메소드 호출 (Method invocations)
- 객체 생성 표현식 (Object creation expressions)
아래는 익스프레션 문장(Expresstion Statements)의 예시들이다.
// 할당 익스프레션 문장
aValue = 8933.234;
// 증가 문장
aValue++;
// 메소드 호출 문장
System.out.println("Hello World!");
// 객체 생성 문장
Bicycle myBike = new Bicycle();익스프레션 문장 외에도 선언 문(declaration statements)과 제어 흐름 문(control flow statements)이 있다. 선언문은 아래와 같이 변수를 선언한다.
// 선언 문
double aValue = 8933.234;블록(Blocks)
블록은 중괄호({ }) 사이에, 0개 또는 그 이상의 명령문 그룹을 의미한다. 단일 명령문(single statement)이 허용되는 곳이라면 어디에서나 사용할 수 있다.
class BlockDemo {
public static void main(String[] args) {
boolean condition = true;
if (condition) { // 블록 1 시작
System.out.println("Condition is true.");
} // 블록 1 종료
else { // 블록 2 시작
System.out.println("Condition is false.");
} // 블록 2 종료
}
}Reference: Oracle Java Docs
6. 변수의 스코프와 라이프타임
변수 스코프
변수를 사용할 수 있는 또는 변수가 유효한 범위(프로그램 세그먼트)를 말한다.
클래스 스코프
Class Scope, 클래스 범위
아래, 클래스 스코프를 가진 변수 amount는 다음과 같은 특징을 갖는다.
-
private접근 제어자를 가짐 -
클래스 내부에 있는 모든 메소드(
method1,method2)의 외부에 위치함
이러한 특징을 가지는 변수들은, 클래스 내부 어디에서나 사용가능하지만, 외부에서는 사용할 수 없다(private하기 때문에). 아래 예시에서는, 클래스 내부 메소드(method1 과 method2) 어디에서나 amount를 사용할 수 있다.
이때,
private을 사용하지 않으면, 전체 패키지에서amount에 접근할 수 있다.
public class ClassScopeExample {
private Integer amount = 0;
public void method1() {
amount++;
}
public void method2() {
Integer anotherAmount = amount + 4;
}
}메소드 스코프
Method Scope, 메소드 범위
변수가 메소드 내에서 선언되면 메소드 범위가 있으며 동일한 메소드 내에서만 유효하다. 아래 메소드 범위 예시를 살펴보자.
public class MethodScopeExample {
public void method1() {
Integer area = 2;
}
public void method2() {
// 컴파일 에러가 발생한다, 변수 `area`를 찾을 수 없다.
area = area + 2;
}
}method1 내부에서 변수 area를 만들었다. 따라서 method1 내부에선 어디서나 area를 사용할 수 있다. 하지만 다른 곳에선 이 변수를 사용할 수 없다(이것이 method2에서 컴파일 에러가 발생하는 이유다.).
루프 스코프
Loop Scope, 루프 범위, 반복문 범위
루프 내에서 변수를 선언하면 루프 범위가 생기고, 루프 내에서만 이 변수를 사용할 수 있다. 아래 루프 스코프의 예시를 살펴보자.
public class LoopScopeExample {
List<String> listOfNames = Arrays.asList("Joe", "Susan", "Amy");
public void iterationOfNames() {
String allNames = "";
for (String name : listOfNames) {
allNames = allNames + " " + name;
}
// 컴파일 에러가 발생한다, 변수 `name`를 찾을 수 없다.
String lastNameUsed = name;
}
}iterationOfNames 메소드에서 변수 name이 사용되었다. 이 변수는 루프 내부에서만 사용할 수 있으며 외부에서는 사용할 수 없다.
괄호 스코프
Bracket Scope, 괄호 범위, 브래킷 범위
중괄호({ }) 를 사용하여 범위를 추가적으로 정의할 수 있다.
public class BracketScopeExample {
public void mathOperationExample() {
Integer sum = 0;
{
Integer number = 2;
sum = sum + number;
}
// 컴파일 에러가 발생한다, 변수 `number`를 찾을 수 없다.
number++;
}
}변수 number은 중괄호 내에서만 유효하다.
Reference: Variable Scope in Java
스코프와 변수 섀도잉
Scopes and Variable Shadowing
클래스 변수가 있고 같은 이름의 메소드 변수를 선언한다고 가정하자.
public class NestedScopesExample {
String title = "Baeldung";
public void printTitle() {
System.out.println(title); // #1
String title = "John Doe"; // #2
System.out.println(title); // #3
}
}-
#1: 처음
title을 출력하면Baeldung이 출력된다. -
#2: 그런 다음 동일한 이름의 메소드 변수
title를 선언하고 여기에 "John Doe"값을 할당한다. -
#3: 여기서 메소드 변수
title은, 클래스 변수title보다 우선한다(override). 그래서 두 번째로John Doe가 출력된다.이를 변수 섀도잉이라고하는데, 위와 같은 방법은 좋은 방법이 아니다.
클래스 변수에 액세스하려면
this접두사를 사용하는 것이 좋다. (this.title처럼)
변수의 라이프타임
| 지역 변수와 매개변수 | 인스턴스 변수 | |
|---|---|---|
| 위치 | 스택 프레임 | 힙 |
| 수명 | 메소드 실행 동안만 | 객체 생성 시점부터 가비지 컬렉션 시점까지 |
| 스코프 | 메소드 범위 | private 하다면, 클래스 범위public 하다면, 전체 패키지 범위 |
7. 프리미티브 타입 변환 및 프로모션
확장 변환
Widening Primitive Conversions
더 작은 기본 형식에서, 큰 형식으로 변환할 때를 의미하며, 이때 특별한 표기법을 사용하지 않아도 된다. 변환 시 정수 값에서는 정보 손실이 발생하지 않는다 (소수와 그외의 경우는 다르다). 아래 예시에서는 long이 int보다 크기 때문에 특별한 표기법을 사용하지 않아도 된다.
int myInt = 127;
long myLong = myInt;축소 변환
Narrowing Primitive Conversion
현재 변수 유형보다 더 큰 값을 할당받는 경우에 발생한다. 일부 바이트를 삭제해야 하기 때문에 정보 손실이 있을 수 있다.
축소 변환을 할 경우, 캐스트를 사용해서 축소에 동의한다는 것을 명시적으로 표현해야 한다.
byte myByte = (byte) myInt; // int는 byte보다 크므로 명시적으로 캐스팅해야 한다.아래는 보다 구체적인 축소 변환 사례를 보여준다.
public class NarrowingPrimitiveConversion {
public static void main(String[] args) {
float fmin = Float.NEGATIVE_INFINITY;
float fmax = Float.POSITIVE_INFINITY;
// float -> char -> int
System.out.println("char: " + (int) (char) fmin + ".." + (int) (char) fmax);
// float -> int
System.out.println("int: " + (int) fmin + ".." + (int) fmax);
// float -> long
System.out.println("long: " + (long) fmin + ".." + (long) fmax);
// float -> byte
System.out.println("byte: " + (byte) fmin + ".." + (byte) fmax);
// float -> short
System.out.println("short: " + (short) fmin + ".." + (short) fmax);
}
}
// 출력 결과
// char: 0..65535
// int: -2147483648..2147483647
// long: -9223372036854775808..9223372036854775807
// byte: 0..-1
// short: 0..-1char, int 및 long의 경우, 각 유형의 최소 및 최대 표현 가능 값이 생성됨을 알 수 있다.
한편, byte 및 short에 대한 결과는 숫자 값의 부호 및 크기에 대한 정보를 잃고, 정밀도도 잃어버린다는 걸 볼 수 있다.
숫자 프로모션
이진 연산(binary operation)을 실행하려면 두 피연산자가 크기 측면에서 호환되어야 한다. 그리고 그런 점에서 자바는 아래 규칙을 적용시키고 있다.
-
피연산자 중 하나가
double이면 다른 피연산자는double로 승격된다. -
그렇지 않고, 피연산자 중 하나가
float이면 다른 피연산자는float으로 승격된다. -
그렇지 않고, 피연산자 중 하나가
long이면 다른 하나는long으로 승격된다. -
그렇지 않으면 둘 다
int로 간주된다.
아래 예시를 보자.
byte op1 = 4;
byte op2 = 5;
byte myResultingByte = (byte) (op1 + op2);두 피연산자가 모두 int로 승격되었으며, 타입에 맞도록 결과는 다시 byte로 다운캐스트 되어야 한다.
박싱 및 언박싱 변환은 본래 프리미티브 타입 변환에 속하나, 내용이 너무 길어져 래퍼 클래스와 함께 아래 주제로 따로 빼놓았다.
Refs:
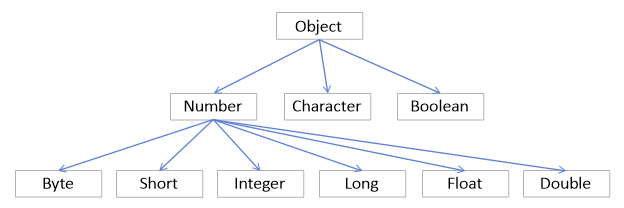
8. 래퍼 클래스와 박싱
래퍼 클래스
Wrapper Class, 기본 타입 전용 클래스
자바의 8가지 기본 타입에는 각각 전용 클래스가 있다. 기본 타입을, 해당 클래스의 객체로 래핑하기 때문에 이들을 가리켜 래퍼 클래스라고 한다. 래퍼 클래스는 java.lang 패키지의 일부이다.
사용 이유
기본적으로 제네릭 클래스는 객체(Object)에서만 작동하며 기본 요소를 지원하지 않는다. 따라서 제네릭 클래스로 작업하려면 원시 값을 래퍼 객체로 변환해야 한다.
예를 들어, 자바 컬렉션 프레임워크(Java Collection Framework)는 오직 객체들로만 작동한다. 오래 전(Java 5 이전, 거의 15 년 전)에는 오토박싱(autoboxing)이 없었고, Integer 컬렉션으로 예를 들면 단순한 add(5)조차 호출할 수 없었다. 그 당시에는 이러한 기본 값을 래퍼 클래스로 수동으로 변환하고 컬렉션에 저장해야 했다.
오늘날에는 오토박싱을 사용하면 ArrayList.add(101)을 쉽게 수행할 수 있다. 왜냐하면 내부적으로 자바가 valueOf() 메소드를 사용해 ArrayList에 저장하기 전에 기본 값을 정수로 변환해주기 때문이다.
래퍼 클래스 종류
| 프리미티브 타입 | 래퍼 클래스 | 생성자 인수 |
|---|---|---|
| boolean | Boolean | boolean or String |
| byte | Byte | byte or String |
| char | Character | char |
| int | Integer | int or String |
| float | Float | float, double or String |
| double | Double | double or String |
| long | Long | long or String |
| short | Short | short or String |
위의 표에 따르면, 아래와 같이 래퍼 클래스 객체를 생성하고 출력할 수 있다.
// .. 메인 메소드 생략 ..
Integer intObj = new Integer (25);
Integer intObj2 = new Integer ("25");
System.out.println(intObj); // 25가 출력됨
System.out.println(intObj2); // 25가 출력됨하지만 자바 9부터는 래퍼 클래스의 생성자 지원이 중단되었다. 실제로 vscode에서 사용하려고 하면, 아래 사진에서처럼 노란 줄로 Deprecated 경고 표시가 나타난다. 따라서 생성자 대신 사진 아래에서처럼 팩토리 메소드를 사용하는 것이 좋다.

팩토리 메소드 사용
Integer anotherObject = Integer.valueOf(1);valueOf() 메소드는 지정된 int 값을 나타내는 인스턴스를 반환한다. 이때, 반환 값은 캐시 값이므로 꽤 효율적이다. 항상 -128에서 127 사이의 값을 캐시하지만, 이 범위 밖의 다른 값도 캐시할 수 있다. 만약 String을 Integer로 변환해야 한다면, String이 래퍼 클래스가 아니기 때문에 parseInt() 메소드를 사용해야 한다(아래 String 변환 항목에서도 확인할 수 있다.).
Integer intObj3 = Integer.parseInt("333"); 반면, 래퍼 객체에서 원시 값으로 변환하려면 intValue(), doubleValue() 등과 같은 해당 메소드를 사용할 수 있다.
int val = object.intValue();박싱 변환
Boxing Conversion
기본 타입의 표현식을 레퍼런스 타입의 표현식으로 변환하는 것을 말한다. 자바에는 각각의 프리미티브 유형에 대한 래퍼 클래스(Wrapper Class)를 가지고 있다. 자바 5 이후로 자동으로, 프리미티브 요소에서 객체로, 또는 그 반대로 변환하는 기능이 추가되었다. -> 오토박싱(autoboxing)
// 기본 타입 int를 레퍼런스 타입 Integer로 자동 변환(자바 5 이후 가능)
Integer myIntegerReference = myInt;
Integer val = 2; // 역시 autoboxing
// 위와 같은 코드이고, 내부적으로는 아래처럼 변환을 위해 valueOf 메소드를 사용한다.
Integer value = Integer.valueOf(2);
// 컬렉션의 add 메소드 호출시 autoboxing 사용
List<Integer> list = new ArrayList<>();
list.add(1); // autoboxing오토박싱이 매우 편하기는 하지만, 때때로 사용하지 말아야 하는 경우도 있다. (예를 들어, 루프 내부)
언박싱 변환
Unboxing Conversion
레퍼런스 타입의 표현식을 기본 타입의 표현식으로 변환하는 것을 말한다. 박싱 변환과 마찬가지로, 자바 5 이후로 자동 변환 기능이 추가되었다. 객체를 기본 타입을 예상하는 메소드에 전달하거나, 기본 타입 변수에 할당할 때 언박싱이 자동으로 수행된다.
Integer object = new Integer(1);
// 레퍼런스 타입 Integer를 기본 타입 int로 자동 변환(자바 5 이후 가능)
int val1 = getSquareValue(object); // 객체를 메소드에 전달할 때 unboxing
int val2 = object; // 객체를 기본 타입 변수에 할당할 때 unboxing
public static int getSquareValue(int i) {
return i*i;
}만약 기본 값이나 래퍼 객체를 받아들이는 메소드를 작성하면 두 값을 모두 전달할 수 있다. 자바는 컨텍스트에 따라 올바른 타입을 전달한다.
String 변환
모든 기본 유형은 toString() 메소드를 재정의하는 래퍼 클래스를 통해 String으로 변환될 수 있다.
String myString = myIntegerReference.toString();기본 유형으로 돌아 가야하는 경우, 해당 래퍼 클래스에서 정의한 parse 메소드를 사용해야 한다.
byte myNewByte = Byte.parseByte(myString);
short myNewShort = Short.parseShort(myString);
int myNewInt = Integer.parseInt(myString);
long myNewLong = Long.parseLong(myString);
float myNewFloat = Float.parseFloat(myString);
double myNewDouble = Double.parseDouble(myString);boolean myNewBoolean = Boolean.parseBoolean(myString);유일한 예외는 문자 클래스(Character Class)이다. 문자열이 단일 문자로 만들어졌음을 고려하면, String 클래스의 charAt() 메소드를 사용할 수 있다.
char myNewChar = myString.charAt(0);Refs:
- 래퍼클래스 그림 및 설명: w3resource
- Wrapper Classes in Java
- Java Primitive Conversions
9. 업다운 캐스팅과 다형성
레퍼런스 타입 변환 소개
상속 관계 변환
레퍼런스 타입의 변환은 기본 타입의 변환과 다르다. 레퍼런스 변수는 객체를 참조할, 뿐 객체 자체를 메모리 위치에 저장하고 있지 않다. 레퍼런스 변수를 캐스팅하면 참조하는 객체에 영향을 주지 않고, 다른 방식으로이 개체에 레이블을 지정하여 작업할 기회를 확대하거나 축소한다.(이는 상속 관계이기에 가능하다.)
업 캐스팅(Upcasting)은 이 객체에 사용할 수있는 메소드와 속성 목록을 좁히고, 다운 캐스팅(Downcasting)은 이를 확장시킨다.
업 캐스팅
Upcasting, 슈퍼 클래스로 캐스팅
서브 클래스에서 슈퍼 클래스로 캐스팅하는 것을 업 캐스팅이라고합니다. 일반적으로 업 캐스팅은 컴파일러에 의해 묵시적으로 수행된다. 업 캐스팅은 상속과도 밀접한 관련이 있다. 상속에서 보다 구체적인 유형의 서브클래스를 참조하려면 레퍼런스 변수를 사용하는 것이 일반적이다. 그리고 이것을 할 때 묵시적으로 업 캐스팅이 발생한다. 아래 Animal과 Cat 클래스를 보며 업 캐스팅을 살펴보자.
public class Animal {
public void eat() {
System.out.println("동물이 먹습니다.");
}
}public class Cat extends Animal {
public void eat() {
System.out.println("고양이가 먹습니다.");
}
public void meow() {
System.out.println("야옹~!");
}
}이제 Cat 클래스의 객체를 만들고 Cat 유형의 참조 변수에 할당할 수 있다.
Cat cat = new Cat();또한 Animal 유형의 참조 변수에 cat을 할당할 수도 있다.
Animal animal = cat; // 암시적 캐스팅
animal = (Animal) cat; // 명시적 캐스팅(컴파일러가 알고 있기 때문에 굳이 이렇게 작성할 필요는 없다.)
System.out.println(cat); // Cat@73a28541
System.out.println(animal); // Cat@73a28541참조는 선언된 유형의 모든 하위 유형을 참조 할 수 있다. 업 캐스팅을 사용하여 Cat 인스턴스에 사용할 수있는 메소드의 수를 제한했지만, 인스턴스 자체는 변경하지 않았다. Cat 객체는 Cat 객체로 남아 있지만 meow()를 호출하면 컴파일러 에러가 발생한다.
animal.meow();
// animal.meow(); The method meow() is undefined for the type Animal다형성
Polymorphic
위의 업 캐스팅 덕분에 이제 다형성을 활용할 수 있게 되었다. 아래 예시들은 다형성이 무엇인지 기본적인 그림을 그려준다. 먼저, Animal의 또 다른 하위 클래스인 Dog 클래스를 정의하자.
public class Dog extends Animal {
public void eat() {
System.out.println("개가 먹습니다.");
}
} 이번엔, 고양이나 개에게 먹이를 주기 위해 AnimalFeeder를 정의해보자.
public class AnimalFeeder {
public void feed(List<Animal> animals) {
animals.forEach(animal -> {
animal.eat();
});
}
}그런 다음, animals 목록에 고양이와 개의 객체를 각각 추가해주자. 특정 유형의 개체를 animals 목록에 추가할 때 암시적 업 캐스팅이 발생할 것이다. 그리고 지금까지의 코드와 아래 코드를 이해했다면, 다형성의 그림이 조금은 그려질 것이다.
List<Animal> animals = new ArrayList<>();
animals.add(new Cat());
animals.add(new Dog());
new AnimalFeeder().feed(animals);
// 출력 결과
// Animal의 eat 메소드에서, Cat과 Dog의 eat 메소드가 오버라이딩한 결과가 나타남
고양이가 먹습니다.
개가 먹습니다.여기에서는 분명 다른 종류의 동물들(Cat과 Dog)을 생성, 추가해주었다. 하지만 메소드 안에서 Cat와 Dog는 모두 업 캐스팅되기 때문에 이들은 동물(Animal) 유형이 가지는 작업만 가능해진다(즉, Animal의 메소드인 eat만 사용할 수 있음). 이런 상황에서 Cat과 Dog을 두고 다형성으로 이해할 수 있다(사실 모든 객체 타입은 Object를 상속하기 때문에 모든 자바 객체가 다형성의 특징을 가진다). 왜 다형성을 사용하는지는 추후에 논의해보도록 하자. 어쨌든 컴파일러는 다형성에 대해 불평하지 않는다..
다운 캐스팅
Downcasting, 서브 클래스로 캐스팅
Animal 유형의 변수가 Cat 클래스의 메소드(meow())를 호출하려면 어떻게 해야 할까? 슈퍼 클래스에서 하위 클래스로 캐스팅할 수 있는데, 이를 다운 캐스팅이라고 한다. 아래 코드를 살펴보자.
Animal animal = new Cat();animal 변수가 Cat의 인스턴스를 참조하고 있다. 그리고 이제 Cat의 meow() 메소드를 호출하려고 한다. 이때, 다음과 같은 코드를 사용하면 된다.
((Cat) animal).meow(); // "야옹~!" 출력, 참고로 (Cat)을 `캐스트 연산자`라고 한다.이전 AnimalFeeder 예제를 meow() 메소드를 활용하는 방식으로 조금 변경해보자.
public class AnimalFeeder {
public void feed(List<Animal> animals) {
animals.forEach(animal -> {
animal.eat();
if (animal instanceof Cat) {
((Cat) animal).meow();
}
});
}
}
// 출력 결과
// 고양이가 먹습니다.
// 야옹~!
// 개가 먹습니다.ClassCastException
위에 예시에서 instanceof 연산자를 사용하였다. 사실 이 연산자를 사용하지 않아도, 컴파일러는 불평하지 않을 것이다. 하지만 런타임에서는.. 아래와 같은 에러가 발생할 것이다.
java.lang.ClassCastException: class Dog cannot be cast to class CatClassCastException 은 우리가 다운 캐스트하는 유형이 실제 객체의 유형과 일치하지 않으면 런타임에 항상 발생한다. 따라서 코드를 올바르게 컴파일하려면 두 유형이 동일한 상속 트리에 있어야 한다.
cast 메소드
Class 메소드를 사용하여 객체를 캐스팅할 수도 있다.
public void whenDowncastToCatWithCastMethod_thenMeowIsCalled() {
Animal animal = new Cat();
if (Cat.class.isInstance(animal)) { // isInstance()가 isinstanceof 연산자를 대신
Cat cat = Cat.class.cast(animal); // cast()가 캐스트 연산자를 대신
cat.meow();
}
}추후에 알아볼 제네릭 유형과 함께 cast()및 isInstance() 메소드를 사용하는 것이 일반적이다.
10. 배열과 배열 생성
배열
배열은 단일 종류의, 고정된 개수의 값을 보유하는 컨테이너다. 정의에 따라 배열의 길이는 배열이 생성될 때 설정되며, 생성 후에는 길이가 고정된다.
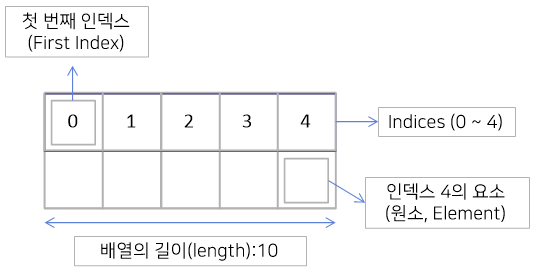
배열의 각 항목을 요소라고 하고, 각 요소는 숫자 인덱스로 접근할 수 있다.
인덱스는 0부터 시작한다.
예를 들어 5번째 요소는 인덱스 4에서 접근할 수 있다.
배열 레퍼런스 변수 선언
배열의 타입은 보통 type[]으로 작성하는데, type은 배열의 요소가 가지고 있는 자료형을 나타낸다. 배열 선언 방식은 아래와 같이 두 가지가 있다.
int[] anArray; // 정수 배열 선언
float anArrayOfFloats[]; // Float 배열 선언 (관례상 이 방법은 권장하지 않음)주의할 점은, 선언은 실제로 배열을 생성하지 않는다는 점이다. 대신, 이 변수가, 지정된 유형의 배열을 보유할 것임을 컴파일러에 알려준다.
여기서 type은 포함 된 요소의 데이터 유형입니다.
아래 ArrayDemo는 정수 배열을 만들고 배열에 일부 값을 넣고 각 값을 출력하는 예시다.
class ArrayDemo {
public static void main(String[] args) {
int[] anArray; // 정수 배열 선언
anArray = new int[3]; // 3개의 정수를 위한 메모리 할당
anArray[0] = 100; // 첫 번째 요소 초기화
anArray[1] = 200; // 두 번째 요소 초기화
anArray[2] = 300; // 세 번째 요소 초기화
System.out.println("인덱스 0의 요소: " + anArray[0]);
System.out.println("인덱스 1의 요소: " + anArray[1]);
System.out.println("인덱스 2의 요소: " + anArray[2]);
}
}
/* 출력 결과 */
/*
인덱스 0의 요소: 100
인덱스 1의 요소: 200
인덱스 2의 요소: 300
*/배열 생성 및 초기화
배열을 만드는 한 가지 방법은 new 연산자를 사용하는 것이다. 아래 코드를 보면, 먼저, new 연산자로 3개의 정수를 담을 수 있는 메모리의 배열을 준비한다(= 오른쪽 부분). 그런 다음 anArray 변수에 생성된 배열을 할당한다(= 왼쪽 부분).
anArray = new int[3];만약 배열을 초기화하지 않고 사용한면, 컴파일러는 컴파일 에러가 발생시킨다.
ArrayDemo.java:4: Variable anArray may not have been initialized.new 연산자를 쓰지 않고, 아래와 같이 빠르게 배열을 생성하고 초기화할 수도 있다.
int[] anArray = {
100, 200, 300,
400, 500, 600,
700, 800, 900, 1000
};다차원 배열
multidimensional array
type[][] 의 방식으로 배열의 요소가 배열인 다차원 배열을 만들 수 있다. 아래 예시를 살펴보자.
class MultiDimArrayDemo {
public static void main(String[] args) {
String[][] names = {
{"Mr. ", "Mrs. ", "Ms. "},
{"Smith", "Jones"}
};
// Mr. Smith
System.out.println(names[0][0] + names[1][0]);
// Ms. Jones
System.out.println(names[0][2] + names[1][1]);
}
}11. 타입 추론과 var
제네릭
제네릭이란, 쉽게 클래스나 메소드 내부에서 사용할 데이터 타입을 외부에서 지정 하는 기법으로 이해하자 - by 생활코딩
제네릭에 관한 상세한 내용은 이곳에 기술해두었다.
타입 추론 등장 배경
제네릭 사용의 이점은 분명히 있지만 다음과 같은 상용구 코드를 작성해야 하는 문제가 생겼다(참고로 아래 세 문장의 코드는 서로 연관성이 없다). 보면 알겠지만 모두 읽기 싫게 생긴 긴 코드들이다.
Map<String, Map<String, String>> mapOfMaps = new HashMap<String, Map<String, String>>();
List<String> strList = Collections.<String>emptyList(); // 1번 (아래서 개선시킴)
List<Integer> intList = Collections.<Integer>emptyList(); // 2번 (아래서 개선시킴)자바 8 이전의 타입 추론
Type Inference, 타입 추론
이처럼 불필요한 코드 정보를 줄이기 위해, 지정되지 않은 타입을 자동으로 추론하는 타입 추론이 도입되었다. 타입 추론은 컨텍스트(메소드 호출, 변수 선언 등에서 얻는 상황 정보)를 통해 이루어진다.
컴파일러는 이런 방식으로 타입 매개 변수를 지정하지 않고도, 필요할 때 자동으로 타입 매개 변수를 유추할 수 있다. 타입 추론을 도입해 위의 코드를 아래처럼 개선하였다.
List<String> strListInferred = Collections.emptyList(); // 1번
List<Integer> intListInferred = Collections.emptyList(); // 1번위의 예에서, 컴파일러는 리턴 타입(List<String> 및 List<Integer>)에 기반해, 제네릭 메소드의 타입 매개 변수를 다음과 같이 유추할 수 있다.
public static final <T> List<T> emptyList()이처럼 자바 5에서는 위에 표시된 대로 특정 컨텍스트(여기선 메소드 컨텍스트)에서 유형 추론을 할 수 있게 되었다.
자바 7에서는 컨텍스트를 점차 확장시켰다. 그리고 다이아몬드 연산자<> 를 도입하였다. 자바 7부터 할당 컨텍스트에서 제네릭 클래스의 생성자에 대해 다이아몬드 연산자를 사용할 수 있게 되었다.
Map<String, Map<String, String>> mapOfMapsInferred = new HashMap<>();여기서 자바 컴파일러는 HashMap 생성자의 타입 매개 변수를 추론하기 위해 할당에 사용된 타입을 사용한다.
일반화된 대상 타입 추론
Generalized Target-Type Inference
자바 8 은 타입 추론의 범위를 더욱 확장했다. 이 확장된 추론 기능을 일반화된 대상 유형 추론이라고 한다. Oracle 공식 문서에서 기술 세부 정보를 읽을 수 있다.
일반화된 대상 유형 추론의 목표는 다음과 같다.
- 메소드 인수 관련 컨텍스트 에서 메소드 타입 매개 변수 추론에 대한 지원 추가
- 체인 호출 에서 메소드 타입 매개 변수 추론에 대한 지원 추가
아래 예시들은 일반화된 대상 유형 추론이 필요한 두 가지 사례를 보여준다.
먼저는 인수 위치에서 타입을 추론을 하는 경우 발생하는 문제를 살펴보자. 아래 List 클래스가 정의되어 있다.
class List<E> {
static <Z> List<Z> nil() { ... };
static <Z> List<Z> cons(Z head, List<Z> tail) { ... };
E head() { ... }
}List.nil()과 같은 제네릭 메소드의 결과는 할당을 통해 유추해볼 수 있다.
List<String> ls = List.nil();컴파일러의 타입 추론 메커니즘은 List.nil() 호출에 대한 타입 인수가 실제로 String이라는 것을 알아낸다. 한편, 위의 내용대로라면 다른 메소드의 인수로 전달될 때 역시 타입이 유추되는 게 합리적일 것이다. 과연 그럴까? 아래 예시 코드를 살펴보자.
List.cons(42, List.nil()); //error: expected List<Integer>, found List<Object>불행히도 JDK 5, 6, 7에서는 이런 메커니즘이 작동하지 않는다. 개발자가 사용할 수 있는 유일한 옵션은 아래와 같이 명시적 타입 인수를 사용하는 것이다.
List.cons(42, List.<Integer>nil());이러한 메소드 호출에서, 매개 변수 타입을 고려하도록 타입-인수 추론을 확장하면 좋을 것이다.
다음으로, 체인 호출에서 추론이 사용되는 경우 어떤 문제가 발생하는지 살펴보자. 체인 호출이란 표현식 안에서 연결된 메소드가 연달아 호출되는 것을 말한다.
String s = List.nil().head(); //error: expected String, found Object위 할당에서도 타입 추론 메커니즘이 정상적으로 작동하지 않는다. 결국 해결 방법은 아까와 같이 개발자가 타입을 수동으로 지정해주는 것 뿐이다. (하지만 가독성이 심히 떨어진다)
String s = List.<String>nil().head();반복되는 얘기이지만, 할당의 오른쪽 타입(String)이 제네릭 메소드 호출 체인을 통과하도록 만들면, 명시적 타입을 수동으로 입력해야 하는 부담을 줄일 수 있을 것이다.ㄴ
var 소개
자바 9까지는 지역 변수의 타입을 명시적으로 작성하고, 초기화에 사용된 이니셜 라이저와 호환되는지 확인해야 했다. 예를 들면, 아래처럼 말이다.
String message = "Good bye, Java 9";그런데, 자바 10부터 var가 추가되면서 다음과 같이 지역 변수를 선언할 수 있게 되었다.
@Test
public void whenVarInitWithString_thenGetStringTypeVar() {
var message = "Hello, Java 10"; // var 사용시 타입 선언을 하지 않아도 괜찮다.
assertTrue(message instanceof String);
}다만, 이 기능은 이니셜 라이저가 있는 지역 변수에만 사용할 수 있다. 멤버 변수, 메소드 매개 변수, 리턴 타입 등에서는 사용할 수 없다. 컴파일러가 타입을 유추 할 수 없는 경우, 반드시 이니셜 라이저가 필요하다.
이 기능은 상용구(보일러플레이트) 코드를 줄이는 데 도움이 된다. 예를 들면,
Map<Integer, String> map = new HashMap<>();위와 같은 코드가 아래처럼 깔끔해진다.
var idToNameMap = new HashMap<Integer, String>(); // 변수 유형보다 변수 이름에 초점이 맞춰진다.var를 사용하더라도 런타임 오버 헤드가 없고, 자바를 동적 타입 언어로 만들지도 않는다. 변수의 타입은 여전히 컴파일 시간에 유추되며 나중에 변경할 수 없다.
잘못된 var 사용
-
var는 이니셜 라이저없이 작동하지 않는다.
var n; // error: cannot use 'var' on variable without initializer -
null로 초기화해도 작동하지 않는다.var emptyList = null; // error: variable initializer is 'null' -
지역 변수가 아닌 경우에도 작동하지 않는다.
public var = "hello"; // error: 'var' is not allowed here -
Lambda 표현식에는 명시적인 대상 유형이 필요하므로
var를 사용할 수 없다.var p = (String s) -> s.length() > 10; // error: lambda expression needs an explicit target-type -
배열 이니셜 라이저의 경우에도 사용할 수 없다.
var arr = { 1, 2, 3 }; // error: array initializer needs an explicit target-type
이외에, 에러가 발생하지는 않더라도 가독성이 떨어지는 경우, 메소드의 반환 타입을 알 수 없는 경우, 파이프 라인이 긴 스트림의 경우, var 사용을 지양해야 한다.
