DynamoDB(1)
-
NoSQL(Not Only SQL) 데이터베이스
-
매우 빠른 쿼리 속도
-
Auto-Scaling 기능 탑재 (처음 데이터베이스를 만들면 그 크기가 정해지는데, 데이터가 크기가 초과될 시 테이블의 크기가 알아서 늘어나고 그렇지 않으면 사이즈가 줄어든다.)
-
Key-Value 데이터 모델 지원
-
테이블 생성시 스키마 생성 필요 없음 (데이터가 들어올 때 알아서 스키마가 생성 됨)
-
모바일, 웹, IoT데이터 사용시 추천됨
-
SSD 스토리지 사용
DynamoDB(2)
-
테이블(Table)
-
아이템(Items) - 행(row)와 개념이 비슷함
-
특징(Attributes) - 열(column)과 개념이 비슷함
-
Key-Value (Key : 데이터의 이름, Value : 데이터 자신)
-
예시) JSON, XML
Primary Keys (PK)
- pk를 사용하여 데이터 쿼리
- DynamoDB에는 두가지의 PK 유형이 있음
파티션 키 (Partition Key)- 고유 특징(Unique Attribute)
- 실제 데이터가 들어가는 위치를 결정해줌
- 파티션키 사용시 동일한 두개의 데이터가 같은 위치에 저장될 수 없음!
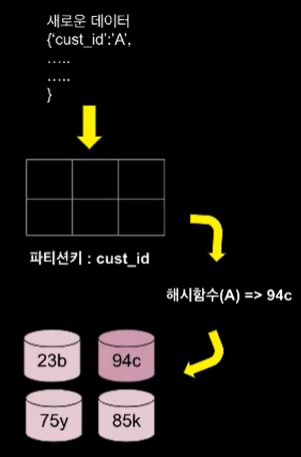
- 테이블을 만들 떄 파티션 키를 설정하고, 데이터가 들어오면 그 데이터가 어디로 저장될지 파티션 키 내부에 들어있는 해시함수를 돌리고 그 결과를 반환 함(해시 값)
- 똑같은 여러개의 데이터가 같은 장소에 저장할 수 없다, 파티션 키는 중복될 수 없다.
복합 키(Composite Key)
- 파티션키(Partition Key) + 정렬키(Sort Key) 를 합친것
- 예시 : 똑같은 고객이 다른 날짜에 다른 물건을 구매
- 파티션키 : 고객아이디, 정렬키 : 날짜(Timestamp)
- 같은 파티션키의 데이터들은 같은 장소에 보관, 그다음 정렬키에 의해 데이터가 정렬됨

- Customer_id 파티션키, 정렬키를 Transction_date
DynamoDB 데이터 접근 관리
- AWS IAM으로 관리할 수 있음
- 테이블 생성과 접근 권한을 부여할 수 있음
- 특정 테이블만 특정 데이터만 접근 가능케 해주는 특별한 IAM 역할 존재
- ex. 어떤 기록을 볼때 다른 사람들의 정보는 가리고, 본인꺼만 보여지도록 IAM 역할
Index
- 특정 컬럼만을 사용하여 쿼리
- 테이블 전체가 아닌 기준점(pivot)을 사용해 쿼리가 이루어짐
- 매우 큰 쿼리 성능 효과
- 두가지의 Index 유형 존재
- Local Secondary Index
- Global Secondary Index
Local Secondary Index (LSI)
- 테이블 생성시에만 정의해줄 수 있음
- 따라서 테이블 생성 후 변경, 삭제가 불가능
- 똑같은 파티션키 사용, 그러나 다른 정렬키 사용
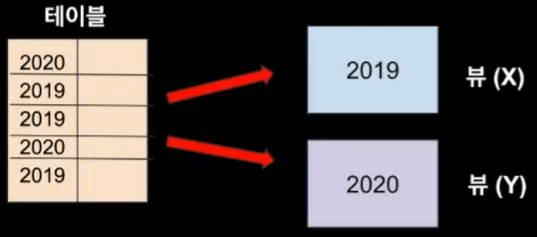
- 파티션키는 x와 y 둘다 같다
- 같은 파티션키와 다른 정렬키로 각각의 뷰가 생성
- LSI는 파티션키, 정렬키 둘다 사용됨 정렬키 기반으로 쿼리 실행 시 그렇지 않은것 보다 훨씬 빠르다.
- 만약에 정렬키가 없다면 2020년만 가져오고 싶다면 테이블 전체를 뒤져야함
Global Secondary Index(GSI)
-
테이블 생성후에도 추가, 변경, 삭제 가능
-
다른 파티션키, 정렬키 사용
-
뷰 : 인덱스를 정의하면 기존에 있던 테이블에서 전혀 다른 파티션키와 정렬키를 갖는 뷰가 복제가 된다.
만약에 테이블에서 데이터가 변경이 된다면 뷰는 알아서 변화를 인식하여 그대로 받아들임
GSI를 생성하면 새로운 뷰를 생성하는것, 테이블 안에서 조작하는게 아님
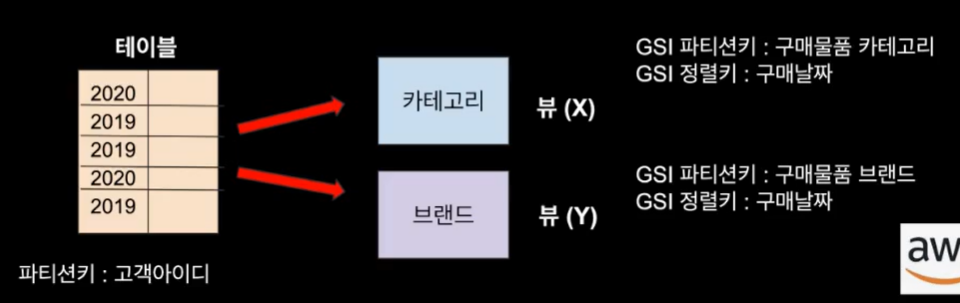
- ex. 의류 백화점 거래 내역이 들어 있다
- 테이블을 만들 때 파티션키를 고객아이디로 생성
- 구매 물품 카테고리별로 무엇이 많이 팔리는지 궁금
- 테이블이 아닌 다른 파티션키를 사용하여 GSI 도움을 받아 새로운 뷰를 만들 수 있다.
- 저 뷰를 이용하여 쿼리를 한다면 훨씬 빠르고 정확한 쿼리를 가져올 수 있다.
DynamoDB - Query VS Scan
Query
- Primary Key를 사용하여 데이터 검색, 보조 파티션/해시 키 를 기반으로 선택한 파티션에 대한 직접 조회를 수행
- Query사용시 모든 데이터(컬럼) 반환
- index 가 설정된 필드만 Query 가 가능합니다.
- ProjectionExpression 파라미터 (필터링 : ex. 거래 아이디와 가격만 보여 주도록)

Scan
- 모든 데이터를 불러옴(primary key 사용 x), 값과 일치하는 요소를 찾기 위해 전체 테이블을 풀스캔합니다.
- 따로 필터를 추가하여 원하는 데이터를 볼 수 있다.
- ProjectionExpression 파라미터
Query VS Scan
- Query가 Scan보다 훨씬 효율적임
- 따라서 Query 사용 추천
scan 성능 높이는 방법
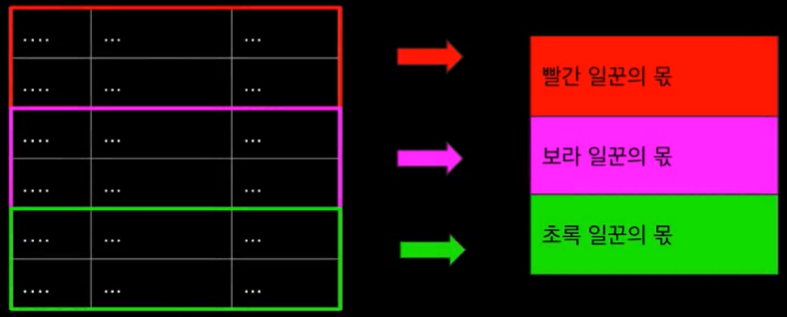
- 스캔할 때 스캔하는 일꾼들을 여러개로 분산시키는 기능이 있다.
- 병행 스캔(Parallel Scan)
- 테이블 전체를 n등분으로 나누고 스캔 일꾼들을 쪼개진 파편들로 보내 스캔하는 방법
- 테이블의 크기가 작거나, pk 정의가 필요없는 룩업 정도로 사용할 때만 Scan 사용하는것이 적절하다 (변화가 없는 단순 참고용)
https://www.inflearn.com/course/aws-%EC%9E%85%EB%AC%B8/dashboard
