팀 프로젝트 진행중 N+1 문제에 대해서 물어보는 팀원이 있어서, 단순히 N+1문제는 성능저하를 일으키고 그 대안으로 Fetch join, batch size 등을 알려줬지만 하나하나 상세하게 설명하지는 못하였다. 팀원들과 같이 문제를 해결하기 위해서 N+1 문제에 대해 알아보려고 한다.
N+1 문제란?
연관관계가 설정된 엔티티를 조회할 때, 쿼리문이 1회 발생되어야 하지만 연관관계에 따라서 N개 의 쿼리를 추가로 조회해서 총 N+1만큼 쿼리가 발생되는 현상. 객체는 연관관계를 통해 레퍼런스를 가지고 있으면 언제든지 메모리 내에서 연관 객체에 접근할 수 있지만, RDB의 경우 Select 쿼리를 통해서만 조회할 수 있기 때문이다.
N+1 문제 코드
House : Room = 1 : N
House
@Getter
@Entity
@Builder
@AllArgsConstructor
@NoArgsConstructor
public class House {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "house_id")
private Long id;
private String name;
@OneToMany(mappedBy = "house", cascade = ALL, fetch = FetchType.EAGER)
private List<Room> rooms = new ArrayList<>();
}Room
@AllArgsConstructor
@NoArgsConstructor
@Builder
@Getter
@Entity
public class Room {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "room_id")
private Long id;
private String name;
@ManyToOne(fetch = FetchType.EAGER)
@JoinColumn(name = "house_id")
private House house;
@Builder
public Room(String name, House house) {
this.name = name;
setHouse(house);
}
private void setHouse(House house) {
this.house = house;
house.getRooms().add(this);
}
}Test
@SpringBootTest
public class HouseRoomTest {
@Autowired
HouseRepository houseRepository;
@Autowired
RoomRepository roomRepository;
@Test
public void test() {
for (int i = 0; i < 5; i++) {
House house = House.builder().name("house" + i).build();
houseRepository.save(house);
roomRepository.save(Room.builder().name("room" + i).house(house).build());
}
System.out.println("-----------------------------------------------");
houseRepository.findAll();
}
}
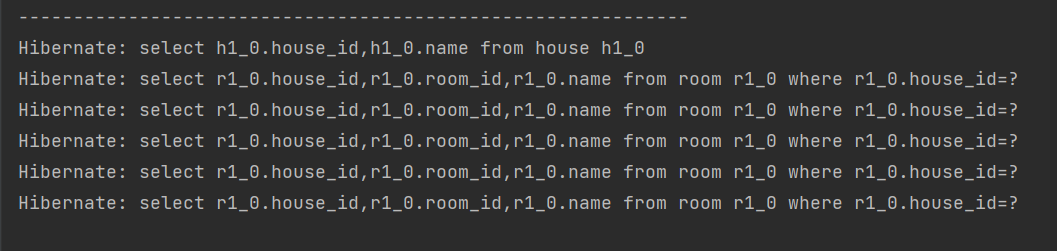
테스트 코드를 실행하면 바로 위 사진과 같이 N+1 문제가 발생되는 것을 알 수 있다. N+1 문제가 발생하면 쿼리가 N번 만큼 증가하기 때문에 서버에 부담을 주고 사용자의 요청은 적지 않은 시간동안 지연된다.
해결 방법
해결 방법에 들어가기 전 fetchType Lazy설정은 해결 방법이 아니라는 것을 알고 가야한다. 지연로딩은 연관관계 데이터를 프록시 객체로 바인딩했을 뿐이며, 지연 로딩 역시 하위 엔티티로 작업을 하게 되면 그 순간 추가로 N개의 쿼리가 발생된다.
Fetch Join
첫 번째는 Fetch Join이다. FetchJoin은 JPQL에서 제공 하는 기능으로 DB에서 데이터를 가져올 때 처음부터 연관된 데이터까지 같이 가져오게 하는 방법이다.
Fetch Join 일반 Join 차이점
일반 Join
- Join은 fetch join과 다르게 쿼리에서는 join으로 조회해도, 영속성 컨텍스트에는 조회의 주체가 되는 엔티티만 불러오게 된다.
- 조회의 주체가 되는 Entity만 SELECT해서 영속화하기 때문에, 데이터는 필요하지 않지만 연관 Entity가 쿼리 검색 조건에는 필요한 경우에 주로 사용한다.
Fetch Join
- Fetch Join은 join 이 걸린 모든 연관 Entity를 영속성 컨텍스트에 저장한다.
- Fetch Join이 걸린 Entity 모두 영속화하기 때문에, FetchType이 Lazy인 Entity를 참조하더라도 이미 영속성 컨텍스트에 들어있기 때문에, 따로 쿼리가 실행되지 않은 채로 N+1문제가 해결된다.
public interface HouseRepository extends JpaRepository<House, Long> {
@Query("select h from House h join fetch h.rooms")
List<House> findAllWithRoom();
}
@SpringBootTest
public class HouseRoomTest {
...
@Test
public void test() {
...
System.out.println("-----------------------------------------------");
houseRepository.findAllWithRoom();
}
}
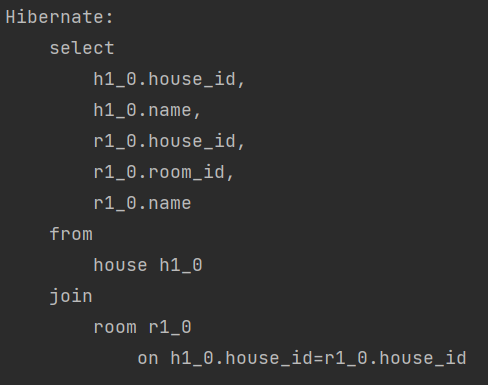
쿼리문이 1개로 줄은 것을 확인할 수 있다. Fetch Join의 단점으로는 하나의 쿼리문에 2번 이상 적용 불가능이다. 또한 페이징이 포함된 검색 쿼리에서 사용하면 큰 문제점이 하나있는데 아래와 같은 경고 문구를 만나게 된다.
HHH000104: firstResult/maxResults specified with collection fetch; applying in memory!
Join하는 엔티티를 limit로 갖고 오는 것이 아닌, 전부를 가지고와 서버에서 개수를 조절하는 작업을 하게 된다. 이는 out of memory 현상을 발생시킬수 있어서 매우 조심해야한다.
@Entity Graph
@EntityGraph의 attributePaths에 쿼리 수행시 바로 가져올 필드명을 지정하면 Lazy가 아닌 Eager 조회로 가져오게 된다.
public interface HouseRepository extends JpaRepository<House, Long> {
@EntityGraph(attributePaths = {"rooms"})
@Query("select h from House h")
List<House> findAllWithRoomGraph();
}@SpringBootTest
public class HouseRoomTest {
...
@Test
public void test() {
...
System.out.println("-----------------------------------------------");
houseRepository.findAllWithRoomGraph();
}
}
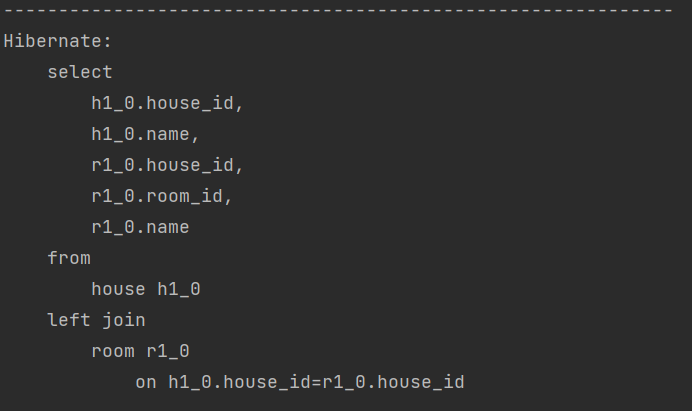
Fetch Join과 @Entity Graph의 차이점 및 공통점
Fetch조인은 inner join이며 @Entity Graph는 outer join이다. 그리고 공통적으로 카티션 프로덕트(Cartesian Product)가 발생하여 데이터가 중복 발생할 수 있다. 이에 대응하여 쿼리문에 Distinct 옵션을 주거나, 일대다 필드 타입을 Set으로 하는 것이다.
Batch Size
hibernate가 제공하는 옵션중 default_batch_fetch_size이 있는데 이 옵션은 N+1의 완벽한 해결 방안보다는 차선책의 느낌이다. 이 방법을 사용하면 기존 쿼리문에서 where 조건에 in으로 batch size만큼의 id값을 넣는다. 즉 연관된 엔티티에 1만개의 데이터가 있을 때 batch size가 1000이라면 기존 10000/1000, 10번의 쿼리가 나간다. 최소한의 쿼리를 보내 효율적으로 지연로딩을 하는 것이다.
spring.jpa.properties.hibernate.default_batch_fetch_size=1000결론
1:1 연관관계는 최대한 fetch join을 활용하고 컬렉션 연관관계는 Batch size를 활용하는 것이 좋고, 많은 컬럼 중 특정 컬럼만 조회해야 할 경우 처음부터 DTO로 조회를 하는 것이 좋다. 마지막으로 JPA를 사용할 때는 항상 N+1의 문제를 염두에 두어야 하며, 항상 로그를 통해서 쿼리가 내가 원하는 대로 나가는지 확인해야 한다.
