DB, DBMS, RDBMS, NoSQL 순으로 설명
데이터베이스(DB)
- 컴퓨터 시스템에 저장되는 구조화된 정보 혹은 데이터의 집합
(ex.회원 정보가 있는 엑셀)
DBMS(Database Management System)
-
데이터베이스에서 데이터를 정의, 저장, 검색 및 인출, 관리하기 위해 사용되는 소프트웨어
- 저장되는 데이터를 어떻게 정의할 것인지?
- 데이터를 어떻게 저장할 것인지?
- 저장된 데이터를 어떻게 관리할 것인지?(백업도 필요하고 데이터가 손상이 됐을 때 복원하는 기능도 필요)
- 데이터가 요청이 되었을 때 어떤식으로 검색할 것인지?
- 데이터를 어떻게 인출을 해서 데이터를 서비스 해줄것인지
-
즉 데이터가 단순하게 저장만 되어 있는 상태가 아니라 그 데이터가 효율적으로 관리되고 서비스 될수 있도록 관리해주는 제반 기능들을 다 가진 소프트웨어를 DBMS라고 한다.
DBMS 종류
관계형 데이터베이스(Relational DBMS)
-
데이터가 테이블 형태로 기본 단위가 구성이 되어 있고(column, row)
-
그 테이블과 테이블간의 관계(relationship)에 의해서 전체 데이터베이스가 만들어져서 돌아가는 것
-
데이터는 테이블에 레코드로 저장되는데, 각 테이블마다 명확하게 정의된 구조가 있다. 해당 구조는 필드의 이름과 데이터 유형으로 정의된다.
-
따라서 스키마를 준수하지 않은 레코드는 테이블에 추가할 수 없다. 즉, 스키마를 수정하지 않는 이상은 정해진 구조에 맞는 레코드만 추가가 가능한 것이 관계형 데이터베이스의 특징 중 하나다.
-
하나의 테이블에서 중복 없이 하나의 데이터만을 관리하기 때문에 다른 테이블에서 부정확한 데이터를 다룰 위험이 없어 테이블간에 독립성이 유지된다.
-
관계형태로 되어 있기 때문에 어떤 데이터를 조회를 하거나 조작을 하기 위해서 SQL(Structured Query Language)이라는 언어를 이용한다.
비관계형 데이터베이스(Non-Relational)
-
RDBMS와는 달리 테이블 간 관계를 정의하지 않습니다. 데이터 테이블은 그냥 하나의 테이블이며 테이블 간의 관계를 정의하지 않아 일반적으로 테이블 간 Join도 불가능합니다.
-
NoSQL은 점점 빅데이터의 등장으로 인해 데이터와 트래픽이 기하급수적으로 증가함에 따라 RDBMS에 단점인 성능을 향상시키기 위해서는 장비가 좋아야 하는 Scale-Up의 특징이 비용을 기하급수적으로 증가시키기 때문에
-
데이터 일관성은 포기하되 비용을 고려하여 여러 대의 데이터에 분산하여 저장하는 Scale-Out을 목표로 등장하였습니다.
NoSQL Type
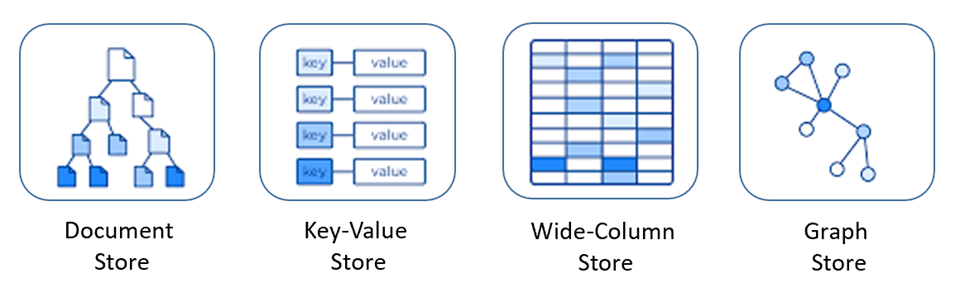
Document(다양한 형태의 데이터 저장 가능)
-
Documnet Database 데이터는 Key와 Document의 형태로 저장된다. Key-Value 모델과 다른 점이라면 Value가 계층적인 형태인 도큐먼트로 저장된다는 것이다.
-
객체지향에서의 객체와 유사하며, 이들은 하나의 단위로 취급되어 저장된다. 다시 말해 하나의 객체를 여러 개의 테이블에 나눠 저장할 필요가 없어진다는 뜻이다.
-
주요한 특징으로는 객체-관계 매핑이 필요하지 않다. 객체를 Document의 형태로 바로 저장 가능하기 때문이다.
-
또한 검색에 최적화되어 있는데, 이는 Key-Value 모델의 특징과 동일하다. 단점이라면 사용이 번거롭고 쿼리가 SQL과는 다르다는 점이다.
-
도큐먼트 모델에서는 질의의 결과가 JSON이나 xml 형태로 출력되기 때문에 그 사용 방법이 RDBMS에서의 질의 결과를 사용하는 방법과 다르다.
-
대표적인 NoSQL Document Model로는 MongoDB, CouthDB 등이 있다.
Key-Value(빠른 속도, 많은 데이터)
-
Key-Value Database는 데이터가 Key와 Value의 쌍으로 저장된다.
-
Key는 Value에 접근하기 위한 용도로 사용되며, 값은 어떠한 형태의 데이터라도 담을 수 있다.
-
심지어는 이미지나 비디오도 가능하다. 또한 간단한 API를 제공하는 만큼 질의의 속도가 굉장히 빠른 편이다.
-
대표적인 NoSQL Key-Value Model로는 cassandra, Redis, Riak, Amazon Dynamo DB 등이 있다.
Graph(노드 사이 관계를 알아야할 때)
-
Graph Model Model에서는 데이터를 Node와 Edge, Property와 함께 그래프 구조를 사용하여 데이터를 표현하고 저장하는 Database입니다.
-
개체와 관계를 그래프 형태로 표현한 것이므로 관계형 모델이라고 할 수 있으며, 데이터 간의 관계가 탐색의 키일 경우에 적합하다.
-
페이스북이나 트위터 같은 소셜 네트워크에서(내 친구의 친구를 찾는 질의 등) 적합하고, 연관된 데이터를 추천해주는 추천 엔진이나 패턴 인식 등의 데이터베이스로도 적합하다.
-
대표적인 NoSQL Graph Model로는 Neo4J가 있다.
Wide-Column
-
Column-family Model 기반의 Database이며 이전의 모델들이 Key-Value 값을 이용해 필드를 결정했다면, 특이하게도 이 모델은 키에서 필드를 결정한다.
-
키는 Row(키 값)와 Column-family, Column-name을 가진다. 연관된 데이터들은 같은 Column-family 안에 속해 있으며, 각자의 Column-name을 가진다. 관계형 모델로 설명하자면 어트리뷰트가 계층적인 구조를 가지고 있는 셈이다.
-
이렇게 저장된 데이터는 하나의 커다란 테이블로 표현이 가능하며, 질의는 Row, Column-family, Column-name을 통해 수행된다.
-
대표적인 NoSQL Column-family Model로는 HBase, Hypertable 등이 있다.
NoSQL 데이터베이스는 어떻게 확장되나?

- 심플하게 key, value로 저장된다고 한다면, value는 JSON 형식으로 저장되어 많은 데이터를 포함하게 된다.
- 이 단순한 디자인은 NoSQL 데이터베이스가 더 잘 확장되는 이유이다.

-
단일 데이터베이스 서버가 모든 데이터를 저장하거나 모든 쿼리를 처리하기에 충분하지 않은 경우 워크로드를 둘 이상의 서버로 분할할 수 있다.
-
그러면 각 서버는 데이터베이스의 일부만 담당한다.
-
NoSQL 용어로 데이터베이스를 분할하여 각 부분을 파티션이라고 한다.
NoSQL 데이터베이스는 어떻게 동작하는가?
- 데이터베이스가 수천 개의 파티션으로 분할되어 있는 경우 항목이 저장된 위치를 어떻게 알 수 있을까?
- 기본 키(Primary key)가 필요하다.
- NoSQL 데이터베이스는 키-값 저장소이며 키는 항목이 저장될 파티션을 결정한다.

- NoSQL 데이터베이스는 해시 함수를 사용하여 각 항목의 기본 키를 고정 범위에 속하는 숫자로 변환합니다.

- 예를 들어 0 ~ 100사이 해시 값과 범위는 항목을 저장할 위치를 결정하는데 사용된다.
- 데이터베이스가 작거나 많은 요청을 받지 못한다면 모든 것을 단일 서버에 넣을 수 있습니다.
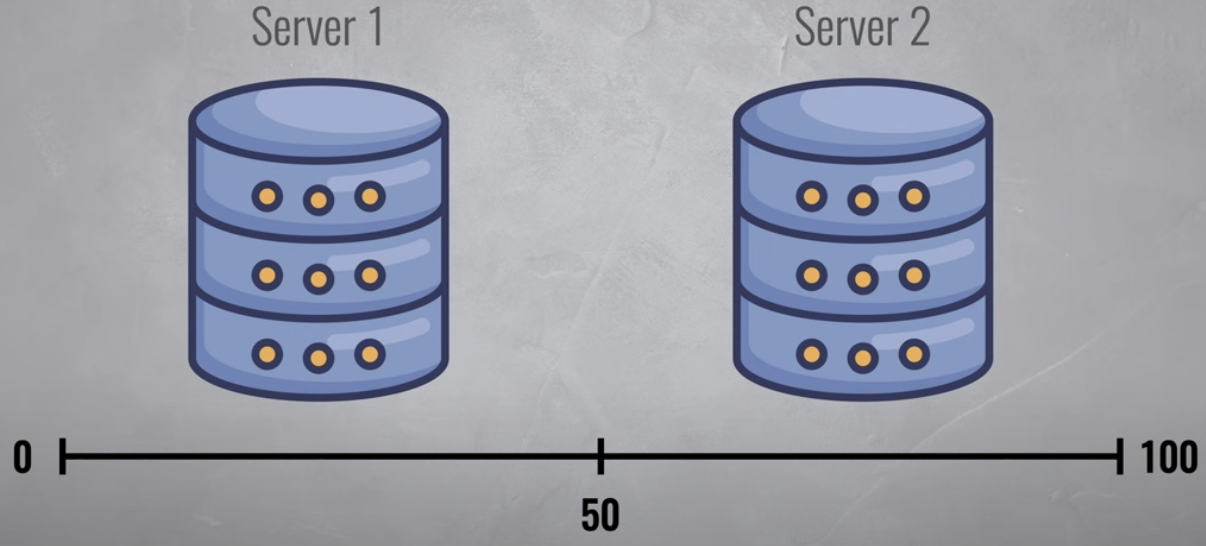
- 해당 서버에 과부하가 걸리면 보조 서버를 추가하여 범위가 절반으로 분할
- Server1은 해시가 0 ~ 50 사이인 모든 항목을 담당하고, Server2는 50 ~ 100 사이의 모든 항목을 저장합니다.
- 이 범위를 Keyspace 라고 합니다.
- 새 항목을 저장할 위치와 기존 항목을 찾을 위치의 두 가지 문제를 해결하는 간단한 시스템
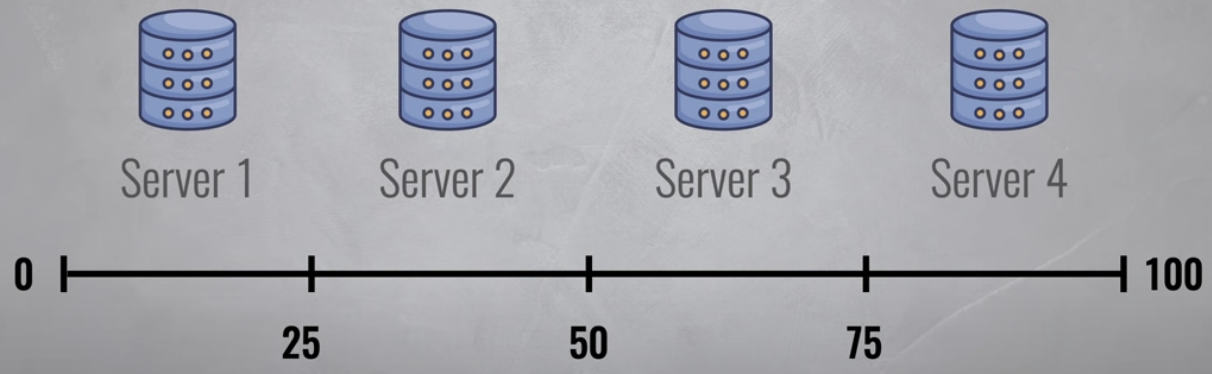
- 항목 키의 해시를 계산하고 키 공간의 어느 부분을 담당하는지 서버를 추적하기만 하면 됩니다.
- 실제 NoSQL 데이터베이스는 훨씬 더 큰 키 공간을 가지므로 거의 제한 없이 확장할 수 있다.
그래서 NoSQL은?
- NoSQL 데이터베이스는 관계형 데이터베이스에 비해 특정 이점이 있는건 분명하다.
- 그러나 그것이 관계형 데이터베이스가 구식이라는 말이 아니다.
- NoSQL은 데이터를 검색할 수 있는 방식이 더 제한적이며 기본 키로 항목을 검색할 수만 있다.
- ID로 주문을 찾는 것은 문제가 없지만 일정 금액 이상의 주문을 모두 찾는 것은 매우 비효율적이다.
- 반면에 관계형 데이터베이스는 문제가 없다.
- 이 문제에 대한 해결 방법이 있지만 데이터에 액세스하는 방법을 알고 있는 경우에만 가능하다.
- NoSQL 데이터베이스는 결과적 일관성(Eventual consistency)을 구현한다.
- 즉 특정 서버는 변경 된 데이터가 조회되고 일부는 변경되지 않은 상태로 조회될 수 있다.
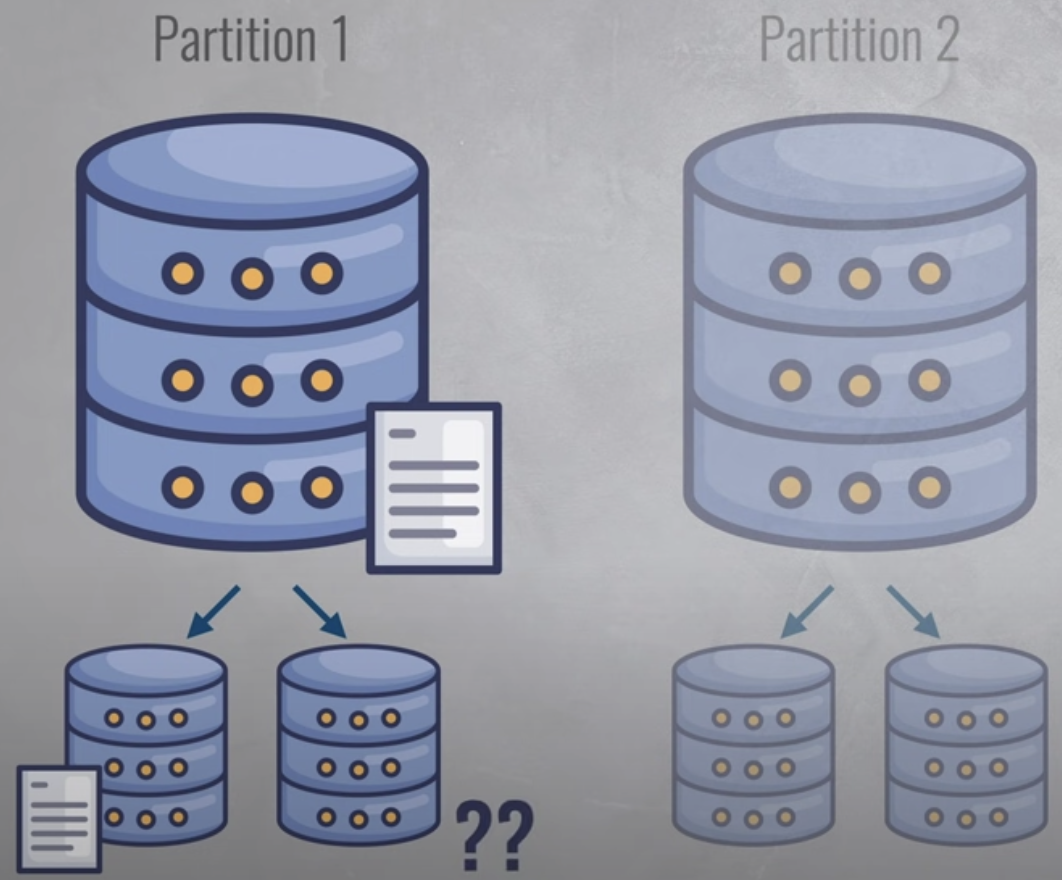
- NoSQL은 데이터베이스를 파티션으로 분할, 각 파티션은 여러 서버에 미러링
- 데이터베이스에 새 항목을 쓰면 미러 중 하나가 새 항목을 저장한 다음 백그라운드에서 다른 항목에 복사된다.
- 이 프로세스에는 약간의 시간이 걸릴 수 있다.
- 따라서 해당 항목을 읽을 때 NoSQL 데이터베이스는 아직 해당 항목이 없는 미러에서 해당 항목을 읽으려고 할 수 있다.
- 데이터가 단 몇 밀리초 만에 복제되기 때문에 실제로는 큰 문제가 아니다.
- 데이터 일관성을 위해서 모든 서버에 결과값을 질의하고 N개 이상이 같은 값을 반환할 때 사용자에게 해당 값을 보여주는 형태의 일관성이다.
- 이 때 사용되는 개념이 쿼럼(Quorum)과 구성임계값 (Configurable Threshold)이다.
- 쿼럼 : 완료되었다고 여겨지는 읽기나 쓰기 작업에 반드시 응답해야 하는 서버의 수
- 구성임계값 : 응답여부를 결정짓는 기준
- 응답 시간 : 일관성 사이의 균형을 맞추기 위해 구성임계값을 조정한다.
- 임계값이 높을 수록 일관성이 높고 정확해지며, 낮을 수록 속도는 빨라지나 일관성이 깨진다.
- 또한, 응답시간 - 지속성 사이의 균형을 맞추는 경우에도 사용할 수 있다.
- 임계값 수가 적으면 서버 N대중 일부에만 데이터를 저장하고 완료했다고 결과값을 내보내므로
- 지속성 측면에서는 임계값 = 서버 전체 대수와 일치해야만 지속성을 유지할 수 있다.
RDBMS와 NoSQL의 장단점
RDBMS
장점
- RDBMS는 위에서 설명을 하였듯이 정해진 스키마에 따라 데이터를 저장하여야 하므로 명확한 데이터 구조를 보장하고 있습니다.
- 또한 관계는 각 데이터를 중복없이 한 번만 저장할 수 있습니다.
단점
- 테이블간테이블 간 관계를 맺고 있어 시스템이 커질 경우 JOIN문이 많은 복잡한 쿼리가 만들어질 수 있습니다.
- 성능 향상을 위해서는 서버의 성능을 향상 시켜야하는 Scale-up만을 지원합니다. 이로 인해 비용이 기하급수적으로 늘어날 수 있습니다.
- 스키마로 인해 데이터가 유연하지 못합니다. 나중에 스키마가 변경 될 경우 번거롭고 어렵습니다.
NoSQL
장점
- NoSQL에서는 스키마가 없기 때문에 유연하며 자유로운 데이터 구조를 가질 수 있습니다. 언제든 저장된 데이터를 조정하고 새로운 필드를 추가할 수 있습니다.
- 데이터 분산이 용이하며 성능 향상을 위한 Saclue-up 뿐만이 아닌 Scale-out 또한 가능합니다.
단점
- 데이터 중복이 발생할 수 있으며 중복된 데이터가 변경 될 경우 수정을 모든 컬렉션에서 수행을 해야 합니다.
- 스키마가 존재하지 않기에 명확한 데이터 구조를 보장하지 않으며 데이터 구조 결정가 어려울 수 있습니다.
CAP 이론
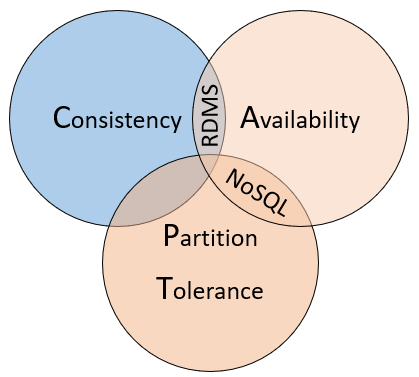
- CAP 이론(또는 Brewers theorem)이란 Network로 연결된 분산된 데이터베이스 시스템은 일관성(Consistency), 가용성(Availability), and 분할 내구성(Partition Tolerance)의 3가지 특성중 2가지 특성만을 충족 할수 있고 3가지 모두 충족할 수 없다는 이론입니다.

- DB의 CAP 이론 기준의 분류 현실과 동떨어진 부분이 많다.
일관성(Consistency)
- 일관성을 가진다는 것은 모든 데이터를 요청할 때 응답으로 가장 최신의 변경된 데이터를 리턴 또는 실패를 리턴한다는 것입니다. 즉, 모든 읽기에 대해서 DB노드가 항상 동일한 데이터를 가지고 있어야한다는 의미입니다.
가용성(Availability)
- 가용성은 모든 요청에 대해서 정상적인 응답을 한다는 것입니다. 즉, 클러스터의 노드 일부에서 장애(Down 등)가 발생하더라도 READ와 WRITE 등의 동작은 항상 성공적으로 리턴되어야 한다는 것입니다.
분할 내구성(Partition Tolerance)
- 분할 내구성이란 DB Node간의 통신 장애가 발생하더라도 동작해야한다는 것입니다. Instacne A와 B가 있습니다. 이때 A와 B의 Instance간의 네트워크에 장애가 발생했습니다. 유저는 A DB에서 쿼리를 했습니다. Instance A는 B의 상태를 알지 못하지만 A 자체만으로 동작합니다. 이를 분할 내구성이라고 합니다.
가용성 VS 분할 내구성
- 가용성과 분할 내구성의 개념이 조금 헷갈릴 수 있을 것입니다. 개인적으로 확인 했을 때 가용성은 노드에서 장애가 발생하여 Down 되었을 때, 분할 내구성은 노드간의 통신이 정상적으로 이루어지지 않을 때 라고 확인하였습니다.
관계형 및 NoSQL 시스템에 대한 고려 사항
| 다음과 같은 경우 NoSQL 데이터 저장소를 고려합니다. | 다음과 같은 경우 관계형 데이터베이스를 고려합니다. |
|---|---|
| 대규모로 예측 가능한 대기 시간이 필요한 대량 워크로드(예: 초당 수백만 개의 트랜잭션을 수행하는 동안 밀리초 단위로 측정된 대기 시간) | 일반적으로 워크로드 볼륨은 초당 수천 개의 트랜잭션에 적합합니다. |
| 데이터가 동적이며 자주 변경됩니다. | 데이터는 고도로 구조화되어 있으며 참조 무결성이 필요합니다. |
| 관계는 비정규화된 데이터 모델일 수 있습니다. | 관계는 정규화된 데이터 모델에서 테이블 조인을 통해 표현됩니다. |
| 데이터 검색은 간단하며 테이블 조인 없이 표현됩니다. | 복잡한 쿼리 및 보고서 작업 |
| 데이터는 일반적으로 여러 지역에서 복제되며 일관성, 가용성 및 성능을 더 세부적으로 제어해야 합니다. | 데이터는 일반적으로 중앙 집중화되거나 비동기적으로 지역을 복제할 수 있습니다. |
| 애플리케이션이 퍼블릭 클라우드와 같은 상용 하드웨어에 배포됩니다. | 애플리케이션이 대규모의 고급 하드웨어에 배포됩니다. |
워크로드 란?
고객 대면 애플리케이션이나 백엔드 프로세스 같이 비즈니스 가치를 창출하는 리소스 및 코드 모음 또는
주어진 기간에 시스템에 의해 실행되어야 할 작업의 할당량을 의미
https://www.youtube.com/watch?v=pk7FP2FDIw8
https://gyoogle.dev/blog/computer-science/data-base/SQL%20&%20NOSQL.html
https://aws.amazon.com/ko/nosql/
https://docs.microsoft.com/ko-kr/dotnet/architecture/cloud-native/relational-vs-nosql-data
https://azure.microsoft.com/ko-kr/overview/nosql-database/
https://khj93.tistory.com/entry/Database-RDBMS%EC%99%80-NOSQL-%EC%B0%A8%EC%9D%B4%EC%A0%90
https://www.youtube.com/watch?v=0buKQHokLK8
